






整体模型架构
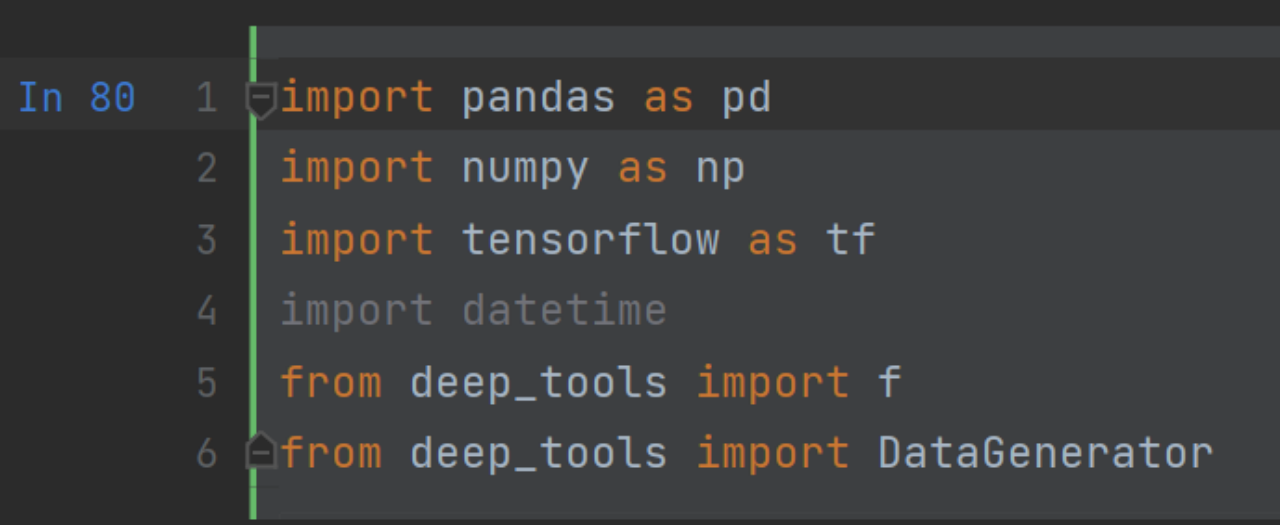
import pandas as pd 导入pandas模块,并简写为pd
pandas : py数据分析模块(库名),用于数据分析和数据处理
pd : 缩写后的库名
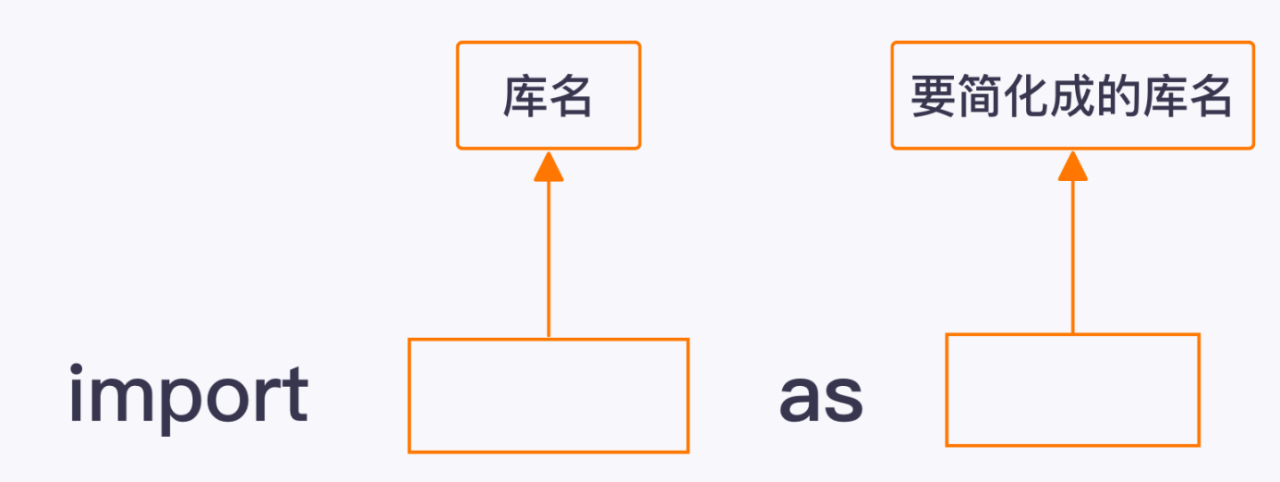
from deep_tools import f 从deep_tools模块中导入f
from...import...从...(模块名)导入...(工具名)
文件夹
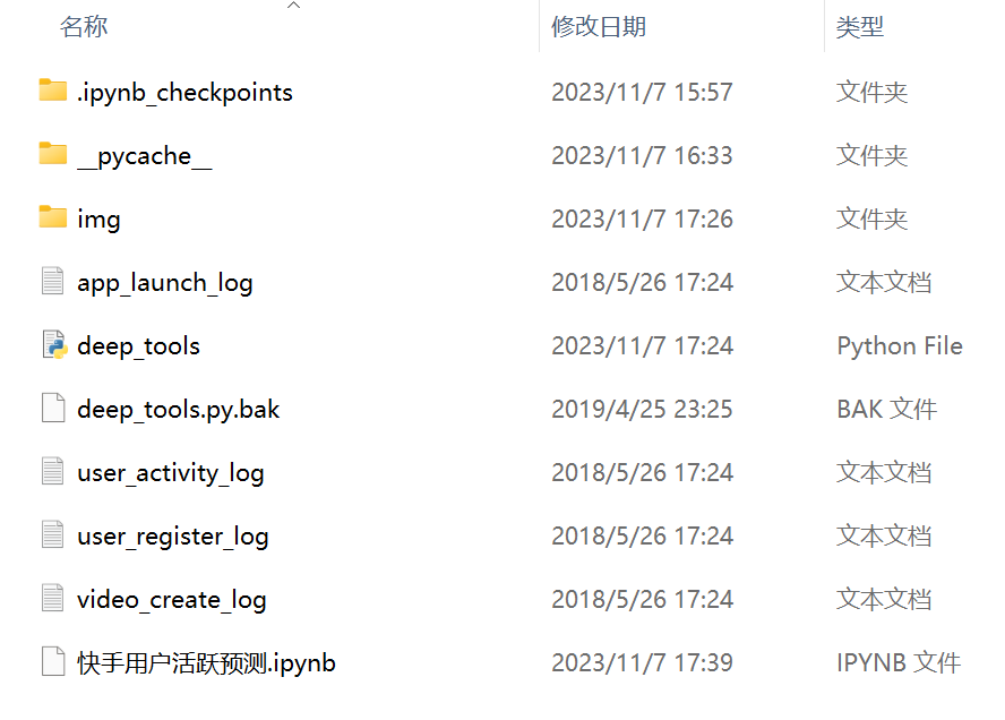
app_launch_log:用户登陆数据集
user_register_log:用户注册数据集
user_create_log:用户视频创建数据集
user_activity_log:用户行为数据集(点赞、转发...)
