







目录
(6)启动spark服务(确保已经配置ssh免密登录和时间同步)
一、集群搭建步骤说明
①解压、配置环境变量
②Workers主机名称
③配置Master、Workers、History
④创建EventLogs存储目录
⑤配置spark应用保存Eventlogs
⑥设置日志级别
⑦分发集群所有机器
⑧启动服务进程
⑨集群运行验证
注:①到⑦都在主节点操作即可
二、配置集群(Stand alone(非HA))
(1)上传压缩包并解压、配置环境变量



(2)修改配置文件名称和内容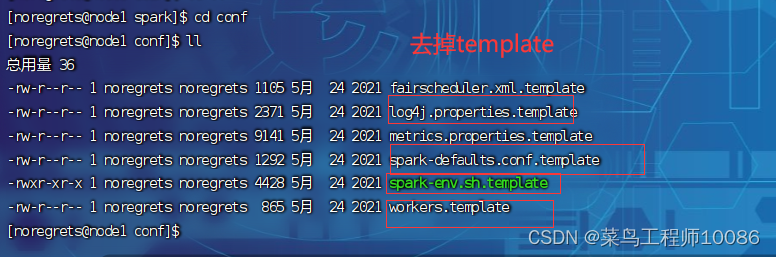
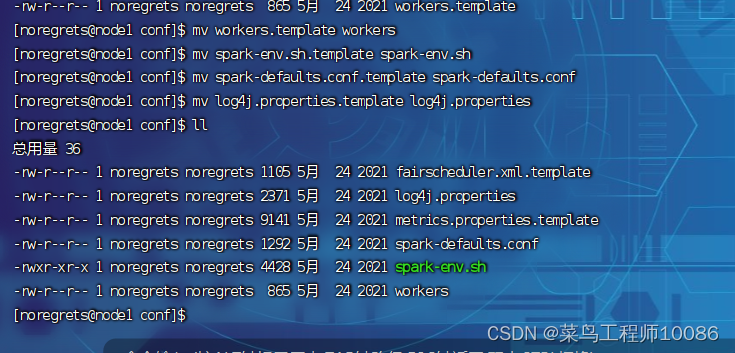
spark-env.sh文件
SPARK_MASTER_HOST=node1
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/spark/eventLogs/
-Dspark.history.fs.cleaner.enabled=true"


workers文件

(3)创建日志存储路径
启动Namenode
启动Datanode
创建存储目录

修改spark-defaults.conf文件
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/spark/eventLogs/
spark.eventLog.compress true
(4)设置日志级别
修改log4j.properties文件
(5)分发文件

配置环境变量

(6)启动spark服务(确保已经配置ssh免密登录和时间同步)
启动master(在spark的sbin目录下运行start-master.sh)

启动workers(在spark的sbin目录下运行start-workers.sh)


启动history(在spark的sbin目录下运行start-history-server.sh)


(7)测试集群
SPARK_HOME=/export/servers/spark
${SPARK_HOME}/bin/spark-submit \
--master spark://node1:7077 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.1.2.jar \ (注意查看jar名称是否正确)
100

三、集群搭建(Stands alone(HA))
Spark Stand alone集群式Master-Slaves架构的集群模式i,和大多数的Master-Slaves结构集群一样,存在着Master单点故障(SPOF)的问题。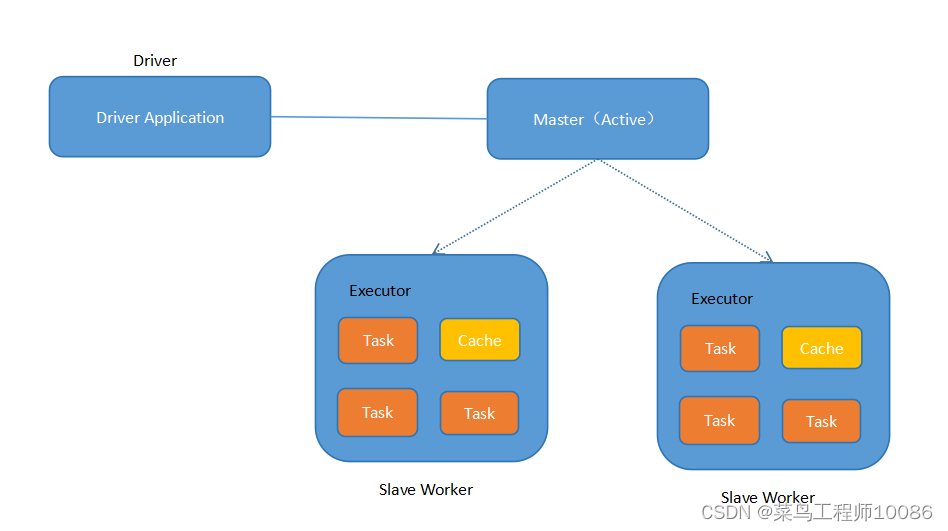 针对此问题spark提供了两种解决方案:
针对此问题spark提供了两种解决方案:
①基于文件系统的单点恢复(Single-None Recovery with Local File System)
②基于zookeeper的Standby Masters(Standby Masters with Zookeeper)
zookeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个master,但是只有一个式Active的,其他的都是Standby。当Active的master出现故障时,另外的一个standby master会被选举出来。由于集群的信息,包括worker、driver和application的信息都已经持久化到文件系统,因此在切换的过程中只会影响job的提交,对应正在进行的job没有任何影响。加入zookeeper的集群整体架构如下图所示。
(1)停止Stand alone集群
运行spark的sbin目录下的stop-master.sh
运行spark的sbin目录下的stop-workers.sh
配置spark-env.sh文件
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181
-Dspark.deploy.zookeeper.dir=/spark-ha"
注释原有master

(2)分发文件

(3)启动集群
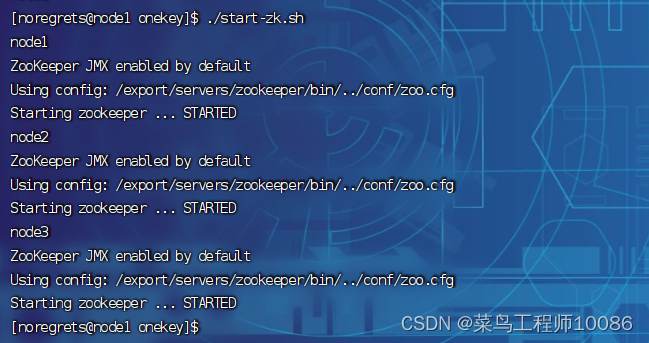
①启动zookeeper集群(这里我运行自己写的启动脚本)
②在每个机器启动master
/export/servers/spark/sbin/start-master.sh


在处于active的节点启动workers

③测试,提交PI运算

















 4489
4489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











