







AdaBoost算法(一)——基础知识篇
集成学习系列博客:
- 集成学习(ensemble learning)基础知识
- 随机森林(random forest)
- AdaBoost算法(一)——基础知识篇
- AdaBoost算法(二)——理论推导篇
在前面博客集成学习(ensemble learning)基础知识中介绍了集成学习方法大体可分为Boosting、Bagging和Stacking。在Boosting算法族中最著名的就是AdaBoost(全称:adaptive boosting)了(当然GBDT和XGBoost也是灰常的出名),这篇博客就来介绍AdaBoost,这篇博客主要从以下三个方面来介绍AdaBoost:
- AdaBoost的基本算法
- AdaBoost的举例说明
- AdaBoost在scikit-learn中的应用
因此,这篇博客主要面向基础原理介绍和应用,至于AdaBoost的理论推导证明部分,将会在下一篇博客AdaBoost算法(二)——理论篇中介绍。
一、AdaBoost的基本算法
对于Boosting(提升)方法而言,主要需要考虑两个方面的问题:1、在每一轮如何改变训练数据的样本或者概率分布。2、如何将弱分类器组合为一个强分类器。来看看AdaBoost是怎样处理这两个问题的:
对于第一个问题,AdaBoost会提高前一轮被弱(基)分类器误分的样本的权重,降低那些被正确分类得样本的权值。这样就会让被误分的样本在下一轮中被弱分类器更加关注(因为误分的样本权重大)。读者肯定还会对误分类样本权重加大了,在下一轮中是如何被重点关注的,具体怎么操作的,抱有疑问,这个问题先放在这,后面会回到这个问题。
对于第二个问题,AdaBoost采取加权投票的原则,即加大分类误差率小的弱分类器的权重,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权重,使其在表决中起较小的作用。
下面来看看假定是一个二分类问题,AdaBoost算法的细节:

下面对以上算法流程做个简短的说明:
第1步也就是刚开始每个样本权重都会被初始化为一样的,即
W
1
,
i
=
1
m
W_{1,i} = \frac{1}{m}
W1,i=m1,这样在第一步每个样本起的作用是相同的,注意整个算法中始终都有
∑
i
=
1
m
W
t
,
i
=
1
\sum_{i=1}^mW_{t,i} = 1
∑i=1mWt,i=1。
第2步b中,
e
t
=
P
(
G
t
(
x
i
)
=
̸
y
i
)
=
∑
i
=
1
m
W
t
,
i
⋅
I
(
G
t
(
x
i
)
=
̸
y
i
)
e_t = P(G_t(x_i) = \not y_i) = \sum_{i=1}^mW_{t,i}\cdot I(G_t(x_i) = \not y_i)
et=P(Gt(xi)≠yi)=∑i=1mWt,i⋅I(Gt(xi)≠yi),能够看出基分类器
G
t
(
x
)
G_t(x)
Gt(x)在训练集上的误差实际上是被
G
t
(
x
)
G_t(x)
Gt(x)误分类的样本的权重之和。
第2步c中,计算基分类器
G
t
(
x
)
G_t(x)
Gt(x)的系数
α
t
\alpha_t
αt,
α
t
\alpha_t
αt表示基分类器
G
t
(
x
)
G_t(x)
Gt(x)在最终的投票中所占的权重,从公式中能够看出,当
e
t
≤
1
2
e_t \leq \frac{1}{2}
et≤21时,
α
t
≥
0
\alpha_t \geq 0
αt≥0,而且
α
t
\alpha_t
αt随着
e
t
e_t
et的减小而增大,所以分类错误率越小的基分类器在最终投票的时候作用越大。
第2步d中,因为
y
∈
{
+
1
,
−
1
}
y\in \{+1,-1\}
y∈{+1,−1},所以
W
t
+
1
,
i
=
W
t
,
i
Z
t
e
x
p
(
−
α
t
y
i
G
t
(
x
i
)
)
W_{t+1,i} = \frac{W_{t,i}}{Z_t}exp(-\alpha_ty_iG_t(x_i))
Wt+1,i=ZtWt,iexp(−αtyiGt(xi))可以改写为:
W
t
+
1
,
i
=
{
W
t
,
i
Z
t
e
−
α
t
,
G
t
(
x
i
)
=
y
i
W
t
,
i
Z
t
e
α
t
,
G
t
(
x
i
)
=
̸
y
i
W_{t+1,i} = \left\{\begin{matrix} &\frac{W_{t,i}}{Z_t}e^{-\alpha_t},G_t(x_i) = y_i \\ \\ & \frac{W_{t,i}}{Z_t}e^{\alpha_t},G_t(x_i) = \not y_i \end{matrix}\right.