读取4份文件:

read_csv()函数:不仅可以读取csv文件,还可以直接读入txt文件(默认逗号间隔内容的txt文件)
上述图片中sep=’\t’表明规定用换行符分隔
p.s.拿到的数据最大序列长度是30天(用户注册日期不同)
目标预测未来一个周期,(e.g.根据第1-7天的行为预测第14天)
构建用户特征序列
以表格形式输出注册日志:
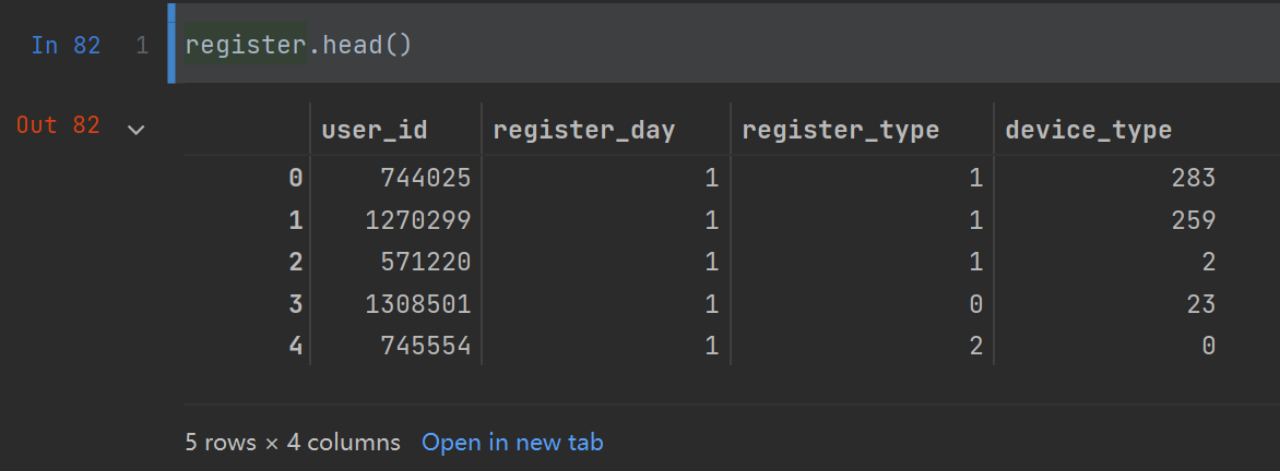
head()函数:
e.g.register.head()中:register是文件名,()中没有内容,默认输出5行
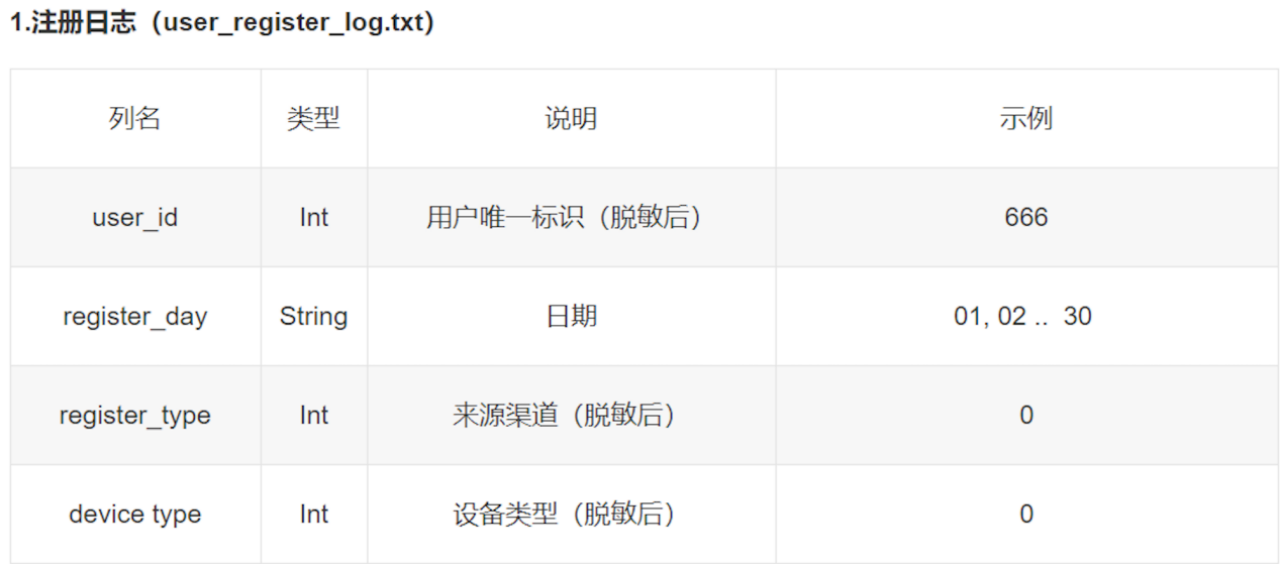
输出启动日志:
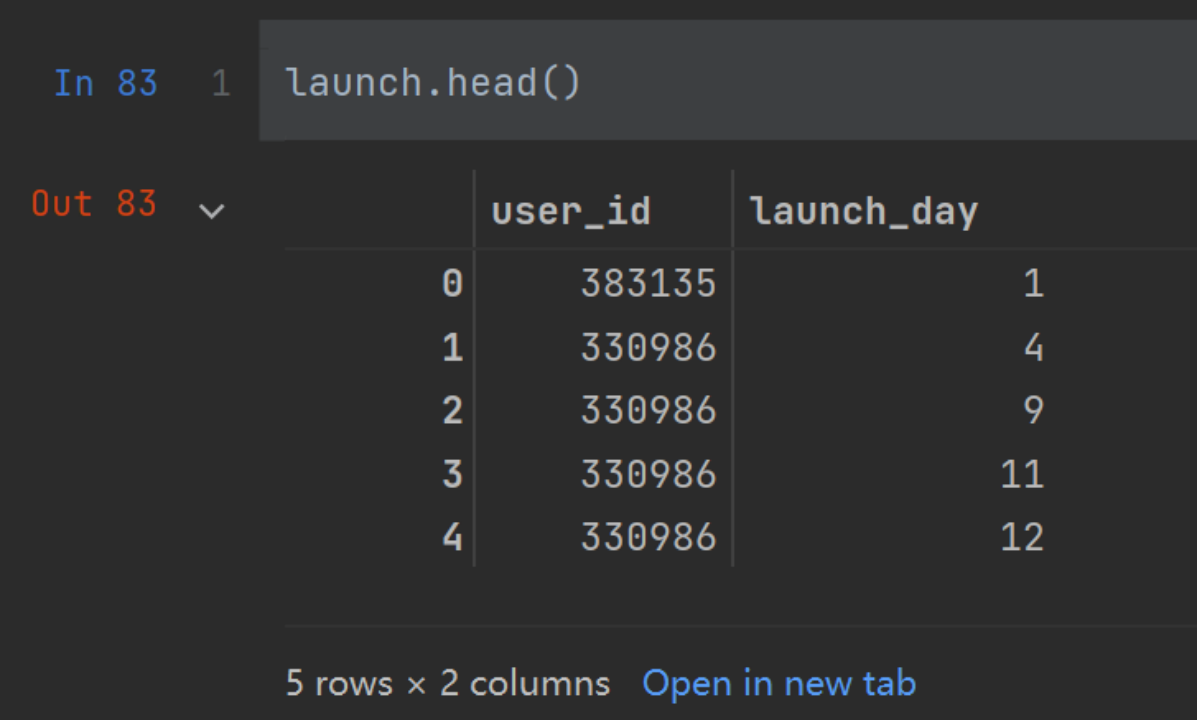
e.g.上图中id为330986的用户在4,9,11,12天都启动了该APP
