






摘要
本研究旨在提高交通安全和改善驾驶习惯,通过实时监测驾驶员行为并及时发出警报来预防交通事故。研究背景是随着汽车保有量的增加和智能交通系统的兴起,驾驶员行为监测技术变得尤为重要。本研究的主要目标是利用YOLOv8算法提高对驾驶危险行为的识别准确性,并实现系统的实时响应
研究方法包括采用YOLOv8模型进行目标检测,结合检测头和分类头预测目标定位框,以及使用pyttsx3模块进行语言合成技术,以实现轻量化的语音反馈。
研究结果表明,改进后的SEAttention-YOLOv8模型在驾驶场景下表现出优异的识别精度(map50-95为0.826),语音反馈机制能有效及时警告驾驶员。该系统在提高交通安全、改善驾驶习惯以及支持交通管理方面具有显著效果。本研究不仅提高了驾驶行为识别的准确性和系统的实时性,还通过语音反馈机制增强了系统的人性化。这些成果对于降低交通事故发生率、减少社会成本具有重要的理论和实践意义,并为未来智能交通系统的发展提供了新的方向。
关键词:智能交通系统;YOLOv8;目标检测;语音反馈
目 录
······
3 基于YOLO算法的模型构建与实验
3.1 YOLO模型与SEAttention机制
本文使用的模型是SEAttention-YOLOv8框架,是基于经典的模型加入通道注意力(SEAttention)机制。
3.1.1 YOLOv8模型
YOLOv8是YOLO(You Only Look Once)系列目标检测模型的较新版本,它在YOLOv5的基础上进行了进一步的优化与提升,成为更加高效和精准的目标检测模型。
YOLOv8模型骨干网络和 Neck 部分参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数。
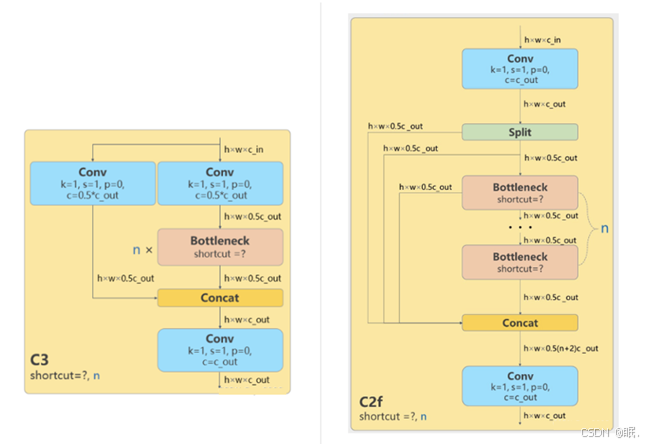
图3-1 C3和C2f结构
Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free,这意味着模型不再依赖于预定义的Anchor框,而是通过直接回归目标的中心点、边界框宽高等信息来进行目标定位。不再需要手动设计Anchor框,降低了实验和调参的复杂度,加适应不同类型的目标和场景,尤其是对于一些形状不规则或者大小差异较大的物体。
Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss。它通过引入分布的概念来优化Focal Loss的表现。优化包括通过考虑类别的分布,进一步提高了对难分类目标的关注,使得模型能够更好地处理类别不平衡问题。传统的Focal Loss对小物体的识别能力可能较弱,因为小物体通常与背景重叠较多,容易被忽视。Distribution Focal Loss通过更加细化的权重分配,增强了对这些小物体的关注,从而提升了对小物体的检测精度。YOLOv8通常会在多尺度下进行训练,Distribution Focal Loss能够帮助在不同尺度下对各类目标进行优化,尤其是对于那些在图像中占据较小区域的目标。
