







百日筑基篇——回归分析(R语言初识十)
前言
本章着重介绍如何进行线性回归以及多元线性回归,并根据回归结果判断线性模型的可行性,经过调换,取得最佳线性模型。
一、回归分析是什么?
回归,通常指用一个或多个预测变量,也称自变量或者解释变量,来预测响应变量,也称因变量、标效变量或者结果变量的方法。
回归分析主要用于分析自变量对因变量的影响
二、线性回归
最简单的线性回归:普通最小二乘回归法(OLS),原理就是找到一条直线(拟合直线),使残差平方和最小.
> women
height weight
1 58 115
2 59 117
3 60 120
4 61 123
5 62 126
6 63 129
7 64 132
8 65 135
9 66 139
10 67 142
11 68 146
12 69 150
13 70 154
14 71 159
15 72 164
plot(women)
?lm
fit <- lm(weight~height,data=women)
> summary(fit) #回归结果,可以使用summary()函数查看详细的分析结果
Call:
lm(formula = weight ~ height, data = women)
Residuals:
Min 1Q Median 3Q Max
-1.7333 -1.1333 -0.3833 0.7417 3.1167
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -87.51667 5.93694 -14.74 1.71e-09 ***
height 3.45000 0.09114 37.85 1.09e-14 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.525 on 13 degrees of freedom
Multiple R-squared: 0.991, Adjusted R-squared: 0.9903
F-statistic: 1433 on 1 and 13 DF, p-value: 1.091e-14
- call这一列,是列出使用的回归的公式.
- Residuals(残差),真实值与预测值之间的差。残差给出了五个值,最小值、最大值、中位值、四分之一的值、四分之三的值,这四个值的绝对值越小,说明预测模型越精确。
- Coefficients:系数项,intercept:截距项(当x等于0时,与y轴的相交点)
- Estimate是项系数的值(故该线性回归公式为y=3.45x-87.5,
- pr就是pvalue,是假设x与y不相关时候的概率,这个值也是小于0.05比较好
- residual standard error 残差标准误,表示残差的标准误差,这个也是越小越好
- Multiple R-squared: 0.991, Adjusted R-squared: 0.9903
这两个值称为R方判定系数,是衡量模型拟合质量的指标,它是表示回归模型所能解释的响应变量的方差比例. - F-statistic(F统计量),这个值说明模型是否显著,也是用pvalue来衡量,也是值越小越好.
反正总之,看待线性回归结果时,一般是先看pvalue值,如果它不小于0.05,那这个线性回归模型就没什么价值,要重新拟合。
如果小于0.05,就再看R方差,看模型能解释多少变量。
> coefficients(fit)
(Intercept) height
-87.51667 3.45000
confint(fit,level= 0.95)#提供模型参数的置信区间(默认95%)
fitted(fit)# 列出拟合模型的预测值
residuals(fit)#列出拟合模型的残差值
women1 <- women
predict(fit,women1) #用拟合模型对新的数据集预测响应变量值
plot(fit)#会生成四幅图:残差拟合图、正态分布qq图、大小位置图以及残差影响图