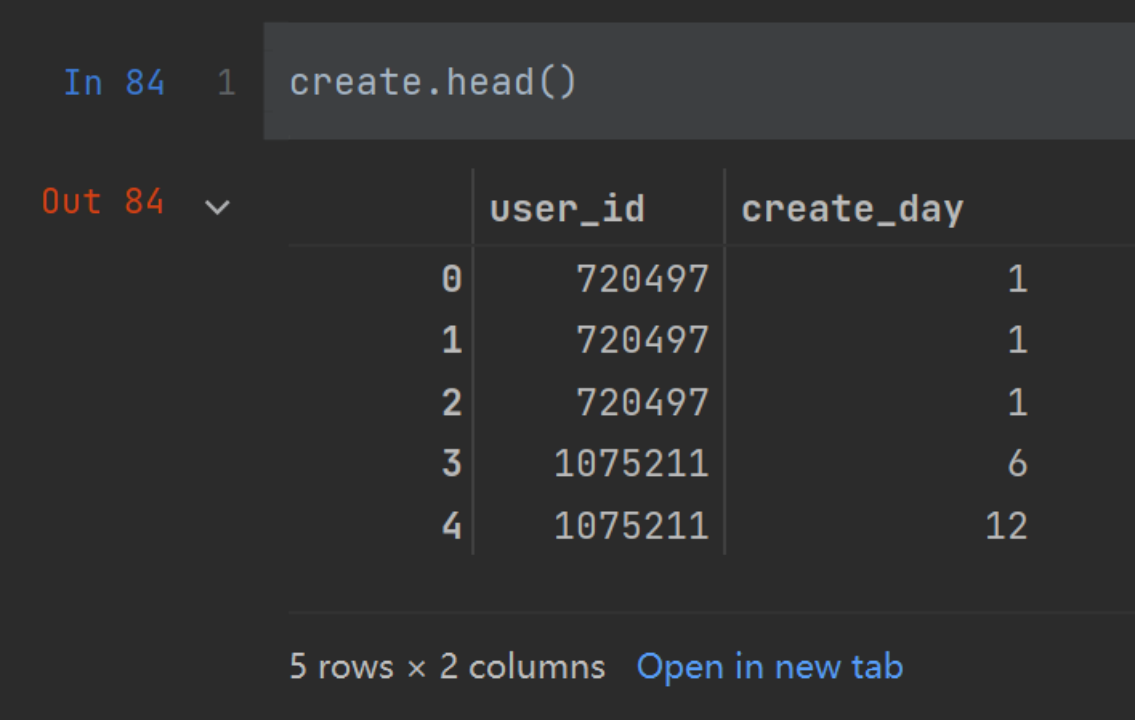
输出创建日志:
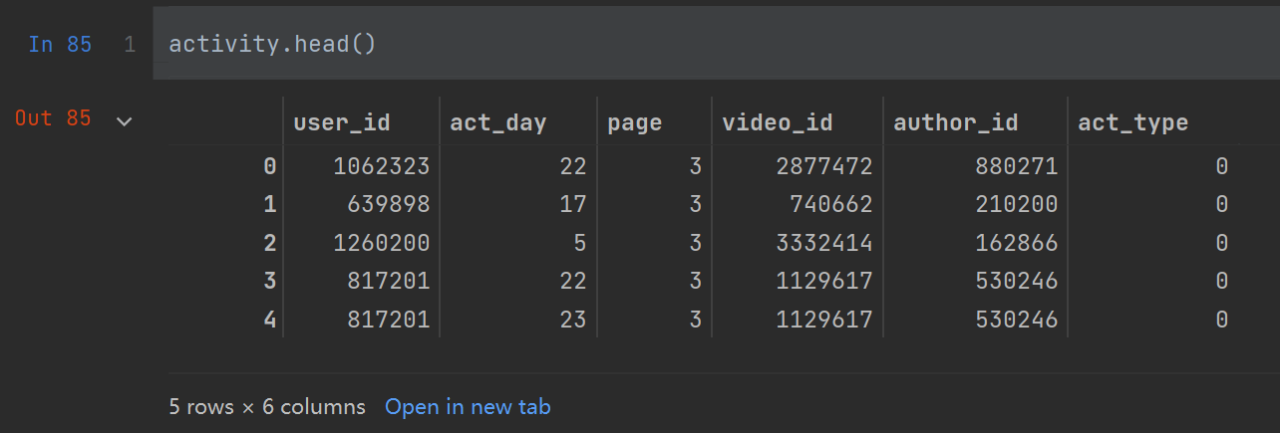
输出行为日志:
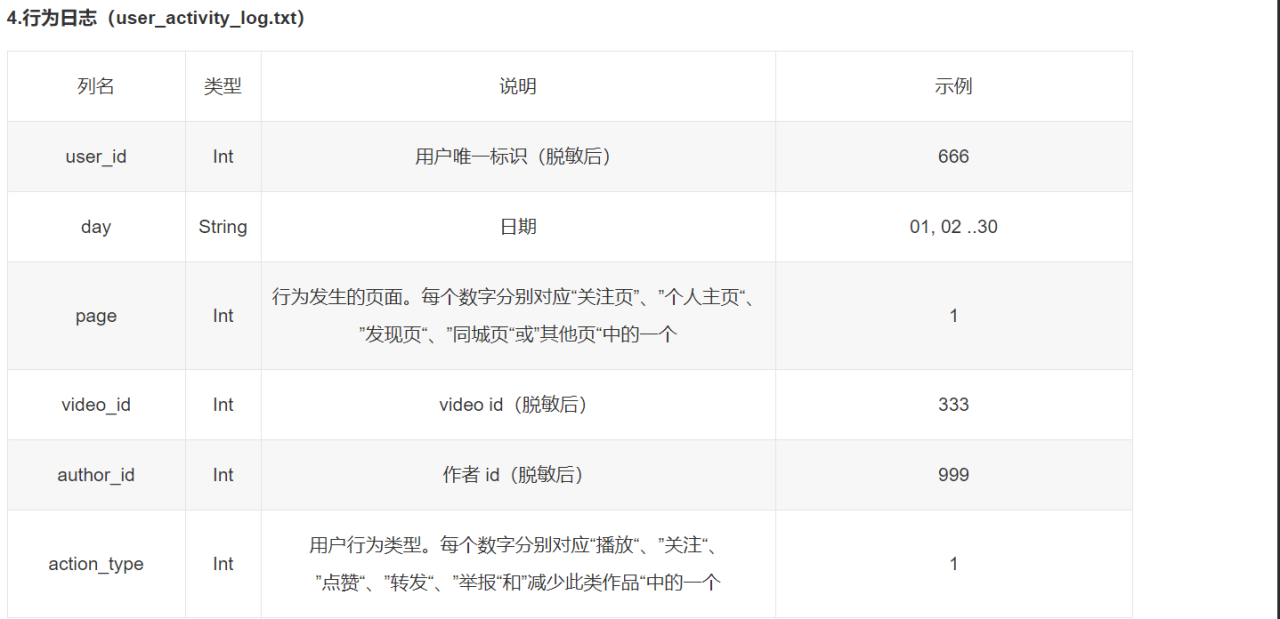
用户特征序列提取方法
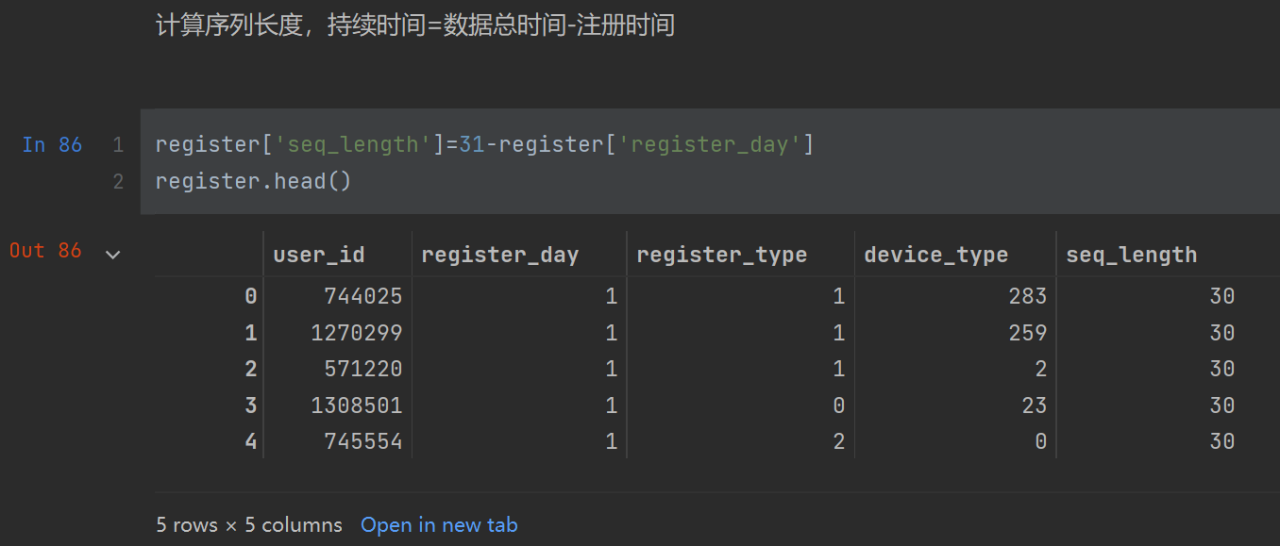
31-register_day:31是一个月,register_day是注册的日期,所以seq_length代表用户从注册到一个月的天数。
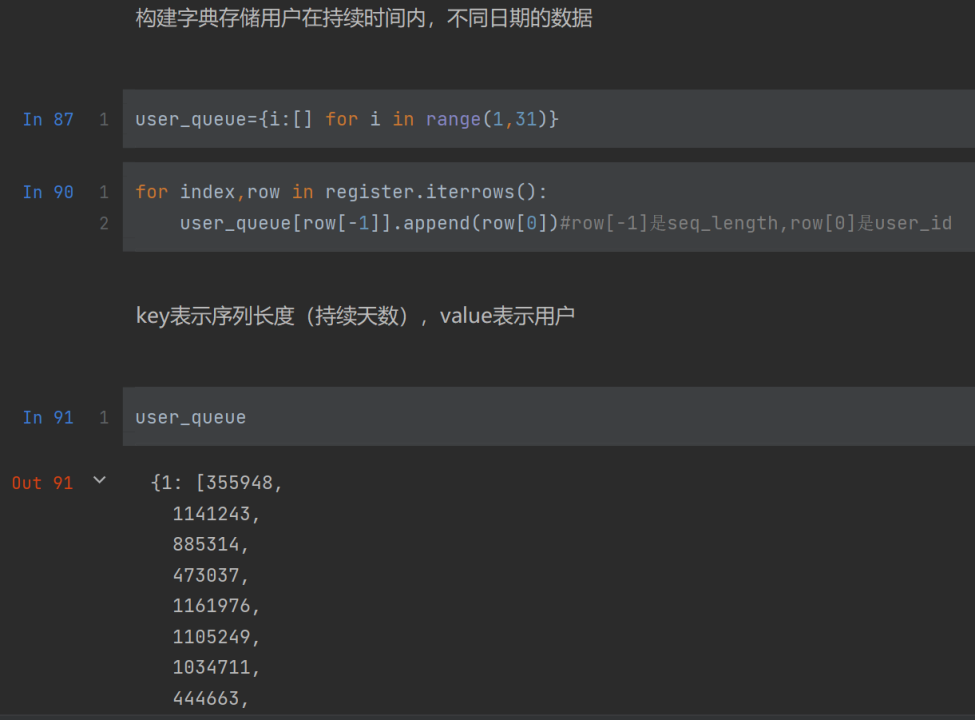 queue:队列
queue:队列
建立30个队列,把对应持续时间的用户放到一个序列里
用for遍历register数据
row[-1]代表最后一列,也就是seq_length。row[0]是第一列,也就是user_id