同时训练的数据增强部分引入了 YOLOX[9] 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度。
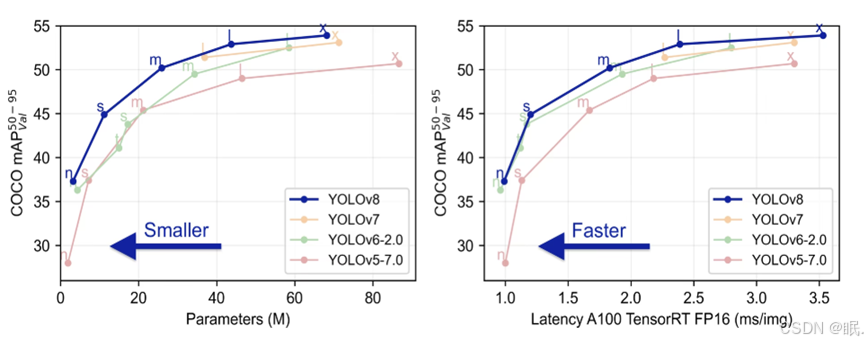
图3-2 YOLOv8模型效果优势
下面介绍通道注意力机制。
3.1.2 通道注意力机制
SE是指"Squeeze-and-Excitation",是一种用于增强卷积神经网络(CNN)的注意力机制。SE网络结构由Jie Hu等人在2018年提出,其核心思想是在卷积神经网络中引入一个全局的注意力机制,以自适应地学习每个通道的重要性。
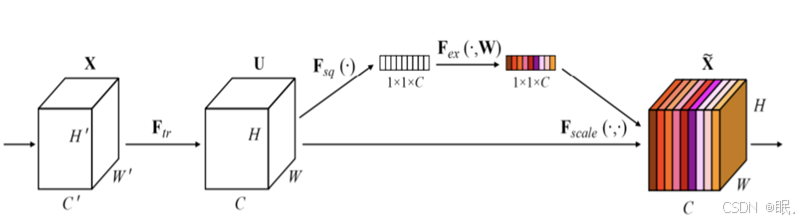
图3-3 SE网络结构
SE网络首先通过输入的特征图 (例如,卷积层输出的特征图),SEAttention通过全局平均池化 (Global Average Pooling, GAP) 操作对每个通道的空间信息进行压缩。具体地,假设输入特征图的尺寸是𝐻×𝑊×𝐶 (其中𝐻和𝑊是特征图的高和宽,𝐶是通道数),全局平均池化操作会对每个通道的所有空间位置进行平均,得到一个长度为𝐶 的向量:
zc=1H×Wi=1H j=1Wxijc, for each channel c (1)
接下来,SEAttention通过一个全连接(FC)层对压缩后的特征向量进行处理,生成每个通道的权重。具体来说,先经过一个瓶颈层(通常是通过减少维度的方式),然后通过ReLU激活函数,再通过一个恢复维度的全连接层,最后得到一个通道权重向量:通过引入SE模块,CNN可以自适应地学习每个通道的重要性,从而提高模型的表现能力。SE网络在多个图像分类任务中取得了很好的效果,并被广泛应用于各种视觉任务中。
s=σW2δW1z
(2)
其中W1 和 W2是全连接层的权重矩阵,δ 是ReLU激活函数,σ 是Sigmoid激活函数(用于将输出限制在0到1之间),s是每个通道的权重向量。
最后进行重校准,SEAttention将生成的通道权重向量与原始特征图进行逐通道的加权操作,即通过对每个通道的特征图进行乘法操作,得到调整后的特征图。
SEAttention的核心思想就是通过“压缩”和“激活”两个步骤,自动学习每个通道的重要性,并通过这种自适应的通道重校准,来增强网络对有用特征的敏感性,抑制不重要的信息,从而提升模型的表达能力和性能。
本文将SEAttention机制加入到YOLOv8框架的backbone SPPF模块后,一方面增强模型在特征学习方面的处理能力,另一方面只加入一个SEAttention模块,降低训练成本:
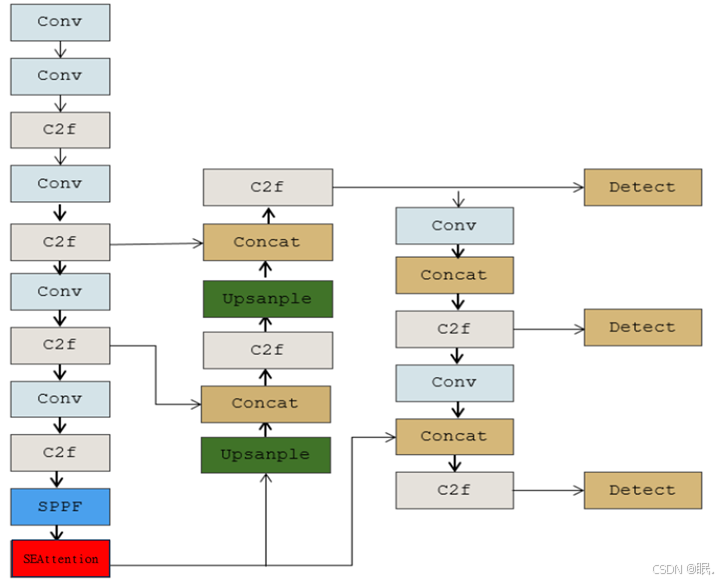
图3-4 图4-4 SEAttetion-YOLOv8结构
3.2实验设计
