








近期,公司的事情略少,于是乎开始钻研一下已经火了很久的模式识别,话说,每次公司的seminar都会提到深度学习啊,分类啊,我都像丈二的和尚,摸不着头脑。趁有时间,得补一补。
我应该先百度或谷歌一下,哪些入门材料,然后开始学习,blabla。。。
然并卵,我天性懒惰,不爱看一大堆一大堆的文字,既不生动,又显得十分枯燥。于是乎,我开始看ppt,图文并茂,重点的知识又列出来了。一个下午能刷几十页,成就感都油然而生。我就是这样,一直活在自欺自乐的世界里的。
好吧,言归正传,接下来我会从这个ppt入手,ppt不懂的再查找资料。每天记录一下当天的学习,希望哪天我真用的是的时候,能够捡的快。
http://wenku.baidu.com/link?url=MGIZmajpFKVUyJx-8BAmpvfqRG5WB2Bgw8XyePjBmGOtaEMZgKVDI11OL42jg9P1r1akvT7gv_43AXCTKwFkA5f2EXfMJ4IcPBLYhNDnVr7
貌似是清华大学的模式识别课程,没准还可以找到其他相关的信息呢!
嘿嘿,果然找到了,相关课程的视频,还有参考书目网上有哦!
http://www.icourses.cn/coursestatic/course_4366.html
参考书:《现代模式识别》
http://vdisk.weibo.com/s/aOL2uYMILo_qV
p42页这块,好长的公式啊,我一看到长串的公式心里就畏难。那么,这一块的内容,我先给它的提纲抽出来,然后逐个概念理解,发现也没有那么难。

Update by 2016.5.12
接下来我们来到第二章,聚类分析
正所谓人以类聚,物以群分,相同的人,因为他们有共同的特点,很容易聚在一起,聚类分析的目的,就是将相似的归为一类。
聚类过程的基本步骤如下:
特征选择,字面意思还比较好理解,而且不一样的分类任务,特征选取也有不一样的讲究,所以ppt没有专门讲这个点了。接下来时讲到模式相似性的测度。
模式相似性测度用于描述各模式之间特征的相似性程度。
主要分:
1.距离测度
两个矢量矢端的距离,常用的有

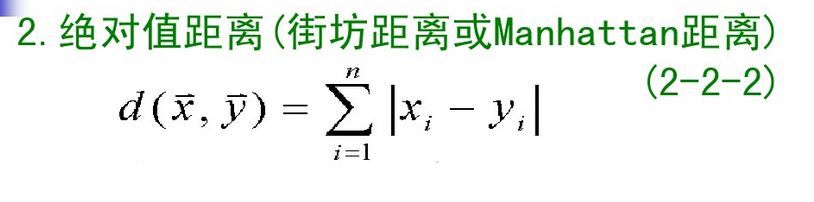



感觉马氏距离好像挺重要,又挺云里雾里的~
ppt中介绍了一个例子:

这个例子说明了,马氏距离比欧式距离更有效!
2.相似测度
3.匹配测度
update by 5.12
聚类的算法
分简单的聚类算法和动态聚类算法,简单聚类算法,由于聚类中心一旦确定,往往就不能改动,因此不容易得到较好的聚类效果,所以常用的聚类算法,多为动态聚类算法。
重点是C均值聚类和C均值聚类之改进
1)C均值聚类
上实例:
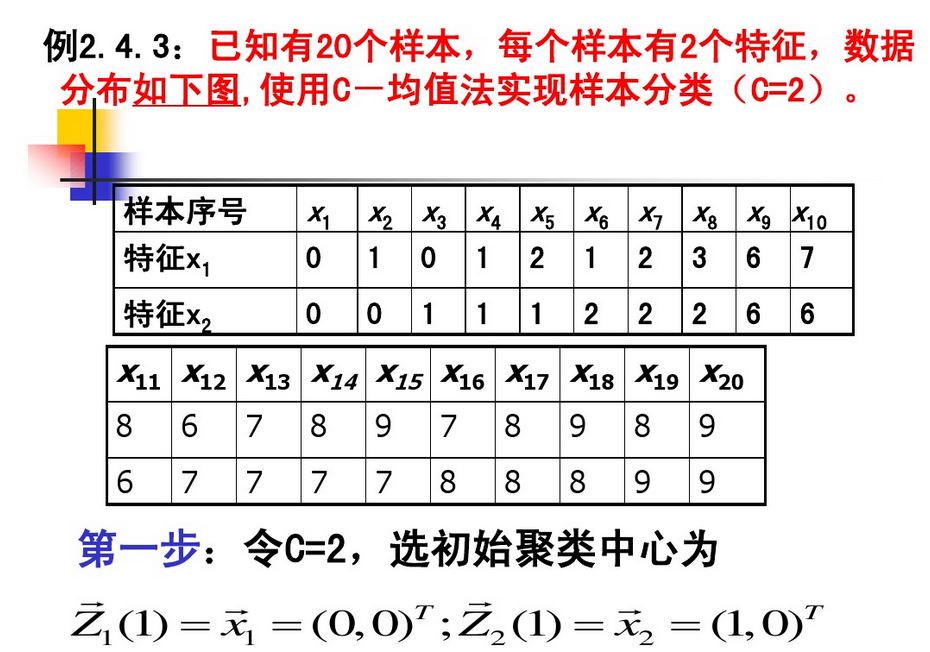
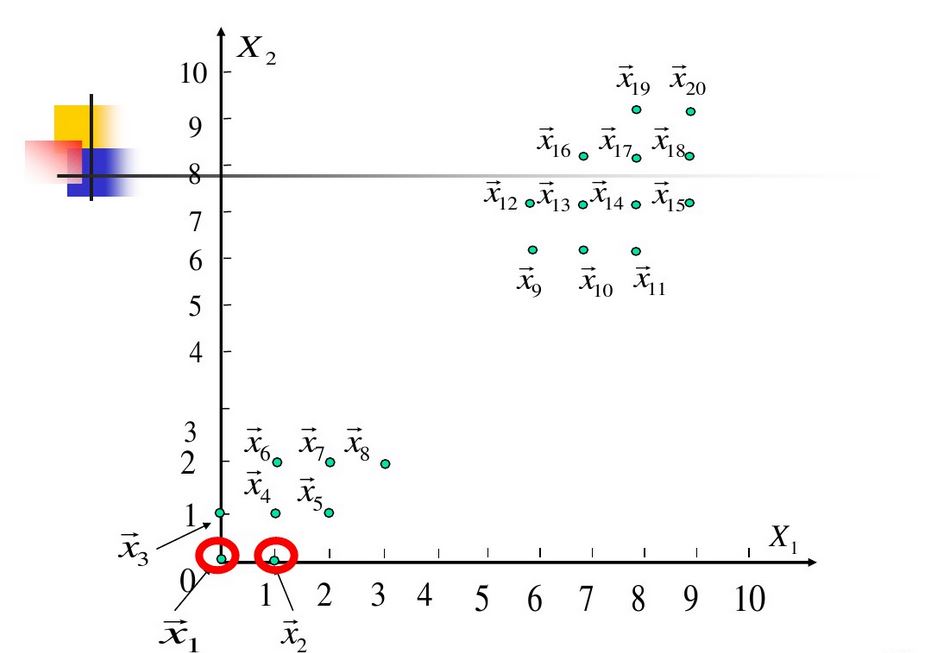
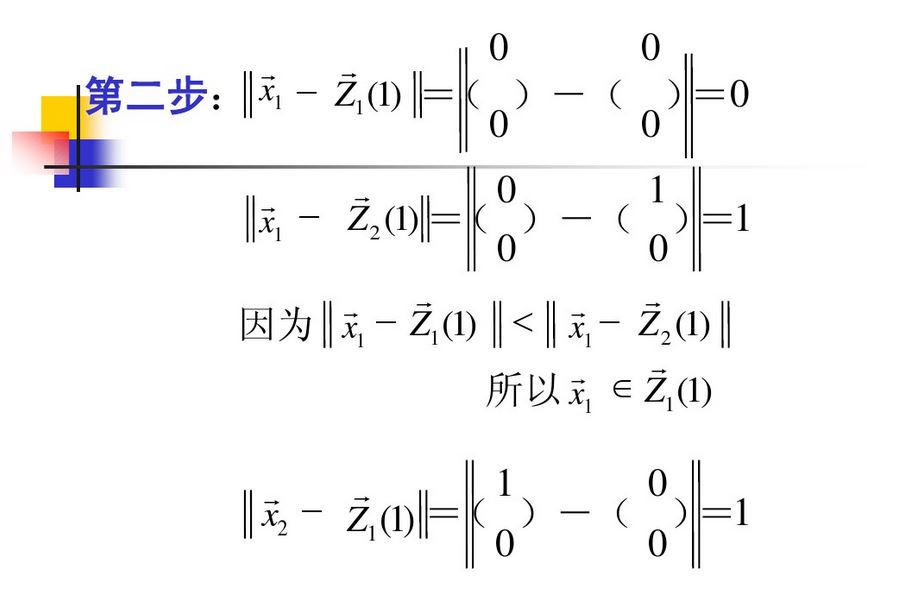




