









YOLO v7论文解读
摘要总结
首先对文章的摘要进行解读:摘要原文如下所示:
YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS and has the highest accuracy 56.8% AP among all known real-time object detectors with 30 FPS or higher on GPUV100. YOLOv7-E6 object detector (56 FPS V100, 55.9%AP) outperforms both transformer-based detector SWINL Cascade-Mask R-CNN (9.2 FPS A100, 53.9% AP) by 509% in speed and 2% in accuracy, and convolutionalbased detector ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) by 551% in speed and 0.7% AP in accuracy, as well as YOLOv7 outperforms: YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5, DETR, Deformable DETR, DINO-5scale-R50, ViT-Adapter-B and many other object detectors in speed and accuracy. Moreover, we train YOLOv7 only on MS COCO dataset from scratch without using any other datasets or pre-trained weights. Source code is released in https:// github.com/WongKinYiu/yolov7.
对于摘要的翻译可以参考下面的表达方式。
YOLOv7在5FPS到 160 FPS 范围内的速度和准确度都超过了所有已知的物体检测器,YOLOv7 在 5 FPS 到 160 FPS 范围内的速度和准确度都超过了所有已知的目标检测器,并且在 GPU V100 上 30 FPS 或更高的所有已知实时目标检测器中具有最高的准确度 56.8% AP。