3.2.1 实验目标
本文设计一组对比实验,评估并比较下面两个模型在驾驶行为检测任务中的性能。
基础YOLOv8模型:仅使用标准的YOLOv8架构进行驾驶行为检测。
YOLOv8+SEAttention模型:在YOLOv8的SPPF模块后加入SEAttention模块,以提升模型在复杂驾驶场景中的表现。
3.2.2 实验步骤
(1)数据处理:本文将数据集进行从灰度图到RGB的颜色处理和像素进行超清晰度处理,处理模型为DDclolr[10]和SRGAN[11]。然后采用标注工具labelimg[12]进行手工标注。数据集包括“分心驾驶”、“喝水”、“打哈欠”等行为的标注图片。然后通过原生的YOLOv8的数据增强方式进行如旋转、拼接、噪声添加等操作。
(2)模型架构:基础YOLOv8模型:使用YOLOv8的标准架构,采用SPPF(Spatial Pyramid Pooling Fast)模块处理特征图,进行多尺度特征融合
YOLOv8+SEAttention模型:在YOLOv8模型中,保持SPPF模块,加入SEAttention模块。SEAttention是一种通过显式建模通道间的依赖关系来增强特征图的模块,通常能提高模型的表现。结合SPPF模块后,SEAttention模块将帮助网络在多尺度的特征图中关注更重要的区域,提升对细节和异常行为的敏感性。SEAttention模块结构:对SPPF输出的特征图应用SE模块,利用通道注意力机制对不同通道的特征进行加权,从而提升对目标特征的表示能力。
(3)实验设置:实验平台:
表3-1 实验平台
| 实验平台 | 值 |
| 系统 | Ubuntu22.04 |
| CUDA | 12.4 |
| GPU | 24G |
| Pytorch[8] | 2.43 |
在训练YOLO模型时,选择适当的超参数对于获得好的性能至关重要。YOLO模型的超参数包括学习率、批次大小、权重衰减、优化器选择等,可以直接影响模型的收敛速度、精度以及泛化能力。对比经典YOLOv8和加入SEAttention的YOLOv8模型,超参数设置:
表3-2 YOLO模型训练超参数配置
| 超参数 | YOLOv8 | SEAttention-YOLOv8 |
| epochs | 100 | 25 |
| batch | 16 | 24 |
| imgsz | 640 | 640 |
| pretrained | yolov8x.pt | yolov8x.pt |
| optimizer | auto | auto |
| iou | 0.7 | 0.7 |
其中,优化器控制如何更新神经网络的权重。在YOLO模型中,auto选择的优化器包括AdamW[13]、SGD[14]两种优化器,根据计算公式:
iterations=NmaxB,n×E (3)
N 表示训练数据集的样本总数,B 表示批量大小,n 表示每个批次的批量大小,E表示训练的总轮数。如果iterations
