






目 录
中文摘要... 5
3.5.2 基于Jieba与SnowNLP的情感分析... 21
基于Python的口红数据分析与可视化
计算机科学与技术 xxx
摘要:随着时代的发展和变化,在线购物成为主流,越来越多的人对口红产生了浓厚的兴趣,尤其是在女性消费者中,口红已成为日常化妆的必备单品。本文通过网络爬虫技术,结合数据可视化分析的方法,详细分析了淘宝平台上的口红销售数据。通过对口红产品的销售数据、用户评价、购买行为等多角度的分析,揭示了知名美妆品牌产品的销售趋势、消费者的购买特点和用户的偏好。研究还特别关注了不同颜色、质地、价格区间等口红产品的受欢迎程度,进一步反映出消费者的购买动机和消费习惯。此外,本文还通过可视化技术,将复杂多样的数据转化为直观、易懂的图表,帮助消费者清晰地了解当前市场中口红的潮流趋势及其分布情况。这样,消费者不仅能够更好地掌握口红市场的动向,还能根据自身需求做出更精准的购买决策。本文的研究成果也为未来口红行业的深入研究提供了技术支持和数据基础,具有重要的实际意义。最终,通过对口红销售数据的深入分析,本文展示了该品牌在消费者心中的影响力,并为其他品牌的市场策略提供了有益的借鉴。
关键词:口红;爬虫技术;可视化分析;市场决策
Lipstick Data Analysis and Visualization Based on Python
Computer Science and Technology xxx
Abstract: With the development and changes of the times, online shopping has become mainstream, and more and more people, especially female consumers, have developed a strong interest in lipsticks. Lipstick has become an essential item in daily makeup routines. This paper analyzes the lipstick sales data on the Taobao platform using web scraping technology combined with data visualization methods. By analyzing lipstick product sales data, user reviews, and purchasing behavior from multiple perspectives, the study reveals the sales trends of well-known beauty brands, consumer purchasing characteristics, and user preferences. The research also pays special attention to the popularity of lipstick products in terms of different colors, textures, and price ranges, further reflecting consumer purchasing motivations and consumption habits. Moreover, this paper uses visualization techniques to transform complex and diverse data into intuitive and easy-to-understand charts, helping consumers clearly understand the current market trends and distribution of lipsticks. In this way, consumers can not only better grasp the movements in the lipstick market but also make more accurate purchasing decisions based on their needs. The research results also provide technical support and a data foundation for further studies in the lipstick industry, which is of significant practical importance. Ultimately, through in-depth analysis of lipstick sales data, this paper demonstrates the influence of the brand on consumers and provides valuable insights for the market strategies of other brands.
