







 本文探讨了互联网下半场背景下大数据资源优化的必要性,澄清了资源优化与性能优化的区别,详细解释了计算资源(CU)的概念及其计费方式,以及如何在不影响业务的前提下进行计算资源和存储资源的无损优化。提供了一些实用的优化技巧,如内存调整、副本数减少和压缩率提升,以降低成本并提高效率。
本文探讨了互联网下半场背景下大数据资源优化的必要性,澄清了资源优化与性能优化的区别,详细解释了计算资源(CU)的概念及其计费方式,以及如何在不影响业务的前提下进行计算资源和存储资源的无损优化。提供了一些实用的优化技巧,如内存调整、副本数减少和压缩率提升,以降低成本并提高效率。
目录
4.CU的含义为什么是1vcore+2.25G内存,为什么不是1+3或者1+4?
7.假如我按照1:2的配比申请资源,节省的内存可以给其他任务使用吗
一、背景
互联网进入下半场,对于互联网公司的考核模型也从增长考核转变为利润考核。受疫情等宏观经济环境的影响,收入不是那么容易增加,但是成本更像是一个可控输入可以更好的管控。在公司提出系统性的降本增效后,大数据资源的使用成本也需要进一步的优化,并进行更为精细化的“量入为出”。今年住宿业务的目标是把大数据资源的费用缩减30%,这在住宿数据治理进入到第3个年头是一个非常不容易达成的目标。比较容易治理的内容已经在常态化的工作中被治理掉,现在能够优化的空间往往都需要“伤筋动骨”的操作。除了靠一些常规的治理动作,本文试图通过对于底层技术的深入理解,在不影响业务使用的前提下,能够对计算和存储资源进行“无损优化”,降低资源的使用。
二、基本概念/问题的澄清
离线大数据资源主要就是存储和计算,进行资源的优化也要从这两方面入手。在做优化前首先有一些基本概念要搞清楚,才能帮助我们更好的达成目标。
1.资源优化和性能优化有什么区别?
资源优化是以使用更少的资源为唯一目标,而性能优化可以有多个目标,比如更早的就绪时间、更快的查询速度、支撑更多的并发等。资源优化和性能优化的手段可能是相通的,比如一个耗时任务优化后就绪时间提前了,使用的资源量也更少了。但有时资源优化和性能优化也是相悖的,比如一个任务执行的速度快了可能是使用了更多的资源。所以简单的用做性能优化的手段来做资源优化,可能是南辕北辙。但同时资源的优化也要受性能、稳定性、业务诉求的制约,不能不管不顾的一味减少
2.计算资源和存储资源是以什么来计费的?
存储的计量单位可以是GB、TB、PB,计算的计量单位是CU。但因为计算和存储的资源都是实时在变化的,计量单位只是某个时刻的状态值,真正的计费单位是要结合时间来看
存储资源的计费单位用的是GB/天,取得是每天最后时刻的存储占用,计费方法比较简单,用量乘以单价算出总价。
计算资源的计费单位是CU*天,计算资源的计费比较复杂,有点类似于手机号的流量计费模式。比如,套餐价格10元,套餐内有2G的流量。一个月使用不超过2G流量则只需要花费套餐的价格10元,但即使你一点流量都没有也需要花10元套餐费。若使用了3G流量,超出套餐的1G流量会按照一个单价,比如5元/G计费,最终一个月花费10元套餐费+5元超出流量费=15元。大数据的计算资源也类似,分为配额计费(类比套餐)和弹性计费(类比套餐外)。比如配额是1000CU/天,价格1元/CU*天,则在任何时刻只要使用的资源不超过1000CU,一天的费用就是1000元,即使这一天你一个CU都没有使用。而如果某些时间段,比如夜间2点到4点两个小时的时间使用了3000CU的资源,那么除了需要支付1000元的配额费,还需要为使用的弹性资源2000CU支付(2000*2小时/24小时)*弹性资源单价的费用。由于弹性资源是不可保障的资源(有可能完全申请不到),所以单价上是配额资源单价的一半。
3.什么是CU,CU和CU*分钟、CU*天有什么关系?
