







写在前面的话
在聚类问题中,我们给定一个训练集,算法根据某种策略将训练集分成若干类。在监督式学习中,训练集中每一个数据都有一个标签,但是在分类问题中没有,所以类似的我们可以将聚类算法称之为非监督式学习算法。这两种算法最大的区别还在于:监督式学习有正确答案,而非监督式学习没有。
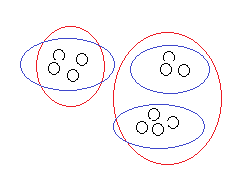
比如上面这个训练集,非监督式学习有可能将它分成两类也可能是三类,到底哪种分类正确,因情况而定;有时候即便是给定了情况也不见得就能确定。但是监督式学习就完全不一样。可能随着学习的深入我们的理解会更加的深刻。
算法基本内容
算法的核心目标就是将给定的数据集分成k类,具体做法为:
1、随机选取k个簇中心(cluster centroids)记为
μ 1 ,μ 2 ,...,μ k ∈R n
2、重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类
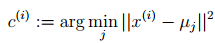
对于每一个类j,重新计算该类的质心
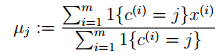
}
K是我们事先给定的聚类数,
c (i)
代表样本i与k个簇中距离最近的那个簇的下标,
c (i)
的值是1到k中的一个。质心
μ j
代表我们对属于同一个类的样本中心点的猜测。程序就这样反复进行直到收敛或者簇中心基本不动。
算法过程可以如下图示意,其中k取2:
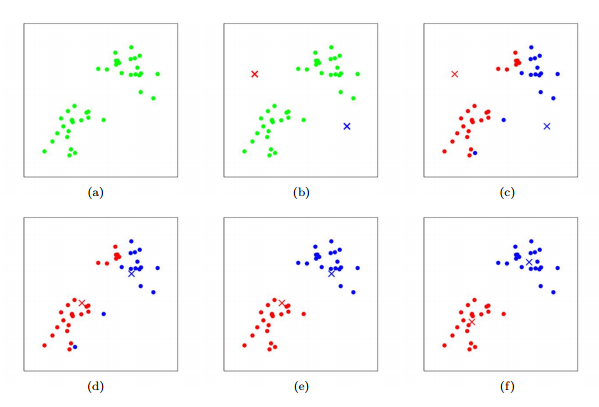
K-means面对的一个重要问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下:
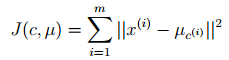
J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个簇中心
μ j
,调整每个样例的所属的类别
c (i)
来让J函数减少,同样,固定
c (i)
,调整每个簇中心
μ j
也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,
μ
和
c
也同时收敛。(在理论上,可以有多组不同的
如果畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对簇中心初始位置的选取比较敏感,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的
算法优点
K-Means聚类算法的优点主要集中在:
1. 算法快速、简单;
2. 对大数据集有较高的效率并且是可伸缩性的;
3. 时间复杂度近于线性,而且适合挖掘大规模数据集。K-Means聚类算法的时间复杂度是O(nkt) ,其中n代表数据集中对象的数量,t代表着算法迭代的次数,k代表着簇的数目。
算法缺点
k-means 算法缺点
1. 在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。这也是 K-means 算法的一个不足。有的算法是通过类的自动合并和分裂,得到较为合理的类型数目 K,例如 ISODATA 算法。关于 K-means 算法中聚类数目K 值的确定在文献中,是根据方差分析理论,应用混合 F统计量来确定最佳分类数,并应用了模糊划分熵来验证最佳分类数的正确性。在文献中,使用了一种结合全协方差矩阵的 RPCL 算法,并逐步删除那些只包含少量训练数据的类。而文献中使用的是一种称为次胜者受罚的竞争学习规则,来自动决定类的适当数目。它的思想是:对每个输入而言,不仅竞争获胜单元的权值被修正以适应输入值,而且对次胜单元采用惩罚的方法使之远离输入值。
2. 在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,这也成为 K-means算法的一个主要问题。对于该问题的解决,许多算法采用遗传算法(GA),例如文献中采用遗传算法(GA)进行初始化,以内部聚类准则作为评价指标。
3. 从 K-means 算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。所以需要对算法的时间复杂度进行分析、改进,提高算法应用范围。在文献中从该算法的时间复杂度进行分析考虑,通过一定的相似性准则来去掉聚类中心的侯选集。而在文献中,使用的 K-means 算法是对样本数据进行聚类,无论是初始点的选择还是一次迭代完成时对数据的调整,都是建立在随机选取的样本数据的基础之上,这样可以提高算法的收敛速度。
参考资料
1.ISODATA算法http://www.cnblogs.com/huadongw/p/4101422.html
2.Andrew Ng老师的斯坦福公开课
3.百度百科:K-means
end
















 6620
6620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









