






第1章 数据集介绍
1.1 数据来源
实验所使用的数据集来源于全球最大的电影资料库和评分网站——Internet Movie Database(IMDb)。这个网站包含了丰富的电影、电视剧集、纪录片和特种影片的信息,以及用户对这些作品的评论和评分。
1.2 数据规模
IMDB数据集包含了大量的电影评论,通常版本的数据集包含约50,000条评论。这些评论被分为正面(positive)和负面(negative)两类,每类约包含25,000条评论。每条评论都被标记为1(正面)或0(负面),以便用于监督学习。
1.3 数据特点
IMDB数据集的评论文本具有较长的长度,每条评论通常包含几百个单词。这使得该数据集在训练深度学习模型时具有挑战性,因为模型需要处理较长的文本序列。此外,评论中的语言风格、表达方式以及主题多样性也为模型提供了丰富的信息。
第2章 模型介绍
2.1 实验模型
该实验基于阿里云的大模型平台,采用的是长短期记忆 (LSTM) 深度学习模型。
2.2 模型机制的介绍
LSTM网络引入门控机制(Gating Mechanism)来控制信息传递的路径,遗忘门𝒇𝑡 、输入门𝒊𝑡和输出门𝒐𝑡 的作用分别为:遗忘门𝒇𝑡 控制上一个时刻的内部状态𝒄𝑡−1 需要遗忘多少信息;输入门𝒊𝑡控制当前时刻的候选状态𝒄𝑡̃ 有多少信息需要保存;输出门𝒐𝑡 控制当前时刻的内部状态𝒄𝑡 有多少信息需要输出给外部状态𝒉𝑡。
当𝒇𝑡 = 0, 𝒊𝑡 = 1时,记忆单元将历史信息清空,并将候选状态向量𝒄𝑡̃ 写入,但此时记忆单元𝒄𝑡 依然和上一时刻的历史信息相关;当𝒇𝑡 = 1, 𝒊𝑡 = 0 时,记忆单元将复制上一时刻的内容,不写入新的信息。
LSTM网络的循环单元结构的计算过程如下:
1)首先利用上一时刻的外部状态𝒉𝑡−1和当前时刻的输入𝒙𝑡,计算出三个门和候选状态𝒄𝑡̃ ;
2)结合遗忘门𝒇𝑡 和输入门𝒊𝑡 来更新记忆单元𝒄𝑡;
3)结合输出门𝒐𝑡,将内部状态的信息传递给外部状态𝒉𝑡。
第3章 模型的搭建和参数的调整
3.1 数据的处理
定义方法read_file(filetype), rm_tags(text)用于对数据集的数据进行处理。
read_file(filetype)用于从读取本地文件并返回评价标签all_labels和评论内
all_texts。
rm_tags(text)方法用于剔除评论的html标签。
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>') # 剔除掉html标签
return re_tag.sub('', text)
我们从网址得到的数据需要清除文本中html格式标签。在本地的train和test文件夹中找到对应的pos和neg的评论,并将其合并为file_list,然后将file_list中的文件剔除掉html标签写入all_texts中。
all_labels = ([1] * 12500 + [0] * 12500) # 前12500是正面都为1;后12500是负面都为0
all_texts += [rm_tags(" ".join(file_input.readlines()))]
(all_labels, all_texts)就是训练所需的数据。
3.2 文本预处理
使用 Tokenizer 类来创建一个分词器,该分词器会将文本分解为单词,并计算每个单词在训练数据中出现的频率。
token = Tokenizer(num_words=2000) # 词典的单词数为2000
使用 fit_on_texts 方法在训练数据上训练分词器,并为每个单词添加序号,虽然每个单词都会有序号,但只会有2000个单词投影
token.fit_on_texts(train_text)
使用 texts_to_sequences 方法将训练和测试文本转换为数字序列,其中每个单词都被替换为其在词汇表中的索引。
x_train_seq = token.texts_to_sequences(train_text)
x_test_seq = token.texts_to_sequences(test_text)
由于不同的评论有不同的长度,
但大多数机器学习模型需要固定长度的输入,因此使用 pad_sequences 方法对序列进行填充或截断。
所有序列都被填充或截断为长度为 380 的序列。较短的序列会在其前面用0填充,而较长的序列则会被截断
单词的索引是从1开始的,不是从0开始的(按照惯例,0不代表任何特定词,而用来编码任何未知的单词),所以可以使用0填充序列
x_train = sequence.pad_sequences(x_train_seq, maxlen=380)
x_test = sequence.pad_sequences(x_test_seq, maxlen=380)
3.3 实现LSTM(长短期记忆)模型
使用Sequential类初始化一个顺序模型,Sequential 是 Keras 中的一种神经网络框架,可以被认为是一个容器,其中封装了神经网络的结构。Sequential 模型只有一组输入和一组输出。各层之间按照先后顺序进行堆叠。前面一层的输出就是后面一次的输入。通过不同层的堆叠,构建出神经网络。
model = Sequential()
这个 model 是一个空的容器,现在就需要向其中添加层,构成神经网络。这也是 Sequential 模型的核心操作
输出一个单词用32维词向量表示,字典词数(输入维数)为3800,输入序列的最大长度380表示一条评论
model.add(Embedding(output_dim=32, input_dim=3800, input_length=380))
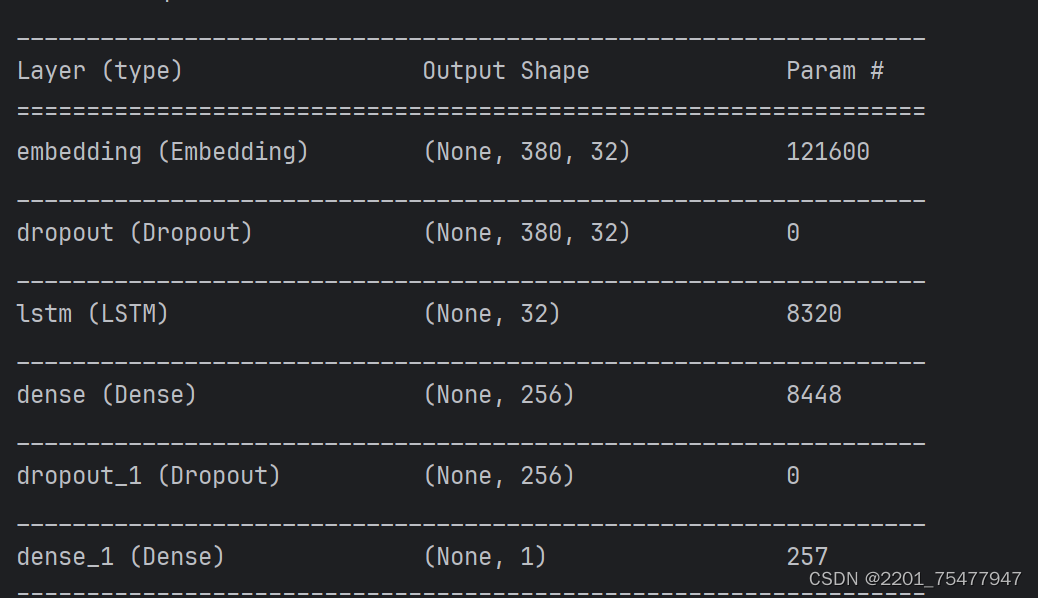
可以看出Embedding层形状为380长度,32维词向量,共121600个神经元

