









cvCreateCARTClassifier函数在haartraining程序中用于创建CART树状弱分类器,但一般只采用单一节点的CART分类器,即桩分类器,一个多节点的CART分类器训练耗时很多。根据自己的测试,要等差不多10分钟(2000正样本、2000负样本)才能训练完一个3节点的弱分类器,当然,总体的树状弱分类器的数目可能也会减少1/2。之所以将此函数拿出来说说,主要是因为在网上找不到针对这个函数的详细说明,同时,CART的应用十分广泛,自己也趁这个机会好好学学,把自己的一点理解分享给大家。
1. 先说说CART树的设计问题,也就是CvCARTClassifier这个结构体,结构体中变量的意义着实让我伤了一番脑筋。现添加其变量含义,如下:
typedef struct CvCARTClassifier
{
CV_CLASSIFIER_FIELDS()
/* number of internal nodes */
int count; // 非叶子节点个数
/* internal nodes (each array of <count> elements) */
int* compidx; // 节点所采用的最优Haar特征序号
float* threshold; // 节点所采用的最优Haar特征阈值
int* left; // 非叶子节点的左子节点序号(叶子节点为负数,非叶子节点为正数)
int* right; // 非叶子节点的右子节点序号(叶子节点为负数,非叶子节点为正数)
/* leaves (array of <count>+1 elements) */
float* val; // 叶子节点输出置信度
} CvCARTClassifier;2. cvCreateCARTClassifier中节点分裂的“候选属性集合”仍旧是Haar特征,“分类准则”是分类错误率(error)的下降程度,这个函数中分类准则的具体度量是:父节点的子节点自身的error减去 该子节点的两个子节点的error之和,这个变量在代码中由errdrop表示。
3. CART树状分类器的形式多种多样,就3个非叶子节点来说,我调试之后,就遇到了如下两种弱分类器:
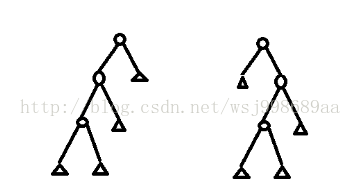
4. 不过,该函数的节点添加方式和普通的cart树有所不同,多了一步对左右两个子节点分裂进一步筛选的过程。这点我还没有参透作者的用意,我的意思是,如果不筛选,有何不妥?
5. 可能有童鞋会问,为什么要采用树状的弱分类器,我的理解是,一个树状的分类器在测试过程中,特征比较的次数相对串行的弱分类器要少很多,比如说,3个串行的Haar特征,比较次数是3次,但是如果是一颗3节点的CART树,比较次数可能只需要两次。并且, 一个树状弱分类器中,子节点针对的数据集更加具体,具有针对性,可能精度会更高。
以上就是自己对cvCreateCARTClassifier函数的理解,带有注释的源代码如下所示:
(转载请注明:http://blog.csdn.net/wsj998689aa/article/details/43411809)
CV_BOOST_IMPL
CvClassifier* cvCreateCARTClassifier( CvMat* trainData, // 训练样本特征值矩阵
int flags, // 样本按行排列
CvMat* trainClasses, // 训练样本类别向量
CvMat* typeMask,
CvMat* missedMeasurementsMask,
CvMat* compIdx, // 特征序列向量
CvMat* sampleIdx, // 样本序列向量
CvMat* weights, // 样本权值向量
CvClassifierTrainParams* trainParams ) // 参数
{
CvCARTClassifier* cart = NULL; // CART树状弱分类器
size_t datasize = 0;
int count = 0; // CART中的节点数目
int i = 0;
int j = 0;
CvCARTNode* intnode = NULL; // CART节点
CvCARTNode* list = NULL; // 候选节点链表
int listcount = 0; // 候选节点个数
CvMat* lidx = NULL; // 左子节点样本序列
CvMat* ridx = NULL; // 右子节点样本序列
float maxerrdrop = 0.0F;
int idx = 0;
// 设置节点分裂函数指针
void (*splitIdxCallback)( int compidx, float threshold,
CvMat* idx, CvMat** left, CvMat** right,
void* userdata );
void* userdata;
// 设置非叶子节点个数
count = ((CvCARTTrainParams*) trainParams)->count;
assert( count > 0 );
datasize = sizeof( *cart ) + (sizeof( float ) + 3 * sizeof( int )) * count +
sizeof( float ) * (count + 1);
cart = (CvCARTClassifier*) cvAlloc( datasize );
memset( cart, 0, datasize );
cart->count = count;
// 输出当前样本的置信度
cart->eval = cvEvalCARTClassifier;
cart->save = NULL;
cart->release = cvReleaseCARTClassifier;
cart->compidx = (int*) (cart + 1); // 非叶子节点的最优Haar特征序号
cart->threshold = (float*) (cart->compidx + count); // 非叶子节点的最优Haar特征阈值
cart->left = (int*) (cart->threshold + count); // 左子节点序号,包含叶子节点序号
cart->right = (int*) (cart->left + count); // 右子节点序号,包含叶子节点序号
cart->val = (float*) (cart->right + count); // 叶子节点输出置信度
datasize = sizeof( CvCARTNode ) * (count + count);
intnode = (CvCARTNode*) cvAlloc( datasize );
memset( intnode, 0, datasize );
list = (CvCARTNode*) (intnode + count);
// 节点分裂函数指针,一般为icvSplitIndicesCallback函数
splitIdxCallback = ((CvCARTTrainParams*) trainParams)->splitIdx;
userdata = ((CvCARTTrainParams*) trainParams)->userdata;
// R代表样本按行排列,C代表样本按列排列
if( splitIdxCallback == NULL )
{
splitIdxCallback = ( CV_IS_ROW_SAMPLE( flags ) )
? icvDefaultSplitIdx_R : icvDefaultSplitIdx_C;
userdata = trainData;
}
// 创建CART根节点
intnode[0].sampleIdx = sampleIdx;
intnode[0].stump = (CvStumpClassifier*)