.append()函数:向列表末尾添加一个元素,这个语句的意思也就是把相应的user_id添加到user_queue中。
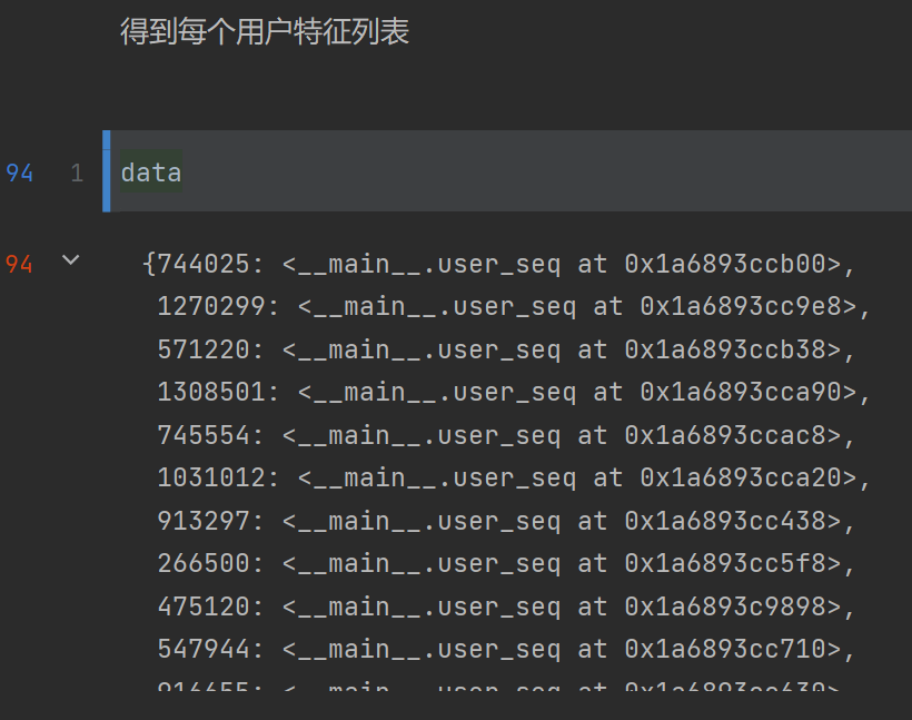
生成特征序列汇总表
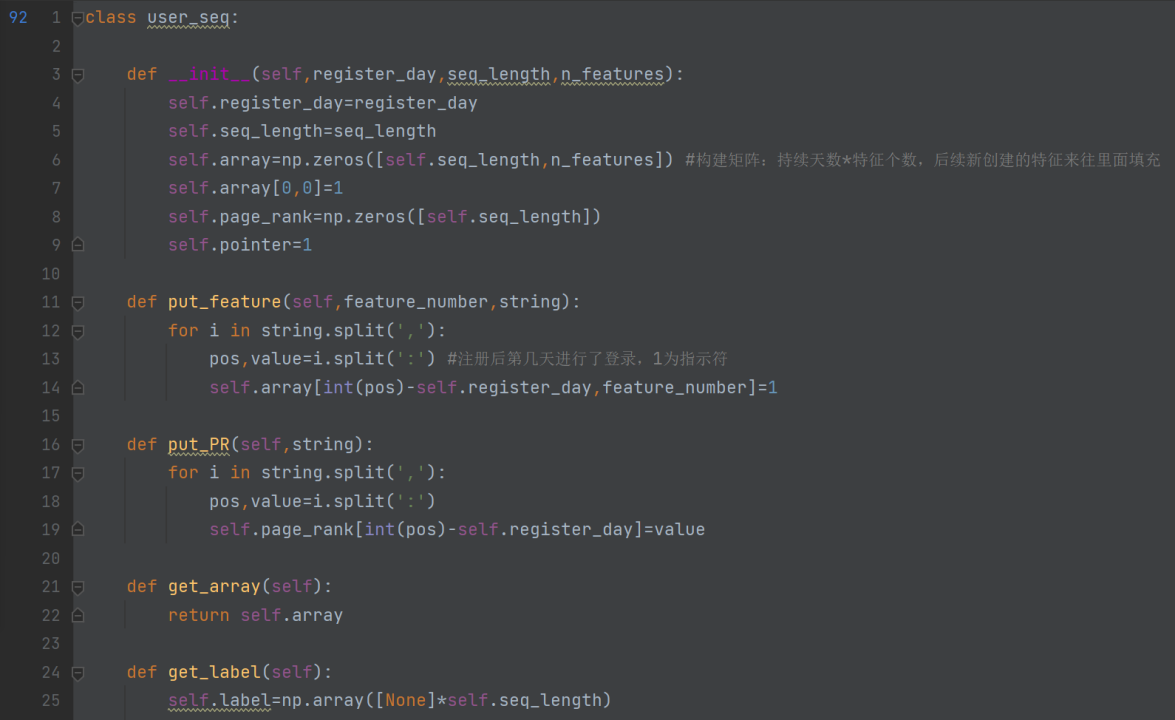
get_array()函数:返回array的结果。
第8行self.seq_length,n_features:下附numpy.zero()函数用法
第13行pos(position)位置,即第几天进行注册的,下一行int(pos)-register_day是持续时间。创建第一个特征,把它传到对应特征的位置
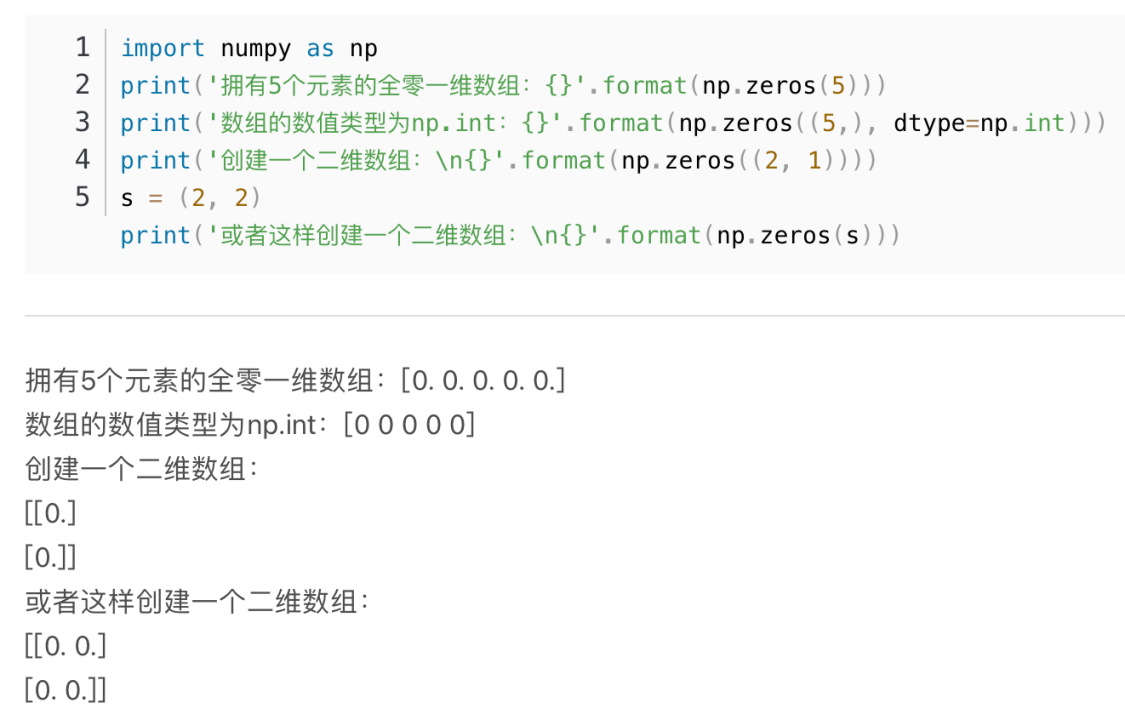
所以这行代码的意思是把用户持续时间内的每一天都列为一行,特征数为列(用0填充)
也就是对每个用户都构建一个特征矩阵。

