







“ 乱花渐欲迷人眼,学会从根本上认识问题 ”
现在市面上大模型如百花齐放,对很多人来说一堆大模型带来的不是简单方便,而是乱七八糟以及迷茫。
因为不知道不同的大模型之间有什么区别,也不知道自己需要什么样的大模型;就拿huggingface来说,上面的模型有几十万,有几个人能弄明白它们都是干什么的?
因此,我们首先需要学会的就是大模型的分类,对大模型分门别类之后就知道哪些大模型是做什么的,自己需要的是什么了。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
01
—
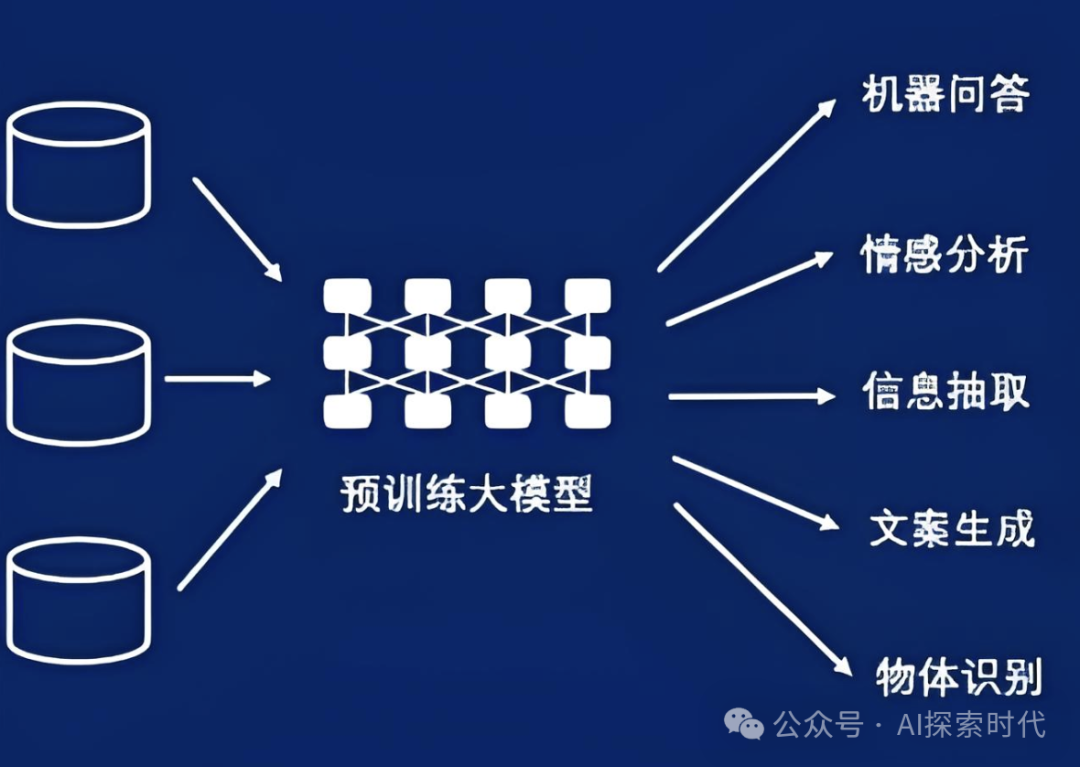
大模型的分类
事实上直接说大模型并不是特别准确,大模型指的是具有庞大参数的机器学习或者深度学习模型。
根据模型的参数量可以分为大/中/小三种类型,不同的模型对资源要求不同,应用的场景也不同;比如一些小模型可能会安装到移动设备之上。
按任务类型分类
根据任务类型,大模型可以分为生成式模型,判别式模型和混合模型。
生成式模型:这种模型主要用于生成内容,包括文本,图像,音视频等;典型的比如GPT模型。
判别式模型:判别式模型主要应用于分类,预测等任务;如图像分类,文本分类等;比如Bert模型。
混合模型:混合模型结合生成式和判别式模型的能力,能够在生成内容的同时进行分类或判别任务。
当然,这个按任务分类只是进行简单的分类,如果再细化还有更多的分类方式,比如情感分析等。
按数据模态分类
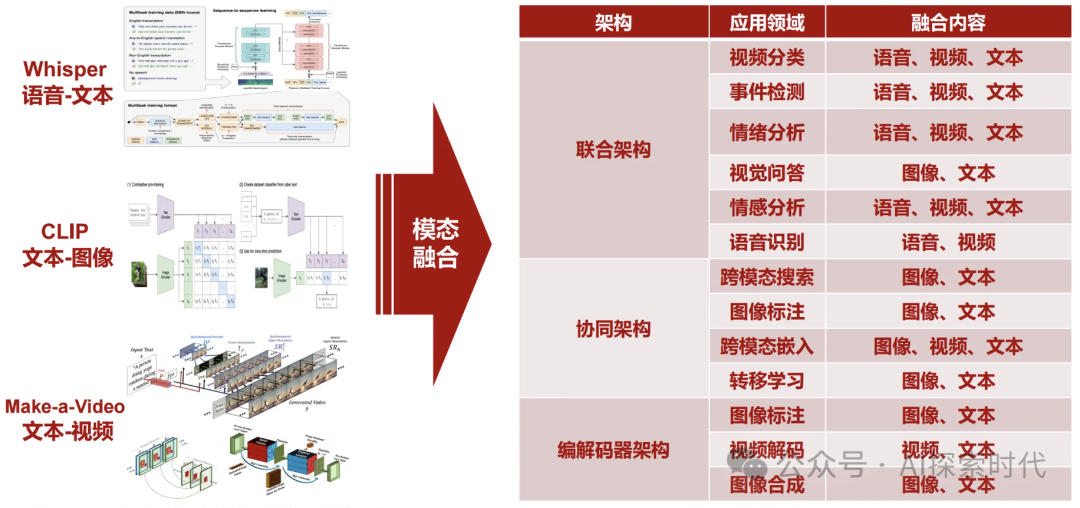
根据数据模态,大模型主要分为两类,一类是单模态模型,一类是多模态模型。
单模态模型:单模态就是仅支持一种模态数据的模型,比如支持文本或者图片等类型的模型;如ResNet处理图像,BERT模型处理文本。
多模态模型:能够同时处理多种类型的数据,如文本,图像,音视频等;如CLIP模型结合了文本和图像处理的功能。
_按训练方法分类_
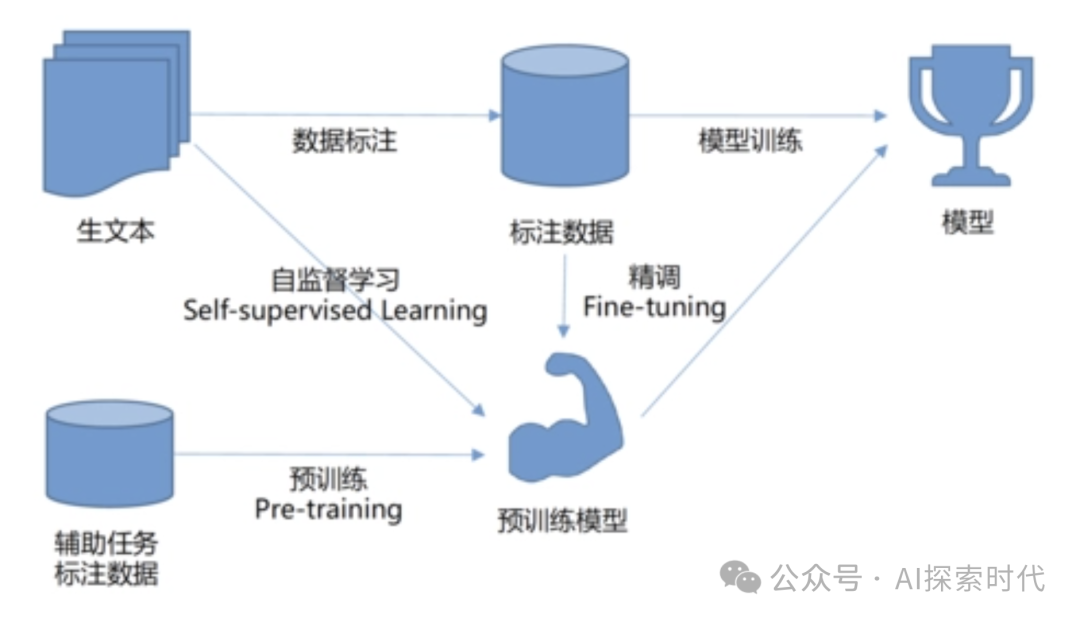