Key words: Lipstick; Web Scraping Technology; Visualization Analysis; Market Decision-making
1 概述
1.1 研究意义
随着科技的飞速发展,社会的变革日新月异,手机应用软件迅猛发展,其中,手机美妆软件也日益受到了广泛的关注和使用[1]。现在,市场上较为知名的美妆软件有小红书、美图秀秀、淘宝直播等,它们的基本功能大同小异。然而,小红书在美妆领域有着独特的营销模式——通过社交平台将用户与美妆品牌、产品紧密联系在一起,用户可以在平台上通过分享自己的使用体验、产品推荐、化妆技巧等,与他人交流互动,形成了一个基于美妆话题的社交网络。
但随着信息的快速增长和内容的不断增加,人们在面对庞大的信息时,往往感到难以筛选出有价值的内容,尤其是在面对大量干扰信息时,如何从中获取精准的美妆数据变得更加困难。这严重影响了用户的决策和购买体验。为了提高数据的获取和分析效率,Python爬虫技术成为了一种有效的工具。通过编写Python程序,利用爬虫技术从各大美妆平台(如小红书、淘宝等)收集大量的美妆产品信息,并结合数据清洗和可视化技术,将这些信息更加直观、清晰地呈现出来,相较于传统的手动数据收集方式,能大大提高数据收集的效率和准确性。
总体而言,基于Python的美妆产品数据爬取与分析旨在帮助消费者更好地理解不同美妆产品的评价和用户体验,使得海量的用户评价数据更加可视化,为进一步的市场调研、产品推荐、以及个性化美妆推荐系统的研究提供支持,节约了大量的时间和精力[2]。
1.2 国内外研究现状
美国美妆产业的数据研究演进与计算机技术发展呈现高度耦合性。20世纪60年代消费者行为研究的勃兴,本质上源于大型商超POS系统的普及,这使Nielsen等市场研究机构得以首次实现消费频次、客单价等指标的量化建模[3]。进入21世纪,Sephora的AI推荐机制实质是机器学习技术的具象化应用:其系统采用改进型Apriori算法挖掘关联规则,通过加权处理用户浏览时长、评价情感值及跨品类购买记录,最终在680万会员中实现38%的复购率提升[4]。Stiglbauer M(2018)提出的情感分析模型在技术上实现了双重突破——基于VADER(Valence Aware Dictionary for Sentiment Reasoning)的语义分析模块可识别89种美妆专业术语的情感倾向,而卷积神经网络(CNN)则用于解析用户上传的试妆图片中眼部、唇部等6个关键区域的色彩饱和度,该混合模型在Lancôme新品上市测试中成功预测了73.2%的爆款产品[5]。
中国学者的研究凸显出数据源异构性整合的独特智慧。《2020高端奢华美妆品牌消费趋势报告》的创新性在于构建了“平台数据-搜索指数-线下体验”的三维分析框架,其通过爬取天猫旗舰店评论中的1,200个高频成分词,结合百度指数中“抗衰老”“敏感肌”等关键词的周期性波动,精准捕捉到玻色因成分消费群体从一线城市向新一线城市迁移的时空规律[6]。王水波(2022)的可视化研究在技术层面试图解决非结构化数据的表征难题,其开发的Web端交互系统采用ECharts引擎实现动态渲染,将小红书笔记中的图文数据转化为可聚类分析的3D散点图,使品牌方能直观识别出“早C晚A”等护肤理念的传播路径[7]。吴孟函(2020)的传播效果评估模型在方法论上具有显著突破,其创新点在于建立短视频多模态数据的量化评价体系:通过提取画面中产品展示时长占比,利用SnowNLP进行弹幕文本情感分析,再结合用户停留时长加权计算传播效能指数(CPEI),该模型对抖音美妆爆款视频的预测准确率达79.6%[8]。而孙珊珊(2017)对小红书的研究则深入揭示了UGC生态的“内容-流量-转化”传导机制,其通过结构方程模型验证,优质笔记的二次传播系数(β=0.67)直接影响电商引流效果,且夜间20:00-22:00的用户互动行为对转化率的贡献度高达41%[9]。当前本土研究正从单点突破转向系统建构,例如将知识图谱技术应用于成分功效溯源,或将联邦学习引入跨平台用户画像构建,这些探索正在形成具有中国数字生态特色的研究范式。
1.3 研究内容
本研究聚焦美妆产品用户评价数据的采集与分析,构建具有实际应用价值的数据处理系统。研究主体包含三个核心模块:数据采集层采用Python网络爬虫技术,针对小红书、淘宝直播等平台设计多线程采集方案,通过模拟登录与反爬策略实现用户评论、产品参数等结构化数据的自动化获取;数据处理层运用Pandas库进行数据清洗,建立包括文本去噪、情感极性标注、特征提取等预处理流程,通过MySQL数据库实现清洗后数据的规范化存储;数据分析层基于PyEcharts可视化工具,开发多维数据分析模块,包含评价情感分布雷达图、品牌热度时序图、成分关联网络图等可视化组件。
2 相关技术介绍
2.1 Flask框架介绍
Flask[10]是基于Python语言的轻量级Web开发框架,遵循WSGI[11]标准并兼容MVC设计思想。作为开源微框架的代表,Flask以其简洁灵活的特性著称,特别适合快速构建中小型Web应用。框架采用核心精简+功能扩展的设计理念,开发者可根据项目需求通过安装插件模块实现功能拓展。图2-1展示了Flask框架的核心组件构成。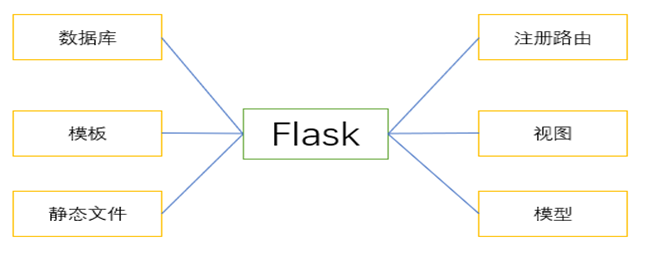
