






摘要
GAN网络全称generative adversarial network,是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中两个模块,即生成模型和判别模型的互相博弈学习产生相当好的输出。
Abstract
The full name of GAN network is generative adversarial network, which is a deep learning model and one of the most promising methods of unsupervised learning in complex distribution in recent years. The model produces a good output through the mutual game learning of the two modules in the framework, which are the generation model and the discriminant model.
一、生成式对抗网络
1.GAN
我们将GAN分为三种形态(Typical GAN, Conditional GAN, Unsupervised Conditional GAN),第一种形态(Typical GAN)要做的事情是找到一个Generator,Generator就是一个function。这个function的输入是random vector,输出是我们要这个Generator生成的图片。
假设要机器做一个动画的Generator,那么就要收集很多动画人物的头像,然后将这些动画人物的头像输入至Generator。
最基本的GAN就是对Generator输入vector,输出就是我们要它生产的东西。我们以二次元人物为例,假设我们要机器画二次元人物,那么输出就是一张图片(高维度的向量)。Generator就像吃一个低维度的向量,然后输出一个高维度的向量。
GAN有趣的地方是:我们不只训练了Generator,同时在我们训练的过程中还会需要一个Discriminator,等下我会讲Generator咋样和Discriminator互动的。Discriminator的输入是一张图片,输出是一个分数。这个分数代表的含义是:这张输入的图片像不像我们要Generative产生的二次元人物的图像,如果像就给高分,如果不像就给低分。
2.algorithm
Generator和Discriminator是如何训练的?
Generator和Discriminator都是neuron network,而它们的架构取决于想要做的任务。举例来说,如果要generator产生一张图片,那显然generator里面有很多的convolution layer。若要generator产生一篇文章或者句子,显然generator就要使用RNN来产生句子。
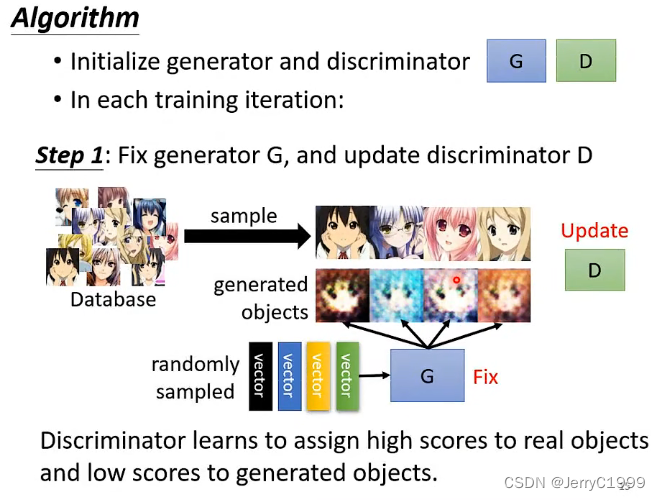
第一件事:固定generator,然后只训练discriminator(看到好的图片给高分,看到不好的图片给低分)。从一个资料库(都是二次元的图片)随机取样一些图片输入 discriminator,对于discriminatro来说这些都是好的图片。因为generator的参数都是随机给定的,所以给generator一些向量,输出一些根本不像二次元的图像,这些对于generator来说就是不好的图片。接下来就可以训练discriminator若看到上面的图片就输出1,看到下面的图片就输出0。训练discriminatro的方式跟我们一般训练neuron network的方式是一样的。
