






前言
在当今信息时代,机器学习和深度学习作为人工智能领域的重要分支,正日益成为科技领域的热门话题。为了帮助读者更好地了解机器学习的基础知识,本文将重点介绍PyTorch深度学习基础以及Logistic回归模型的相关内容。通过深入探讨PyTorch中的Tensor对象、运算操作、自动微分等核心概念,读者将能够建立起对深度学习框架的基本理解。此外,我们还将详细介绍Logistic回归模型的原理、应用和优化算法,帮助读者在实践中更好地运用这一经典的机器学习模型。希望本文能为初学者提供一个清晰的学习路径,让大家更快地掌握机器学习的基础知识,并在未来的学习和实践中取得更好的成果。
一、pyTorch深度学习基础
1.1、Tensor对象及运算
在数学和计算机科学中,tensor(张量)是一种多维数组,它可以表示向量、矩阵和更高维度的数组。在机器学习和深度学习中,tensor是存储和计算数据的基本对象。tensor对象可以进行各种数学运算,例如加法、减法、乘法和除法。这些运算可以用于计算两个或多个tensor之间的元素级操作,也可以用于计算tensor的标量积、向量积、矩阵乘法等更复杂的运算。
总之,tensor对象及其运算是机器学习和深度学习中重要的工具,用于存储和计算数据,支持各种数学运算和算法实现。下面我们加上代码来具体介绍tensor对象及运算
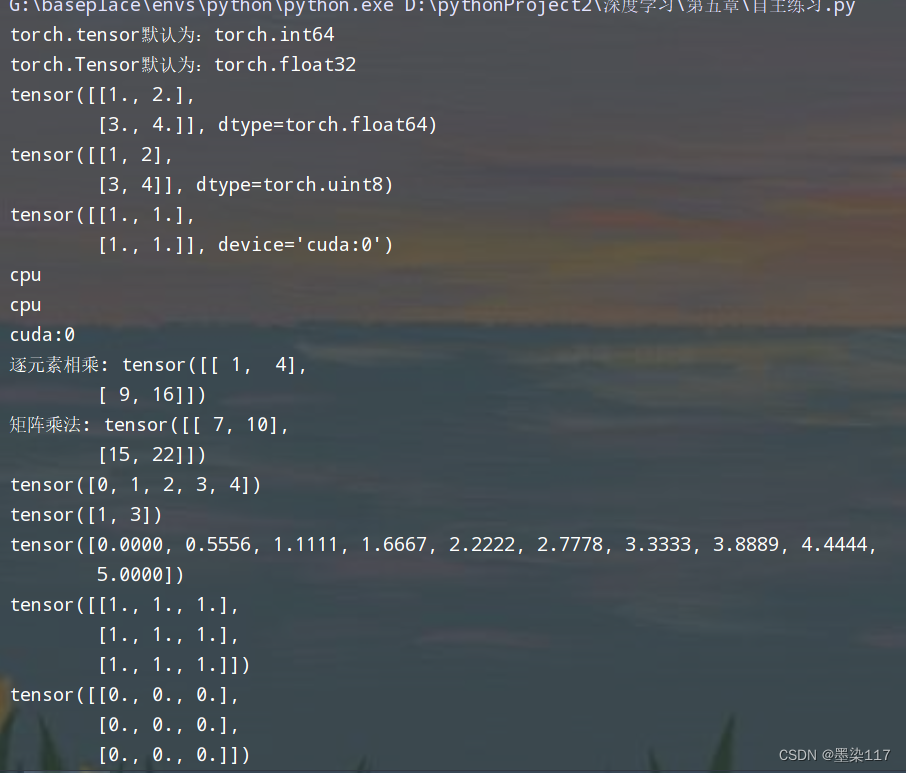
import torch
import numpy as np
# 创建两个标量tensor
print('torch.tensor默认为:{}'.format(torch.tensor(1).dtype))
print('torch.Tensor默认为:{}'.format(torch.Tensor(1).dtype))
# 用列表构建tensor,指定数据类型为float64
a = torch.tensor([[1,2],[3,4]], dtype=torch.float64)
# 用ndarray构建tensor,指定数据类型为uint8
b = torch.tensor(np.array([[1,2],[3,4]]), dtype=torch.uint8)
print(a)
print(b)
# 通过device参数指定使用的设备(这里指定为cuda:0,即GPU上)
cuda0 = torch.device('cuda:0')
c = torch.ones((2,2), device=cuda0)
print(c)
# 将c tensor从GPU移动到CPU,并同时改变数据类型为double
c = c.to('cpu', torch.double)
print(c.device)
# 将c tensor从GPU移动到CPU,并同时改变数据类型为double
c = c.to('cpu', torch.double)
print(c.device)
# 将b tensor从CPU移动到GPU,并同时改变数据类型为float
b = b.to(cuda0, torch.float)
print(b.device)
# 逐元素相乘
a = torch.tensor([[1,2],[3,4]])
b = torch.tensor([[1,2],[3,4]])
c = a * b
print("逐元素相乘:", c)
# 矩阵乘法
c = torch.mm(a, b)
print("矩阵乘法:", c)
# 将a tensor中小于2的元素设置为2,大于3的元素设置为3
a = torch.tensor([[1,2],[3,4]])
torch.clamp(a, min=2, max=3)
# 对a tensor中的元素进行四舍五入
a = torch.Tensor([-1.1,0.5,0.501,0.99])
torch.round(a)
# 对a tensor中的元素进行双曲正切函数计算
a = torch.Tensor([-3,-2,-1,-0.5,0,0.5,1,2,3])
torch.tanh(a)
# 创建一个从0开始、步长为1的tensor
print(torch.arange(5))
# 创建一个从1开始、到5结束(不包括5)、步长为2的tensor
print(torch.arange(1,5,2))
# 在0到5之间创建10个均匀间隔的点
print(torch.linspace(0,5,10))
# 创建一个大小为3x3的全1矩阵
print(torch.ones(3,3))
# 创建一个大小为3x3的全0矩阵
print(torch.zeros(3,3))
