







之前的一篇博客中已经对Kinect的硬件架构有了一定的了解,本篇的内容主要是从产品设计、原理、软件算法、基础研究等角度去分析Kinect的内在奥秘。
3.1 产品设计&系统架构:
Kinect提供三大类的原始数据信息,包括深度数据流(Depth stream)、彩色数据流(color stream)、原始音频数据(raw audio stream),同时分别对应骨骼追踪(skeletal tracking)、身份识别(identify)、语音识别(speech pipeline)三个处理过程。
3.1.1 骨骼追踪的特点:
1)从Kinect Primesense芯片组获取深度数据流,通过USB2.0端口传输。
2)谁都能够人体分类的特征阈值,通过约定的字节编码,为每个被追踪的玩家在深度图像中创建分割遮罩。
3)将深度数据中出现的游戏玩家与背景图像分割,发现玩家。
4)通过机器学习的结果,快速对人体部位进行分类。
5)通过机器学习的结果,从人体部位进一步识别关节点三维坐标,从而对人体骨骼三维建模。
3.1.2 身份识别的特点:包括动作识别和人脸识别两部分
1)从彩色摄像头获得视频流信息,通过USB2.0端口传输。
2)玩家面具器官被分解成关键性的面部标志,通过彩色视频信息的特征采样进行人脸匹配。
3)为了提高识别精度和效率,同时结合人的着装信息,身高等因素进行匹配。
4)玩家用户信息被识别,并从关联数据库中被检索。
3.1.3 语音识别的特点:
1)从麦克风阵列中获取原始音频信息,通过USB2.0端口传输。
2)根据特定算法进行多通道回声消除、回声一直,适应玩家与Kinect麦克风一定距离及室内空旷回声等情况。
3)通过波束成型等机制,进行声源定位。
4)通过噪声抑制等机制,自动过滤环境噪声。
5)语音命令识别。
3.2 Kinect关键技术特性可以归纳为如下四点:骨骼追踪、动作识别、人脸识别、语音识别
3.2.1、骨骼追踪
骨骼追踪要求系统在允许的延时范围内,快速构建用户的躯干、肢体、头部甚至手指。其中涉及以下三个关键点:
1)压缩感知:如何从深度图像中抛弃背景图像信息,把人体骨骼抽象出来,是一个关键的工作,通过一个像素一个像素的识别工作,系统会通过机器学习和模式识别来压缩感知,处理这些原始数据。
2)骨骼关节:关节点连线在一起就是一个火柴人,关节点越多,骨骼就越真实。
3)关节点的精度问题
1、激光散斑测距采样的精度;
2、红外摄像头的采样分辨率和频率(比如Kinect深度图像默认为每秒30帧,320×240的分辨率);
3、通过深度图构建骨骼数据的延时;
Kinect深度图像采样频率并不是产生延迟进而使得空间精度下降的主因,延迟的主因是芯片处理速度和软件识别处理速度不够。
3.2.2、动作识别
动作识别的基础是骨骼追踪,包括肢体运动、手势以及静态姿势。可以把动作抽象为骨骼关节点的状态或运动序列。动作识别包含两个层次的概念:
1、骨骼在某一时间点的状态,是为静态的遏姿势。
2、骨骼中的某一关节或是多个关节点在空间的运动序列,是为动态的行为。
显然动态的行为分析比静态的姿势识别要复杂的多。
3.2.3、人脸识别
人脸识别是在整个身份识别中最重要的一个组成部分,与骨骼追踪类似,第一步首先定位人脸的存在,其次基于人的脸部特征,对输入的人脸图像或者视频流进行进一步的分析,包括脸的位置、大小和各个主要面部器官的位置信息,并根据这些信息,进一步提取每个人脸中所蕴含的身份特征,并将其与意志的人脸进行对比,从而识别每个人的身份。Kinect的人脸识别采用了抽取人脸中层结构特征的折中方式,是基于彩色摄像头的信息,属于纯二维的图片识别算法,并没有用到深度数据。
3.2.4、语音识别