有人会把discriminator当做回归问题来做,看到上面的图片输出1,看到下面的图片就输出0也可以。有人把discriminator当做分类的问题来做,把上面好的图片当做一类,把下面不好的图片当做另一类也可以。训练discriminator没有什么特别之处,跟我们训练neuron network或者binary classifier是一样的。唯一不同之处就是:假设我们训练binary classifier的方式来训练discriminator时,不一样的就是binary classifier其中类别的资料不是人为标记,而是机器自己生成。
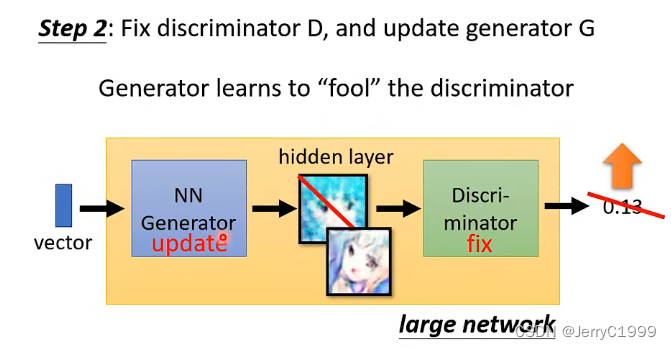
一般我们训练network是minimize人为定义的loss function,在训练generator时,generator学习的对象不是人为定义而是discriminator。你可以认为discriminator就是定义了某一种loss function,等于机器自己学习的loss function。
generator学习的目标就是为了骗过discriminator,我们让generator产生一些图片,在将这些图片输入进discriminator,然后discrimination就会给出这些图片一些分数。接下来我们把generator和discriminator串在一起视为一个巨大的network。这个巨大的network输入是一个向量,输出是一个分数,在这个network中间hidden layer的输出可以看做是一张图片。
我们训练的目标是让输出越大越好,训练时依然会做backpropagation,只是要固定住discriminator对应的维度,只是调整generator对应的维度。调整完generator后输出会发生改变,generator新的输出会让discriminator给出高的分数。
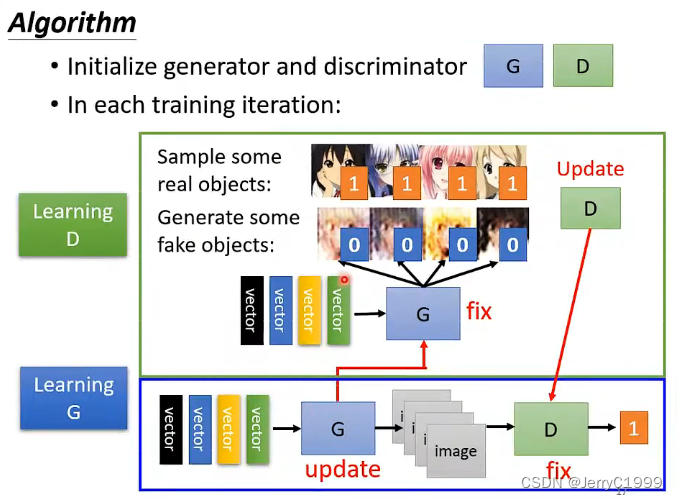
实际上在训练时,训练discriminator一次,然后在训练一次generator(固定discriminator),接下来由新的generator产生更多需要被标为0的图片,再去调discriminator,然后再调generator,generator和discriminator交替训练。
3.conditional GAN
刚才在前一步是让机器随机的产生一些东西,这些不见得是我们想要的。我们更多的想要控制机器产生出来的东西。
我们可以训练一个Generator,这个generator的输入是一段文字,输出是这段文字对应的图像。举例来说:我们现在输入“Girl with red hair”,它就输出一个。根据某一个输入产生对应输出的generator被叫做Conditional GAN。
训练一个network根据文字来产生图像,最直觉的方法就是使用supervised learning。假设可以收集到文字跟影像之间的对应关系,接下来就可以完全的套用传统的supervised learning的方法。直接训练一个network,它的输入是一段文字,输出是一张图像,希望这个输出跟原始的图像越接近越好。可以用这种方法直接训练,看到文字产生图像。
过去用这种方法(看到文字产生图像)来训练,训练出来的结果并不太好。为什么?举例说明,假设要机器学会画火车,但是训练资料里面有很多不同形态的火车,当network输入火车时它的正确答案有好多个,对于network来说会产生它们的平均作为输出。如果用supervised learning的方法产生出来的图像往往是非常模糊。
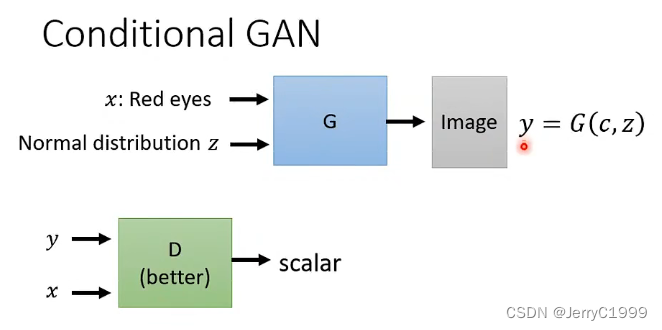
所以我们需要有新的技术(Conditional GAN)来做根据文字产生图像,对于Conditional GAN,我们也需要文字与图像的对应关系(supervised learning),但是它跟一般的supervised learning的训练目标是不一样的。
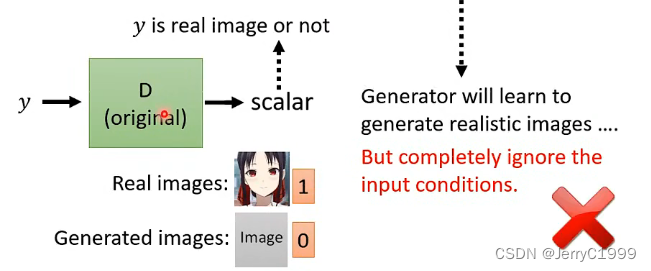