CU是计算单元(computer unit)的简称,离线计算1 CU=(1 vcores(虚拟cpu核心=0.64物理cpu核心),2.25G内存)。CU是一个状态值,代表某一时刻申请或分配的资源量,对于提交到yarn上的一个任务,每分钟会做一次采样,记录采样时刻资源的使用量并用采样值代表这一分钟该任务使用的资源量。如果一个任务执行了3分钟,第一分钟采用值是200CU,第二分钟采样值100CU,第三分钟采样值500CU,则该app使用的总资源量=200CU*1分钟+100CU*1分钟+500CU*1分钟=800CU*分钟,一天有60*24分钟=1440分钟所以800CU*分钟=0.55CU*天。日常中我们经常说的xxCU,一般指的是CU*天。
4.CU的含义为什么是1vcore+2.25G内存,为什么不是1+3或者1+4?
对于yarn来说,在资源分配的时候并不会对CPU和内存的比例有所限制,可以申请1+2或者1+3。阿里云的配置就和我们不一样,一个CU就是1vcore+4G内存。
那么是什么决定了cpu和内存的比例?我推测大概率是购买的物理机中cpu和内存的配比,再乘以虚拟化后物理CPU Core和vcore的放大比例。所以vcore和内存的比例可能是由采购机型和虚拟化放大比例共同决定的。
5.一个任务使用的CU数是如何确定的?
本质上来说,一个任务的资源使用量等于资源使用量曲线在时间上的积分面积,因为是用采样值代表一分钟内的实际值,所以资源使用量就是柱状图的总面积。
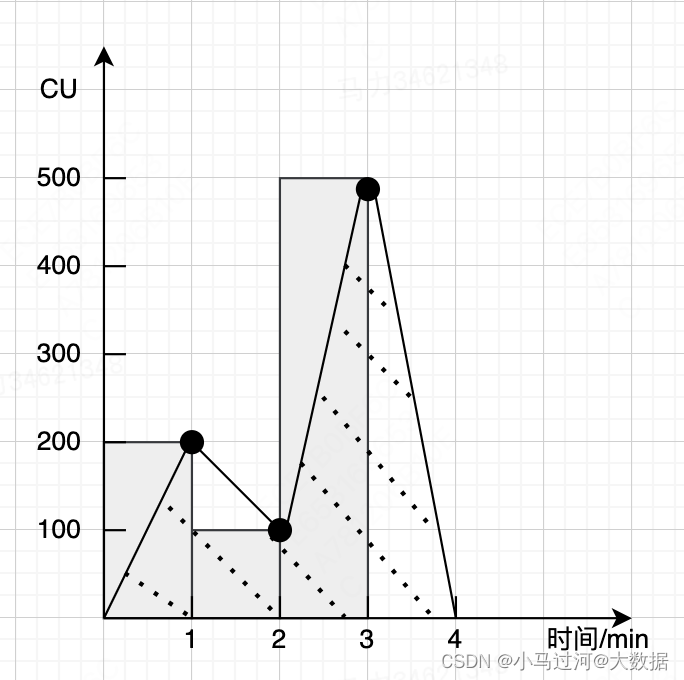
但是一个任务在某个时间点申请的vcore和内存并不一定是1:2.25的关系,那么某个时刻的CU值是如果确定的?答案是CU=Max(vcore,memory/2.25)。因为xt上默认为一个executor分配(1vcore,3Gmemory),默认为一个driver分配(1vcore,11Gmemory),所以默认情况下都是由使用的内存量来决定使用的CU数量。
6.假如我就使用1:3的配比申请资源,有什么问题吗?