YOLOv7-E6 目标检测器(56 FPS V100,55.9% AP)比基于transformer-based的检测器 SWINL Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)的速度和准确度分别高出 509% 和 2%,以及基于卷积的检测器 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度提高 551%,准确率提高 0.7%,以及 YOLOv7 的表现优于:YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR、Deformable DETR , DINO-5scale-R50, ViT-Adapter-B 和许多其他物体探测器在速度和准确度上。 此外,我们只在 MS COCO 数据集上从头开始训练 YOLOv7,而不使用任何其他数据集或预训练的权重。 源码发布在: GitHub - WongKinYiu/yolov7: Implementation of paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
摘要总结
YOLOv7的成就
在5FPS到160FPS的范围内,在速度和精度上都超过了所有已知的物体检测器,在GPU V100上以30 FPS或更高的速度在所有已知 的实时物体检测器中具有最高的精度56.8%AP
YOLOv7-E6在速度和精度上优于
- 基于transformer的检测器SWINL Cascade-Mask R-CNN
- 基于卷积的检测器ConvNeXt XL级联掩码R-CNN
-
YOLOv7优于
YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR、可变形DETR、DINO-5scale-R50、ViT-Adapter-B和许多其他物体检测器的速度和精度。 -
训练方面:作者只在COCO数据集上从0开始训练YOLOv7,而不使用任何其他数据集或预先训练的权重。
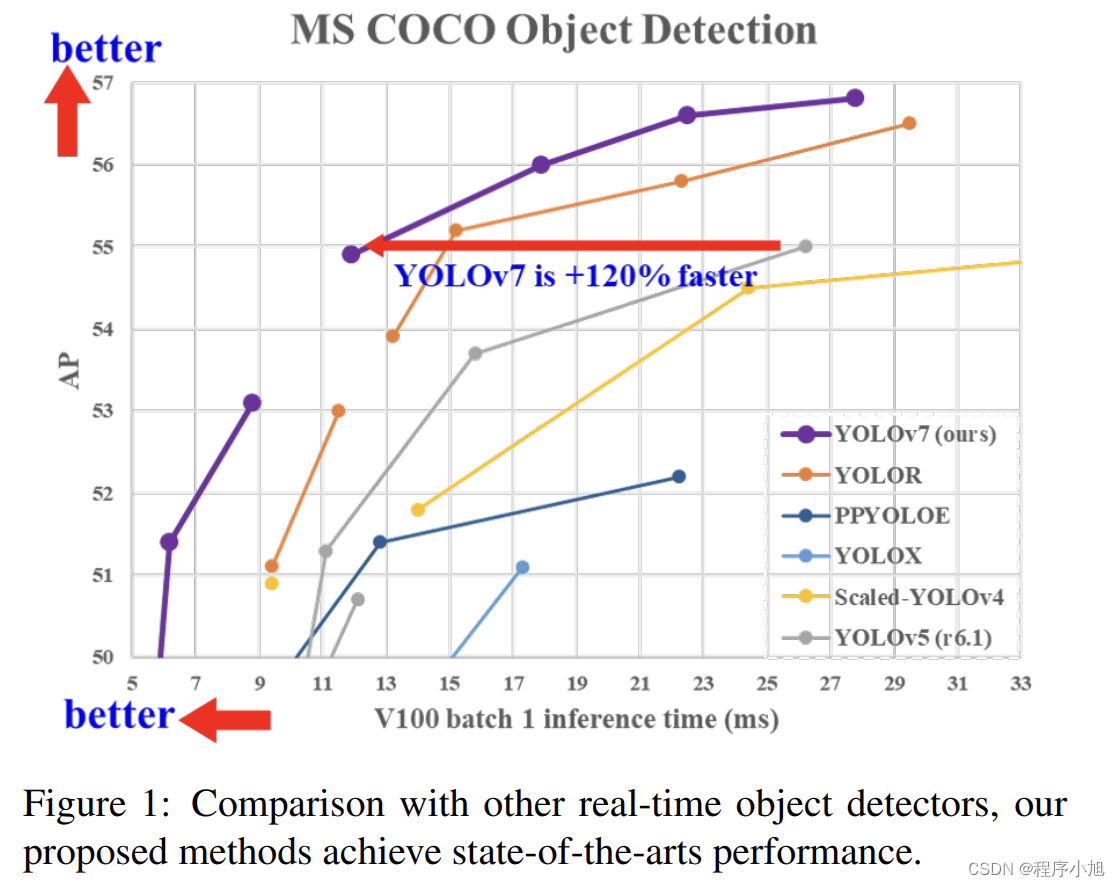
从摘要和结论中我们总结一下论文中提出的两个主要的创新点为:
- 提出了一种新的实时目标检测器架构
- 提出了相应的模型缩放方法
引言(Introduction)
首先对引言部分的原文内容进行翻译:(对文章的写作动机方面进行一定的阐述)
-
实时对象检测是计算机视觉中非常重要的主题,因为它通常是计算机视觉系统中的必要组件。 例如,多目标跟踪[94, 93],自动驾驶[40, 18],机器人[35, 58],医学图像分析[34, 46]等。执行实时目标检测的计算设备通常是一些移动CPU或GPU,以及各大厂商开发的各种神经处理单元(NPU)。 比如苹果神经引擎(Apple)、神经计算棒(Intel)、Jetson AI边缘设备(Nvidia)、边缘TPU(谷歌)、神经处理引擎(Qualcomm)、AI处理单元(MediaTek)、 和 AI SoC(Kneron)都是 NPU。 上面提到的一些边缘设备专注于加速不同的操作,例如普通卷积、深度卷积或 MLP 操作。 在本文中,我们提出的实时目标检测器主要希望它能够同时支持移动 GPU 和从边缘到云端的 GPU 设备。