get_label()函数:先构建有(持续时间)个长度的label序列,都赋值成None,
for循环遍历最近7天,如果1-8特征内有‘1’(即用户有行为产生),就把对应天数的标签值置为1,判定该用户为活跃用户。
n_features=12表明每个用户每天都要统计这12项特征
for index,row in register.iterrows():iterrows()是pandas中的一种遍历方法
用for循环遍历register的行列,index是每一行数据的索引,row是一个Series对象,表示该行数据
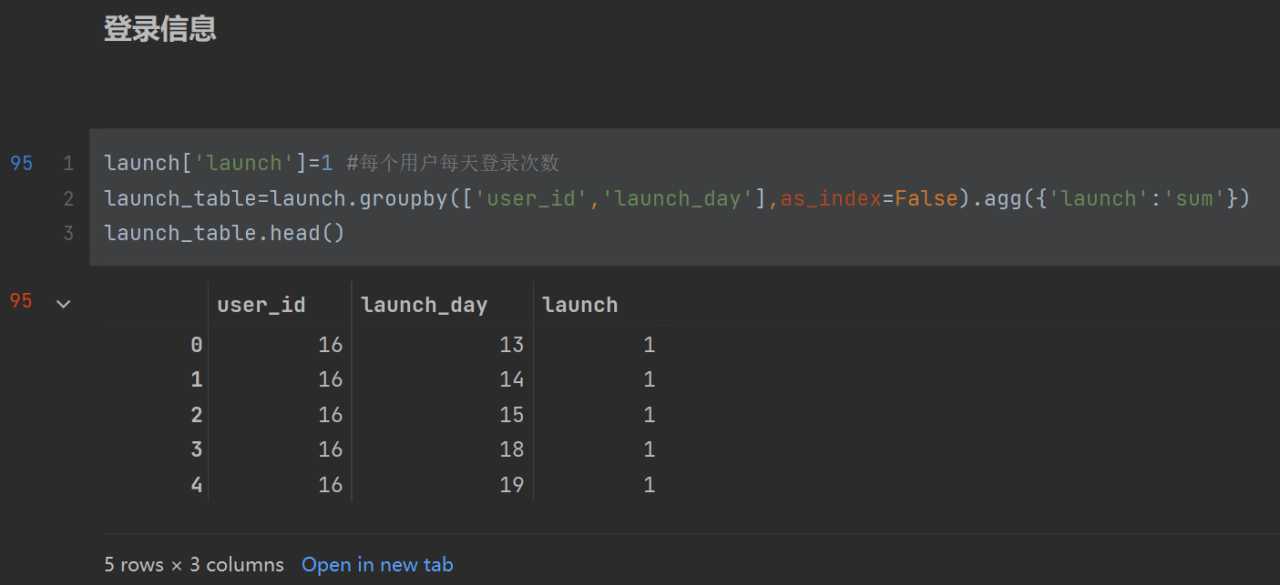
第1行表示把launch设成1
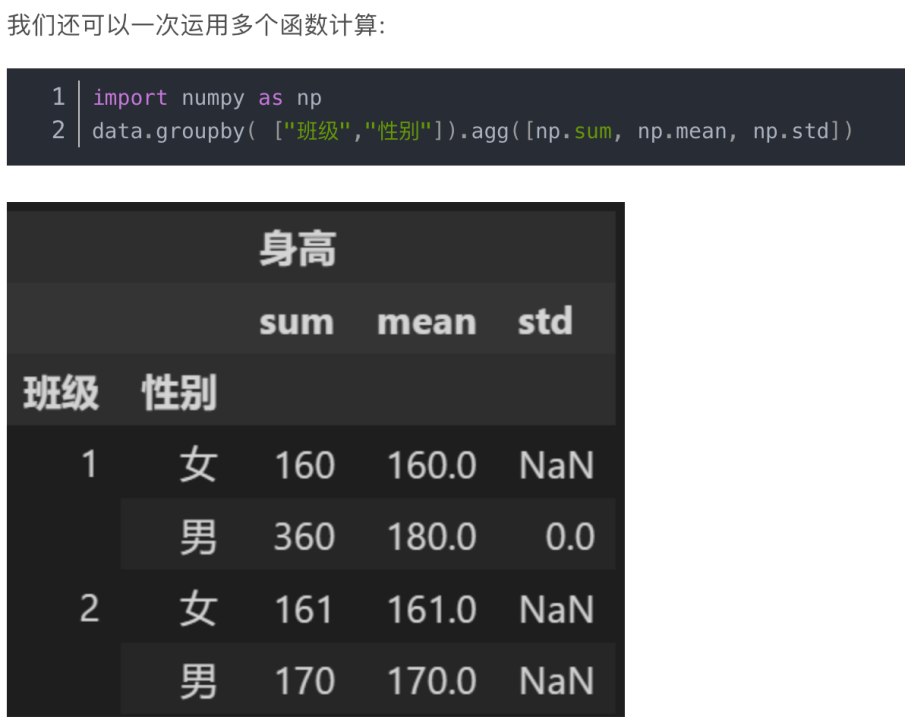
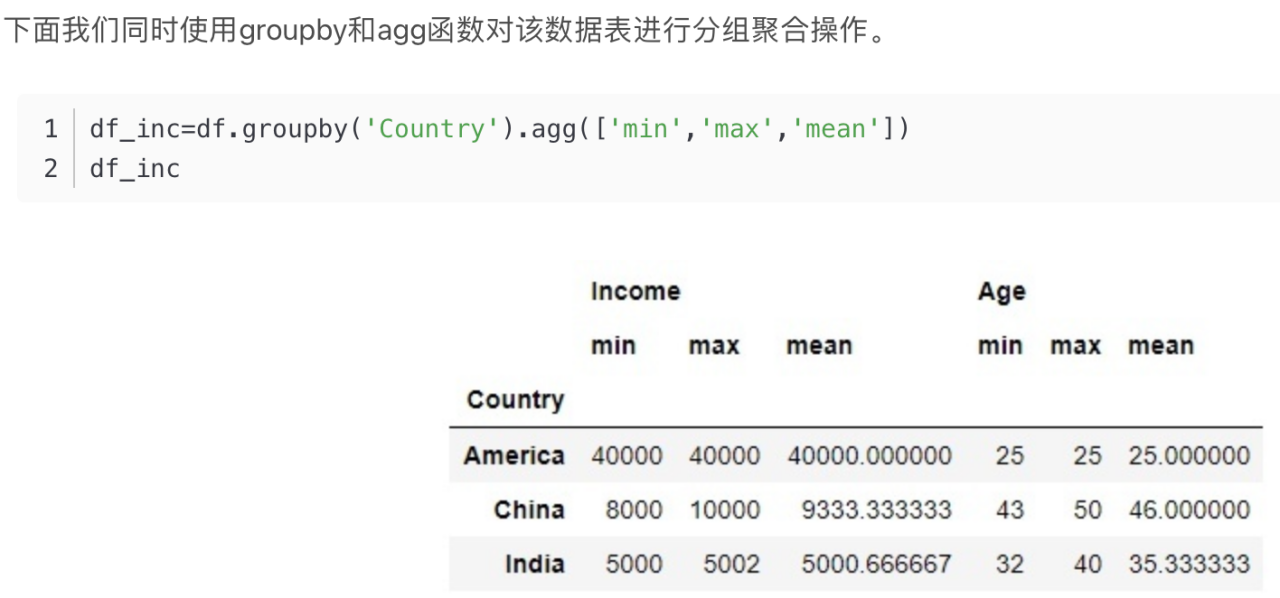
