







 本文从最大间隔分类器的角度探讨支持向量机(SVM),介绍了线性可分与线性分类器的概念,以及如何通过最大化间隔优化分类效果。通过引入松弛变量,SVM能够处理异常点并提升泛化能力。SVM的良好泛化能力源于其寻找最大化间隔的超平面策略。
本文从最大间隔分类器的角度探讨支持向量机(SVM),介绍了线性可分与线性分类器的概念,以及如何通过最大化间隔优化分类效果。通过引入松弛变量,SVM能够处理异常点并提升泛化能力。SVM的良好泛化能力源于其寻找最大化间隔的超平面策略。
“横看成岭侧成峰,远近高低各不同。”
支持向量机(Support Vector Machine, SVM)作为一个被广泛应用的有监督机器学习算法,网络上对它的介绍数不胜数,其中更有不少好文佳作。本文与它们的区别在于:并不着重于“教程式”地对SVM进行系统性介绍,而是希望从三个不同的角度对这个算法进行探究。我相信经过这番“把玩”,看过你会跟我一样觉得:机器学习真的是好玩!
1、引言
最大化类间间隔分类器(maximum margin classifier),估计是最为直观,也是最为人们所熟悉的对于SVM的理解。我们不妨也先从这个角度切入,看看为什么SVM能给我们带来优良的泛化能力。这一部分的路线图如下:
2、线性可分和线性分类器
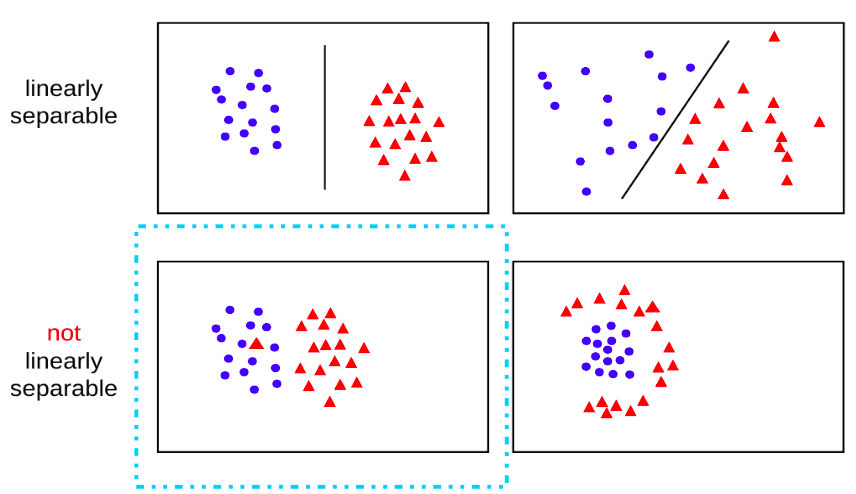
对于一个二分类问题,如果存在至少一个超平面能够将不同类别的样本分开,我们就说这些样本是线性可分的(linear separable)。所谓超平面,就是一个比原特征空间少一个维度的子空间,在二维情况下就是一条直线,在三维情况下就是一个平面。
线性分类器(linear classifier)是一类通过将样本特征进行线性组合来作出分类决策的算法,它的目标就是找到一个如上所述能够分割不同类别样本的超平面。这样在预测的时候,我们就可以根据样本位于超平面的哪一边来作出决策。
用数学语言来描述,一个线性函数可以简单表示为: f(x)=wTx+b ,而线性分类器则根据线性函数的结果进行分类决策:
即分类的结果由 f(x) 的符号决定, f(x)=wTx+b=0 即为分类超平面。
下图展示了几个线性可分/不可分的例子,并且画出了一个可能的分类超平面:
3、最大化间隔
在样本线性可分的情况下,可行的分类超平面可能会有很多,如下图的 L1 、 L2 和 L3 。
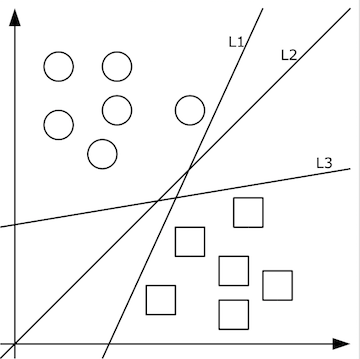
那么怎么选择一个最好的呢?从上图我们可以直观看出, L2 比另外两条分界线要更好,这是因为 L2 离样本的距离更远一些,让人觉得确信度更高。这好比人(相当于样本)站在离悬崖边(分类边界)越远,人就会感到越安全(分类结果是安全还是危险)。从统计的角度讲,由于正负样本可以看作从两个不同的分布随机抽样而得,若分类边界与两个分布的距离越大,抽样出的样本落在分类边界另一边的概率就会越小。
SVM正是基于这种直观思路来确定最佳分类超平面的:通过选取能够最大化类间间隔的超平面,得到一个具有高确信度和泛化能力的分类器,即最大间隔分类器。
3.1、间隔
既然SVM的目标是最大化间隔,我们便要先对“间隔”进行定义。所谓间隔,就是分类超平面与所有样本距离的最小值,表示为:
假设任意一个样本点 x0 ,其在分类超平面上的投影记作 x̂
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