-
近年来,实时目标检测器仍在针对不同的边缘设备进行开发。例如,开发MCUNet [49, 48] 和 NanoDet [54] 的运营专注于生产低功耗单芯片并提高边缘 CPU 的推理速度。 至于 YOLOX [21] 和 YOLOR [81] 等方法,他们专注于提高各种 GPU 的推理速度。 最近,实时目标检测器的发展集中在高效架构的设计上。 至于可以在 CPU [54, 88, 84, 83] 上使用的实时目标检测器,他们的设计主要基于 MobileNet [28, 66, 27]、ShuffleNet [92, 55] 或 GhostNet [25] . 另一个主流的实时目标检测器是为 GPU [81, 21, 97] 开发的,它们大多使用 ResNet [26]、DarkNet [63] 或 DLA [87],然后使用 CSPNet [80] 策略来优化架构。 本文提出的方法的发展方向与当前主流的实时目标检测器不同。 除了架构优化之外,我们提出的方法将专注于训练过程的优化。 我们的重点将放在一些优化的模块和优化方法上,它们可能会增加训练成本以提高目标检测的准确性,但不会增加推理成本。我们将提出的模块和优化方法称为可训练的bag-of-freebies。
最近,模型重新参数化[13,12,29]和动态标签分配[20,17,42]已成为网络训练和目标检测的重要课题。 主要是在上述新概念提出之后,物体检测器的训练演变出了很多新的问题。 在本文中,我们将介绍我们发现的一些新问题,并设计解决这些问题的有效方法。对于模型重参数化,我们用梯度传播路径的概念分析了适用于不同网络层的模型重参数化策略,并提出了有计划的重参数化模型。 此外,当我们发现使用动态标签分配技术时,具有多个输出层的模型的训练会产生新的问题。即:“如何为不同分支的输出分配动态目标?” 针对这个问题,我们提出了一种新的标签分配方法,称为coarse-to-fine引导式标签分配
-
本文的贡献总结如下:(1)我们设计了几种可训练的bag-of-freebies方法,使得实时目标检测可以在不增加推理成本的情况下大大提高检测精度;(2) 对于目标检测方法的演进,我们发现了两个新问题,即重新参数化的模块如何替换原始模块,以及动态标签分配策略如何处理分配给不同输出层的问题。 此外,我们还提出了解决这些问题所带来的困难的方法;(3) 我们提出了实时目标检测器的“扩展”和“复合缩放”方法,可以有效地利用参数和计算; (4) 我们提出的方法可以有效减少最先进实时目标检测器约40%的参数和50%的计算量,并具有更快的推理速度和更高的检测精度。