会造成一定的资源浪费。比如一共有300CU的计算资源,换算后是300个vcore和675G的内存,如果按照1:3的配比使用资源,则内存会优先耗尽,675G内存耗尽后,vcore才使用了675/3=225个,相当于浪费了300-225=75个vcore资源。
下图可以看到,在vcore还有富余的情况下,就已经产生了资源pending
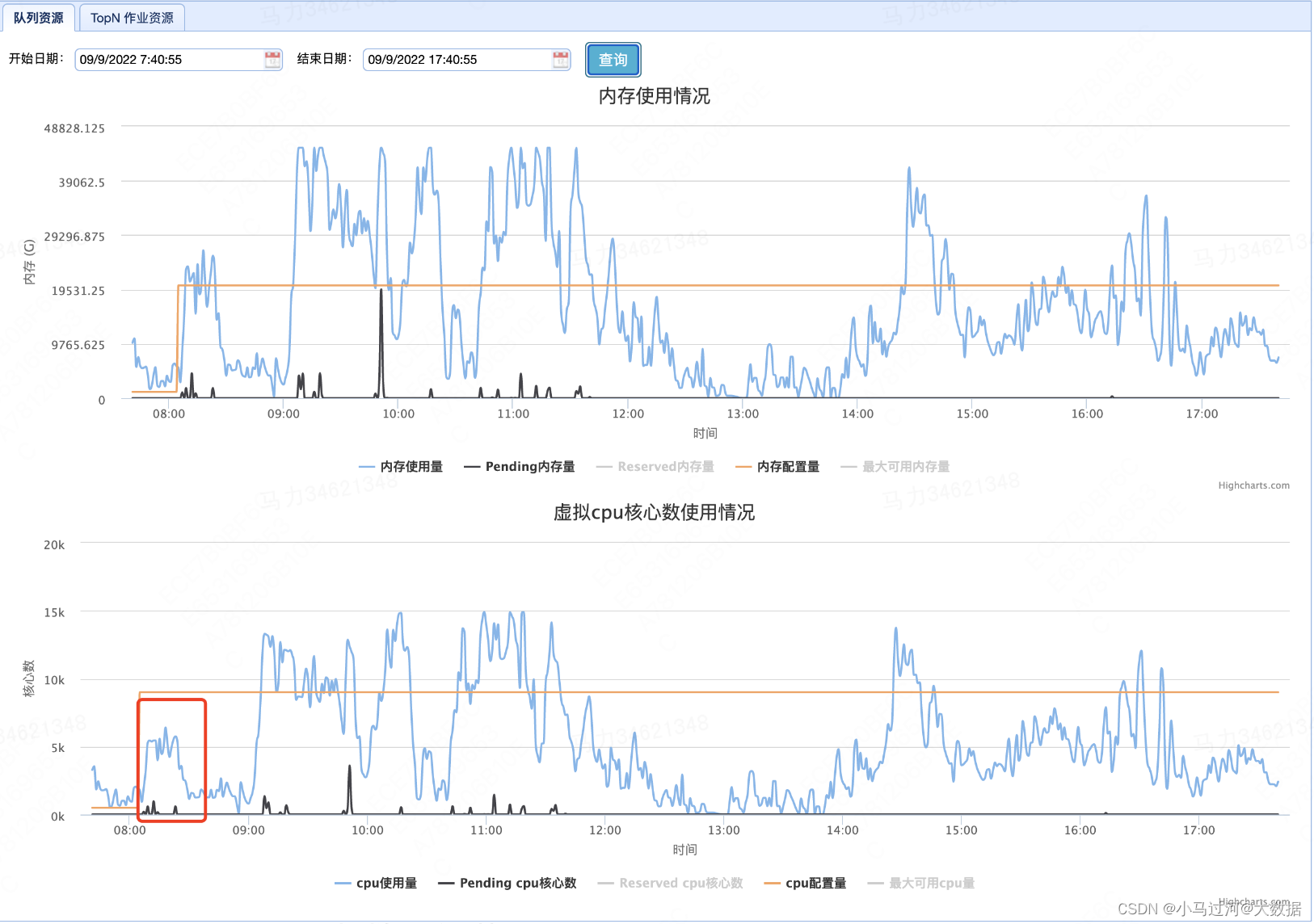
7.假如我按照1:2的配比申请资源,节省的内存可以给其他任务使用吗
可以的。CU仅仅是一个计费单位,并不是分配单位,也不是资源的最小切割单位。有的人可能会有这样的担心,假设我有两个任务A和B,A用了10个vcore和18GB内存,在计费时会记为使用了10CU。B用了10vcore,45GB内存,计费时会记为使用了45/2.25=20CU。如果总体计费时把A和B使用的CU相加则一共使用了30CU,但A和B一共使用了20vcore和63GB内存,应该是总统使用63/2.25=28CU,这样会不会就浪费了2CU?实际上并不会出现这种情况,CU的使用在任务粒度和队列粒度是分别计算的,并不是对任务的CU使用量求和算出的队列CU使用量,因此也就不会造成浪费。
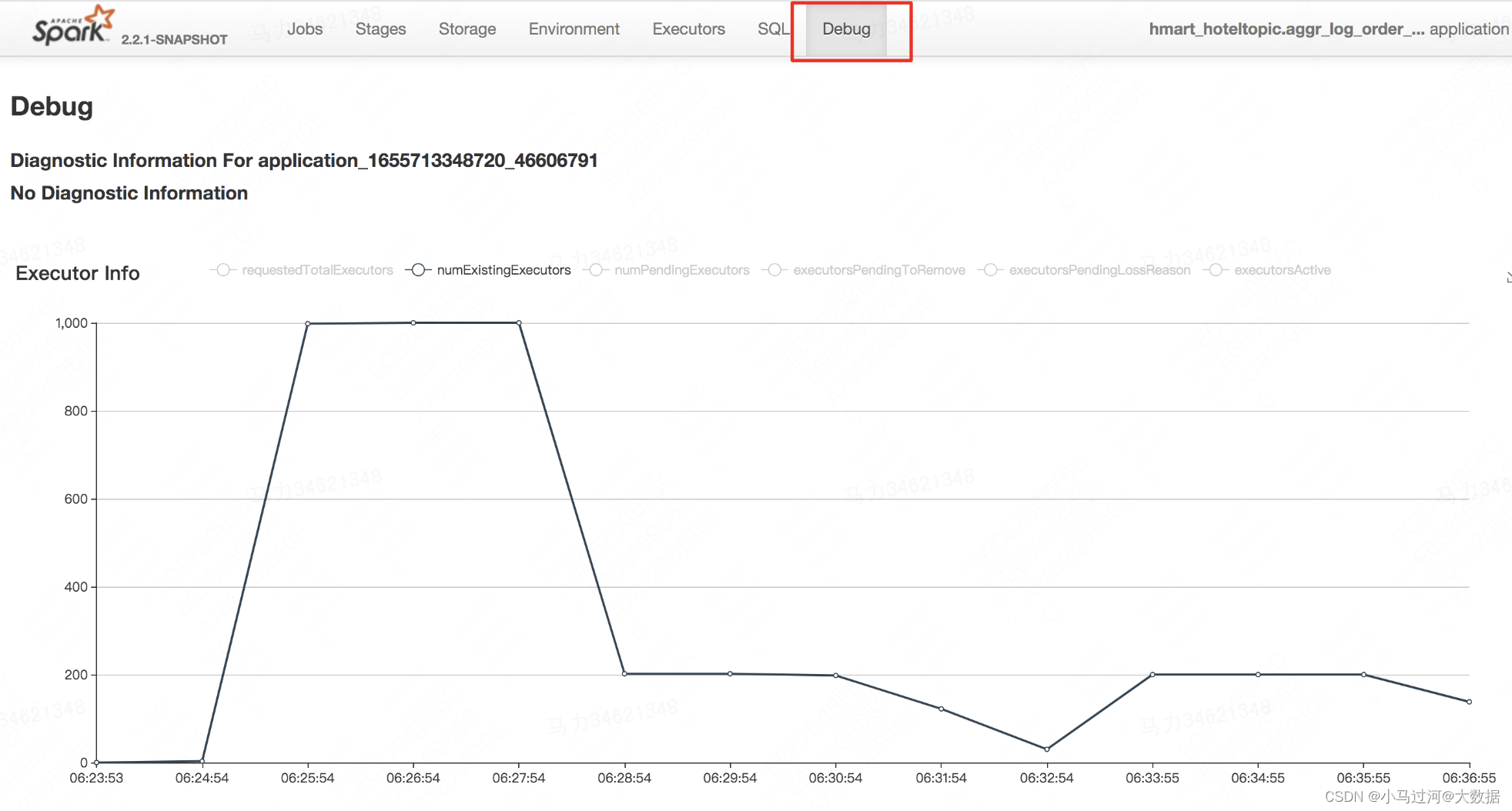
8.如何看到一个任务的一次执行使用的资源量
我们在Spark UI的debug可以看到不同时间点申请的executor数量,根据executor和driver端的vcore和memory的设置,可以大致计算出一次执行的资源开销。
三、优化技巧
一个问题如果能按照因果关系拆解出其中的因,则针对因做功就可以很好的解决这个问题。