数值大于10000为SGD优化器,反之则为AdamW,通过计算本文的优化器为AdamW。
(4)评估指标:
mAP50-95[11]:表示在不同的IoU(Intersection over Union,交并比)阈值下计算的平均精度。具体是指计算在 IoU 阈值从 0.5 到 0.95 范围内,每 0.05 增量的不同阈值下的平均精度(AP)。
mAP50:特定于 IoU ≥ 0.5 时的精度,比较松散的标准。
F1 Score:综合精度与召回率的调和平均,关注模型在精度与召回率之间的平衡。
PR:在分类任务中,模型的输出通常是一个概率值,根据这个概率值,模型会有一个分类阈值,决定是否将某个样本判定为正类。当阈值变化时,精度和召回率会发生变化。
3.3 结果对比
实验表明,在加入SEAttention的模型效果达到map50-95(其含义是在置信度0.5-0.95每5%跨越下检测的平均精度)为0.839,相较于经典模型0.534有巨大提升。
相关指标对比如下:
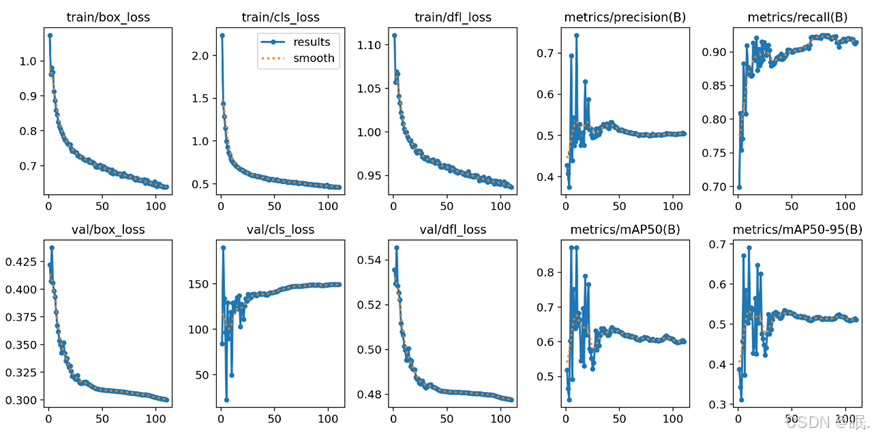
图3-5 YOLOv8模型训练结果
上图是经典YOLOv8模型的训练结果图像,其中较为重要的map50和map50-95指标均上下波动较大,且map50-95仅为0.534。
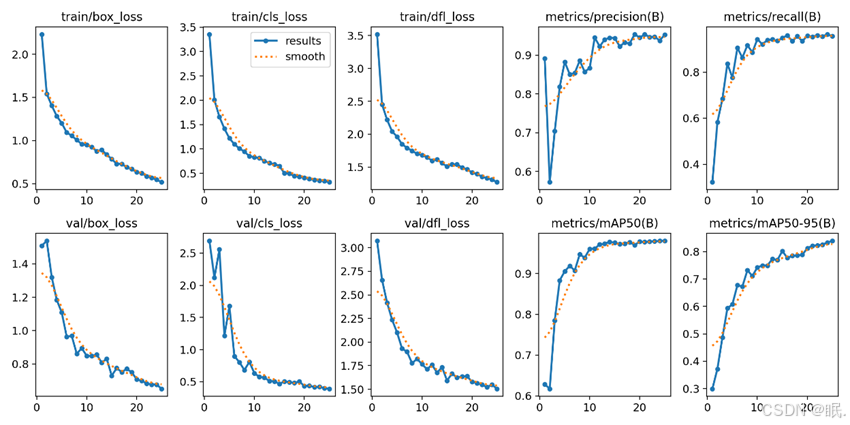
图3-6 SEAttention-YOLOv8模型训练结果
上图是加入SEAttention的YOLOv8模型的训练结果,可以发现,各类损失均呈平滑的下降趋势,且map50和map50-95分别达到0.986和0.839,效果提升明显。其他指标对比如下
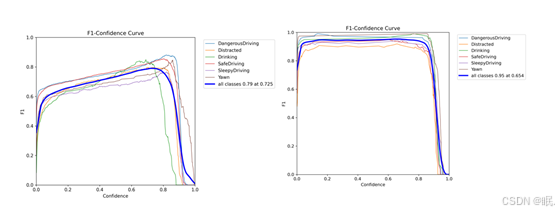
图3-7 YOLO模型F1值比较
上图左为经典YOLO模型,右为加入SEAttention的,可见,加入通道注意力后的F1指标也明显优于未加的。下面进行PR曲线的比较:
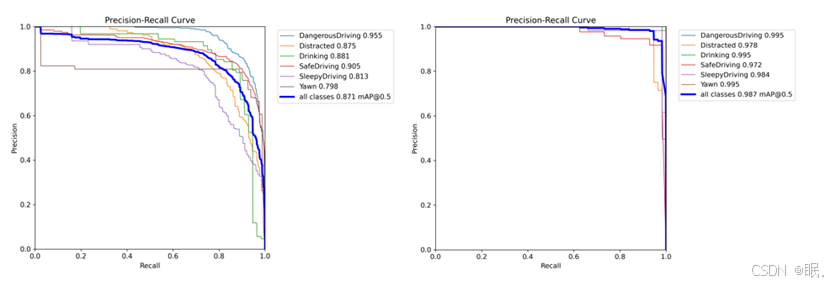
图3-8 YOLO模型PR曲线比较
曲线越接近左上角:表示模型的表现越好,因为左上角对应着较高的精确度和召回率。曲线下的面积(AUC-PR):PR曲线下面积(Area Under Curve)可以作为衡量模型性能的指标。AUC值越接近1,说明模型性能越好。由此可看,图4-左是经典的YOLO模型效果同样低于加入SEAttention的模型。
具体指标如下表:
表3-3 实验结果指标
| 指标 | SEAttention-YOLOv8 | YOLOv8 |
| map50-95 | 0.839 | 0.534 |
| map50 | 0.986 | 0.600 |
| F1 | 0.740 | 0.725 |
| PR | 0.986 | 0.871 |
3.4 本章总结