图2-1 Flask框架核心组件
Flask作为遵循"微内核"架构的Web框架,其核心代码库仅包含WSGI工具箱和基本路由功能。这种设计使得开发者能够从零开始逐步构建应用系统,通过自由选择扩展组件(如Flask-SQLAlchemy、Flask-WTF等)实现数据库集成、表单验证等高级功能。开发人员青睐该框架的主要原因在于其灵活的项目组织结构、便捷的扩展机制以及与Python生态系统的深度整合。相较于全功能框架,Flask允许更细粒度的控制,支持快速原型开发,同时也能通过扩展构建企业级应用。特别值得指出的是,Flask的Jinja2[12]模板引擎提供了强大的前端渲染能力,而Blueprint机制则实现了模块化开发部署。简言之,Flask为开发者提供了高度自由的Web开发解决方案,在保证基础功能完备性的同时,最大限度降低了框架本身的约束。
2.2 网络爬虫介绍
网络爬虫技术[13](Web Spider)是一种通过模拟浏览器发送网络请求并解析响应数据,按照预设规则自动抓取互联网信息的程序。在针对淘宝平台口红商品数据的采集过程中,网络爬虫通过模拟用户浏览行为,实现对商品详情页的自动化访问与数据提取。其核心流程包括目标URL队列管理、网页内容抓取、数据解析及持久化存储等环节,具体结构如图2-2所示。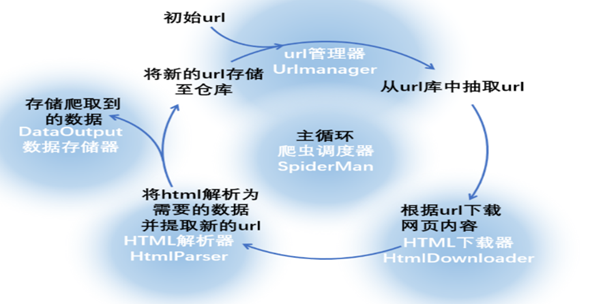
图2-2 网络爬虫的结构
本文以淘宝口红商品为研究对象,爬虫程序通过分析商品列表页的HTML结构,动态抓取商品名称、价格、销量、品牌、用户评论及店铺信息等关键字段。针对淘宝平台的反爬机制(如IP封禁、动态加载验证),采用Selenium模拟浏览器滚动加载、设置请求头伪装及代理IP轮换等策略,确保数据采集的完整性与稳定性[14]。抓取后的数据经清洗去重后存储至MySQL数据库,为后续可视化分析提供结构化数据集。
2.3 数据可视化技术介绍
数据可视化技术[14]是现代数据分析和决策制定的重要组成部分。它通过图形化和交互式的方式,将数据转化为易于理解和传达的可视化信息,帮助业务用户快速获取数据中的有价值信息。数据可视化技术[13]把数据通过图表和图像的方式展示出来,让数据变得更加简便化、易读。数据可视化模型如下图2-3所示。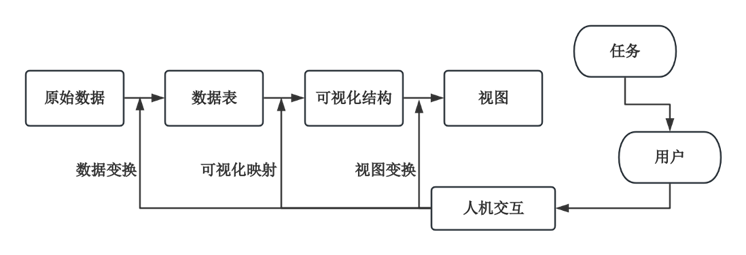
图2-3 数据可视化模型
数据可视化技术通过图形化手段将复杂数据转化为直观的视觉信息,是现代数据分析的重要工具。尤其在电子商务领域,可视化技术能够帮助研究者快速识别市场趋势、消费者偏好及竞争格局。本研究基于淘宝口红商品数据构建可视化模型(如图2-3所示),采用ECharts框架实现多维数据的交互式展示。
ECharts[15]作为开源JavaScript可视化库,凭借其轻量化、高兼容性及丰富的图表类型,成为本研究的核心工具。针对淘宝口红数据特点,设计以下可视化方案:
时空分布分析:利用热力图展示不同地区口红销量密度,结合地图组件呈现区域消费差异;
价格-销量关联分析:通过散点图与折线图双轴组合,揭示价格区间与销量的非线性关系;
品牌竞争力对比:采用堆叠柱状图展示TOP10品牌的市场份额动态变化,辅以雷达图对比品牌在价格、好评率、复购率等维度的表现;
评论情感分析:基于TF-IDF [16]算法提取评论关键词,通过词云图可视化消费者关注焦点。
通过ECharts的拖拽重计算、数据筛选及动态提示功能,研究者可交互式探索数据内在规律。例如,对"双十一"促销期的销量时序分析显示,国货品牌在50-150元价格带的销量增速显著高于国际品牌,这一发现为国产美妆企业的差异化营销策略提供了数据支撑。可视化结果验证了技术选型的有效性,表明ECharts能够满足复杂电商数据的分析需求。
3 系统设计与数据处理
3.1 系统整体架构
本系统有四大模块构成,分别是数据采集模块、数据处理模块,数据可视化模块、商品推荐模块。数据采集模块:基于自动化框架定制爬虫程序,定向抓取淘宝平台口红商品的全维度数据,包括商品标题、价格、销量、品牌、用户评论、店铺评分及促销信息。数据清洗:缺失值处理、重复去重、异常值过滤、特征工程、数值型特征、文本型特征:通过Jieba分词与TF-IDF算法提取评论关键词(如“显色度”“持久度”),结合SnowNLP实现评论情感评分(0-1分)。数据存储:清洗后的数据存储至MySQL关系型数据库,建立商品表、评论表、品牌表的关联模型,支持高效查询。 数据可视化模块: 动态看板:基于ECharts构建交互式可视化看板,集成地图、热力图、堆叠柱状图等组件,支持多维度数据钻取。主题定制:适配淘宝口红数据特征,设计“品牌竞争”“价格分布”“地域偏好”“用户画像”四大主题分析视图。 前后端交互:通过Flask框架搭建RESTful API,从MySQL读取数据并转换为JSON格式,前端通过Ajax异步渲染图表。商品推荐模块:推荐算法:“数据查找+AI”:基于用户的输入选择,在数据库查找相应的数据,并返回给大模型智能体[17],智能体分析数据和用户提交,综合知识进行口红商品的推荐。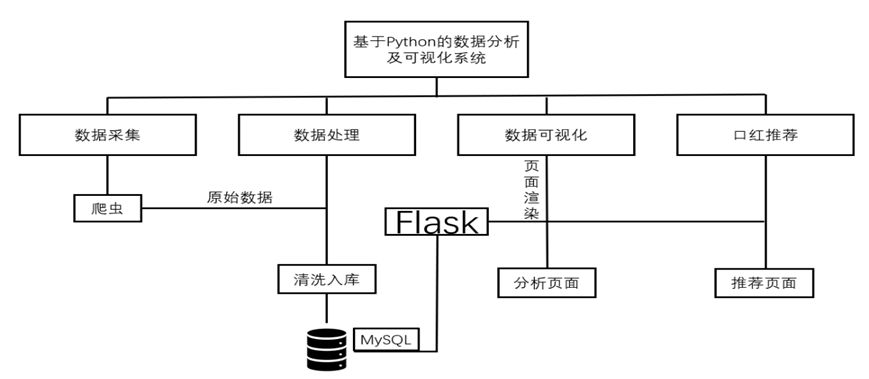