Wt+1,i=⎩⎪⎨⎪⎧ZtWt,ie−αt,Gt(xi)=yiZtWt,ieαt,Gt(xi)≠yi
所以能够看出如果样本被错误分类,则样本权值会被放大;反之,则会被缩小。
现在你已经对AdaBoost算法了解了,但是算法中似乎并未体现是怎么解决上面的疑问的:“对误分类样本权重加大了,在下一轮中是如何被重点关注的,具体怎么操作的”,从这个算法流程中并不能看出在下一轮中怎样关注被误分类的样本的。
答案其实是:AdaBoost的基分类器一般是个单层决策树(又叫decision stump,决策树桩。因为只有一次分裂过程,所以叫做树桩),在前面的决策树构造的博客里决策树(decision tree)(一)——构造决策树方法,我们知道决策树在分裂的时候会选择最优属性进行分裂,这里就是选择使得误差最小的那个属性进行分裂。也就是说AdaBoost在每次迭代会选择误差最小的那棵树。而从上面AdaBoost的算法中我们能够知道误差是由样本的权重决定的,上一轮被误分类的样本权重大,我们这里选择误差最小的那棵树,则必然决定了这棵树尽量把上一轮误分类的样本都分对,不然误差不会是最小的。
关于这一点无论是《西瓜书》还是《统计学习方法》都略过去了,导致很多初学者不清楚。不过《统计学习方法》里给出的例子体现了这一点。大家也可以看这个MIT的ppt:ADABOOST ALGORITHM,我把算法截个图贴上来:

或者大家看台大的这个ppt,会更清楚。Introduction to Adaptive Boosting
以上就是AdaBoost算法的思想,其实思想还是很直白的,但是Adaboost厉害的地方就在于把这些想法自然又有效地实现在一种算法里了。
二、AdaBoost的举例说明
接下来举个具体的例子,方便大家理解这个算法。例子来源于李航老师的《统计学习方法》,我会把每一步细化些,方便大家看的更清楚,基分类器使用决策树桩(decision stump),先看数据集:
| 样本 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 特征(x) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| label(y) | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
这里特征
x
x
x为连续值特征。
刚开始,样本的权重被初始化为
1
m
\frac{1}{m}
m1,这里
m
=
10
m=10
m=10:
D
1
=
(
w
11
,
w
12
,
.
.
.
.
,
w
110
)
,
w
1
i
=
0.1
,
i
=
1
,
2
,
.
.
.
,
10
D_1 = (w_{11},w_{12},....,w_{110}), w_{1i} = 0.1,i=1,2,...,10
D1=(w11,w12,....,w110),w1i=0.1,i=1,2,...,10
对
t
=
1
t=1
t=1,
(a)在样本权值分布为
D
1
D_1
D1的训练集上,最优的分裂点为
x
=
2.5
x=2.5
x=2.5,
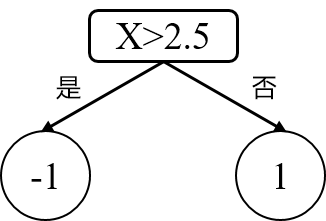
这里为什么是阈值取
2.5
2.5
2.5,为什么不是2.4,不是2.1,不是8.5,不是2.11111?
