






在机器学习的广阔领域中,决策树是一种强大而灵活的工具,用于从数据中提取模式并做出预测。回归树是决策树的一种形式,专门用于解决回归问题。它能够将输入数据划分为不同的区域,并为每个区域分配一个目标值的预测值。
一、数据准备
我们选择了一个包含电信客户流失数据的数据集,用以构建我们的预测模型。数据集中包括多个特征,如客户的账户信息、服务使用情况以及流失状态。
二、数据预处理
在建立回归树之前,我们首先需要对数据进行预处理。这包括处理缺失值、进行特征工程以及将数据划分为训练集和测试集。通过这些步骤,我们确保模型在训练和测试阶段都能得到准确的数据支持。
import pandas as pd
# 读取电信客户流失数据
datas = pd.read_excel("电信客户流失数据.xlsx")
# 将特征和目标变量分开
data = datas.iloc[:, :-1] # 特征
target = datas.iloc[:, -1] # 目标变量
# 划分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test = train_test_split(data, target, test_size=0.2, random_state=60)
三、构建回归树模型
我们使用Scikit-Learn库中的DecisionTreeClassifier来构建回归树模型。这里选择了基尼系数作为分裂标准,并限制树的最大深度为5,以控制模型的复杂度。
from sklearn import tree
# 初始化回归树分类器
dtr = tree.DecisionTreeClassifier(criterion='gini', max_depth=5, random_state=60)
# 在训练集上拟合模型
dtr.fit(data_train, target_train)
四、模型评估与优化
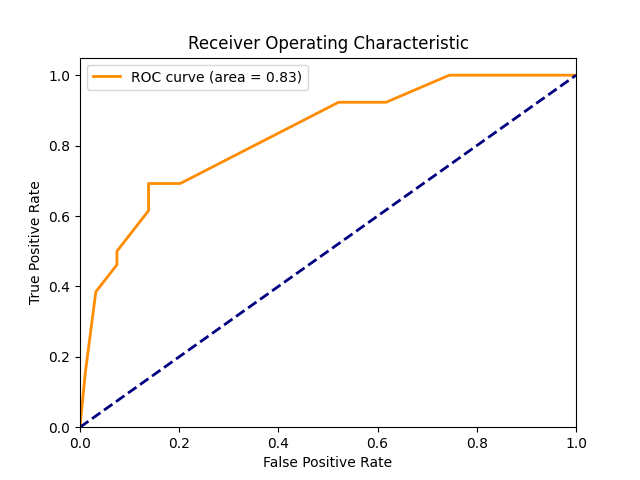
完成模型训练后,我们需要评估其在训练集和测试集上的性能。这里使用了分类报告来展示模型在不同类别上的精确率、召回率和F1分数,以及ROC曲线和AUC值来评估模型整体的预测能力。
from sklearn import metrics
# 在训练集上进行预测并输出分类报告
train_predicted = dtr.predict(data_train)
print("训练集上的分类报告:")
print(metrics.classification_report(target_train, train_predicted))
# 在测试集上进行预测并输出分类报告
test_predicted = dtr.predict(data_test)
print("测试集上的分类报告:")
print(metrics.classification_report(target_test, test_predicted))
# 计算模型在测试集上的准确率
accuracy = dtr.score(data_test, target_test)
print(f"模型在测试集上的准确率: {accuracy:.2f}")
# 计算预测概率并绘制ROC曲线
y_pred_proba = dtr.predict_proba(data_test)[:, 1]
auc_result = metrics.roc_auc_score(target_test, y_pred_proba)
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
# 绘制ROC曲线
fpr, tpr, thresholds = roc_curve(target_test, y_pred_proba)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {auc_result:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend()
plt.show()
五、结果解释与优化
-
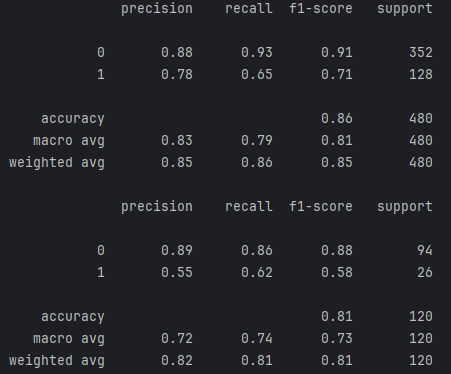
Precision(精确率):对于类别0(未流失客户),精确率为0.88,表示模型预测为未流失的客户中,有88%确实是未流失的。对于类别1(流失客户),精确率为0.78,表示模型预测为流失的客户中,有78%确实是流失的。
-
Recall(召回率):对于类别0,召回率为0.93,表示实际为未流失的客户中,有93%被模型正确预测为未流失。对于类别1,召回率为0.65,表示实际为流失的客户中,有65%被模型正确预测为流失。
-
F1-score:综合考虑精确率和召回率的调和平均值。类别0的F1-score为0.91,类别1的F1-score为0.71。
-
Accuracy(准确率):整体准确率为0.86,即模型在训练集上预测正确的比例。
1、测试集分类报告解释:
-
Precision:对于类别0,精确率为0.89;对于类别1,精确率为0.55。这表示在测试集上,模型对于预测未流失客户的精确度较高,但对于预测流失客户的精确度较低。
-
Recall:对于类别0,召回率为0.86;对于类别1,召回率为0.62。这表示在测试集上,模型能够较好地捕捉未流失客户,但对于流失客户的捕捉能力较弱。
-
F1-score:类别0的F1-score为0.88,类别1的F1-score为0.58。
-
Accuracy:整体准确率为0.81,即模型在测试集上的总体预测准确率。
2、结果优化建议:
不平衡类别处理:注意到流失客户(类别1)的精确率、召回率和F1-score较低,可以考虑使用类别平衡技术,如过采样(Oversampling)或欠采样(Undersampling),来改善模型对少数类别的预测能力。
模型调优:尝试调整决策树模型的超参数,如增加或减少最大深度、调整分裂标准等,以提高模型的整体性能。















 1378
1378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