Conditional GAN是跟着discriminator来进行学习的,要注意的是:在做Conditional GAN时跟一般的GAN是不一样的。在第一部分讲一般的GAN时,discriminator是输入一张图片,然后判断它好还是不好。现在在Conditional CAN的情况下,discriminator只输入一张图片会遇到的问题是:对于discriminator想要骗过generator太容易了,它只要永远产生好的图像就行了。举例来说,永远产生猫就可以骗过discrimination(对于discriminator来说那只猫是好的图片),然后就结束了。Generator就会学到不管现在输入什么样的文字,就一律忽视,都产生好的图片。如果discrimination只看产生出来的image,那么就产生出来的image骗过它。但是输入的文字就一纪律无视它,这显然不是我们想要的。
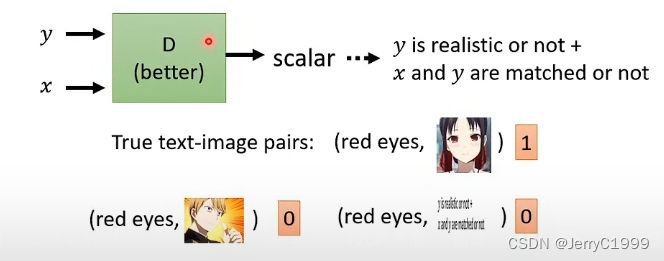
在进行Conditional GAN时往往有两个输入,discriminator应该同时看generator的输入(文字)和输出(图像),然后输出一个分数,这个分数同时代表两个含义。第一个含义是两个输入有多匹配,第二个含义是输入图像有多好。
训练discriminator时要给它一些好的输入,这些是要给高分的。在Conditional GAN的例子里面有文字与图像之间的关系,就可以从datasets里面sample出文字与图像,告诉discriminator看到这些文字和图像应该给出高分。
按照我们在第一部分GAN的想法,我们可能就是把文字输入generator,产生一些图像,这些文字和generator产生出来的图像要给予低分。光是这么做discriminator会学到判断现在的输入是好还是不好,不管文字的部分只管图像的部分,这显然不是我们想要的。所以在做Conditional GAN时,要给低分的case是要有两种。一个是跟一般的GAN一样是用generator生成图片,另外一个是从资料库里面sample出一些好的图片,但是给这些好的图片一些错误的文字。这时discriminator就会学到:并不是所有好的图片都是对的,如果好的图片对应都错误的文字它也是不好的。这样discriminator就会学懂文字与图像之间应该要有什么样的关系。

这样的技术有什么样的应用呢?除了看文字用来生成图像以外,其实只要是有data都可以拿来用Conditional GAN做做看。现在训练了一个Generator,输入声音,可以输出对应的画面。
训练Conditional GAN必须要有pair data,影像跟声音的对应关系其实并不难收集,我们可以收集到很多的video,将video中的audio部分拿出来就是声音,将image frame部分拿出来就是image,这样就有了pair data,就可以训练network。
我们刚才尝试了用文字产生影像,现在反过来想,用影像来产生文字。我们将影像用在Multi-label image Classifier上,给机器看一张图片,让机器告诉我们图片有哪些物件,比如有球,球棒等等。我们在课堂里讲的分类问题,每一个输入都只属于每一个类别。但是在Multi-label image classifier的情况下,同一张图片可以同时属于不同的类别。
一张图片可以同时属于不同类别这件事我们可以想成是一个生成的问题,现在Multi-label image Classifier是一个Conditional Generator,它的输入是一张图片(图片是condition),label是Generator输出。
4.总结
本周学习了部分GAN的相关知识,下周将继续学习。















 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









