






你好,我是小青~
大家知道,由于时间序列数据的特殊性(如时间相关性、不同长度、不等间隔等),传统的欧几里得距离(Euclidean Distance)往往难以有效度量序列之间的相似性。
因此,动态时间规整(DTW, Dynamic Time Warping)被引入作为相似性度量方法,并与K-means 聚类结合,从而形成混合 K-means-DTW 时间序列聚类方法。
完整案例
在很多实际应用场景中(例如金融市场走势分析、医疗健康监测、传感器数据分析、工业设备状态检测等),数据往往以时间序列的形式出现。传统的聚类方法:如 K-means 聚类,在处理时间序列时存在一些局限性,因为时间序列数据具有时序性、趋势性以及局部变化等特点,而直接使用欧氏距离衡量相似度可能无法捕捉到序列之间的非线性对齐关系。
动态时间规整(DTW, Dynamic Time Warping)是一种非常有效的距离度量方法,它可以在不要求两个序列严格对齐的情况下,找到两条时间序列之间的最佳匹配路径,从而计算出一种“弹性”距离。这种方法在实际问题中有较高的鲁棒性,能够处理序列之间存在速度、相位等方面的局部差异。
然而,DTW 距离并不满足三角不等式,且其均值(center)的计算并没有封闭解,使得将 DTW 直接应用于经典的 K-means 算法中存在困难。为了解决这一问题,研究者们提出了多种改进方案,如利用 DTW Barycenter Averaging(DBA)进行中心更新,或者直接在聚类过程中采用 DTW 距离替换欧氏距离。
本案例的核心思想就是:
-
利用虚拟数据构造多个具有不同形态的时间序列(例如正弦波、余弦波、线性趋势序列),
-
使用基于 DTW 度量的 K-means 聚类算法对数据进行划分,
-
通过可视化展示原始数据、聚类中心、DTW 距离矩阵以及各簇内部样本与中心的距离分布,进而验证算法的有效性。
同时,我们还将讨论算法在实际应用中的优化点和调参流程,为后续更大规模数据的处理和算法改进提供参考。
数据生成与预处理
数据集由 150 条时间序列组成,每条序列长度为 100 个时间步,数据大致分为 3 个类别:
-
簇 1:由正弦函数生成的序列,再叠加少量高斯噪声,使得序列呈现周期性波动;
-
簇 2:由余弦函数生成的序列,同样添加噪声,序列形态与簇 1 类似但相位存在明显偏移;
-
簇 3:呈现线性增长趋势的序列,加上噪声后具有一定的上升趋势。
数据预处理的目的是保证不同序列在尺度、偏移上具有一致性,从而使得聚类算法能够专注于形态特征的提取。在本例中,我们通过生成数据时直接控制数值范围来保证数据的归一化;在实际应用中,也可以结合平滑、去趋势、标准化等方法对数据进行进一步处理。
import numpy as np
import matplotlib.pyplot as plt
# 固定随机数种子,保证结果可重复
np.random.seed(0)
n_samples = 150 # 总样本数,每个簇 50 个样本
time_steps = 100 # 每条时间序列的长度
# 生成簇 1:正弦波形(加噪声)
cluster1 = np.array([np.sin(np.linspace(0, 2*np.pi, time_steps)) +
np.random.normal(0, 0.1, time_steps) for _ in range(50)])
# 生成簇 2:余弦波形(加噪声)
cluster2 = np.array([np.cos(np.linspace(0, 2*np.pi, time_steps)) +
np.random.normal(0, 0.1, time_steps) for _ in range(50)])
# 生成簇 3:线性上升趋势(加噪声)
cluster3 = np.array([np.linspace(0, 1, time_steps) +