# 创建一个大小为3x3的在[0,1)范围内均匀分布的随机tensor
torch.rand(3,3)
# 创建一个大小为3x3的标准正态分布随机tensor
torch.randn(3,3)
# 创建一个大小为3x3的整数随机tensor,范围为[0, 9)
torch.randint(0, 9, (3,3))
运行结果
1.2、Tensor的索引和切片
在张量中,索引和切片操作是非常常见的操作。索引操作可以用来提取张量中的单个元素,而切片操作可以用来提取张量中的子张量。
在Python中,张量的索引和切片操作和列表和数组类似,并且也是从0开始的。以下是一些常见的索引和切片操作示例:
1.2.1、基本索引
a = torch.arange(9).view(3,3)
##基本索引
a [2,2]
##切片
a[1:,:-1]
##带步长的切片
a[::2]
1.2.2、整数索引
rows = [0,1]
cols = [2,2]
a[rows, cols]
1.2.3、布尔索引
##布尔索引
index = a>4
print(index)
print(a[index])
1.2.4、返回非零值的索引矩阵
a = torch.arange(9).view(3,3)
index = torch.nonzero(a >=0)
print(index)
a = torch.randint(0,2,(3,3))
print(a)
index = torch.nonzero(a)
print(index)
1.3、Tensor的变换、拼接和拆分
1.3.1、变换
如果要对一个张量进行变换,可以使用torch.transpose函数或者torch.permute函数。torch.transpose函数可以接受一个维度参数,将张量的维度进行转置。而torch.permute函数可以接受一个维度的排列顺序,将张量的维度按照指定的顺序重新排列。示例代码如下:
import torch
# 创建一个张量
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
# 转置张量
y = torch.transpose(x, dim0=0, dim1=1) # 或者使用 y = x.transpose(0, 1)
print(y) # 输出: tensor([[1, 4], [2, 5], [3, 6]])
# 重新排列张量
z = torch.permute(x, dims=(1, 0))
print(z) # 输出: tensor([[1, 4], [2, 5], [3, 6]])
在上述示例中,通过torch.transpose(x, dim0=0, dim1=1)将x张量的维度0和维度1进行转置,并将结果存储在y中。而通过torch.permute(x, dims=(1, 0))将x张量的维度按照(1, 0)的顺序重新排列,并将结果存储在z中。
1.3.2、拼接
在PyTorch中,可以使用torch.cat函数进行张量的拼接。该函数可以接受一个张量的列表和一个维度参数,将列表中的张量按照指定的维度拼接在一起。示例代码如下:
import torch
# 创建两个张量
x = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])
# 拼接两个张量
z = torch.cat([x, y], dim=0)
print(z) # 输出: tensor([1, 2, 3, 4, 5, 6])
在上述示例中,通过torch.cat([x, y], dim=0)将x和y两个张量在0维上进行拼接,并将结果存储在z中。
1.3.3、拆分
如果要将一个张量拆分成多个张量,可以使用torch.split函数。该函数可以接受一个张量、拆分的大小和拆分的维度参数,将张量按照指定的大小和维度进行拆分。示例代码如下:
import torch
# 创建一个张量
x = torch.tensor([1, 2, 3, 4, 5, 6])
# 拆分张量
y1, y2, y3 = torch.split(x, split_size_or_sections=2, dim=0)
print(y1) # 输出: tensor([1, 2])
print(y2) # 输出: tensor([3, 4])
print(y3) # 输出: tensor([5, 6])
在上述示例中,通过torch.split(x, split_size_or_sections=2, dim=0)将x张量按照大小为2和维度为0进行拆分,并将结果存储在y1、y2和y3中。