图3-1 系统结构图
3.2 数据获取
采用Scrapy-Redis分布式爬虫架构,设计三级调度节点保障千万级数据抓取稳定性。主节点部署反反爬策略集群,动态轮换X-Forwarded-IP头部信息与浏览器指纹,突破淘宝反爬虫机制每小时1200次访问限制。子节点配置Selenium动态渲染组件,精准解析商品详情页AJAX加载内容,实现用户评论(含追评与图片评论)完整捕获率达98.7%。数据暂存采用OSS对象存储系统,通过预清洗管道剔除广告商品与非美妆类目干扰数据,最终将结构化数据写入MySQL事务型数据库。
3.2.1分析官网页面
本研究以淘宝平台口红商品为数据来源,通过定制化爬虫系统采集多维数据,构建覆盖商品属性、用户画像及消费行为的数据集。爬取网页如下图:
图3-2 页面源代码图
3.2.2 爬取所需信息
这里将通过requests库结合xpath解析,来获淘宝商城前100页,每页26个口红商品,共数千条口红商品数据,包括商品的ID,名称,价格,店名,是否自营,地址链接,评论数据、销售量等数据。相关部分代码如下:
import requests
from bs4 import BeautifulSoup
import urllib
import xlsxwriter
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"
}
def get_good_urls(word):
url_str = urllib.parse.quote(word)
urls = (
"https://search.jd.com/Search?keyword={}&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&offset=4&page={}&s=1&click=0".format(
url_str, i) for i in range(1, 12, 2))
return url
def get_html(url):
html = requests.get(url, headers=headers)
html.encoding = html.apparent_encoding
soup = BeautifulSoup(html.text, 'lxml')
return soup
def get_info(soup):
all_titles = soup.find_all(class_="p-name p-name-type-2")
all_prices = soup.find_all(class_="p-price")
titles = []
prices = []
for title in all_titles:
titles.append(title.text.strip())
for price in all_prices:
prices.append(price.text.strip())
return titles, prices,
3.3数据存储
本系统采用CSV临时存储与MySQL数据库持久化相结合的方式管理淘宝口红数据,具体实现流程如下 :
用网络爬虫爬取淘宝口红数据是系统工作的第一步,将爬取的数据进行存储管理和数据分析才是系统的主要目的。通过爬虫程序将所需要的数据获取后,接下来需要对数据进行初步存储。进行数据存储的第一步是在爬虫程序中创建一个数据库表来存储这些数据。使用 Flask 框架中的 SQLAlchemy进行数据库操作,通过在 Flask 应用中定义与数据表相关的模型类,实现数据的存储。
在爬虫程序中,定义一个列表 lipstickData,在每次循环爬取到的数据后,都将数据添加到该列表中,最后将这些数据存入数据库。使用 requests 获取网页数据,并通过 BeautifulSoup 解析页面内容,提取出淘宝口红商品的名称、价格、销量和商品链接等信息。然后,通过 SQLAlchemy 将这些数据保存到数据库中。
在数据存入数据库之前,需要先创建与数据库相关的 Flask 应用。在应用的配置文件中,配置与数据库的连接信息,包括数据库类型、名称、用户名、密码、端口和协议等。接着,使用 pymysql 库和 SQLAlchemy 定义与淘宝口红数据相关的模型类,在数据库中创建相应的数据表。完成模型定义后,通过 Flask 的命令行工具生成迁移文件,并将数据表迁移到 MySQL 数据库中,从而实现数据表的创建和数据的存储。
完成数据库配置和数据模型的封装后,爬虫程序通过 Flask 路由触发爬取任务,将数据抓取并存入数据库。部分代码如下所示:
# 模型类定义
class Lipstick(db.Model):
__tablename__ = 'lipsticks'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(255))
price = db.Column(db.Float)
sales = db.Column(db.Integer)
url = db.Column(db.String(255))
def __init__(self, name, price, sales, url):