关于这个必须有个细节要说清楚,网上的博客大多你抄我我抄你,然后谁也没给解释为什么这样,不知道是他们本来就不明白,还是觉得太简单了不想说,没劲。个人觉得如果博客还想给别人看就应该把问题讲的清楚,也许他们自己本身也不明白,反正糊里糊涂就写上去了~
关于这一点网上很少有资料说明,李航的《统计学习方法》里也只说了阈值取2.5时分类误差率最低。那从那几个阈值里算出来的2.5最低,总归得是从一个有限个数的集合里算出来的吧。关于这个,先看多伦多大学计算机系上课用的课件是怎么说的吧(课件地址:http://www.cs.toronto.edu/~mbrubake/teaching/C11/Handouts/AdaBoost.pdf):

看黄线的部分,也就是说我们在特征里找阈值(分裂点)的时候,比如2,3,这之间有无数个点可以作为分裂点的,但是无论是哪个得到的决策树桩都是一样的,所以你如果开心你取2.123232131313实际上和取2.5是一样的。因此为了方便,我们就取中间值吧,因此从上面的数据集我们可以得到的候选分裂点集合为 { 0.5 , 1.5 , 2.5 , 3.5 , 4.5 , 5.5 , 6.5 , 7.5 , 8.5 } \{0.5,1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5\} {0.5,1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5},解决了这个问题后,我们来算一算为何取2.5:
- 若取0.5,则 x < 0.5 x<0.5 x<0.5时,label为1, x > 0.5 x>0.5 x>0.5时,label也为1。(这个label的取值和决策树中一样,即看叶结点中哪个类别的样本多,就取哪个类别作为叶结点的标记),此时分类错误率为0.4。
- 若取1.5,则 x < 1.5 x<1.5 x<1.5时,label为1, x > 1.5 x>1.5 x>1.5时,label也为1(也可以是-1,数量一样随机选一个),分类错误率为0.4。
- 若取2.5,则 x < 2.5 x<2.5 x<2.5时,label为1, x > 2.5 x>2.5 x>2.5时,label为-1,分类错误率为0.3。
- 若取3.5,则 x < 3.5 x<3.5 x<3.5时,label为1, x > 3.5 x>3.5 x>3.5时,label为-1(也可以是1,数量一样随机选一个),分类错误率为0.4。
- 若取4.5,则 x < 4.5 x<4.5 x<4.5时,label为1, x > 4.5 x>4.5 x>4.5时,label也为1,分类错误率为0.4。
- 若取5.5,则 x < 5.5 x<5.5 x<5.5时,label为1(也可以是-1,数量一样随机选一个), x > 5.5 x>5.5 x>5.5时,label为1,分类错误率为0.4。
- 若取6.5,则 x < 6.5 x<6.5 x<6.5时,label为1, x > 6.5 x>6.5 x>6.5时,label也为1,分类错误率为0.4。
- 若取7.5,则 x < 7.5 x<7.5 x<7.5时,label为1, x > 7.5 x>7.5 x>7.5时,label也为1(也可以是-1,数量一样随机选一个),分类错误率为0.4。
- 若取8.5,则 x < 8.5 x<8.5 x<8.5时,label为1, x > 8.5 x>8.5 x>8.5时,label也为-1,分类错误率为0.3。
从上面能够发现其实取2.5和取8.5分类错误率一样都是0.3,为最低,此时任取一个,这里取了2.5。(a) 因此基分类器为:
G
1
(
x
)
=
{
1
,
x
<
2.5
−
1
,
x
>
2.5
G_1(x) = \left\{\begin{matrix} & 1, x < 2.5\\ & -1, x > 2.5 \end{matrix}\right.
G1(x)={1,x<2.5−1,x>2.5
(b)
G
1
(
x
)
G_1(x)
G1(x)在训练数据集上的误差率
e
1
=
P
1
(
G
1
(
x
i
)
=
̸
y
i
)
=
∑
i
=
1
10
w
1
i
I
(
G
1
(
x
i
)
=
̸
y
i
)
=
0.3
e_1=P_1(G_1(x_i)= \not y_i) = \sum_{i=1}^{10}w_{1i}I(G_1(x_i)= \not y_i) = 0.3
e1=P1(G1(xi)≠yi)=∑i=110w1iI(G1(xi)≠yi)=0.3。
(c) 计算
G
1
(
x
)
G_1(x)
G1(x)的系数:
α
1
=
1
2
l
o
g
1
−
e
1
e
1
=
0.4236
\alpha_1 = \frac{1}{2}log\frac{1-e_1}{e_1} = 0.4236
α1=21loge11−e1=0.4236。
(d) 更新训练数据的权值分布:
w
2
i
=
w
1
i
Z
1
e
x
p
(
−
α
1
y
i
G
1
(
x
i
)
)
,
i
=
1
,
2
,
.
.
.