语音识别包括很多层次的技术,如最简单的“语音命令”、声音特征识别、语种识别、分词、、语气语调情感探测等多个方面。Kinect麦克风阵列捕获的音频数据流通过音频增强效果算法来屏蔽环境噪声。阵列技术包含有效的噪声消除和回波抑制算法,同时采用波束成形技术通过每个独立设备的响应时间确定音源位置,并尽可能避免环境噪声的影响。Kienct的语音识别仅仅定位在简单的“语音命令”的层次。
3.3 Kinect眼中的三维世界:
Kinect眼中的世界包括彩色摄像头看到的人物、用户分割后的深度图像、基于“像素级”的分析推测出来的人体部位,以及最终得到的人体关节点。
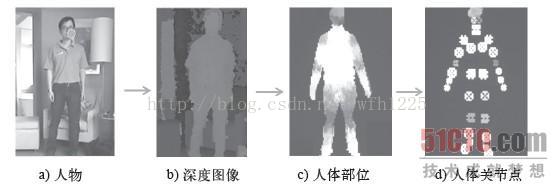
3.3.1、深度数据是Kinect的精髓
Kinect的核心数据也是属于计算机视觉范畴,只不过它们分析的不是彩色图像,而是目标物体的深度数据。环境光照、衣服颜色、肤色对骨骼追踪是没有影响的。Kinect的每一帧深度图像,其每一个像素点的数值都表达目标物体与Kinect摄像头的距离,因此可以利用Kinect深度数据来构建周边环境三维信息。
对于Kinect256灰阶的单色深度图,纯黑代表距离已经超过Kinect最远可视距离,纯白代表比Kinect最近可是范围还近,黑白间的灰色地带对应物体到传感器的物理距离。
3.4 Kinect深度成像原理
Kinect有发射、捕捉、计算视觉重现的类似过程。严格来说,Kinect的“深度眼睛”是由一个红外投影机和红外摄像头组合而成的,投影和接收互为重叠。
3.4.1 TOF光学测距和结构光测量
TOF (Time of Flight)基于飞行时间原理的摄像头,它通过测量光脉冲之间的传输延迟时间来计算深度信息。
结构光测量:基于光编码,投射已知的红外模式到场景中,通过另外一个红外CMOS成像器所捕捉到的该模式的变形,从而最终来确定深度信息的摄像头,Kinect就是属于此种。“结构光”是指一些具有特定模式的光,其模式图案可以是点、线、面等。结构光扫描法的原理是首先将结构光投射至物体表面,再使用摄像机接受该物体表面反射的结构光图案,由于接受图案必会因为物体的立体形状不同而发生变形,故可以试图通过该图案在摄像机上的位置和形变程度来计算物体表面的空间信息。普通的结构光方法仍然是部分采用了三角测距原理的深度计算。
3.4.2 Light Coding技术
PrimeSense将其深度测量技术命名为Light Coding,顾名思义,就是用光源照明给需要测量的空间编上码,属于结构光技术的一种,只是深度计算方式不一样,Kinect深度图像就是才采用了这种技术。
与结构光技术不同的是,Light Coding的光源称为激光散斑,是激光照射到粗糙物体或者穿透毛玻璃后随即形成的衍射斑点。这些散斑具有高度的随机性,而且会随着距离的不同而变换图案。也就是说空间中任意两处的散斑图案都是不同的,只要在空间中打上这样的结构光,整个空间都被做了标记,把一个物体放进这个空间,只要看看物体上面的散斑图案,就可以知道这个物体在什么位置了。当然,在这之前要把整个空间的散斑图案都记录下来,所以要先做一次光源标定。
概括下,Light Coding与传统的TOF、结构光技术的不同之处在于:
1)使用“Light Coding”技术的PrimeSense的PS1080系统级芯片负责对红外光源进行控制,投射出具有三维纵深的立体编码,这种光源称为激光散斑,是当激光照射到粗糙物体或穿透毛玻璃后形成的随机衍射斑点。
2)不需要特制的感光芯片。
3)Light Coding技术不是通过空间几何关系求解的,它的测量精度只是和标定时取的参考面的密度有关,参考面越密测量越精确。
3.4.3 激光散斑原理
激光在散射体表面的漫反射或通过一个透明散射体(如毛玻璃)时,在散射表面或附近的光场中可以观察到一种无规则分布的亮暗斑点,这中斑点成为激光散斑(Laser Speckles)。激光散斑是由无规则散射体被相干光照射产生的,因此是一种随机过程。最重要的特点就是,这种散斑具有高度的随机性,而且随着距离的不同会出现不同的图案,也就是说,在同一空间中任何两个地方的散斑图案都不相同。只要在空间中打上这样的结构光然后加以记忆就让整个空间都像是被做了标记,然后把一个物体放入这个空间后需要从物体的散斑图案变化就可以知道这个物体的具体位置。
