







节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂同学、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。
今天整理我们社群一个同学面试百度 NLP 算法方向的面试题,分享给大家,希望对后续找工作的有所帮助。喜欢记得点赞、收藏、关注。更多技术交流&面经学习,可以加入我们。
1. 自我介绍
在自我介绍环节,我清晰地阐述了个人基本信息、教育背景、工作经历和技能特长,展示了自信和沟通能力。
2. 技术问题
2.1 讲lora的原理
LoRA的基本原理是冻结预训练的模型参数,然后在Transfomer的每一层中加入一个可训练的旁路矩阵(低秩可分离矩阵),接着将旁路输出与初始路径输出相加输入到网络当中,并只训练这些新增的旁路矩阵参数。其中,低秩可分离矩阵由两个矩阵组成,第一个矩阵负责降维,第二个矩阵负责升维,中间层维度为r,从而来模拟本征秩(intrinsic rank),这两个低秩矩阵能够大幅度减小参数量。
2.2 介绍一下 LayerNorm 计算公式?
2.3 介绍一下 RMSNorm 计算公式?
2.4 RMSNorm比LayerNorm好在哪里?
简单来说就是,虽然二者的时间复杂度一致,但是RMSNorm比起LayerNorm确实减少了减去均值以及加上bias的计算,这在目前大模型预训练的计算量下就能够体现出训练速度上的优势了,并且RMSNorm在模型效果上的表现并不弱于LayerNorm(LN取得成功的原因可能是缩放不变性,而不是平移不变性),所以选择RMSNorm就很自然了, 要注意RMSNorm也是LaverNorm的一种,以上提到的LaverNorm指的是最常见的形式
2.5 说一下 Encoder-only、Encoder-Decoder、Decoder-only 的区别?
在深度学习和自然语言处理(NLP)领域中,Encoder-Only、Decoder-Only以及Encoder-Decoder架构是三种不同类型的神经网络结构,它们各自设计用于不同的任务:
- Encoder-Only架构:
-
定义与特点:这类模型仅包含编码器部分,主要用于从输入数据提取特征或表示。例如,在BERT (Bidirectional Encoder Representations from Transformers) 中,它是一个双向Transformer编码器,被训练来理解文本上下文信息,并输出一个固定长度的向量表示,该表示包含了原始输入序列的丰富语义信息。
-
用途:主要用于预训练模型,如BERT、RoBERTa等,常用于各种下游任务的特征提取,比如分类、问答、命名实体识别等,但不直接用于生成新的序列。
- Decoder-Only架构:
-
定义与特点:解码器仅架构专注于从某种内部状态或先前生成的内容生成新的序列,通常用于自回归式预测任务,其中每个时刻的输出都依赖于前面生成的所有内容。
-
优点:强大的序列生成能力,能够按顺序逐个生成连续的元素(如单词、字符),适用于诸如文本生成、自动摘要、对话系统等生成性任务。典型的Decoder-Only模型包括GPT系列(如GPT-3)。
- Encoder-Decoder架构:
-
定义与特点:这种架构由两个主要部分组成:编码器和解码器。编码器负责将输入序列转换为压缩的中间表示,解码器则基于这个中间表示生成目标输出序列。这种结构非常适合翻译、摘要生成、图像描述等任务,需要理解和重构输入信息后生成新序列的任务。
-
工作原理:编码器对源序列进行处理并生成上下文向量,解码器根据此上下文向量逐步生成目标序列。例如,经典的Seq2Seq(Sequence-to-Sequence)模型和Transformer中的机器翻译模型就采用了这样的结构。
总结起来:
-
Encoder-Only用于理解输入并生成其抽象表示,不涉及序列生成。
-
Decoder-Only专门用于根据之前的信息自动生成新序列,不接收外部输入。
-
Encoder-Decoder结合了两者的功能,首先对输入进行编码,然后基于编码结果解码生成新序列。
2.6 为什么现在的LLM都是Decoder only的架构?
-
双向注意力可能存在的低秩问题。双向注意力带来的低秩问题会导致效果下降。
-
在同等参数量、同等推理成本下,Decoder-only架构很比另外两种框架具有更优的效果。
-
Decoder-only的zero-shot能力更强;
2.7 介绍一下 transformer?
Transformer是一种由谷歌在2017年提出的深度学习模型,主要用于自然语言处理(NLP)任务,特别是序列到序列(Sequence-to-Sequence)的学习问题,如机器翻译、文本生成等。Transformer彻底改变了之前基于循环神经网络(RNNs)和长短期记忆网络(LSTMs)的序列建模范式,并且在性能上取得了显著提升。
2.8 在BERT中,token分3种情况做mask,分别的作用是什么?
15%token做mask;其中80%用[MASK]替换,10%用random token替换,10%不变。其实这个就是典型的Denosing Autoencoder的思路,那些被Mask掉的单词就是在输入侧加入的所谓噪音
这么做的主要原因是:
-
在后续finetune任务中语句中并不会出现 [MASK] 标记;
-
预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
2.9 BERT训练时使用的学习率 warm-up 策略是怎样的?为什么要这么做?
warmup 需要在训练最初使用较小的学习率来启动,并很快切换到大学习率而后进行常见的 decay。
这是因为,刚开始模型对数据的“分布”理解为零,或者是说“均匀分布”(当然这取决于你的初始化);在第一轮训练的时候,每个数据点对模型来说都是新的,模型会很快地进行数据分布修正,如果这时候学习率就很大,极有可能导致开始的时候就对该数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。当训练了一段时间(比如两轮、三轮)后,模型已经对每个数据点看过几遍了,或者说对当前的batch而言有了一些正确的先验,较大的学习率就不那么容易会使模型学偏,所以可以适当调大学习率。这个过程就可以看做是warmup。那么为什么之后还要decay呢?当模型训到一定阶段后(比如十个epoch),模型的分布就已经比较固定了,或者说能学到的新东西就比较少了。如果还沿用较大的学习率,就会破坏这种稳定性,用我们通常的话说,就是已经接近loss的local optimal了,为了靠近这个point,我们就要慢慢来。
2.10 BERT预训练任务?
第一部分是来自 MLM 的单词级别分类任务,另一部分是来自NSP的句子级别的分类任务
2.11 BERT预训练过程中的损失函数是什么?
- MLM 预训练任务损失函数设计:

- NSP 预训练任务损失函数设计:
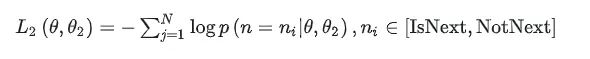
- 两个任务联合学习的损失函数是:

2.12 为什么BERT比ELMo效果好?ELMo和BERT的区别是什么?
因为LSTM抽取特征的能力远弱于Transformer,即使是拼接双向特征,其融合能力也偏弱;BERT的训练数据以及模型参数均多于ELMo。
ELMO给下游提供的是每个单词的embedding,所以这一类预训练的方法被称为“Feature-based Pre-Training”。而BERT模型是“基于Fine-tuning的模式”,这种做法的下游任务需要将模型改造成BERT模型,才可利用BERT模型预训练好的参数。
3. Leetcode 题
- 手撕 beamsearch 算法
在NLP翻译或对话任务中,在句子解码阶段,经常用到一种搜索算法beam search。这个算法有时候在大厂面试中,甚至可能会被要求手写实现。这里就从beam search的原理出发,最后手写实现一个beam search。
- 思路:beam search在贪心搜索上进一步扩大了搜索范围,贪心搜索每下一步只考虑当前最优的top-1结果,beam search考虑最优的top-k个结果。
import torch
import torch.nn.functional as F
def beam_search(LM_prob,beam_size = 3):
batch,seqlen,vocab_size = LM_prob.shape
#对LM_prob取对数
log_LM_prob = LM_prob.log()
#先选择第0个位置的最大beam_size个token,log_emb_prob与indices的shape为(batch,beam)
log_beam_prob, indices = log_LM_prob[:,0,:].topk(beam_size,sorted = True)
indices = indices.unsqueeze(-1)
#对每个长度进行beam search
for i in range(1,seqlen):
#log_beam_prob (batch,beam,vocab_size),每个beam的可能产生的概率
log_beam_prob = log_beam_prob.unsqueeze(-1) + log_LM_prob[:,i,:].unsqueeze(1).repeat(1,beam_size,1)
#选择当前步概率最高的token
log_beam_prob, index = log_beam_prob.view(batch,-1).topk(beam_size,sorted = True)
#下面的计算:beam_id选出新beam来源于之前的哪个beam;index代表真实的token id
#beam_id,index (batch,beam)
beam_id = index//vocab_size
index = index%vocab_size
mid = torch.Tensor([])
#对batch内每个样本循环,选出beam的同时拼接上新生成的token id
for j,bid,idx in zip(range(batch),beam_id,index):
x = torch.cat([indices[j][bid],idx.unsqueeze(-1)],-1)
mid = torch.cat([mid,x.unsqueeze(0)],0)
indices = mid
return indices,log_beam_prob
if __name__=='__main__':
# 建立一个语言模型 LM_prob (batch,seqlen,vocab_size)
LM_prob = F.softmax(torch.randn([32,20,1000]),dim = -1)
#最终返回每个候选,以及每个候选的log_prob,shape为(batch,beam_size,seqlen)
indices,log_prob = beam_search(LM_prob,beam_size = 3)
print(indices)
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:技术交流
用通俗易懂方式讲解系列
- 用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
- 用通俗易懂的方式讲解:1.6万字全面掌握 BERT
- 用通俗易懂的方式讲解:NLP 这样学习才是正确路线
- 用通俗易懂的方式讲解:28张图全解深度学习知识!
- 用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
- 用通俗易懂的方式讲解:实体关系抽取入门教程
- 用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
- 用通俗易懂的方式讲解:图解 Transformer 架构
- 用通俗易懂的方式讲解:大模型算法面经指南(附答案)
- 用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
- 用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
- 用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
- 用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
- 用通俗易懂的方式讲解:利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
- 用通俗易懂的方式讲解:使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
- 用通俗易懂的方式讲解:面了 5 家知名企业的NLP算法岗(大模型方向),被考倒了。。。。。
- 用通俗易懂的方式讲解:NLP 算法实习岗,对我后续找工作太重要了!。
- 用通俗易懂的方式讲解:理想汽车大模型算法工程师面试,被问的瑟瑟发抖。。。。
- 用通俗易懂的方式讲解:基于 Langchain-Chatchat,我搭建了一个本地知识库问答系统
- 用通俗易懂的方式讲解:面试字节大模型算法岗(实习)
- 用通俗易懂的方式讲解:大模型算法岗(含实习)最走心的总结
- 用通俗易懂的方式讲解:大模型微调方法汇总
















 7092
7092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