在训练过程中随机丢弃20%的网络单元以防止过拟合
model.add(Dropout(0.2))
Dropout的做法是在训练过程中随机地忽略一些神经元。这些神经元被随机地“抛弃”了。也就是说它们在正向传播过程中对于下游神经元的贡献效果暂时消失了,反向传播时该神经元也不会有任何权重的更新。
随着神经网络模型不断地学习,神经元的权值会与整个网络的上下文相匹配。神经元的权重针对某些特征进行调优,具有一些特殊化。周围的神经元则会依赖于这种特殊化,如果过于特殊化,模型会因为对训练数据过拟合而变得脆弱不堪。神经元在训练过程中的这种依赖于上下文的现象被称为复杂的协同适应(complex co-adaptations)。
model.add(LSTM(32))
LSTM单元内的隐藏层的尺寸为32,对于LSTM而言,每个单元有3个门,对应了4个激活函数(3个sigmoid,一个tanh)。也就是说有4个神经元数量为32的前馈网络层。
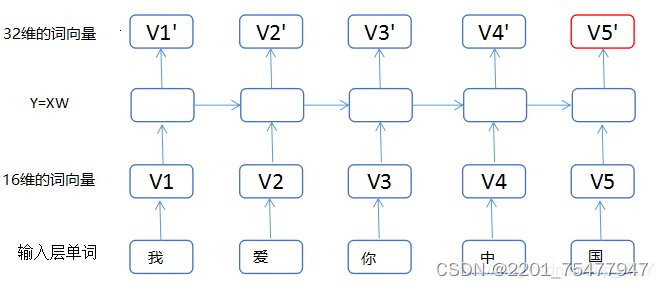
假如我们样本的每一句话包含5个单词,每个单词用16维的词向量表示。对于LSTM(units=32),我们可以把LSTM内部的计算过程计算过程简化为:
Y=x(1×16)w(16×32),这里x为(1,16)的向量,w为(16,32)的矩阵,所以运用矩阵乘法,将16维的X转化为32维的向量,所以我们可以简单的将LSTM内部的各种计算想象成全连接的之间的矩阵计算。
添加Dense层(全连接层),参数 activation 表示激活函数,以字符串的形式给出,包括relu、softmax、Sigmoid、Tanh 等,
使用ReLU激活函数,输出有256个单元,用于对LSTM层的输出进行非线性转换,对于正数直接输出,而负数全部抑制为0
model.add(Dense(units=256, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(units=1, activation='sigmoid'))