引言总结
本文主要工作
- 提出了一个实时对象检测器,主要是希望它能够从边缘到云端同时支持移动GPU和GPU设备
- 优化了架构,专注于优化训练过程。重点放在优化模块和优化方法上,称为可训练的
Bag of freebies。
其实关于Bag of freebies和Bag of specials我们在YOLOv4就见过
- Bag of freebies:字面意思就是“免费赠品”。在这里就是指用一些比较有用的训练技巧来训练模型, 只会改变训练策略或只会增加训练成本(不增加推理成本)的方法。从而使得模型获得更好的准确率但不增加模型的复杂度,也就不会增加推理的计算量。
- Bag of specials:指一些插件模块(plugin modules)和后处理方法(post-processing methods), 它们只稍微增加了推理成本,但可以极大的提高目标检测的准确度。 一般来说,这些插件用来提高一个模型中的特定属性。比如增加感受野( SPP、 ASPP、 RFB),引入注意力机制(spatial attention、channel attention),提高特征整合的能力(FPN、ASFF、BiFPN)。
重点部分提出
- 模型重参数化问题:(
model re-parameterization)
- 对于
模型重参数化问题,本文使用梯度传播路径的概念分析了适用于不同网络中的层的模型重参数化策略,并提出了有计划的重参数化模型。
- 动态标签分配问题(
dynamic label assignment)
- 对于
动态标签分配问题,本文提出了一种新的标签分配方法,称为由粗到细引导标签分配(coarse-to-fine)
论文的主要贡献点
(1) 提出了几种可用于训练的方法,这些方法仅仅会增加训练上的负担用于提升model性能,而不会增加推理负担
(2)对于目标检测方法的发展,作者发现了两个新问题:
①重参数化模块如何替换原始模块
②动态标签分配策略如何处理对不同输出层的分配
论文提出了解决这俩问题的方法
(3) 作者针对目标检测可以更有效的利用参数和计算问题,提出了"扩展"(extend)和“复合缩放”(compound scaling)
(4) 提出的方法可以有效的减少40%参数量和50%计算量,高精度高速度
相关工作(Related work)
对目前已有的文献进行一部分总结,同时对之前的引言部分进行一定的补充和说明。
实现目标检测器
先进的网络应该具有以下特性:
-
更快更有效的网络
-
更有效的特征集成方法
-
更准确的检测方法
-
更有鲁棒性的损失函数
-
更有效的标签匹配方法
-
更有效的训练方法