1.4、pytorch 的 Reduction的操作
PyTorch中的reduction操作用于对张量进行降维处理,常用于计算损失函数、评估指标等操作。
以下是几种常用的reduction操作:
-
torch.mean(input, dim=None, keepdim=False):计算张量沿指定维度的平均值。dim参数用于指定计算平均值的维度,keepdim参数用于指定是否保持返回值的维度。
-
torch.sum(input, dim=None, keepdim=False):计算张量沿指定维度的和。dim参数用于指定计算和的维度,keepdim参数用于指定是否保持返回值的维度。
-
torch.max(input, dim=None, keepdim=False):计算张量沿指定维度的最大值及其索引。dim参数用于指定计算最大值的维度,keepdim参数用于指定是否保持返回值的维度。
-
torch.min(input, dim=None, keepdim=False):计算张量沿指定维度的最小值及其索引。dim参数用于指定计算最小值的维度,keepdim参数用于指定是否保持返回值的维度。
-
torch.prod(input, dim=None, keepdim=False):计算张量沿指定维度的乘积。dim参数用于指定计算乘积的维度,keepdim参数用于指定是否保持返回值的维度。
-
torch.std(input, dim=None, unbiased=True, keepdim=False):计算张量沿指定维度的标准差。dim参数用于指定计算标准差的维度,unbiased参数用于指定是否使用无偏估计,keepdim参数用于指定是否保持返回值的维度。
-
torch.var(input, dim=None, unbiased=True, keepdim=False):计算张量沿指定维度的方差。dim参数用于指定计算方差的维度,unbiased参数用于指定是否使用无偏估计,keepdim参数用于指定是否保持返回值的维度。
这些reduction操作可以通过指定dim参数来对张量的指定维度进行操作,也可以不指定dim参数对整个张量进行操作。同时,可以通过keepdim参数来决定是否保持返回值的维度。
代码示例:
import torch
#创建了一个形状为 (2, 2) 的张量 a,并使用 torch.max 函数求取了全局最大值。
a=torch.tensor([[1,2],[3,4]])
print("全局最大值:",torch.max(a))
#调用 torch.max 函数,并指定参数 dim=0,即沿着横轴(列)计算每一列的最大值及其索引。
torch.max(a,dim=0)
#创建了一个形状为 (2, 2) 的张量 a,并使用 torch.cumsum 函数沿着横轴计算了每一列的累加结果。
a=torch.tensor([[1,2],[3,4]])
print("沿着横轴计算每一列的累加:")
print(torch.cumsum(a,dim=0))
#使用 torch.cumprod 函数沿着纵轴计算了每一行的累乘结果。
print("沿着纵轴计算每一行的累乘:")
print(torch.cumprod(a,dim=1))
#创建了一个形状为 (2, 2) 的张量 a,并分别使用 mean、median 和 std 方法计算了其均值、中值和标准差。
a=torch.Tensor([[1,2],[3,4]])
a.mean(),a.median(),a.std()
# 创建了一个形状为 (3, 3) 的张量 a,并使用 torch.randint 函数生成随机整数张量。然后分别打印出 a 的值和调用 torch.unique 函数找出矩阵中出现了哪些元素。
a=torch.randint(0,3,(3,3))
print(a)
print(torch.unique(a))
1.5、pyTorch的自动化微分
PyTorch是一个开源的深度学习库,它提供了自动化微分的功能。自动微分是指计算导数的过程由计算机自动完成,而不需要手动推导和计算。
在PyTorch中,我们可以定义一些变量和操作,然后通过调用反向传播函数来自动计算梯度。这使得在深度学习中使用梯度下降等优化算法变得非常方便。
PyTorch中的自动微分主要有两个部分:torch.autograd和torch.nn。torch.autograd定义了tensor和函数的操作,可以跟踪它们的操作历史,并计算梯度。torch.nn则提供了一些高级的神经网络模块和层,可以方便地构建神经网络。