本章围绕基于YOLO算法的模型构建与实验展开,重点介绍了YOLOv8模型的优化与SEAttention机制的应用。YOLOv8模型在YOLOv5基础上进行了多项优化,包括改进的骨干网络、Neck部分的设计、解耦头结构以及优化的Loss计算方式。SEAttention机制通过自适应通道重校准,提升了模型对重要特征的敏感性,从而提高了性能。
实验设计上,通过对比YOLOv8和YOLOv8+SEAttention模型在驾驶行为检测任务中的表现,验证了SEAttention机制的有效性。实验结果表明,加入SEAttention后的YOLOv8模型在多个评估指标上(如mAP50-95、mAP50、F1 Score、PR等)均优于经典YOLOv8模型,性能显著提升。
结果表明,SEAttention机制显著增强了YOLOv8模型的特征学习和处理能力,提供了进一步优化模型的有效途径,并为后续研究和应用提供了有力支持。
4.3 系统测试
4.3.1 功能测试
(1)用户界面测试
多模型选择界面测试:确保用户能够在界面中选择不同的YOLO模型,且每个模型有明确的描述与选择按钮。测试模型选择按钮是否响应、选择后的界面展示是否正确。
文件上传功能测试:测试用户能够成功上传图片和视频文件,并确保上传过程中的界面反馈清晰(如加载状态)。检查上传后的文件能否正确传递给检测系统进行分析。
实时摄像头接入功能测试:测试系统是否能够成功调用本地摄像头,并进行实时视频流的捕捉。检查视频流是否稳定,帧率是否符合规定。
检测结果展示测试:确保检测结果(包括类别、置信度、坐标、系统时间)能够实时显示在界面上,且与实际检测结果一致。
语音提醒功能测试:测试系统能否在检测到危险驾驶行为时触发语音提醒。确保语音提醒的音量控制和语音开关选项正常工作。
(2)检测功能测试
图片检测测试:测试系统能否正确处理用户上传的图片,识别并标注出驾驶员的行为,给出准确的类别、置信度、坐标及时间信息。
视频检测测试:测试系统能否处理视频文件,对每一帧进行分析,正确识别和标注驾驶员行为,并且输出完整的视频结果。
实时视频流检测测试:确保系统能够处理来自摄像头的实时视频流,并实时识别驾驶员行为,且结果能在界面上实时显示。
多类别检测测试:测试系统能否识别多种驾驶员行为(例如打哈欠、饮水、危险驾驶等),并且对于每种行为能正确分类和反馈。
置信度评估测试:验证系统为每次检测提供的置信度评分的准确性,确保评分反映检测结果的可靠性。
4.3.2. 非功能性测试
(1)数据导出功能测试
CSV导出测试:测试上传数据类型(如视频、实时检测)是否可以选择是否导出检测结果,并且导出的CSV文件内容正确(包括检测时间、最大置信度类别、置信度和框坐标)。
历史信息学习与预测测试:测试系统是否能够通过历史检测结果学习驾驶员行为习惯,并在一定程度上弥补预测危险行为的不足。
(2)PyQt5框架兼容性测试
跨平台兼容性测试:测试系统在Windows、macOS和Linux等主流操作系统上的兼容性,确保所有功能在不同操作系统上均能正常运行。