论文中提出了6种特性,并介绍了之前的实时目标检测网络yolo.论文中的创新和改进方式主要集中在4.5.6三个部分
模型重新参数化
模型重新参数化的介绍
在训练时将一个模块拆分为多个相同或不同的模块分支;在推理时将多个分支模块整合为一个完全等效的模块。
有两种方法:即模块级集成和模型级集成
获得最终推理模型的两种方法
-
用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均
-
对不同迭代次数的模型权重进行加权平均
优点:
训练时,采用多分支的网络使模型获取更好的特征表达推理时,将并行融合成串行,从而降低计算量和参数量,提升速度(融合后理论上和融合前识别效果一样,实际基本都是稍微降低一点点)不足并不是所有提出的重新参数化模块都可以完美地应用于不同的架构。
模型缩放
模型缩放部分, 说明了网络架构搜索(NAS)的确定和一些常见的缩放因子。
常采用的缩放因子
- 分辨率(输入图像的大小)
- 深度(层数)
- 宽度(通道数)
- 阶段(特征金字塔的数量)
常用方法:NAS
介绍:NAS即模型搜索,其主要思路就是不需要人为去设计特定的网络,而是让模型自己去选择。不足:消耗大量的时间和资源
注意问题:
-
怎么定义候选空间
-
加速训练
网络结构(Architecture)
在大多数关于设计高效架构的文献中,主要考虑因素不超过参数的数量、计算量和计算密度。Ma 等人还从内存访问成本的特点出发,分析了输入/输出通道比、架构的分支数量以及 element-wise 操作对网络推理速度的影响。多尔阿尔等人在执行模型缩放时还考虑了激活,即更多地考虑卷积层输出张量中的元素数量。 图 2(b)中 CSPVoVNet [79] 的设计是 VoVNet [39] 的变体。 除了考虑上述基本设计问题外,CSPVoVNet [79] 的架构还分析了梯度路径,以使不同层的权重能够学习更多不同的特征。上述梯度分析方法使推理更快、更准确。 图 2 © 中的 ELAN [1] 考虑了以下设计策略——“如何设计一个高效的网络?”。 他们得出了一个结论:通过控制最短最长的梯度路径,更深的网络可以有效地学习和收敛。 在本文中,我们提出了基于 ELAN 的扩展 ELAN(E-ELAN),其主要架构如图 2(d)所示。
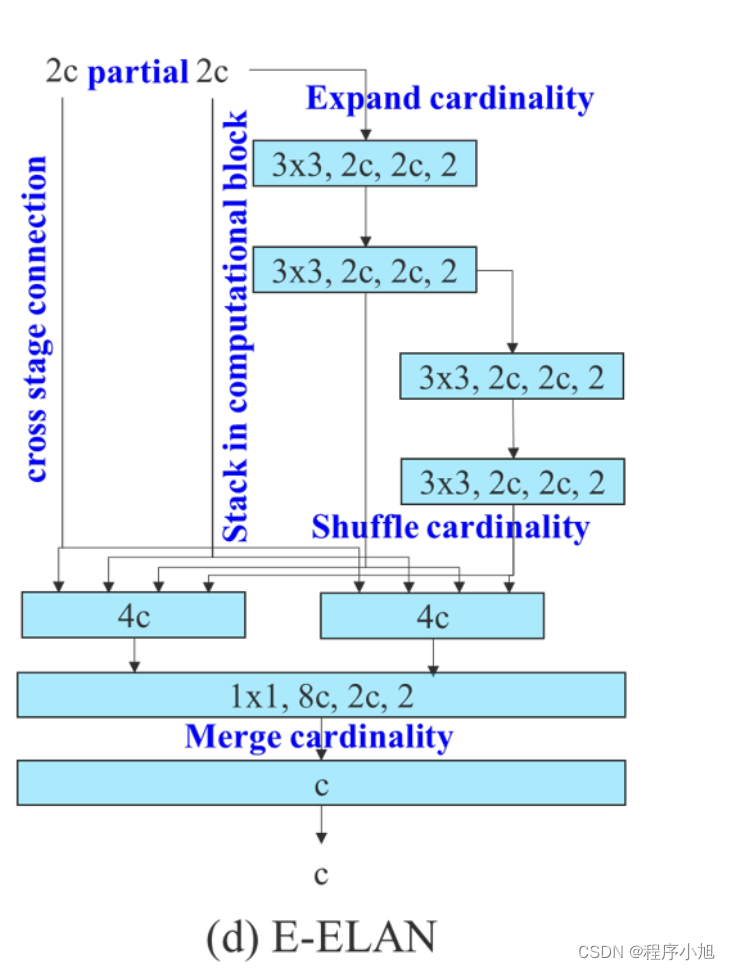
无论梯度路径长度和大规模 ELAN 中计算块的堆叠数量如何,它都达到了稳定状态。 如果无限堆叠更多的计算块,可能会破坏这种稳定状态,参数利用率会降低。 提出的E-ELAN使用expand、shuffle、merge cardinality来实现在不破坏原有梯度路径的情况下不断增强网络学习能力的能力。在架构方面,E-ELAN 只改变了计算块的架构,而过渡层的架构完全没有改变。 