.agg():聚合操作
groupby()函数用法如下:
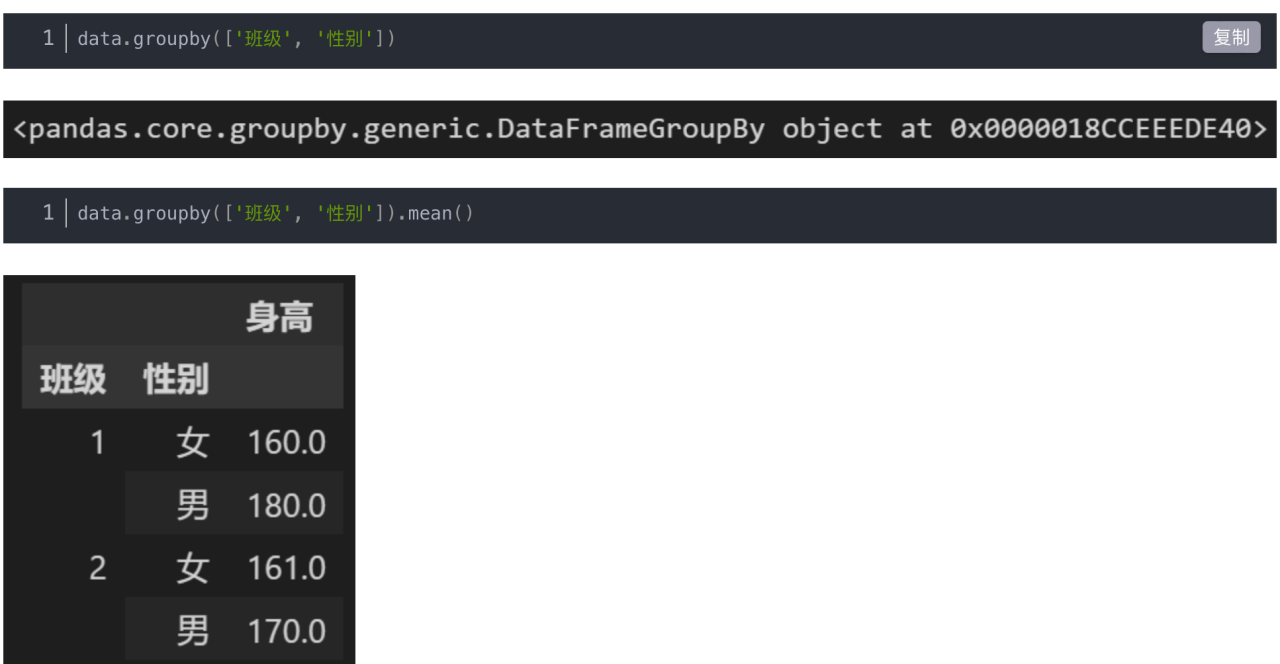
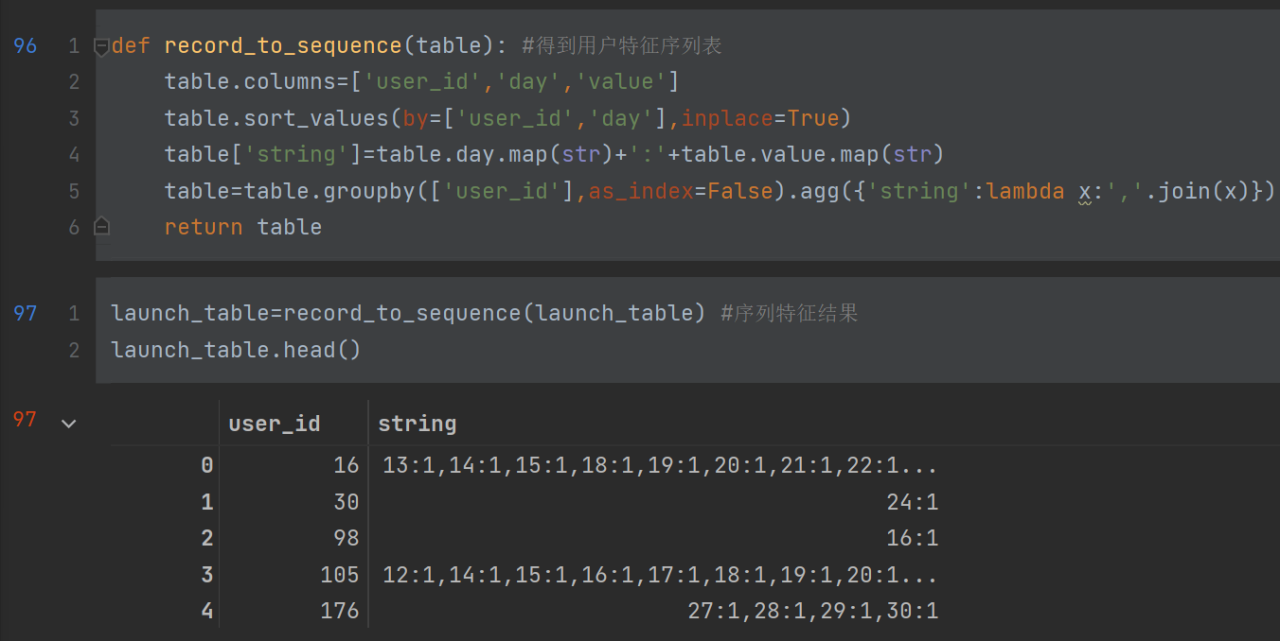
2,3行重新指定了列名,
table中的day转换成str形式,后面加上:来分隔,后面再加上value(值)
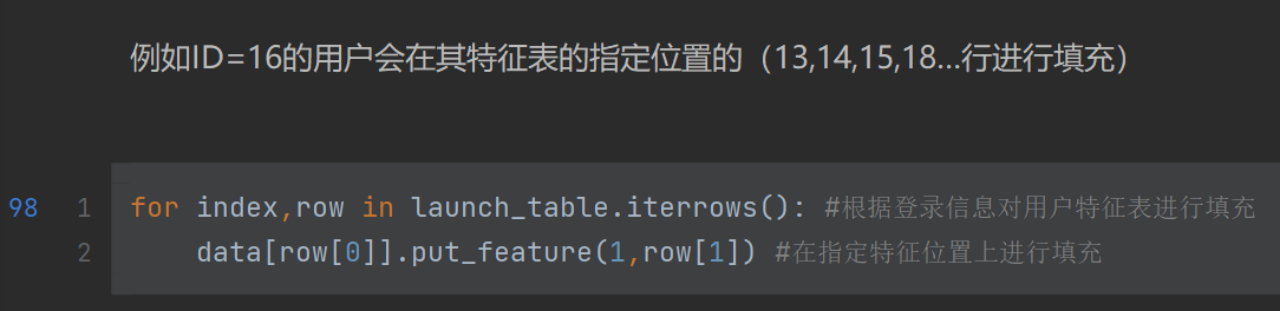
row[0]是user_id,put_feature()函数在上面有定义,()中1代表第一个特征,row[1]为填充进去的内容(string)。没有填充的地方不变,还是0。
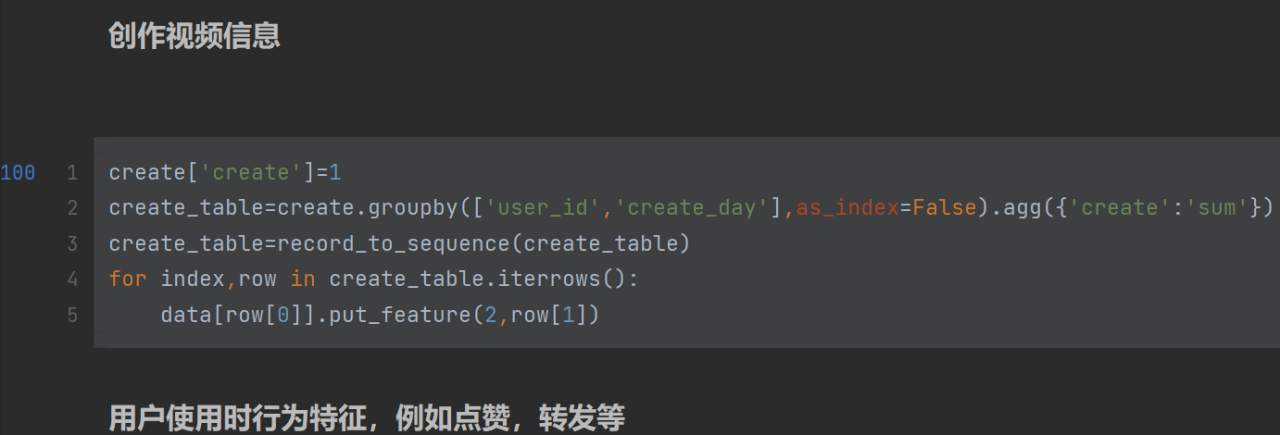
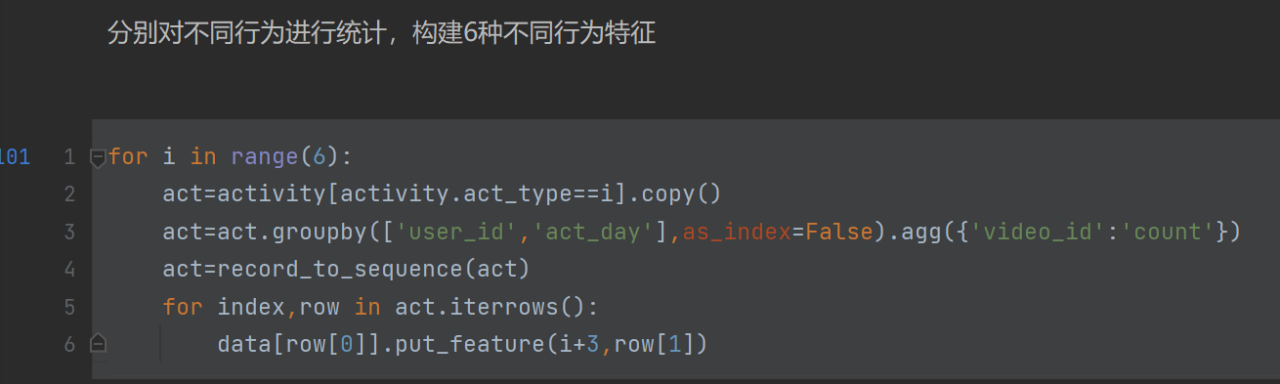
for循环构建6种不同特征(e.g.点赞,转发,拉黑...)