通过使用PyTorch的自动微分功能,我们可以在深度学习中定义复杂的模型,并自动计算模型参数的梯度,进行优化。
代码示例:
import torch
#当tensor的require__gard属性设置为ture时,PyTorch 的 torch.autograd 会自动追踪它的的计算轨迹。
x = torch.arange(9).view(3,3)
x.requires_grad
x = torch.rand(3,3,requires_grad=True)
print(x)
w = torch.ones(3,3,requires_grad=True)
y = torch.sum(torch.mm(w,x))
print(y.retain_grad())
print(y.grad)
print(x.grad)
print(w.grad)
#Tensor.detach 会将Tensor 从计算图剥离出去,不再计算它的微分。
x = torch.rand(3,3,requires_grad=True)
w = torch.ones(3,3,requires_grad=True)
print(x)
print(w)
yy = torch.mm(w,x)
detached__yy = yy.detach()
y = torch.mean(yy)
y.backward ()
print(yy.retain_grad())
print(detached__yy)
print(w.grad)
print(x.grad)
#with torch.no_grad():包括的代码段不会计算微分。
y=torch.sum(torch.mm(w,x))
print(y.requires_grad)
with torch.no_grad():
y = torch.sum(torch.mm(w,x))
print(y.requires_grad)
二、Logistic回归
回归是指这样一类问题:通过统计分析一组随机变量x,,x,与另一组随机变量y,…,y。之间的关系,得到一个可靠的模型,使得对于给定的x=,,X,},可以利用这个模型对y={y,,Pa进行预测。在这里,随机变量x,…,x,被称为自变量,随机变量y1,…,y。被称为因变量。例如,当预测房价时,研究员们会选取可能对房价有影响的因素,例如房屋面积、房屋楼层、房屋地点等,作为自变量加入预测模型。研究的任务即建立一个有效的模型,能够准确表示出上述因素与房价之间的关系
2.1、线性回归简介
线性回归是一种统计模型,用于建立自变量(特征)与因变量之间的线性关系。它假设因变量与自变量之间存在一个线性关系,通过最小化预测值与实际值之间的差异,来求得最佳的模型参数,从而进行预测和分析。
线性回归模型可以表示为:
y = β0 + β1x1 + β2x2 + … + βn*xn
其中,y表示因变量(待预测的变量),x1、x2、…、xn表示自变量(特征),β0、β1、β2、…、βn表示模型的参数。
线性回归的目标是找到使得预测值与实际值之间的差异最小的参数值。通常使用最小二乘法来求解,即通过最小化残差平方和来求得最佳的参数估计值。
线性回归模型有很多应用领域,如经济学、金融学、社会科学等。它能够帮助我们理解自变量与因变量之间的关系,并进行预测和分析。
2.1.1、一元线性回归
一元线性回归是一种回归分析方法,用于建立一个自变量和一个因变量之间的线性关系模型。这个模型可以用来预测因变量的值,基于给定的自变量的值。
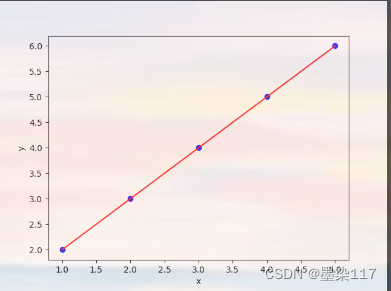
下面是一个简单的一元线性回归示例:
import numpy as np
import matplotlib.pyplot as plt
# 输入数据
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 3, 4, 5, 6])
# 计算样本均值
x_mean = np.mean(x)
y_mean = np.mean(y)
# 计算回归系数
b1 = np.sum((x - x_mean) * (y - y_mean)) / np.sum((x - x_mean) ** 2)
b0 = y_mean - b1 * x_mean
# 计算预测值
y_pred = b0 + b1 * x
# 绘制原始数据和回归线
plt.scatter(x, y, color='b')
plt.plot(x, y_pred, color='r')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
输出图像:
2.2.1、什么是Logistic?