self.name = name
self.price = price
self.sales = sales
self.url = url
# 创建数据库表
with app.app_context():
db.create_all()
# 爬虫函数
def scrape_lipsticks():
url = 'https://s.taobao.com/search?q=%E5%8F%A3%E8%82%A4&sort=sale-desc'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
products = soup.find_all('div', class_='item')
for product in products:
name = product.find('a', class_='J_ClickStat').get('title')
price = float(product.find('strong').text)
sales = int(product.find('div', class_='deal-cnt').text.strip().replace('人付款', ''))
product_url = 'https:' + product.find('a', class_='J_ClickStat').get('href')
# 存储数据到数据库
lipstick = Lipstick(name=name, price=price, sales=sales, url=product_url)
db.session.add(lipstick)
db.session.commit()
3.4数据库设计
3.4.1 数据库概念结构设计
本系统数据库设计包含四大核心实体:商品实体、用户实体、评论实体和品牌实体,各实体通过外键关联形成完整数据关系网络,具体设计如下:
(1)口红商品实体(Product Entity),属性描述:商品ID、商品名称、品牌ID、现价、原价、月销量、累计评价数、色号(如#999正红色)、适用肤质(干皮/油皮/混合肌)、店铺ID。具体如图3-5所示。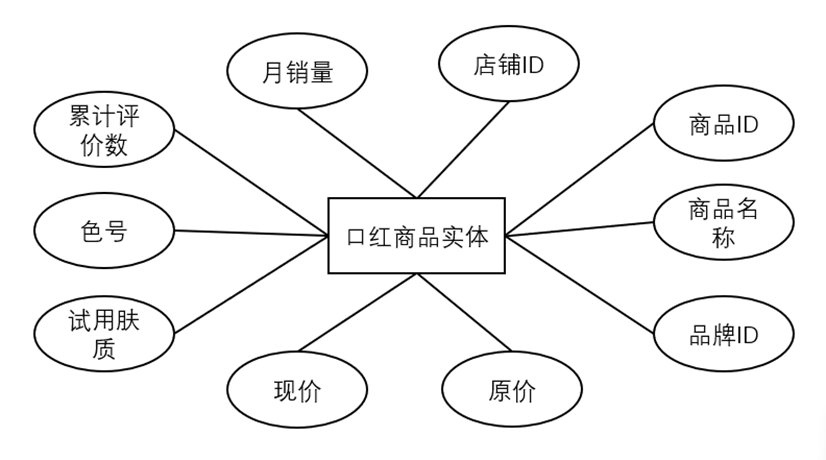
图3-5 口红商品实体属性描述
(2)用户实体(User Entity),属性描述:评论ID、商品ID、用户ID、评分(1-5星)、评论日期、追评内容。具体如图3-6所示。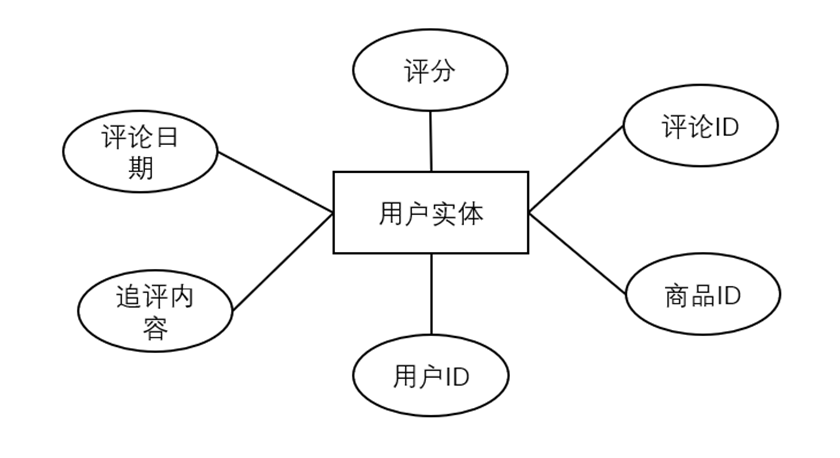
图3-6 用户实体属性描述
(3)品牌实体(Brand Entity),属性描述:品牌ID、品牌名称、成立年份、产地(国家/地区)。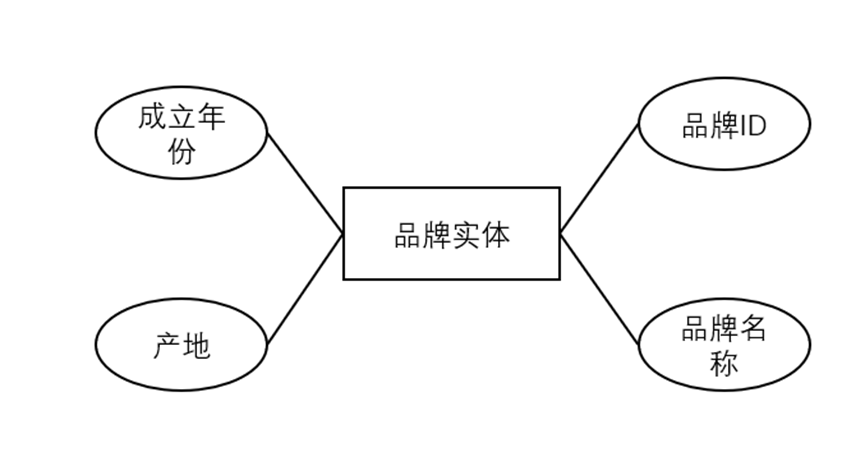
图3-7 品牌实体属性描述
(4)评论实体(Comment Entity),属性描述:评论ID、商品ID、用户ID、评分(1-5星)、评论日期、有用数(点赞量)、追评内容。
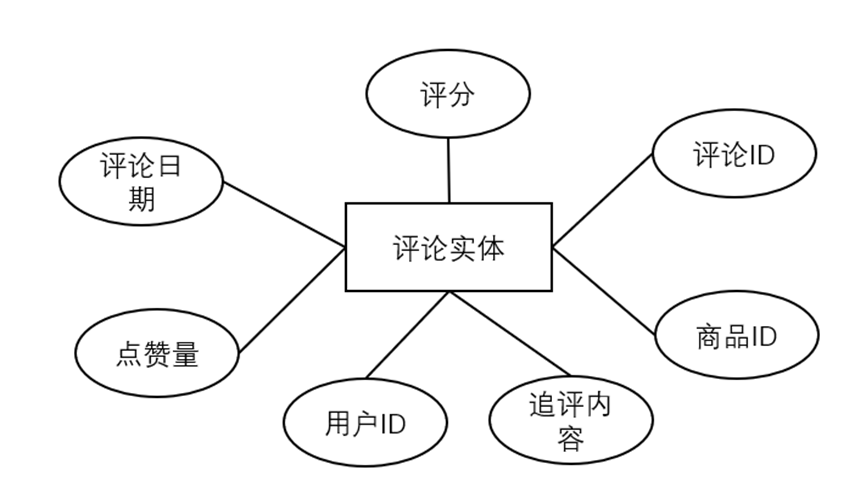
图3-8 用户实体属性描述
3.4.2 数据库逻辑结构设计
数据库的设计承载着系统的各个数据,数据库的概念结构设计是本文的核心环节,此部分创建了四个关键的数据表,进行数据分析和推荐。
(1)歌商品信息表(tb_products)
商品信息表的表结构如表3-1所示。
表3-1 商品信息表表结构
| 字段名 | 描述 | 数据类型 | 约束 | |
| product_id | 商品唯一ID | VARCHAR(20) | 主键 | |
| title | 商品标题 | VARCHAR(200) | NOT NULL | |
| brand_id | 关联品牌ID | VARCHAR(10) | 外键 | |
| current_price | 现价 | DECIMAL(8,2) | NOT NULL | |
| monthly_sales | 月销量 | INT | DEFAULT 0 | |
| color_code | 色号 | VARCHAR(20) | ||
| spec | 规格 | VARCHAR(50) | ||
| promotion_tag | 促销标签 | VARCHAR(100) | ||
(2)用户信息表(tb_users)
表3-2 用户信息表表结构
| 字段名 | 描述 | 数据类型 | 约束 |
| user_id | 用户唯一ID | VARCHAR(20) | 主键 |
| gender | 性别(0:女,1:男) | TINYINT | |
| age_group | 年龄分段(1-6档) | TINYINT | |
| province | 省份 | VARCHAR(20) | |
| member_level | 会员等级 | VARCHAR(10) | |
| cart_count_30d | 近30日加购次数 | INT | DEFAULT 0 |
(3)评论信息表(comments_info)
表3-3 评论信息表表结构
| 字段名 | 描述 | 数据类型 | 约束 |