np.random.normal(0, 0.1, time_steps) for _ in range(50)])
# 将所有簇数据合并为一个数据集
data = np.concatenate([cluster1, cluster2, cluster3], axis=0)
在这段代码中,我们利用 NumPy 的向量化操作生成每个簇的数据,并通过添加服从正态分布的噪声来模拟真实数据中常见的测量误差和随机波动。生成的数据为一个形状为 (150, 100) 的二维数组,每一行代表一条时间序列。
模型构建与聚类算法
由于标准 K-means 算法中均值的计算依赖于欧氏距离,而 DTW 距离无法直接用于求均值,为了将两者结合,我们可以借助开源库tslearn中已经实现的时间序列聚类方法。
该库中提供了 TimeSeriesKMeans 类,其支持多种距离度量,包括 DTW。
我们利用 TimeSeriesKMeans 类实现以 DTW 作为距离度量的 K-means 聚类。
from tslearn.clustering import TimeSeriesKMeans
from tslearn.metrics import dtw, cdist_dtw
# 使用 DTW 作为距离度量的 TimeSeriesKMeans 聚类
# 注意:参数 n_clusters 为簇数,metric="dtw" 指定距离计算方式
km_dtw = TimeSeriesKMeans(n_clusters=3, metric="dtw", max_iter=10, random_state=0)
# 进行模型训练,并获得每个样本的聚类标签
y_pred = km_dtw.fit_predict(data)
# 提取聚类中心(利用 DBA 算法更新得到的中心序列)
cluster_centers = km_dtw.cluster_centers_
我们将簇数设置为 3(与虚拟数据中实际簇数一致),最大迭代次数设为 10。TimeSeriesKMeans 内部会调用 DBA 算法对每个簇计算“均值”序列,使得更新后的中心更符合簇内样本的整体趋势。训练完成后,变量y_pred保存了每条时间序列对应的聚类标签,cluster_centers则包含了三个聚类中心。
可视化
为了直观展现聚类效果及各项数据特征,设计了4个数据分析图表,供大家去理解和学习。
-
原始时间序列数据图:内容对每个簇中部分时间序列进行绘制(每簇选取 10 条),使用红、绿、蓝三种颜色分别表示不同簇。直观展示了不同簇的时间序列在波动、趋势上的差异,同时验证同一簇内数据形态较为相似,证明 DTW 能够捕捉到形态特征。
-
聚类中心图:将三个簇的聚类中心以粗实线绘制,不同颜色对应不同簇,并添加图例。展示了每个簇的代表性中心序列,帮助我们理解聚类中心的形态特征与原始数据的关系,验证 DBA 算法在计算“均值”序列时的合理性。
-
DTW 距离矩阵热图:选取部分样本(例如前 30 个时间序列),计算它们之间的 DTW 距离,并用热图展示。通过热图,颜色越深表示距离越大,能够直观展示样本之间的相似性分布情况。
-
各簇内部距离分布箱型图:分别计算每个簇中各个时间序列与对应聚类中心之间的 DTW 距离,然后用箱型图展示不同簇的距离分布。该图有助于评估每个簇内部样本与中心的紧密程度,箱线图中上下四分位数、异常值等信息能帮助我们发现潜在的离群点或簇内离散度问题。
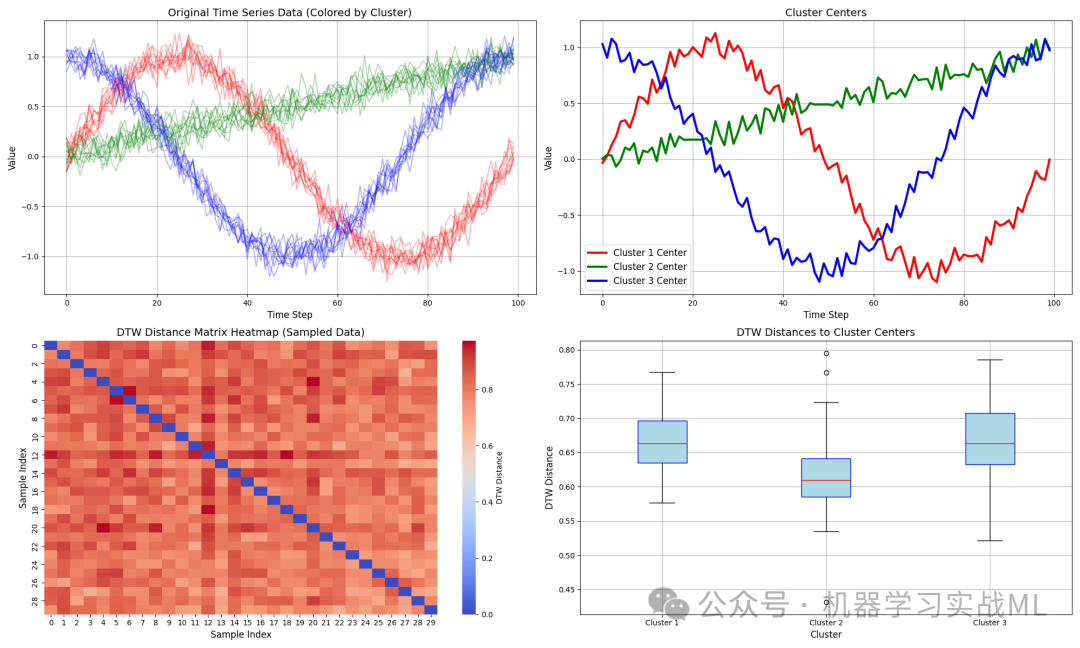
-
同一簇内的时间序列呈现较高的相似性;
-
聚类中心较好地捕捉了各簇的主要趋势;
-
DTW 距离矩阵热图中,相似度高的样本之间的距离较小(颜色较浅或渐变),而不相似的样本之间距离较大;
-
箱型图显示了不同簇内部的紧密程度,为后续的模型评价提供依据。


















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