使用 model 的 summary() 函数来查看网络的结构和参数信息
model.summary()
3.4 配置训练方法
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
使用二分类交叉熵损失函数,激活函数 Sigmoid 搭配使用,优化器使用adam,可以代替经典的随机随机梯度下降法来更有效地更新网络权重,使用数值评估指标accuracy。
训练模型:
train_history = model.fit(x=x_train, y=y_train, validation_split=0.2, epochs=10, batch_size=300, verbose=1)
validation_split=0.2:将20%的训练数据用作验证集,不参与训练,用来在训练的过程中,测试模型的误差、准确率等指标。
epochs=10:训练模型10个周期。
batch_size=300:每个批次包含300个样本。
3.5 绘制训练过程中准确率和损失的变化图
print(train_history.history)
在此我只展示训练一轮的结果

可以看出返回值是一个字典,有四个字典元素,关键字分别是 ‘loss’、‘accuracy’、‘val_loss’ 以及 ‘val_accuracy’, 分别是训练集和测试集上的损失和准确率。每个关键字对应的值是一个列表,保存着各轮训练或测试的结果,通过关键字可以分别从字典中取出训练集和测试集的损失和准确率。
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
分别绘制训练集和验证集的准确率和损失
show_train_history(train_history, 'accuracy', 'val_accuracy') # 准确率折线图
show_train_history(train_history, 'loss', 'val_loss') # 损失函数折线图
3.6 测试结果的输出
用以下的代码对结果做出输出展示。
scores = model.evaluate(x_test, y_test)
print(scores)
print('Test loss: ', scores[0])
print('Test accuracy: ', scores[1])
第4章 成果对照
4.1 成果展示
训练十轮的结果展示:
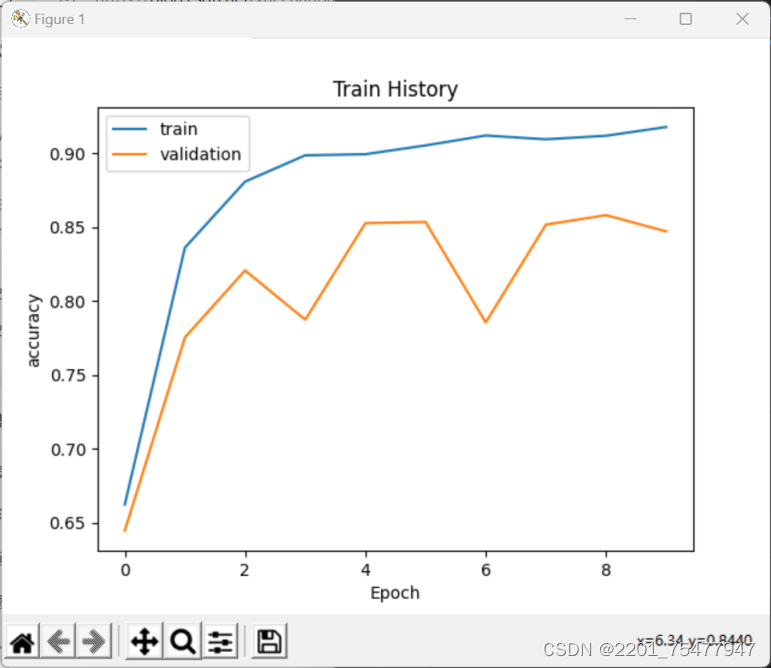
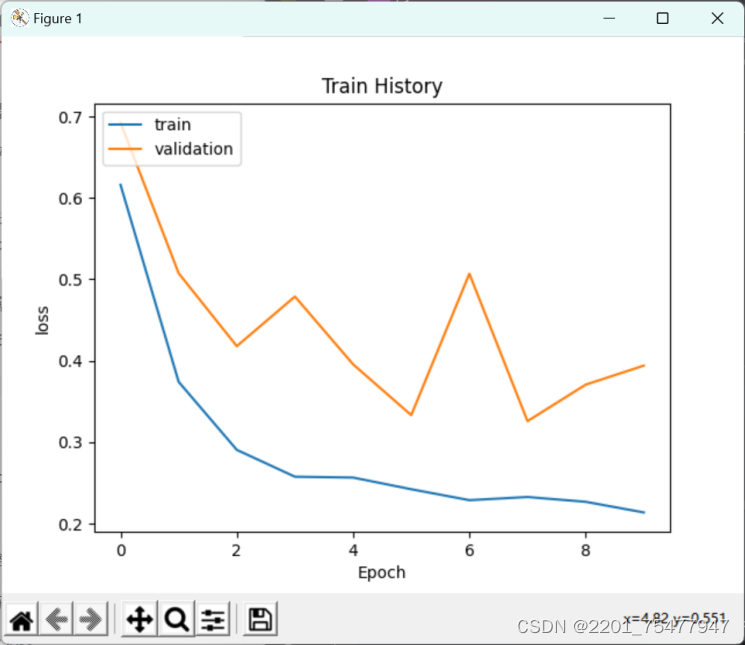

可以看出准确率为0.87,损失为0.33,说明此模型训练结果还不错。
将我们的待测试的语句用训练得到的模型测试。

通过模型预测测试语句得到“it is very good”这个语句属于正面评论的概率为0.95,可见模型的预测结果相对正确。















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