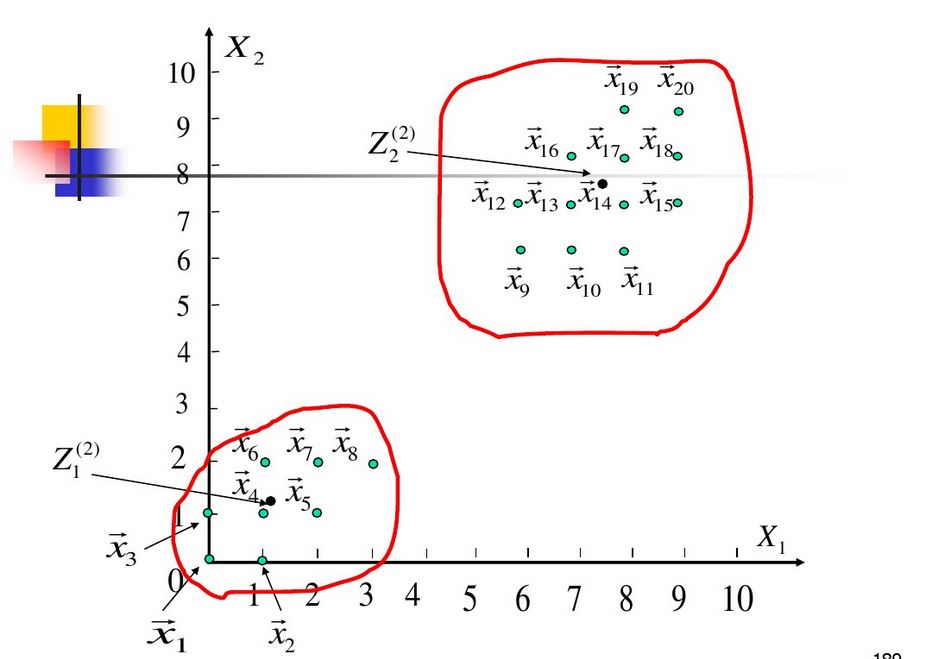

聚类中心不再改变,计算结束。
这个就是C均值聚类的流程,当模式分布呈现内内团聚状,C-均值算法是能达到很好的聚类结果,故应用较多。从算法的迭代过程看,C-均值算法是能使各模式到其所判属的类别中心距离(平方)之和最小的最佳聚类。
因为这个聚类中心的初始化是随机的嘛,所以,我想这个上面应该是有优化空间的。















 2119
2119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