第4行act=record_to_sequence(act)是将act转换成序列
row[0]是user_id
i起始位置是0,i+3是3
groupby()函数用法如下:
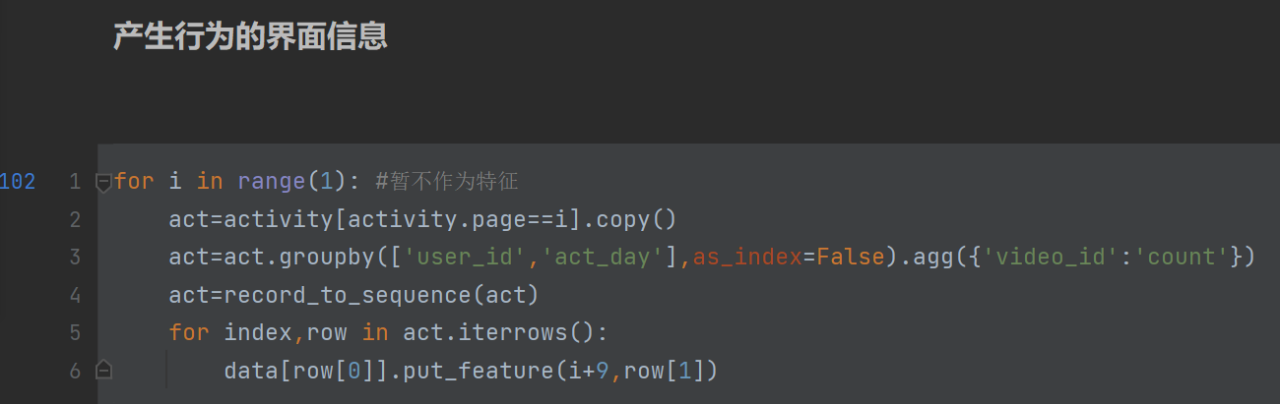
只列举了一个行为特征,(要想知道一共有几个特征,直接value_count,)
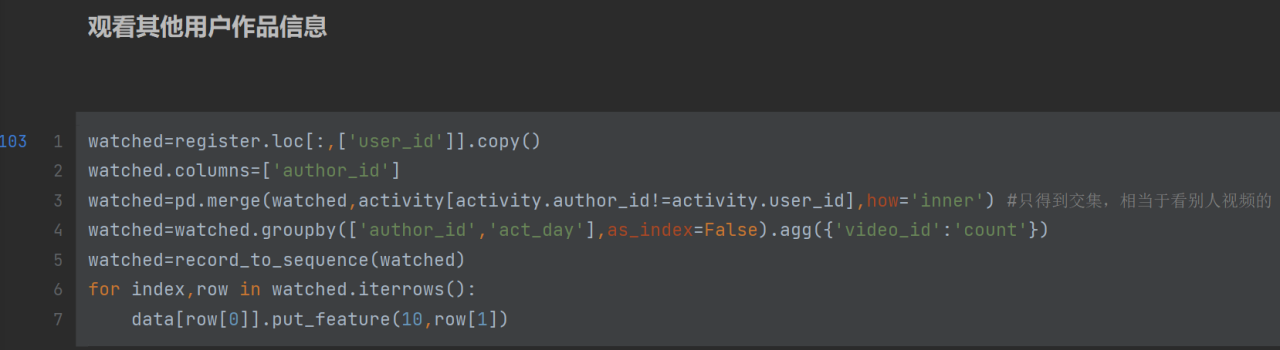
第3行activity数据集里author_id(作者id)!=user_id(用户id)意思是观看别人作品,
进行merge操作取得交集(watched(观看)和 观看别人作品 的交集),运行完watched就是观看别人作品的信息
存到10这个位置
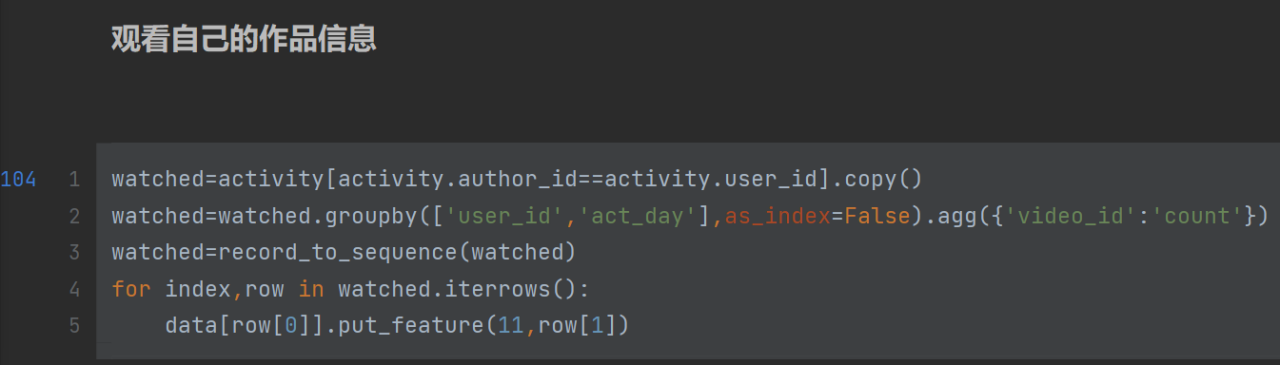
到此,12个特征就全部构建完成,这个矩阵是为了RUN网络进行服务的。