我们的策略是使用组卷积来扩展计算块的通道和基数。 我们将对计算层的所有计算块应用相同的组参数和通道乘数。 然后,每个计算块计算出的特征图会根据设置的组参数g被打乱成g个组,然后将它们连接在一起。 此时,每组特征图的通道数将与原始架构中的通道数相同。 最后,我们添加 g 组特征图来执行合并基数。 除了保持原有的 ELAN 设计架构,E-ELAN 还可以引导不同组的计算块学习更多样化的特征。
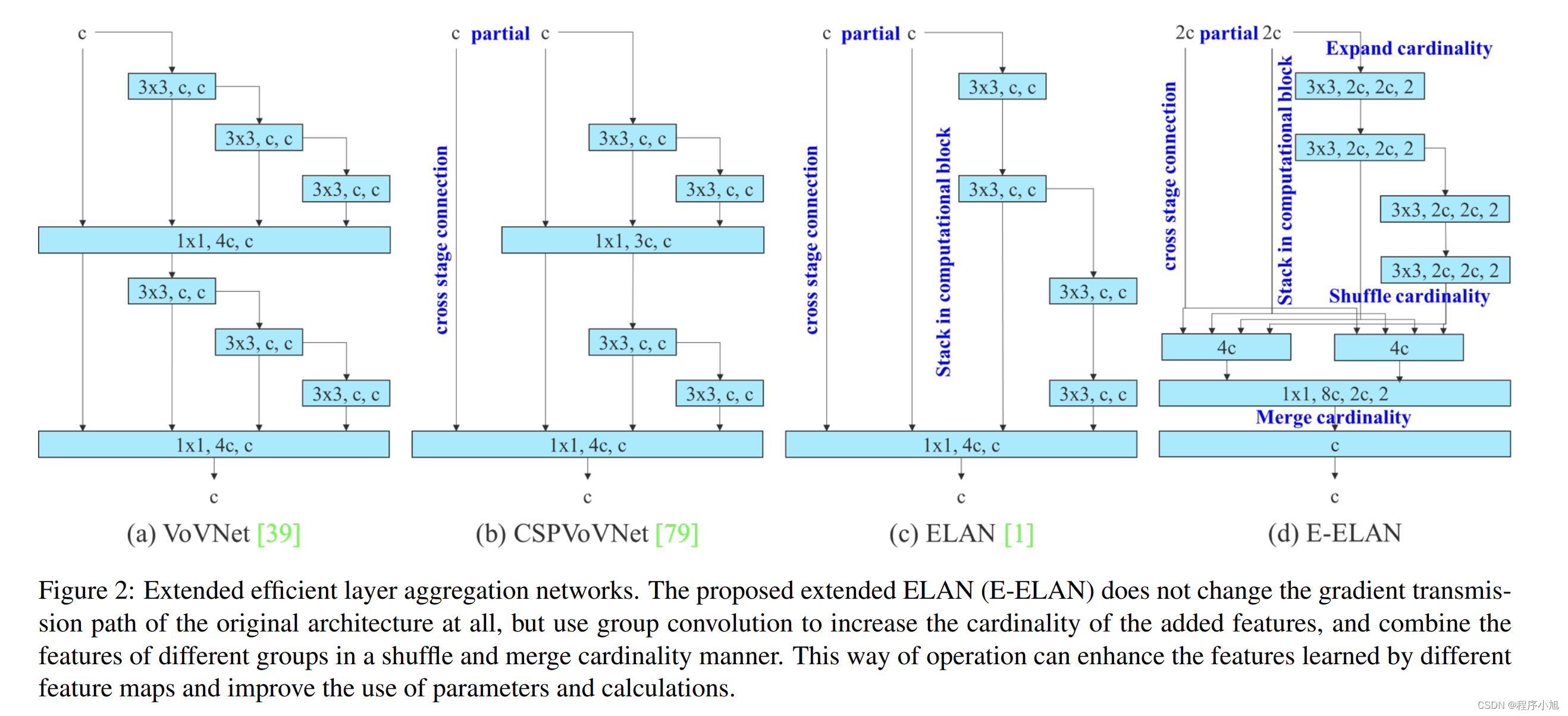
VoVNet
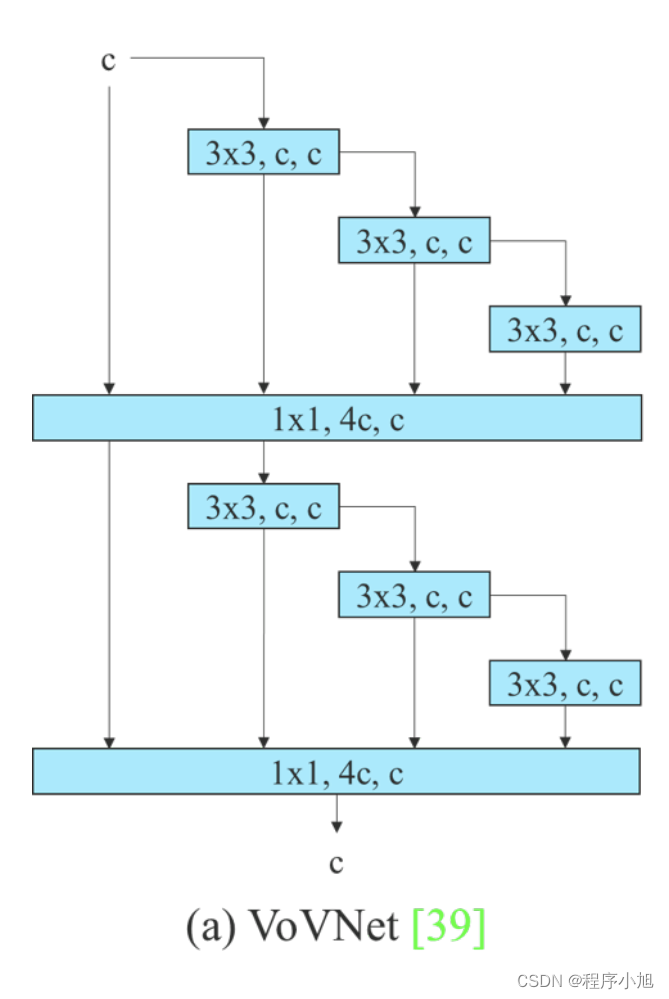
VoVNet是一个基于连接的模型,由OSA组成,将 DenseNet 改进的更高效,区别于常见的plain结构和残差结构。
这种结构不仅继承了 DenseNet 的多感受野表示多种特征的优点,也解决了密集连接效率低下的问题。
CSPVoVNet
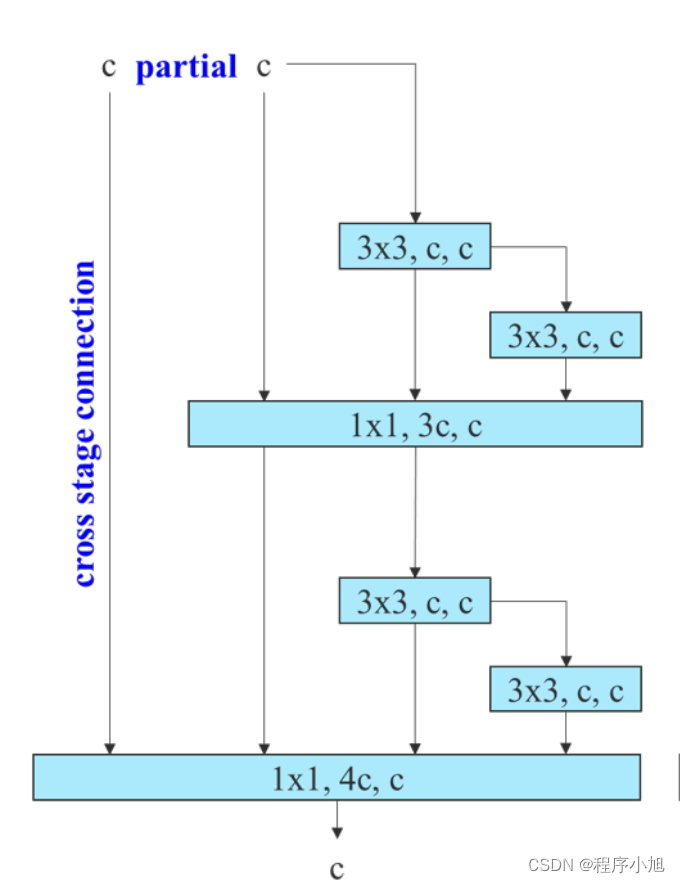
是VoVNet的CSP变体,CSPVoVNet除了考虑到参数量、计算量、计算密度、ShuffleNet v2提出的内存访问成本(输入输出通道比,架构分支数量,element-wise等),还分析了梯度路径,可以让不同层的权重学习到更具有区分性的特征。
ELAN
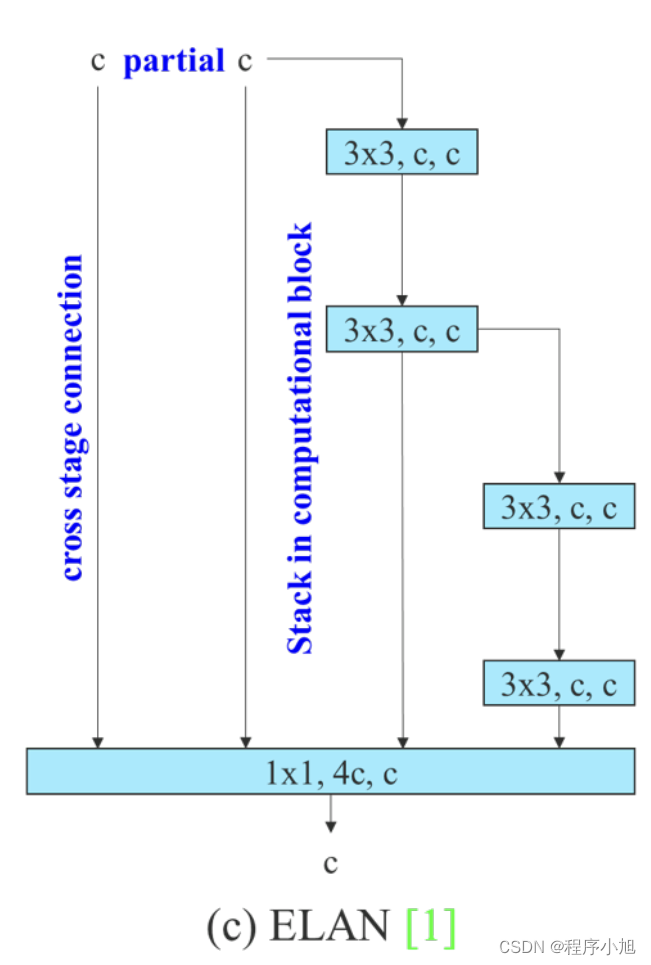
就“如何设计一个高效的网络”得出结论:通过控制最短最长的梯度路径,更深的网络可以更有效地学习和收敛。
梯度路径设计的优点与缺点
梯度路径设计策略总共有3个优点:
- 可以有效地使用网络参数 ,在这一部分中提出通过调整梯度传播路径,不同计算单元的权重可以学习各种信息,从而实现更高的参数利用效率
- 具有稳定的模型学习能力,由于梯度路径设计策略直接确定并传播信息以更新权重到每个计算单元,因此所设计的架构可以避免训练期间的退化
- 具有高效的推理速度,梯度路径设计策略使得参数利用非常有效,因此网络可以在不增加额外复杂架构的情况下实现更高的精度。
由于上述原因,所设计的网络在架构上可以更轻、更简单。
梯度路径设计策略有1个缺点:
- 当梯度更新路径不是网络的简单反向前馈路径时,编程的难度将大大增加。
E-ELAN
是作者提出的 Extended-ELAN (E-ELAN) ,E-ELAN 使用了 expand、shuffle、merge cardinality来实现对 ELAN 网络的增强。
在架构方面,E-ELAN 只改变了计算块(computation blocks)的架构,而过渡层(transition layer)的架构完全没有改变。
YOLOv7 的策略是使用组卷积来扩展计算块的通道和基数。
实现方法:
- 首先,使用组卷积来增大通道和计算块的基数 (所有计算块使用的组参数及通道乘数都相同)
- 接着,将计算块得到的特征图 shuffle 到 g 个组,然后 concat,这样一来每个组中的特征图通道数和初始结构的通道数是相同的
- 最后,将 g 个组的特征都相加
基于连接的模型的模型缩放
模型缩放的主要目的是调整模型的一些属性,生成不同尺度的模型,以满足不同推理速度的需求。 例如,EfficientNet [72] 的缩放模型考虑了宽度、深度和分辨率。至于 scaled-YOLOv4 [79],其缩放模型是调整阶段数。 在 [15] 中,Dollar等人。分析了香草卷积和组卷积在进行宽度和深度缩放时对参数量和计算量的影响,并以此设计了相应的模型缩放方法。
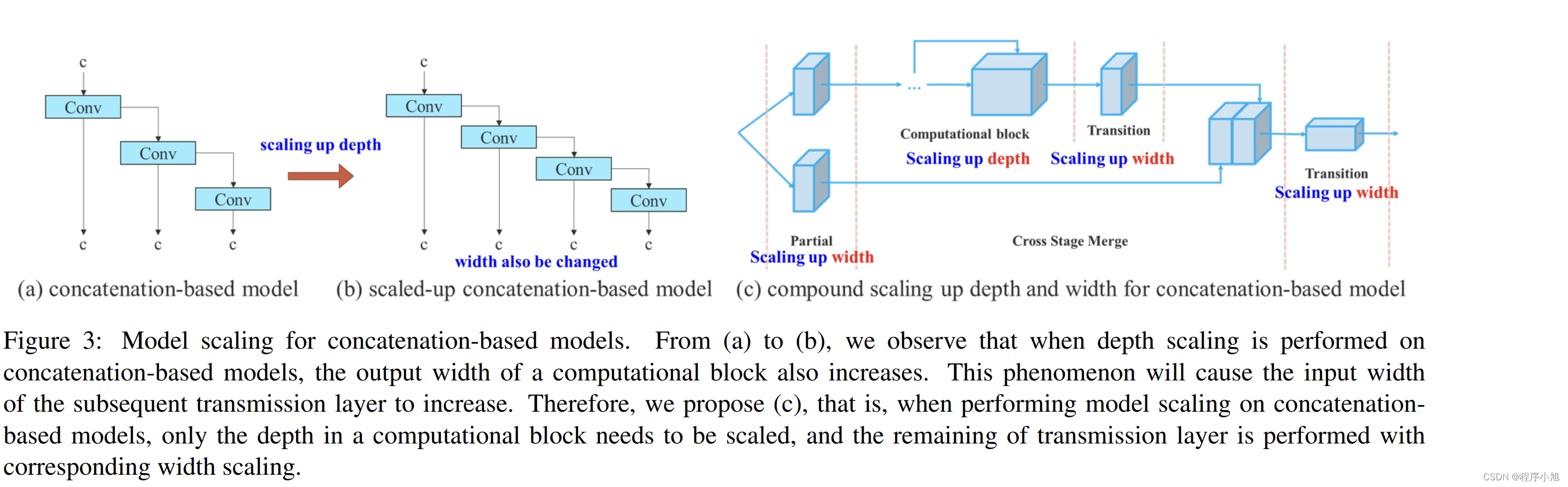
模型缩放的主要目的
模型缩放的主要目的是调整模型的某些属性,并生成不同比例的模型,以满足不同推理速度的需要【像V5和YOLOX】
问题引入
每个比例因子的参数和计算是可以独立分析的。然而,如果将这些方法应用于基于连接的模型架构,我们会发现当对深度进行放大或缩小时,后续网络层的输入width发生变化,使后续层的输入channel和输出channel的ratio发生变化,紧接在基于连接的计算块之 后的转化层(translation layer)的入度将减小或增加,从而导致模型的硬件使用率下降如图(a)->(b)的过程。
方法
作者对于连接模型,提出了一种复合模型方法,在考虑计算模块深度因子缩放的同时也考虑过渡层宽度因子做同等量的变化
当对连接结构的网络进行尺度缩放时,只缩放计算块的深度,转换层的其余部分只进行宽度的缩放
可训练的bag-of-freebies
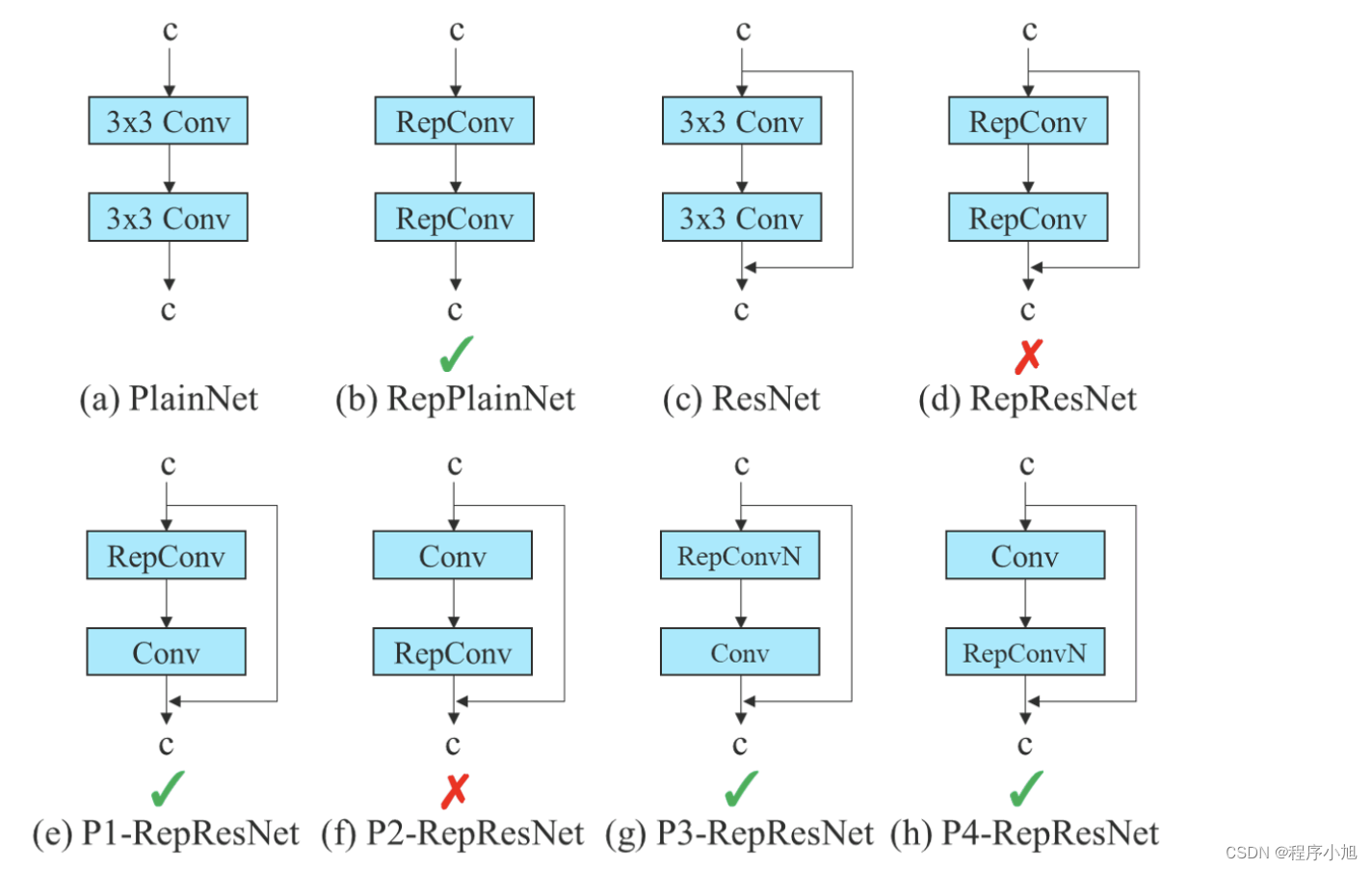
卷积重参化
RepVGG是采用了VGG风格进行搭建的,采用了重参数化技术,因此叫RepVGG。
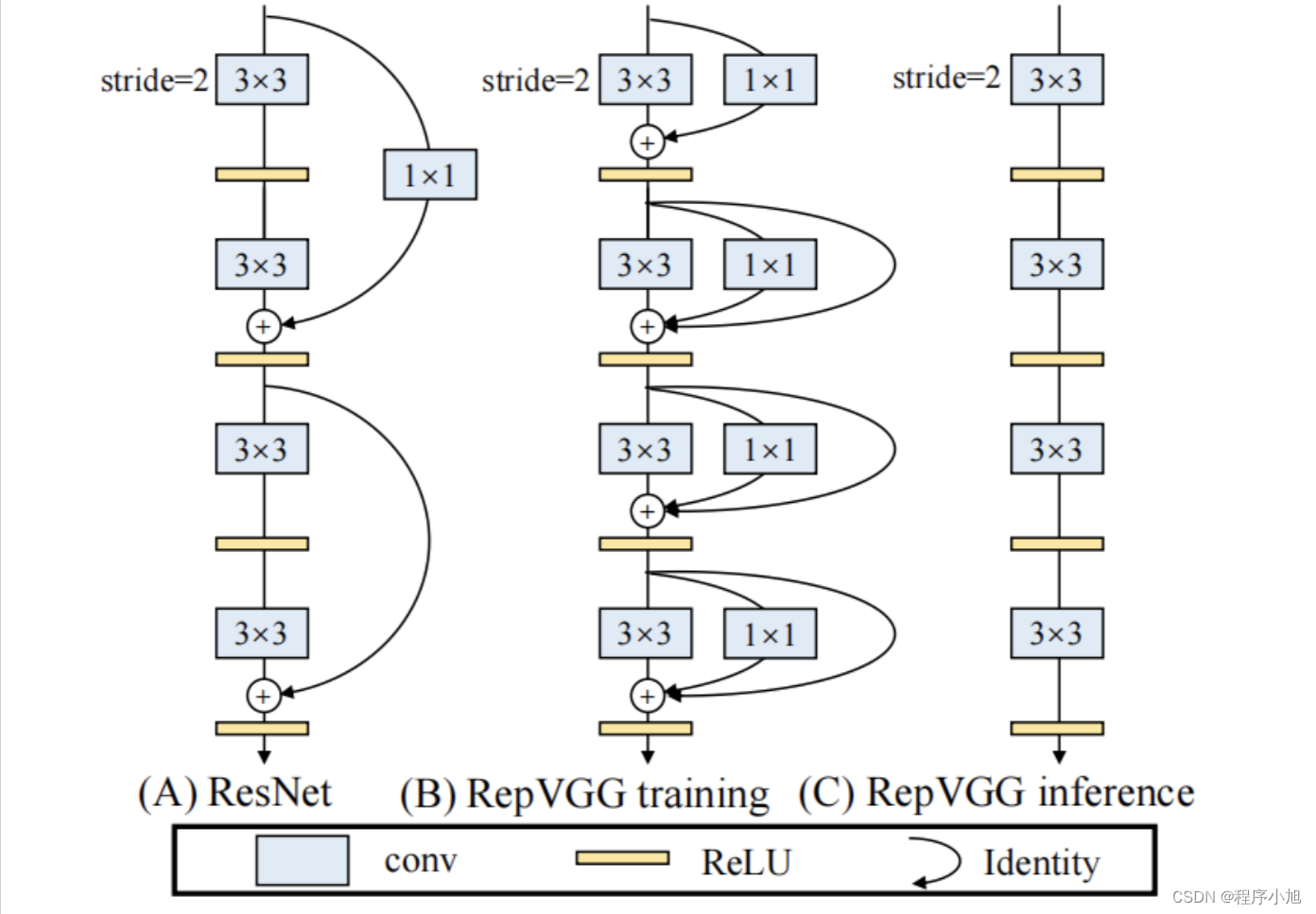
(A)是ResNet结构,最上面的部分的identity采用了1×1卷积,而RepVGG大体结构与ResNet相似.
(B)图是RepVGG训练时结构,借鉴了ResNet的residual block的结构,具体包括3×3、1×1、shortcut三个分支。
当输入输出的维度不一致,即stride=2时,则只有3×3、1×1两个分支
当输入输出的维度一致时,在后三层卷积中不仅有1×1的identity connection,还有一个无卷积的直接进行特征融合的identity connection
( C)图是RepVGG测试时结构,会把这些连接全部去掉,就变成了一个单一的VGG结构,这种操作也被称为训练与预测的解耦合.