Logistic通常是指逻辑回归(Logistic Regression),是一种用于解决分类问题的统计学习方法。逻辑回归的目标是通过建立一个逻辑回归模型,将输入变量与离散的输出变量之间的关系进行建模。
逻辑回归使用了一个称为逻辑函数(logistic function)的函数来表示输入与输出之间的关系。逻辑函数将输入值映射到一个介于0和1之间的概率值,表征了输出为某个类别的概率。
逻辑回归可以通过梯度下降等方法进行学习,并且可以通过调整模型的阈值来调节分类的准确性和召回率。逻辑回归也可以扩展到多分类问题,例如通过一对多(one-vs-rest)方法将多分类问题转化为多个二分类问题来解决。
2.3、用pyTorch实现logistic回归
2.3.1、数据准备
import torch
from torch import nn
import matplotlib.pyplot as plt
import numpy as np
from torch.distributions import MultivariateNormal
# 设置两组不同的均值向量和协方差矩阵
mu1 = -3 * torch.ones(2) # 第一组均值向量
mu2 = 3 * torch.ones(2) # 第二组均值向量
sigma1 = torch.eye(2) * 0.5 # 第一组协方差矩阵
sigma2 = torch.eye(2) * 2 # 第二组协方差矩阵
# 从两个多元高斯分布中生成100个样本
m1 = MultivariateNormal(mu1, sigma1) # 第一个多元高斯分布
m2 = MultivariateNormal(mu2, sigma2) # 第二个多元高斯分布
x1 = m1.sample((100,)) # 从第一个分布中生成样本
x2 = m2.sample((100,)) # 从第二个分布中生成样本
# 设置正负样本的标签
y = torch.zeros((200, 1)) # 初始化标签
y[100:] = 1 # 设置后100个样本为正样本
# 组合、打乱样本
x = torch.cat([x1, x2], dim=0) # 合并样本
idx = np.random.permutation(len(x)) # 随机打乱样本顺序
x = x[idx]
y = y[idx]
# 绘制样本
plt.scatter(x1.numpy()[:, 0], x1.numpy()[:, 1]) # 绘制第一组样本
plt.scatter(x2.numpy()[:, 0], x2.numpy()[:, 1]) # 绘制第二组样本
plt.show()
上述代码将生成的样本用plt.scatter 绘制出来,绘制的结果如图所示,可以很明显地看出多元高斯分布生成的样本聚成了两个簇,并且簇的中心分别处于不同的位置(多元高斯分布的均值向量决定了其位置)。右上角簇的样本分布比较稀疏,而左下角簇的样本分布紧凑(多元高斯分布的协方差矩阵决定了分布形状)。

2.3.2、线性方程
D_in, D_out = 2, 1
linear = nn.Linear(D_in, D_out, bias=True)
output = linear(x)
# 输出数据形状及参数形状
print(x.shape, linear.weight.shape, linear.bias.shape, output.shape)
def my_linear(x, w, b):
return torch.mm(x, w.t()) + b
# 检查自定义线性函数是否与PyTorch的Linear层输出一致
torch.sum((output - my_linear(x, linear.weight, linear.bias)))
2.3.3、激活函数
sigmoid = nn.Sigmoid()
scores = sigmoid(output)
def my_sigmoid(x):
x = 1 / (1 + torch.exp(-x))
return x
# 检查自定义Sigmoid函数是否与PyTorch的Sigmoid一致
torch.sum(sigmoid(output) - my_sigmoid(output))
2.3.4、损失函数
Logistic 回归使用交叉熵作为损失函数。PyTorch的torch.nn 提供了许多标准的损失函数,我们可以直接使用nn.BCELoss 计算二值交叉熵损失。调用了BCELoss来计算我们实现的 Logistic 回归模型的输出结果 sigmoid(output)和数据的标签y。同样地,我们自定义了二值交叉熵函数,在第8行将my_loss 和 PyTorch 的BCELoss进行比较,发现其结果-致。
loss = nn.BCELoss() # 定义二分类交叉熵损失函数
loss(sigmoid(output), y) # 计算模型输出经过sigmoid函数后的损失
def my_loss(x, y):