3.4.4 光源标定
每隔一段距离,取一个参考平面,把参考平面上的散斑图案记录下来。标定的间距越小,精度越高。所以很好理解Kinect注意事项中的警告:不要让阳光直射传感器,不要让传感器接近任何热源。因为Kinect透射出近红外光源,通过膜表物体产生的散斑进行深度计算,太阳光谱和热源会干扰Kinect投射出的近红外光源。这个在以下的两篇专利中有体现:
Range mapping using speckle decorrelation(No.US7433024B2)和DEPTH MAPPING USING PROJECTED PATTERNS(No.0118123 A1)
3.5 从深度图像到骨骼图
Kinect现在已经可以看到三维世界了,下一步探讨如何从深度图像生成骨骼图。
3.5.1 动静分离,识别人体
识别人体的第一步是从深度图像中将人体北京从环境中区分出来。Kinect首先分析比较接近传感器的区域,这也是最有可能是人体的目标,其次会逐点扫描这些区域深度图像的像素,来判断属于人体的哪些部位。这个过程主要包括边缘检测、噪声阈值处理、对人体目标特征点的分类等环节。
3.5.2 人体部位分类
之前的工作室对人体与背景的分离。现在的目标就是从深度图像中将人体的各个部位识别出来,Kinect的机器学习有32个不同人体部位。
3.5.3 从人体部位识别关节
系统根据骨骼追踪的20个关节点来生成一副骨架系统。通过这种方式能够基于充分的信息最准确的评估人体实际所在位置。骨骼识别能够兼容不同身高的人体,除了站姿之外,还可以分辨出坐立在椅子上或沙发上的人体。Kinect总是先识别人体部位进而再推断出关节点,这是一个近似度匹配、评估的过程:逐个像素扫描,先局部再总体。
3.5.4 Kinect大脑——骨骼追踪的机器学习技术
Kinect通过红外摄像头看到三维的世界后,将这部分深度数据传输到Kinect大脑去处理,接着深度图像的每一个像素会被进行分析评估,其特征变量都会被分类,在一个成为随机决策库中进行搜索,来判断它是属于人体的那个部位,这是一个概率推测的过程。Kinect SDK中并不含有存储一个人体部位与动作姿态的数据库,只有提炼过的人体部位特征信息以及最终训练结果的决策树。
3.5.5 骨骼追踪的精度与效率
Kinect的骨骼追踪就是给每个玩家穿上动作捕捉的Marker点,Kinect的硬件采集、芯片处理不是延迟的主因,软件处理是主要考验的环节。根据第三方的测试数据,Kinect对于在2m左右范围的物体而言,X和Y维度上的空间精度是3mm,Z维度上的空间精度为1cm。
3.6 创建你的Avatar
Kinrct可以识别追踪声音和肢体语言,其对于面部表情也能识别,通过Kinect Avatat服务可以得到与真人对应的卡通形象。Avatar在人体骨骼基础上进一步丰满肢体。受到Kinect成本限制的原因,深度图像分辨率不高,人体经过Kinect扫描所得的深度图凹凸不平。传统的图像处理方法中使用中值滤波这种非线性平滑技术来保护边缘信息,而Kinect采用了泊松方程等算法进行噪声滤波,使得粗糙变平滑、缺陷能够自动对齐。
总结:本章分析了Kinect的工作原理,重点分析了体感操作的部分。Kinect骨骼跟踪是重点分析的内容,充分体现了当今计算机图形视觉的高水准技术。首先从Kinect的产品设计和应用场景谈起,从中归纳出关键技术特征;其次结合激光散斑原理来讲述红外摄像头和Light Coding技术。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