制作数据标签
活跃用户定义为7天内使用过APP(在上述任一类型日志中出现过)
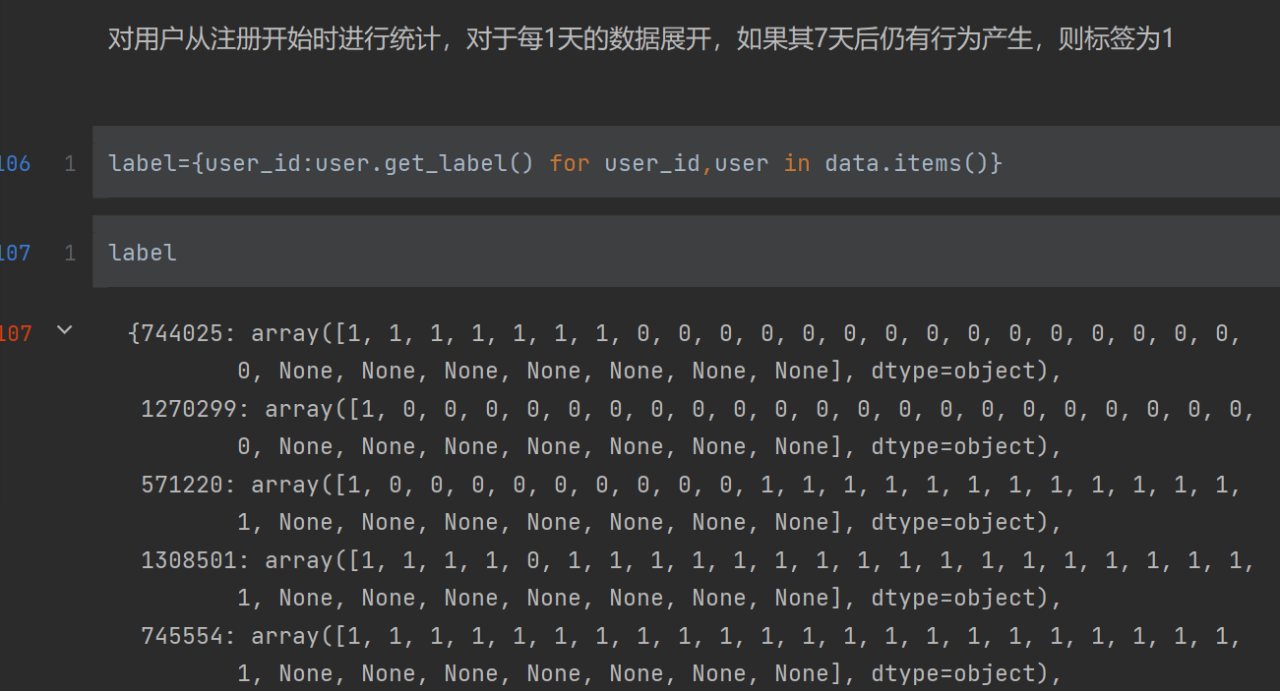
label函数在上文提到过(label是一个序列),array[ ]内是按天数排序(第1天,第2天)并将每天的特征展开,1是有行为,0是无行为。
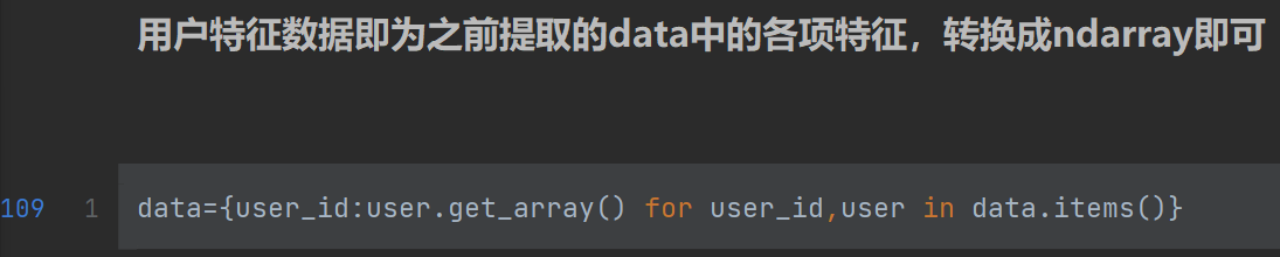
get_array()函数:上文中提到过,即输出array。
网络训练模块

在deep_tools文件里都已经封装好以上模块
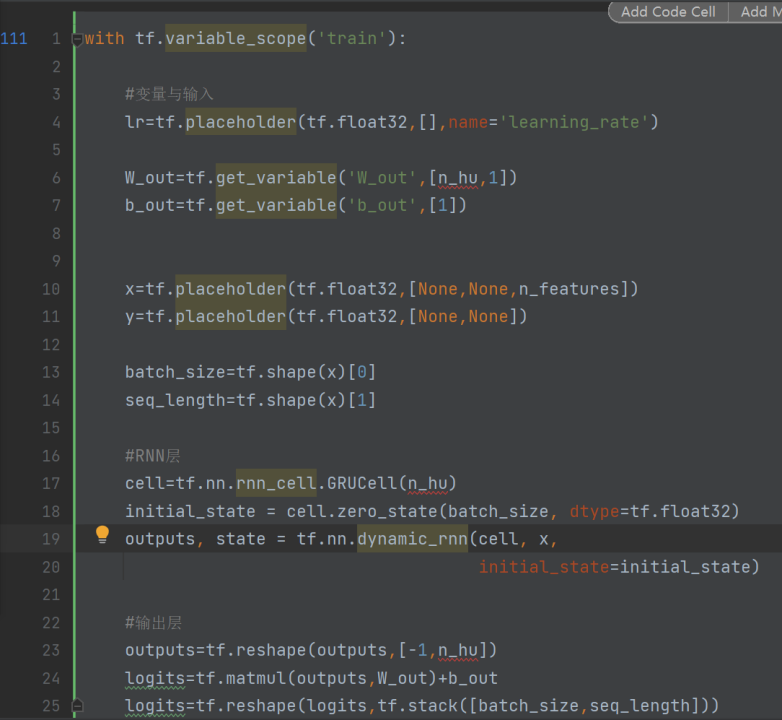
构建RNN网络模型

















 2167
2167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