下面具体给出的优化技巧,可以在不影响业务使用的前提下,对于计算和存储资源进行“无损优化”。在常用的数据治理已经达到极致后,依然可以从底层技术入手,降低资源的使用。
计算资源
计算资源的使用量可以抽象为一个数学公式
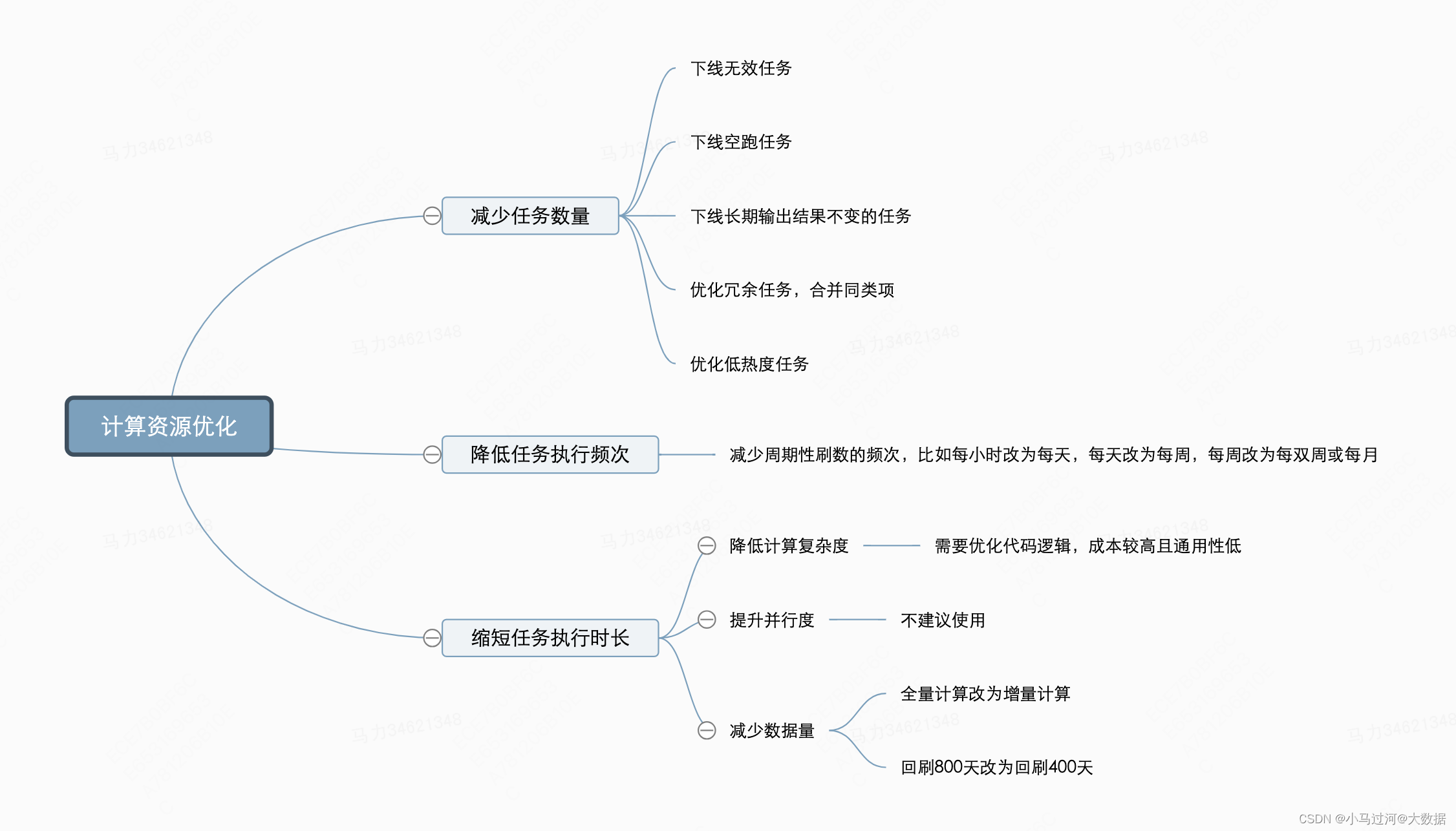
计算资源使用量=任务数量*任务执行次数*任务执行时长*单位时间计算开销
在过往的数据治理上,我们一般集中在前面三项进行优化,即减少任务数量、降低任务执行次数、缩短任务执行时长
其中需要注意的是以增加资源使用来缩短任务执行时长往往是得不偿失的,不太建议使用
假如上面的动作都做完后,使用的资源依然需要节省有没有办法解决呢?
其实在了解上面的基本概念后,如果熟练掌握spark内存模型的原理(可以参考storage memory的含义),在单位时间计算开销上也有很大的优化空间。本质上就是减少单位时间对计算资源的申请/使用
方法1:不用过多的内存
最好确保vcore和内存的比例是1:2.25(不同云计算产品中这个比例可能不同),可以设置的参数为spark.driver/executor.memory和spark.yarn.driver/executor.memoryOverhead。由于一个任务就一个driver,所以改动driver端的内存效果很小可以先集中在executor端的内存优化。默认情况下,xt任务会申请3G内存,如果内存使用率很低,可以减少内存的使用量,推荐改为
##一共申请2.25G内存
set spark.executor.memory=1536M;##1.5G
set spark.yarn.executor.memoryOverhead=768;##0.75G注意:参数不能设置为小数,所以想设置1.5G内存要转换单位为MB。