问题引入
RepConv中带有的 identity connection破坏了ResNet中的残差和DenseNet中的concatenation,而我们知道残差和concatenation为不同的特征图提供了更多的梯度多样性,这样一来会导致精度下降。所以当一个带有残差或concatenation的卷积层被重参数的卷积所取代时,应该不存在 identity connection
方法
基于此,作者使用无identity connection的RepConv (RepConvN)来设计规划重参化卷积结构,如下图所示:
辅助训练模块
Lead head是负责最终输出的 head ;Auxiliary head是负责辅助训练的 head
那么这个标题就是在说负责辅助训练的head用粗标签,负责最终输出的head用细标签
深度监督
原文翻译:
深度监督 [38] 是一种经常用于训练深度网络的技术。 它的主要概念是在网络的中间层添加额外的辅助头,以辅助损失为指导的浅层网络权重。 即使对于 ResNet [26] 和 DenseNet [32] 等通常收敛良好的架构,深度监督 [70, 98, 67, 47, 82, 65, 86, 50] 仍然可以显着提高模型在许多任务上的性能 . 图 5 (a) 和 (b) 分别显示了“没有”和“有”深度监督的目标检测器架构。 在本文中,我们将负责最终输出的head称为lead head,用于辅助训练的head称为辅助head。
深度监督 是一种常用于训练深度网络的技术。其主要概念是在网络的中间层增加额外的Auxiliary head,以及以Auxiliary损失为导向的浅层网络权值。
下图(A)是无深度监督, (B)是有深度监督
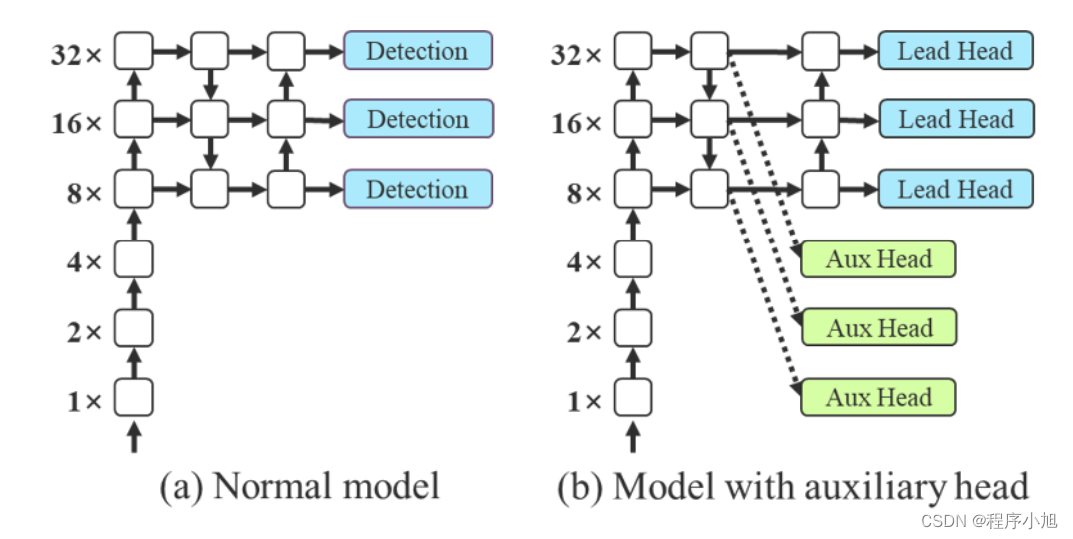
将负责最终输出的head为Lead head,将用于辅助训练的head称为Auxiliary head。
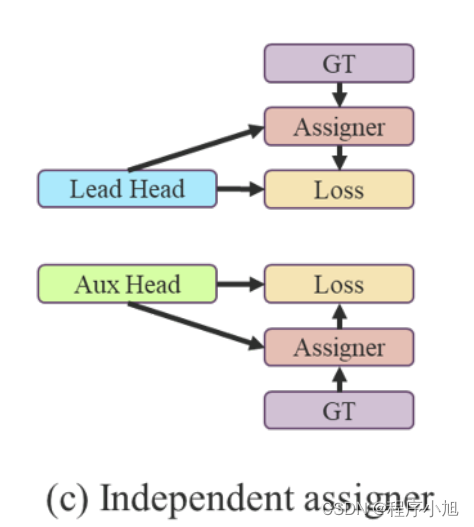
Label assigner— 标签分配器
以前方法
过去,在深度网络的训练中,标签分配通常直接参考GT,并根据给定的规则生成hard label
本文方法
作者提出一个“label assigner(标签分配器)” 机制,该机制将网络预测结果与GT一起考虑,然后分配soft label
关于hard label和soft label:
hard label:有些论文中也称为hard target ,其实这也是借鉴了知识蒸馏的思想,hard字面意思上就可以看出比较强硬,是就是,不是就是不是,标签形式:(1,2,3…)或(0,1,0,0…)【举个栗子:要么是猫要么是狗】
soft label:soft是以概率的形式来表示。可理解为对标签的平滑也即软化,比如像[0.6,0.4],【举个栗子:有60%的概率是猫, 40%的概率是狗】,就好像不会给你非常明确的回答。
现在比较流行的结构中,经常会将网络输出的数据分布通过一定的优化方法等与GT进行匹配生成soft label(其实我们熟悉的经过softmax的或者sigmod输出就是一种soft label)。
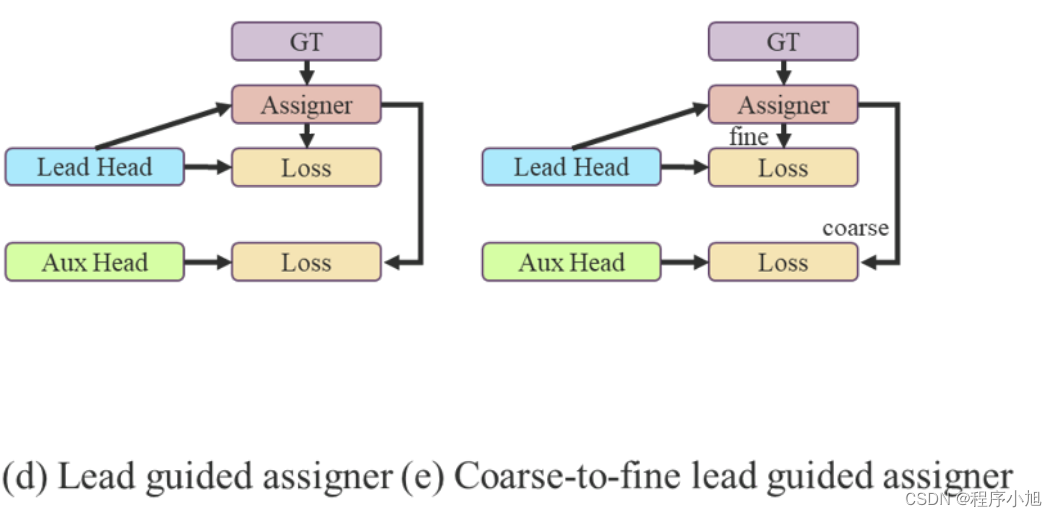
先导头导向标签分配器:


















 4795
4795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











