







 本文介绍了一种有监督的图像检索哈希方法,通过深度学习来学习图像表示和哈希函数。该方法包括两个阶段:近似哈希码学习和图像特征表示及哈希函数学习。利用卷积神经网络(CNN),该方法在图像检索性能上优于传统基于手工设计特征的方法。
本文介绍了一种有监督的图像检索哈希方法,通过深度学习来学习图像表示和哈希函数。该方法包括两个阶段:近似哈希码学习和图像特征表示及哈希函数学习。利用卷积神经网络(CNN),该方法在图像检索性能上优于传统基于手工设计特征的方法。
Supervised Hashing for Image Retrieval via Image Representation Learning
背景
最邻近搜索,是给定一个query,返回空间中距离query最近的点。最直接暴力的方法就是计算查询与特征空间的距离,并按照从小到大的顺序进行排序,返回结果。但是采取这种方法,存储的空间消耗比较大,并且查询时间慢。拿互联网的图片为例,数据规模基本都是上亿级别。如果采取遍历上亿级别的图片,然后返回最小距离的结果,那么用户等的花都谢了。为了解决上述问题,近年来ANN搜索技术发展迅速,对空间和时间的需求也大大降低。其中Hash就是一种代表性的方法。
Hash的目标是相似的特征映射到相近的区域,不相近的特征尽可能映射到远的区域。如下图所示:
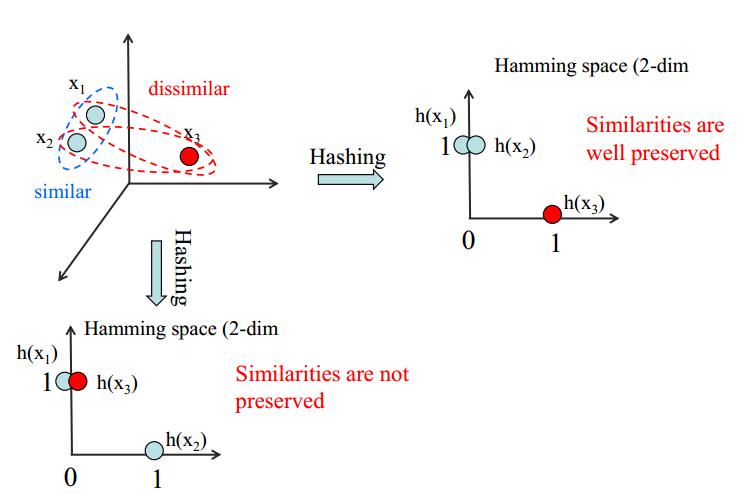
在Hash算法中,通常就是将样本表示为一串固定长度的二值编码,使得相似的样本具有相似的二值编码(编码之间的hamming距离小)。最起初的工作,主要工作是在特征空间中随机选择一些超平面对空间进行划分,根据样本在超平面的哪一侧决定每一个bit的值。虽然这种方法能够保证效果,但是有时需要很长的bit才能取到更好的效果。在后来的工作中,为了取得更短的编码长度,人们采用了各种尝试,比如构建不同的目标函数,采用不同的优化方法,使用非线性建模,放松离散的约束等方法。其中基于深度学习的Hash算法,最早是Hinton研究组提出的Semantic Hashing。14年的时候,CNN风生水起。中山大学的潘炎老师和颜水成老师合作在2014AAAI上发表了CNNH(Convolutional Neural Network Hashing),将基于CNN的深度Hash搬上了舞台。
主要改进
本篇paper主要关注了有监督的Hash算法。一个关键的问题就是基于学习的Hash 算法需要将图片进行encode成有用的feature represention提高hash的性能。但是对于图像提出的Hash方法主要是使用了现有的视觉描述子,例如gist。然而,这种视觉特征描述子提取是一种无监督的形式,不能完全保证图像之间的语义相关性,比如奥巴马在不同场合的图片之间明显有着很强的语义相关,但是视觉特征向量之间的距离可能很大。于是作者提出了一种用于图片检索的有监督的Hash Method。方法主要分为两个阶段。
第一阶段 Learning approximate hash code
给定n个图片 {
I1,I2,I3,......In} ,首先根据图片之间的差异,构建一个相似度矩阵 S ,其中矩阵
分解以后的q-bit的 Hk 就作为label进行下一步的训练。
研究发现的 Hi. 与 Hj.的 内积 Hi.Hj. 和 Hi. 与 Hj. 的Hamming distance有一一对应的关系。所以我们可以通过最小化重构误差来学习近似的Hash code。
其中 ||.||2F
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1293
1293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