注意2:由于spark任务的executor进程是运行在yarn上的Container中,而RM给每个Container分配的内存必须是yarn.nodemanager.resource.memory-mb的整数倍,在美团的集群中yarn.nodemanager.resource.memory-mb被设置为256MB,所以内存参数设置也要是256MB的整数倍(spark.executor.memory+spark.yarn.executor.memoryOverhead),不然实际分配时会向上“取整”。
方法2:把内存更多分配给统一内存
假如使用方法1后发现内存不够用,此时可以根据内存模型的结构,把整体内存降低一半,把统一内存比例提升一倍,这样实际可以使用的统一内存仍然保持不变(有关spark内存模型可以参考我之前写的文章)
##社区版默认就是0.6,美团集群改为了0.3,改为0.6就是提高了一倍。
##如果没有UDF可以尝试进一步提到到0.8
set spark.memory.fraction=0.6;存储资源
存储资源的拆解相对比较容易,一般来说就是简单的拆解为表数量*表大小,而表大小一般又可以拆解为记录数*字段数*字段类型。整体来说
存储使用量=表数量*记录数*字段数*字段类型
由于字段数量和字段类型的改动成本很高,所以对于存储空间的优化过往的治理动作基本就集中在表数量和记录数上,比如无效存储删除、生命周期管理、表的视图化等。但当治理进入深水区,表的数量、记录数、字段数都不能改变时,是否还有方法来减少存储使用量。答案当然是有的,需要结合更深层的技术原理来优化。结合HDFS和ORC文件的特性,存储使用量可以继续拆解为