界面设计测试:检查系统界面的简洁性与直观性,确保用户能够轻松找到各项功能并顺利操作。
多线程支持测试:测试系统在进行检测和语音提醒时,界面是否流畅,检测过程是否能并行执行且不影响其他操作。
4.3.3 性能测试
(1) 响应时间测试
测试系统在处理图片、视频及实时视频流时的响应时间,确保用户操作后能够在合理的时间内获得检测结果(图片检测响应时间 ≤ 3秒,视频检测每帧响应时间 ≤ 100ms)。
(2) 系统稳定性测试
测试系统在长时间运行(24小时连续检测)的稳定性,系统不会因为资源限制或长时间运行而崩溃或卡顿。
4.3.4 兼容性测试
(1) 操作系统兼容性测试
测试系统在不同版本的Windows(Windows 10、Windows 11)、macOS(macOS Ventura)和Linux(Ubuntu 22.04)上的运行情况,确保无系统崩溃或无法启动的情况。
4.2 硬件兼容性测试
测试系统在不同硬件配置的计算机上运行的情况,包括的CPU、GPU和内存配置。确保系统能够在低配置计算机上正常运行。
系统运行界面如下图
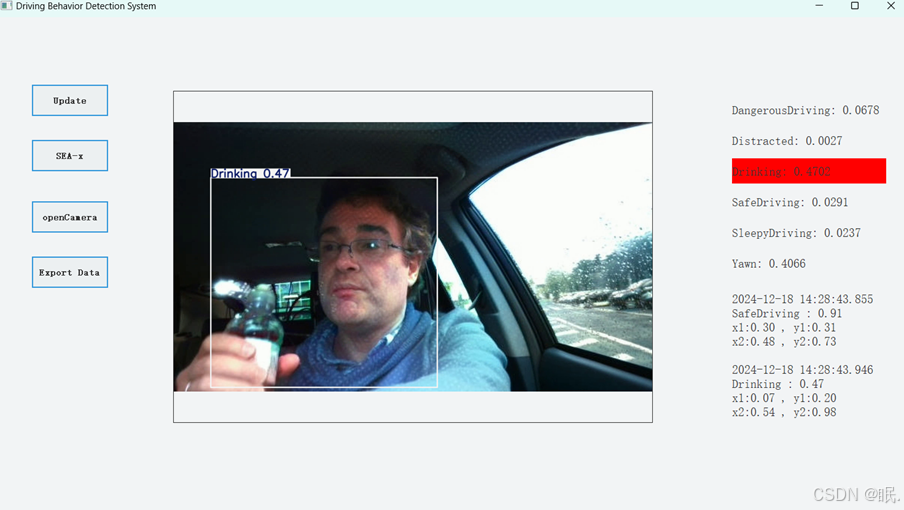
图4-3 系统效果展示
4.4 本章小结
本章详细介绍了系统的功能需求和模块设计以及系统测试内容。首先,系统的主要目标是通过检测驾驶员的危险行为并进行实时语音提醒,以提高驾驶安全性。系统具备了图像、视频上传以及实时摄像头接入功能,可以有效处理不同类型的检测数据,并实时显示检测结果。同时,系统支持多种YOLO模型选择,提供了对驾驶员行为的多类别检测,并在危险行为发生时触发语音提醒。
在功能需求和系统设计方面,系统提供了用户界面的设计需求,如多模型选择、文件上传和实时视频流检测等功能,同时确保检测结果能够实时展示,且具有语音提醒功能,增强了用户的互动体验。数据导出功能也被纳入非功能性需求中,通过CSV格式保存检测结果,以便进行历史分析和行为预测。此外,PyQt5框架被选用来实现跨平台支持、界面设计、以及多线程支持,确保系统在不同操作系统和硬件环境下能够稳定运行。
在数据需求方面,系统通过上传图片、视频或实时视频流进行检测,并结合深度学习模型实时进行目标识别和结果展示。系统还对实时视频数据进行了优化,以确保采集和处理的稳定性。所有检测结果都能及时以图像或语音的方式反馈给用户,提升交互体验。
系统测试部分涵盖了功能测试、非功能性测试、性能测试和兼容性测试,确保系统在不同条件下的表现稳定。测试内容包括界面、文件上传、实时检测、语音提醒、检测精度、响应时间等方面,确保系统能够高效、准确地运行。
总的来说,本章为系统的设计和实现提供了全面的功能需求与技术细节,同时通过详细的测试方案确保了系统的稳定性与可靠性。


















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