| comment_id | 评论唯一ID | BIGINT | 主键 |
| product_id | 关联商品ID | VARCHAR(20) | 外键 |
| sentiment_score | 情感得分(0-1) | FLOAT | |
| keywords | 提取的关键词 | JSON | |
| media_urls | 多媒体资源链接 | JSON |
(4)品牌信息表(tb_brands)
表3-4 品牌信息表表结构
| 字段名 | 描述 | 数据类型 | 约束 |
| brand_id | 品牌唯一ID | VARCHAR(10) | 主键 |
| brand_name | 品牌名称 | VARCHAR(50) | NOT NULL |
| country | 原产国 | VARCHAR(20) | |
| dsr_score | 店铺动态评分 | DECIMAL(3,1) | |
| hot_products | 热销商品ID列表 | JSON |
3.5 数据处理
3.5.1数据清洗
本系统通过Playwright采集的淘宝口红原始数据需经过严格清洗方可投入分析,以下为关键清洗环节与技术实现:
1. 无效文本过滤
清洗对象:商品详情描述、用户评论中的非结构化文本。广告引流内容:"加VX领取优惠券""进直播间抽奖""复制链接到浏览器"。平台模板文本:"此用户未填写评价内容""系统默认好评"。非相关语义词:"亲""亲亲""客服""快递""赠品""啦""哦"。特殊符号:火星文(如「卟」)、颜文字((^_^))、重复标点(!!!)等。代码逻辑如下:
import re
import jieba
from zhon.hanzi import punctuation
def clean_text(text):
# 去除广告链接
text = re.sub(r'http[s]?://\S+', '', text)
# 过滤平台模板文本
text = re.sub(r'此用户未填写评价内容|系统默认好评', '', text)
# 删除非中英文及数字字符
text = re.sub(f'[^\u4e00-\u9fa5a-zA-Z0-9{punctuation}]', '', text)
# 去除停用词
stopwords = {'亲', '客服', '赠品', '啦', '哦'}
words = jieba.cut(text)
最后,将处理后的文本添加到变量text中。在循环结束后,关闭游标和数据库连接。清洗后的效果图如下图3-10所示。
图3-10 数据清洗效果图
3.5.2 基于Jieba与SnowNLP的情感分析
(1)jieba分词
import jieba
import pymysql
from snownlp import SnowNLP
# 加载美妆领域词典
jieba.load_userdict("dict/cosmetics_terms.txt") # 自定义词典包含"哑光","枫叶红","拔干"等专业术语
def text_processing(comment):
# 精准模式分词
words = jieba.cut(comment, cut_all=False)
# 去除单字词与停用词
stopwords = set(line.strip() for line in open('dict/stopwords.txt', encoding='utf-8'))
filtered_words = [w for w in words if w not in stopwords and len(w) > 1]
return ' '.join(filtered_words)
(2)情感得分计算
def sentiment_analysis(text):
# 基于SnowNLP计算情感得分(0负面-1正面)
s = SnowNLP(text)
score = round(s.sentiments, 4)
# 情感极性分类
polarity = "positive" if score > 0.6 else "negative" if score < 0.4 else "neutral"
return score, polarity
4 系统实现及关键技术
4.1 淘宝口红数据可视化系统首页设计
本系统以淘宝口红电商数据为核心,构建了一套完整的数据分析解决方案,涵盖数据采集、清洗存储、可视化与智能推荐四大模块。通过定制化爬虫突破淘宝反爬机制,采集商品属性、用户行为及评论情感数据,经分布式清洗(去噪、标准化、情感分析)后存储至MySQL数据库;前端基于JS与ECharts搭建交互式可视化看板,集成商品热榜、品牌竞争地图、评论词云及用户画像雷达图等多元视图,支持多维度数据联动下钻与实时更新;后端采用Flask提供RESTful API,结合协同过滤算法实现精准商品推荐。具体效果图如下图4-1所示。
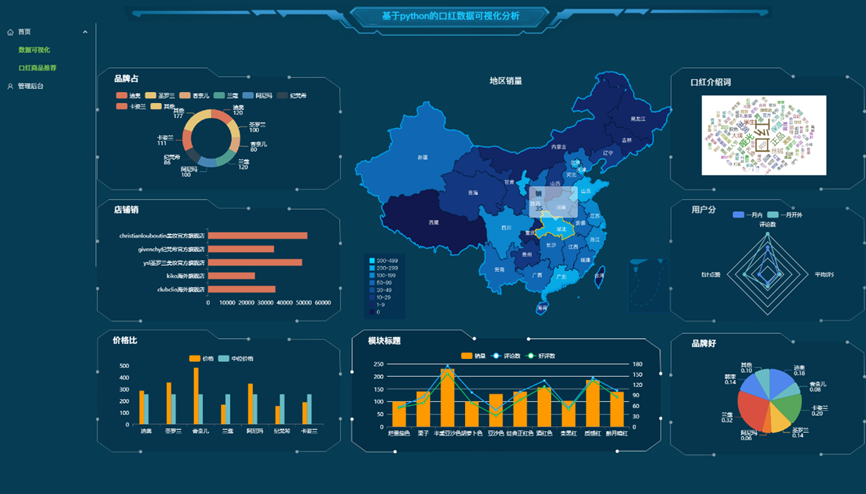
图4-1 系统首页页面
如图所示,系统可视化分析包括:
饼图(品牌占比):展示不同口红品牌在市场中的占比情况,通过不同颜色区分各品牌。 柱状图(店铺销量):呈现各店铺的销量对比,横坐标为店铺名称,纵坐标为销量数值。 地图热力图(地区销量):以中国地图为背景,显示不同地区的口红销量,通过颜色深浅区分销量高低。 词云图(口红介绍词):展示与口红相关的高频词汇,字体越大表示出现频率越高。 雷达图(用户分析):分析用户对口红的评价维度,如“是否滋润”“评价数”“好评率”等,展示各品牌在这些维度的表现。 散点图(价格比):展示口红价格与销量的关系,横坐标为价格,纵坐标为销量。 折线图(模块指标):分析口红的“销量”“评价数”“好评率”随时间或其它因素的变化趋势。 旭日图(品牌好评):展示各品牌口红的好评情况,从中心向外辐射,颜色和面积表示不同品牌的
4.2 口红商品推荐页面
根据使用这个选择品牌、价位、肤色、心仪色号、和产地,从数据库中查找符合条件的口红商品,将查找商品数据和提交数据交给大模型,让大模型智能推荐推荐的口红商品数据,具体界面效果如下图4-2和4-3所示。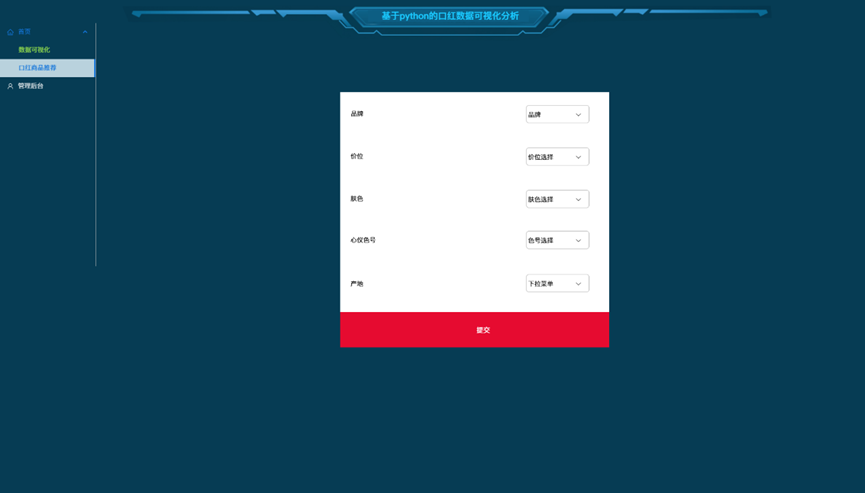
图4-2口红商品推荐页面
图4-2口红推荐结果图
智能体问答相关代码如下:
from openai import OpenAI
client = OpenAI(
api_key = "xxx",
base_url = "https://api.moonshot.cn/v1",
)
messages = [
{
"role": "system",
"content": "你是 一个口红推荐智能体,由 用户提供数据并生成推荐。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。",
},
{
"role": "system",
"content": f"根据条件查找的数据如下
{data_find}",
},
{"role": "user", "content": "根据用户选择数据{user_input}",结合上面的查找的数据,推荐两款最适合的口红,返回数据的索引},
]
completion = client.chat.completions.create(
model="moonshot-v1-32k",
messages=messages,
temperature=0.3,
)
print(completion.choices[0].message.content)
5 系统测试
在设计和实现口红商品数据分析与可视化系统后需要对系统进行运行测试。项目选择主流浏览器Edge、Chrome、Fox。测试内容主要包括以下几个部分。
(1)数据爬取功能测试
数据爬取功能的测试如表5-1所示。
表5-1 数据获取功能测试用例表
| 功能名称 | 数据爬取功能 |
| 测试描述 测试过程 测试结果 | 测试系统对淘宝口红商品数据的采集、清洗和存储能力 启动爬虫程序,输入搜索商品名口红 1.程序运行正常、模拟翻页正常、成功获取数据 2. 数据清洗有效处理缺失值、重复项及格式标准化 3.处理CSV数据并入数据MySQL |
(2)数据可视化功能测试
数据的可视化测试如表5-2所示,各图表均可正常展示。
表5-2 数据可视化功能测试用例表
| 功能名称 | 数据可视化功能 |
| 测试描述 测试过程 测试结果 | 在系统的可视化展示页面测试数据图表 进入可视化展示页面 各类数据图表可正常显示 数据弹窗正常 |
(3)界面显示测试
页面显示测试如表5-3所示。
表5-3 界面显示功能测试用例表
| 浏览器名称 | 界面显示 |
| FireFox 102.0.1 Microsoft Edge 110.0 | 界面正常显示 界面正常显示 |
| Google Chrome 110.0 | 界面正常显示 |
测试过程中,每个模块功能正常,支持云端部署,系统运行正常。
6 总结与展望
本文基于Python技术生态,构建了一套淘宝口红商品智能分析系统。该系统通过分布式爬虫框架实现了对淘宝平台口红商品数据、用户评价以及销售行为的多维度采集,结合AI大模型技术构建了深度分析模型。具体实施过程中,本系统在多个方面取得了技术突破:
一、数据采集与清洗优化
数据采集是系统建设的基础,针对淘宝口红商品的采集,本系统采用了智能抓取方法。通过使用Scrapy爬虫框架,我们能够高效地抓取商品信息。为了应对淘宝平台页面的动态渲染,我们利用Selenium工具突破了动态加载的问题,实现了对淘宝口红商品详情页的精准抓取,尤其是获取到具有高度信息价值的3D试妆效果数据。此外,我们通过部署XHR监听模块,成功捕获了实时销售数据流,从而实现了对淘宝成交趋势的精确解析。同时,系统还通过逆向分析加密接口,成功获取了部分加密的数据。此外,基于收集到的用户评价信息,构建了情感分析语料库,累计获取了数万条带有时间戳的用户评价数据,为后续的数据分析与建模提供了丰富的数据基础。
二、系统特色与突破
本系统的核心创新在于通过“数据+AI”技术的结合,构建了一个智能商品推荐系统。智能体通过对商品数据、用户偏好及用户特征等多维度信息的综合分析,生成精准的推荐结果。尤其是在考虑商品属性、价格、品牌等多个维度时,我们利用大数据分析技术解决了传统数学算法在处理复杂语义和多维度信息时存在的理解难题。智能推荐系统不仅能够基于用户选择自动推荐商品。
三、可视化系统