存储使用量=表数量*副本数*压缩率*记录数*字段数*字段类型
在副本数和压缩率上,我们还是有优化的空间。
方法1:减少副本数
HDFS默认都是3副本,如果我们可以降低为2副本,则可以节省33%的存储空间。实际上通过hadoop命令是可以调整指定目录下的文件副本数
##命令
/opt/meituan/hadoop/bin/hadoop fs -setrep —R 2 hdfs目录
##调整一个表
/opt/meituan/hadoop/bin/hadoop fs -setrep —R 2 数据表的hdfs目录
##调整一个表的2020年分区
/opt/meituan/hadoop/bin/hadoop fs -setrep —R 2 数据表的hdfs目录/datekey=2020*/注意:
1、降低副本数会影响数据的可靠性,尤其是核心表非常不建议调整副本数(在我们的使用中偶尔会出现数据块丢失,建议只减少大表冷分区的副本数,保留近期热分区的副本数);
2、降低副本数对下游任务的读可能会有影响,以副本数从3调整到2为例,3副本数的时候可以同时支撑~1500个读并发,到2副本能支撑的的最大读并发~1000;超出后会出现数据读取失败或者数据丢失等异常;所以下游数量较多的表不建议调整副本数。
以上对于存量的数据可以减少存储的副本数,但是对于增量的分区数据,还需要在任务中增加参数(set hadoop.spark.dfs.replication=2;)来设置每天增量生产的数据也是2副本。
由于并发数和可靠性会降低,所以适用场景是下游任务较少且非核心的数据表,也可以对于历史冷数据单独缩小副本数。
方法2:提升压缩率