((CvCARTTrainParams*) trainParams)->stumpConstructor( trainData, flags,
trainClasses, typeMask, missedMeasurementsMask, compIdx, sampleIdx, weights,
((CvCARTTrainParams*) trainParams)->stumpTrainParams );
cart->left[0] = cart->right[0] = 0;
// 创建树状弱分类器,lerror或者rerror不为0代表着当前节点为非叶子节点
listcount = 0;
for( i = 1; i < count; i++ )
{
// 基于当前节点弱分类器阈值,对当前节点进行分裂
// 留意lidx和ridx,它们指的是左右子节点各自的样本序列
splitIdxCallback( intnode[i-1].stump->compidx, intnode[i-1].stump->threshold,
intnode[i-1].sampleIdx, &lidx, &ridx, userdata );
// 为分裂之后的非叶子节点计算最优特征
if( intnode[i-1].stump->lerror != 0.0F )
{
// 小于阈值的样本集合
list[listcount].sampleIdx = lidx;
// 基于新样本集合寻找最优特征
list[listcount].stump = (CvStumpClassifier*)
((CvCARTTrainParams*) trainParams)->stumpConstructor( trainData, flags,
trainClasses, typeMask, missedMeasurementsMask, compIdx,
list[listcount].sampleIdx,
weights, ((CvCARTTrainParams*) trainParams)->stumpTrainParams );
// 计算信息增益(这里是error的下降程度)
list[listcount].errdrop = intnode[i-1].stump->lerror
- (list[listcount].stump->lerror + list[listcount].stump->rerror);
list[listcount].leftflag = 1;
list[listcount].parent = i-1;
listcount++;
}
else
{
cvReleaseMat( &lidx );
}
// 同上,左分支换成右分支,偏向于右分支
if( intnode[i-1].stump->rerror != 0.0F )
{
list[listcount].sampleIdx = ridx;
list[listcount].stump = (CvStumpClassifier*)
((CvCARTTrainParams*) trainParams)->stumpConstructor( trainData, flags,
trainClasses, typeMask, missedMeasurementsMask, compIdx,
list[listcount].sampleIdx,
weights, ((CvCARTTrainParams*) trainParams)->stumpTrainParams );
list[listcount].errdrop = intnode[i-1].stump->rerror
- (list[listcount].stump->lerror + list[listcount].stump->rerror);
list[listcount].leftflag = 0; // 辨识当前节点是左还是右
list[listcount].parent = i-1;
listcount++;
}
else
{
cvReleaseMat( &ridx );
}
if( listcount == 0 ) break;
idx = 0;
maxerrdrop = list[idx].errdrop;
for( j = 1; j < listcount; j++ )
{
if( list[j].errdrop > maxerrdrop )
{
idx = j; // 这里被忽略了,树中真正的节点是由idx决定的
maxerrdrop = list[j].errdrop;
}
}
// 添加新节点
intnode[i] = list[idx];
// 确定当前节点的非叶子子节点的序号
if( list[idx].leftflag )
{
cart->left[list[idx].parent] = i;
}
else
{
cart->right[list[idx].parent] = i;
}
// 此处需要注意,将候选集合中的选定节点删除,删除位置用倒数第二个候选节点替代
if( idx != (listcount - 1) )
{
list[idx] = list[listcount - 1];
}
listcount--;
}
// 这段代码用于确定树中节点最优特征序号、阈值与叶子节点序号和输出置信度
// left与right大于等于0,为0代表叶子节点
// 就算CART中只有一个节点,仍旧需要设置叶子节点
j = 0;
cart->count = 0;
for( i = 0; i < count && (intnode[i].stump != NULL); i++ )
{
cart->count++;
cart->compidx[i] = intnode[i].stump->compidx; // haar特征的序号
cart->threshold[i] = intnode[i].stump->threshold;
// 确定叶子序号与叶子的输出置信度
if( cart->left[i] <= 0 )
{
cart->left[i] = -j;
cart->val[j] = intnode[i].stump->left; // 这个left是float值,不是CVMat*
j++;
}
if( cart->right[i] <= 0 )
{
cart->right[i] = -j;
cart->val[j] = intnode[i].stump->right;
j++;
}
}
// 后续处理
for( i = 0; i < count && (intnode[i].stump != NULL); i++ )
{
intnode[i].stump->release( (CvClassifier**) &(intnode[i].stump) );
if( i != 0 )
{
cvReleaseMat( &(intnode[i].sampleIdx) );
}
}
for( i = 0; i < listcount; i++ )
{
list[i].stump->release( (CvClassifier**) &(list[i].stump) );
cvReleaseMat( &(list[i].sampleIdx) );
}
cvFree( &intnode );
return (CvClassifier*) cart;
}这段程序有些细节我可能没有理解正确,比如说左右分支的error同时不为0时,我的解释是程序将右分支的优先级设置的更高些,就是一个可能出错的地方,还想与童鞋们一起探讨,谢谢!
后记:上面那个结论的确是说错了,左右分支的优先级一样。这个函数后来又看过一次,感觉对代码又有了重新的认识,将自己之前犯过的错误重新修订,继续分享给大家,谢谢朋友们继续挑我的毛病,感激不尽!















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