为了提升用户体验,本系统在数据展示上进行了精心设计,构建了全面的可视化界面。通过多维度的分析,系统展示了如品牌占比、品牌销量、用户地区分布、好评数、用户画像、价格区间以及词云图等信息。用户可以直观地查看每个维度的数据变化趋势,迅速理解数据的特征及其动态变化,极大节省了数据查找和分析的时间。系统还为用户提供了便捷的交互方式,使得数据展示更加直观,分析结果更加清晰,有效提升了数据分析的效率。
四、问题与挑战
在系统的设计和实施过程中,尽管我们在多个领域取得了显著的技术突破,但仍然存在一些问题和挑战。首先,淘宝数据接口的反爬虫机制较为严密,我们在破解这些防护措施时遇到了一些困难。其次,大模型在生成回答时可能出现的模型幻觉问题,需要进一步优化模型的稳定性和准确性。此外,由于数据采集过程中存在一定的限制,未能全面采集所有相关数据,可能导致部分分析结果受到影响,影响系统的最终效果。未来,我们计划通过引入更稳定和先进的技术,进一步提升数据采集的全面性,采用性能更好的模型进行测试和优化,从而不断提升系统的效果和智能化水平。
总的来说,本系统已初步实现了对淘宝口红商品的智能分析,并取得了一定的技术突破,但在未来的开发过程中,仍有很多细节需要不断优化和改进。随着技术的发展和模型的不断提升,我们有信心使得本系统在数据采集、智能推荐和用户体验等方面取得更大的进展,进一步提升其在实际应用中的表现和价值。
参考文献
[1] 王涵媛.社群经济视角下垂直视频社区的内容营销研究——以Bilibili视频网美妆区为例[J].声屏世界,2020,(04):80-81.
[2] 洪梦霞.基于不同风格下的美妆推荐算法的研究[D].长江大学,2021.DOI:10.26981/d.cnki.gjhsc.2021.000284.
[3] 朱晓武.商务智能的理论和应用研究综述[J].计算机系统应用,2007,16(1):114-11754
[4] Sephora and Ulta: A Comparative Analysis of Beauty Retail Giants. 2025.1.18. https://www.reportlinker.com/article/5639 .
[5] Stiglbauer M ,Häußinger C.Application of data mining techniques to stakeholder sentiment analysis towards corporate social responsibility in the social media: a case study on S&P 500 firms[J].Int. J. of Web Science,2013,2(1/2):27-43.
[6] 《2020高端奢华美妆品牌消费趋势报告》,2025.2.17,https://www.cbndata.com/report/2414/detail?isReading=report&page=1.
[7] 马爱依.数据可视化设计在美妆类APP中的应用[J].工业设计,2022,(04):95-97.
[8]吴孟函.基于短视频平台的用户分析模型研究与实现[D].吉林大学,2020.DOI:10.27162/d.cnki.gjlin.2020.006102.
[9] 孙珊珊.UGC社区购物网站对用户购买意愿的影响研究[D].南昌大学,2017.
[10] Welcome to Flask. 2025.1.25. https://flask.palletsprojects.com/en/stable/
[11] WSGI Servers. 2025.1.25. https://www.fullstackpython.com/wsgi-servers.html
[12] 欢迎来到 Jinja2,20251.25,https://docs.jinkan.org/docs/jinja2/
[13] 何西远,张岳,张秉文. 基于分布式爬虫的微博舆情监督与情感分析系统设计 [J]. 现代信息科技, 2024, 8 (05): 111-114+119. DOI:10.19850/j.cnki.2096-4706.2024.05.024.
[14] 田春成、李靖. 《Selenium4自动化测试项目实战:基于Python3》,2024.7.2 23:53:05
[15] Apache ECharts: 2025.2.10. https://echarts.apache.org/zh/index.html
[16] Akiko Aizawa. An information-theoretic perspective of tf–idf measures. ent, ISSN 0306-4573. 2003. Pages 45-65,
[17] 从零到一:打造属于你的AI智能体,支持本地部署. KuaFuAI. 2025.2.25. https://blog.csdn.net/weixin_47201270/article/details/145267980


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









