







在Pandas中,了解数据的意义是为了能够有效地分析、处理和理解数据。Pandas是Python中一个强大的数据分析库,它提供了数据结构和函数,可以使数据的处理更加简单和高效。通过了解数据,我们可以了解数据的结构和特性,并利用数据来进行分析最后做出决策。总的来说,了解数据意味着能够更好地利用数据来解决问题、做出决策,并从中获得价值。Pandas提供了丰富的工具和功能。下面就将简单介绍一下pandas中了解数据的一系列方法。
首先读取一个名为test的csv文件。
pd.read_csv('路径+test.csv',encoding='utf-8')在jupyter notebook中下面这种情况就是读取成功
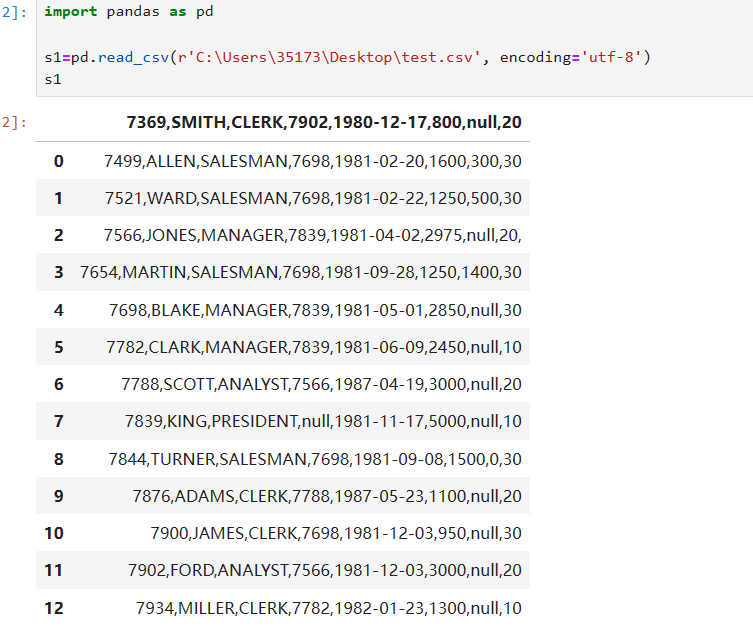
ok我们现在已经有了s1这个数据下面介绍几个查看数据的函数
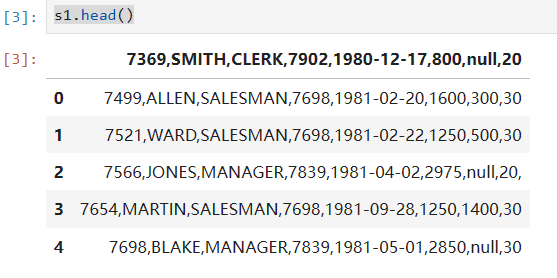
s1.head()这个表示查看s1这个数据的前多少行,如果没有参数传递就默认看前5行,如果有默认参数就可以限制看的行数,如下图所示
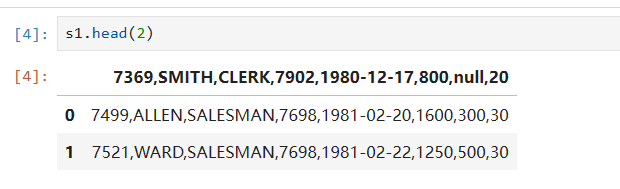
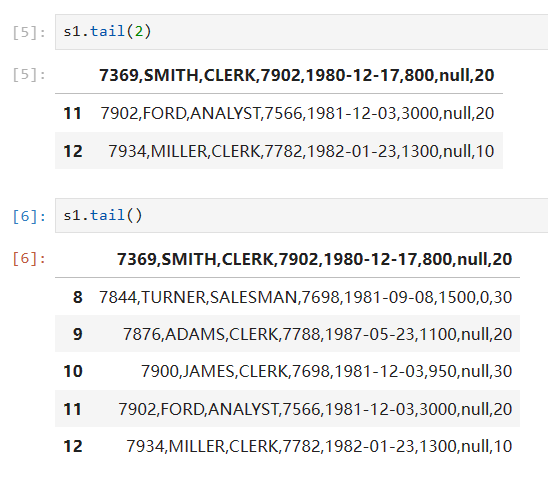
s1.tail(2)这个是表示从数据尾部查看数据的行数默认是查看后面5行,结果如下图所示:
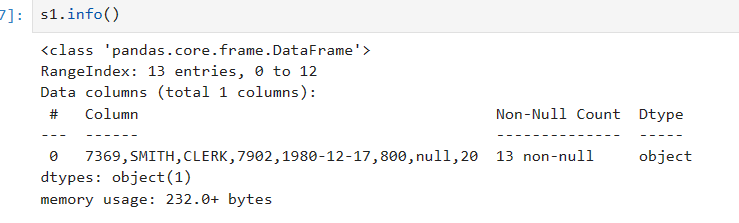
s1,info() info()函数提供了有关DataFrame的一些关键信息,包括:
-
索引信息:显示DataFrame的索引信息,包括索引的数据类型和长度。
-
列信息:显示DataFrame的每一列的名称、非空值数量以及每列数据类型。
-
内存使用情况:显示DataFrame对象所占用的内存空间。
通过调用info()函数,你可以快速了解DataFrame的基本结构和内容,以及内存使用情况。具体情况如下图所示
s1.shapeshape函数就是看下数据表的大小,即数据表有多少行,多少列 。结果如下图所示,s1是一个13行1列的数据。

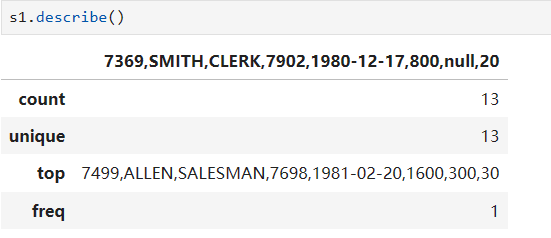
s1.describe()describe()函数是Pandas中DataFrame和Series对象的一个方法,用于生成关于数据的描述性统计信息。它提供了数据的一些基本统计指标,包括:
- 计数(count):非缺失值的数量。
- 均值(mean):数据的平均值。
- 标准差(std):数据的标准差,衡量数据的离散程度。
- 最小值(min):数据的最小值。
- 25th、50th(中位数)、75th百分位数:数据的分位数,描述数据的分布情况。
- 最大值(max):数据的最大值。
对于非数值型数据,describe()函数会提供不同的统计信息,包括:
- 计数(count):非缺失值的数量。
- 唯一值(unique):数据中不同值的数量。
- 最频繁出现的值(top):数据中出现频率最高的值。
- 最频繁出现的值的频数(freq):数据中出现频率最高的值的出现次数。
结果如下图所示:















 1611
1611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