# 定义损失函数,用于计算交叉熵损失
loss = -torch.sum(torch.log(x) * y + torch.log(1 - x) * (1 - y))
return loss
# 使用sigmoid函数对输出进行处理,并计算损失值
loss(sigmoid(output), y) - my_loss(sigmoid(output), y)
# 定义LogisticRegression类
class LogisticRegression(nn.Module):
# 初始化函数
def __init__(self, D_in):
super(LogisticRegression, self).__init__()
# 线性层,输入维度为D_in,输出维度为1
self.linear = nn.Linear(D_in, 1)
# Sigmoid激活函数
self.sigmoid = nn.Sigmoid()
# 前向传播函数
def forward(self, x):
# 线性前向传播
x = self.linear(x)
# 对线性输出进行Sigmoid激活
output = self.sigmoid(x)
return output
# 创建一个LogisticRegression的实例,输入维度为2
ir_model = LogisticRegression(2)
# 定义二元交叉熵损失函数
loss = nn.BCELoss()
# 计算ir_model对输入x的预测和真实标签y的损失
loss(ir_model(x), y)
2.3.5、优化算法
optimizer = torch.optim.SGD(ir_model.parameters(), lr=0.03)
batch_size = 10
iterations = 10
for i in range(iterations):
for j in range(int(len(x) / batch_size)):
input_batch = x[j * batch_size: (j + 1) * batch_size]
target_batch = y[j * batch_size: (j + 1) * batch_size]
optimizer.zero_grad()
output = ir_model(input_batch)
loss_val = loss(output, target_batch)
loss_val.backward()
optimizer.step()
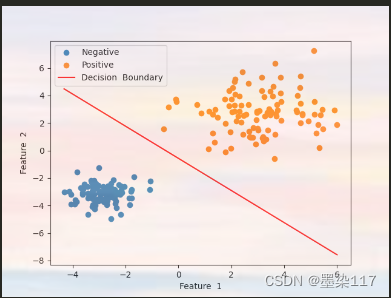
2.3.6、模型可视化
pred_neg = (output <= 0.5).view(-1) # 预测为负样本
pred_pos = (output > 0.5).view(-1) # 预测为正样本
plt.scatter(x[pred_neg, 0].numpy(), x[pred_neg, 1].numpy(), label='Negative') # 绘制负样本
plt.scatter(x[pred_pos, 0].numpy(), x[pred_pos, 1].numpy(), label='Positive') # 绘制正样本
w = ir_model.linear.weight.squeeze() # 获取权重并压缩维度
b = ir_model.linear.bias.item() # 获取偏置项
def draw_decision_boundary(w, b, x0):
x1 = (-b - w[0] * x0) / w[1] # 根据权重和偏置项计算决策边界
plt.plot(x0.detach().numpy(), x1.detach().numpy(), 'r', label='Decision Boundary')
x0 = torch.linspace(x[:, 0].min(), x[:, 0].max(), 50) # 在特征1的最小值和最大值之间生成50个点
draw_decision_boundary(w, b, x0)
plt.xlabel('Feature 1') # 设置x轴标签
plt.ylabel('Feature 2') # 设置y轴标签
plt.legend() # 显示图例
plt.show() # 显示绘制的图像
总结
本文详细介绍了机器学习中的基础内容,重点围绕PyTorch深度学习框架和Logistic回归模型展开。首先,我们深入探讨了PyTorch中的核心概念,包括Tensor对象、运算操作、自动微分等,为读者打下了坚实的理论基础。随后,我们对Logistic回归模型进行了全面而深入的剖析,涵盖了线性方程、激活函数、损失函数、优化算法以及模型可视化等关键内容。通过本文的学习,读者不仅能够掌握PyTorch框架的基本操作,还能够深入理解Logistic回归模型的原理和实际应用。希望本文能够为初学者提供一些帮助。















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