按训练方法进行分类,主要有预训练模型,从零训练模型和迁移学习模型。
预训练模型:通常在大规模数据集上进行预训练,然后通过微调适应特定任务,如GPT,BERT等。
从零训练模型:从头开始训练的模型,通常在特定任务上训练,数据集要求较高。
迁移学习模型:迁移学习通常是指在一个任务中学习的知识迁移到另一个相关任务中;能够减少训练时间并提升性能。
按应用领域分类
按照应用领域分类,主要分为自然语言处理,计算机视觉模型,以及语音处理模型等。
自然语言处理模型:专门用于处理和理解人类的语言,如文本生成,翻译,情感分析等任务。
计算机视觉模型:用于处理和理解图像或视频数据,如图像分类,目标检测,图像生成等任务。
语音处理模型:用于处理语音信号,包括语音识别,合成,情感分析等任务。
基于自然语言处理的人工智能机器人:
_按模型架构分类_
按模型架构分类,主要分为transformer架构,卷积神经网络和循环神经网络以及长短期记忆网络。
transformer架构:transformer架构应该就不用多说了,大名鼎鼎的GPT就是基于Transformer架构,广泛应用于自然语言处理和多模态任务中。
卷积神经网络:主要应用于计算机视觉任务中。
循环神经网络和长短期记忆网络:传统上用于处理时间序列数据或语音处理任务。
当然,大模型的分类还有多种不同的形式,以上分类方式是目前比较主流的方式而已。比如说有应用于代码开发的代码生成模型,用于数据处理的数据分析模型等。
弄清楚模型的分类,有助于加深对模型的理解;比如说有人提到GPT,你就能知道它是一个基于Transformer架构的,能够进行自然语言处理与生成的预训练模型。
CSDN独家福利
最后,感谢每一个认真阅读我文章的人,礼尚往来总是要有的,下面资料虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:


















 3093
3093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