ORC文件的特性是按照stripe进行压缩,因此对于数据记录按照相似度重排序可以提升压缩率,在我们的实践中一些日志类型的大表重排序后可以压缩90%以上,效果非常的好。
注意:压缩率的增加对于当前任务的写和下游任务的读都有一定风险,要全面的考量。
写数据的影响主要是两个原因,一是增加一轮排序耗时,二是压缩率过高,导致最终输出的文件较小,被识别为小文件,进而又增加一轮小文件合并。原因1影响一般不大,如果你的排序字段会出现在某次join,如果可以把这次join放到最后一个stage,那么不用增加排序也会有很大的压缩(前提是sort merge join)。原因2影响通常较大,会有一二十分钟的增加。但是原因二不是一定会出现,通常只在压缩率非常高的情况下才会出现。一般是取消小文件的合并即可
压缩后,下游读的效率可能会变低。比如原先1个亿的数据,大小100G存在1000个文件中,下游读数据按照文件切分的话会有1000个task,只要资源给够可以达到1000的并发读取,每个task处理10w条数据。但是你压缩为10G后,假如变为100个文件,下游依然按照文件切分读取的话,可能会变成100的并发,每个task就需要处理100w条数据,自然读取的时间就慢了。这种情况下,要么上游就是不合并文件,10G大小依然存1000个文件,下游就不会有问题。要么就是下游读取时,按大小切分文件,比如每10M一个split进行读取,这样读取的并发变得和原来一样。不论是哪种方法,只要保证下游读取的并发和压缩前是一样的,事实上的读取速度是会变快一些的(存储小了,磁盘IO、网络IO都会变小)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