10
w_{2i} = \frac{w_{1i}}{Z_1}exp(-\alpha_1y_iG_1(x_i)), i=1,2,...10
w2i=Z1w1iexp(−α1yiG1(xi)),i=1,2,...10
D
2
=
(
0.07143
,
0.07143
,
0.07143
,
0.07143
,
0.07143
,
0.07143
,
0.16667
,
0.16667
,
0.16667
,
0.07143
)
D_2 = (0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,0.16667,0.16667,0.16667,0.07143)
D2=(0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,0.16667,0.16667,0.16667,0.07143)
f
1
(
x
)
=
0.4236
G
1
(
x
)
f_1(x) = 0.4236G_1(x)
f1(x)=0.4236G1(x)
观察上面的权值 D 2 D_2 D2,能够发现基分类器 G 1 ( x ) G_1(x) G1(x)分错的三个样本 7 , 8 , 9 7,8,9 7,8,9的权值会比其他正确分类的样本权值大,这也使得在下一轮中,基分类器 G 2 ( x ) G_2(x) G2(x)会更加关注这三个样本,因为需要使 G 2 ( x ) G_2(x) G2(x)分类器误差最小,而误差是由 e t = P t ( G 1 ( x i ) = ̸ y i ) = ∑ i = 1 N w 1 i I ( G t ( x i ) = ̸ y i ) e_t=P_t(G_1(x_i)= \not y_i) = \sum_{i=1}^{N}w_{1i}I(G_t(x_i)= \not y_i) et=Pt(G1(xi)≠yi)=∑i=1Nw1iI(Gt(xi)≠yi) 计算得到的。
继续,再来看第二轮迭代时( t = 2 t=2 t=2),我们从第一次迭代时( t = 1 t=1 t=1)知道,样本权重为:
| 样本编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 权重 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.16667 | 0.16667 | 0.16667 | 0.07143 |
再来逐个看基分类器:
- 若取0.5,则 x < 0.5 x<0.5 x<0.5时,label为1, x > 0.5 x>0.5 x>0.5时,label也为1。此时样本3,4,5,9被分错,分类错误率为 0.07143*4=0.28572。
- 若取1.5,则 x < 1.5 x<1.5 x<1.5时,label为1, x > 1.5 x>1.5 x>1.5时,label也为1(注意此时label只能为1,因为为1的错误率小于为-1的错误率),分类错误率为分别为0.28572。
- 若取2.5,则 x < 2.5 x<2.5 x<2.5时,label为1, x > 2.5 x>2.5 x>2.5时,label为1(因为为1分类错率低于为-1),分类错误率为0.28572。
- 若取3.5,则 x < 3.5 x<3.5 x<3.5时,label为1, x > 3.5 x>3.5 x>3.5时,label为1,样本4,5,6,10被分错,分类错误率为0.28572。
- 若取4.5,则 x < 4.5 x<4.5 x<4.5时,label为1, x > 4.5 x>4.5 x>4.5时,label也为1,样本4,5,6,10被分错,分类错误率为0.28572。
- 若取5.5,则 x < 5.5 x<5.5 x<5.5时,label为1(也可以是-1,数量一样随机选一个), x > 5.5 x>5.5 x>5.5时,label为1,样本4,5,6,10被分错,分类错误率为0.28572。
- 若取6.5,则 x < 6.5 x<6.5 x<6.5时,label为1, x > 6.5 x>6.5 x>6.5时,label也为1,分类错误率为0.28572。
- 若取7.5,则 x < 7.5 x<7.5 x<7.5时,label为1, x > 7.5 x>7.5 x>7.5时,label也为1,分类错误率为0.28572。
- 若取8.5,则 x < 8.5 x<8.5 x<8.5时,label为1, x > 8.5 x>8.5 x>8.5时,label也为-1,分类错误率为0.07143*3=0.21429。
所以当阈值为8.5时,分类误差率最低。
相信这样大家就很清楚了,再往下就不介绍了,没啥难点了,直接按部就班的套公式就可以了。
一、AdaBoost在scikit-learn中的应用
sklearn中封装好了adaboost算法,我们可以直接调用,api地址:https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html,原来想介绍下用法的,但似乎也没啥好介绍的,相信大家也都看的明白。溜了,公司的事情还一大堆,emmm…
关于理论推导篇后面有时间会写~还有一大堆优先级比较高的事情要去做,平时实习,周末就两天时间,真的有点不够。。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