三、多元线性回归
当预测变量不止一个时,简单线性回归就变成了多元线性回归,相当于求解多元方程,而且和方程式求解不同的是,这些变量的权重还不一样,有些大 ,有些小,有些或者是没有多大影响,
3.1
#一般拟合曲线很少是直线,大部分都是曲线,也就是多项式的回归
fit2 <- lm(weight~height+I(height^2),data=women)#将体重作为因变量,身高与身高的平方作为自变量
summary(fit2)
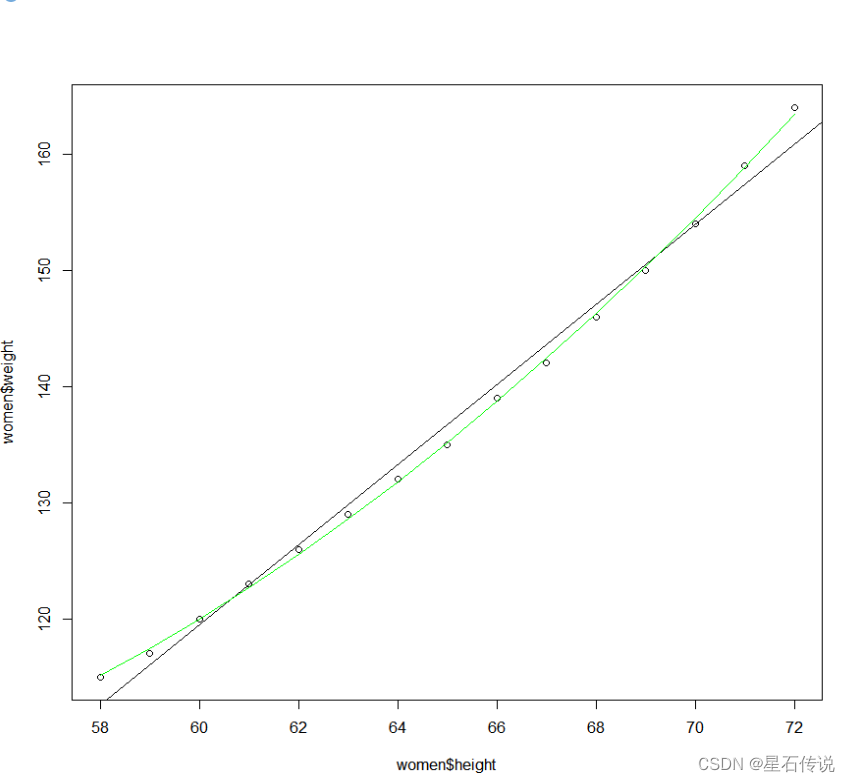
plot(women$height,women$weight)
abline(fit)
lines(women$height,fitted(fit2),col="green")
#使用lines()函数,这个函数能把点连成线,横坐标是身高数据,纵坐标是根据拟合模型的得出的预测值,
> fitted(fit2)
1 2 3 4 5 6 7 8 9
115.1029 117.4731 120.0094 122.7118 125.5804 128.6151 131.8159 135.1828 138.7159
10 11 12 13 14 15
142.4151 146.2804 150.3118 154.5094 158.8731 163.4029
3.2
state.x77
states <- as.data.frame(state.x77[,c(5,1,3,2,7)])
fit <- lm(Murder~Population+Illiteracy+Income+Frost,data=states)
summary(fit)
> coefficients(fit)
(Intercept) Population Illiteracy Income Frost
1.2345634112 0.0002236754 4.1428365903 0.0000644247 0.0005813055
#由此可知,Illiteracy的回归系数为4.143,表示在控制Population 、Income、 Frost这三个变量不变的情况下,文盲率上升1%,谋杀率上升4.143%
#在很多研究中,变量会有交互项,也就是变量相互之间并不是独立的
mtcars
fit <- lm(mpg~hp+wt+hp:wt,data=mtcars)#拟合一下mtcars数据集中,每加仑汽油行驶里程数(mpg)变量与马力(hp)以及车重(wt)之间的关系
> summary(fit)
Call:
lm(formula = mpg ~ hp + wt + hp:wt, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.0632 -1.6491 -0.7362 1.4211 4.5513
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 49.80842 3.60516 13.816 5.01e-14 ***
hp -0.12010 0.02470 -4.863 4.04e-05 ***
wt -8.21662 1.26971 -6.471 5.20e-07 ***
hp:wt 0.02785 0.00742 3.753 0.000811 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.153 on 28 degrees of freedom
Multiple R-squared: 0.8848, Adjusted R-squared: 0.8724
F-statistic: 71.66 on 3 and 28 DF, p-value: 2.981e-13
从结果中可以看见,车重与马力的交互项是非常显著的,这就说明响应变量mpg与其中一个预测变量的关系依赖于另一个预测变量的水平。
3.3
如果存在多个变量,就需要考虑变量之间的相互影响和回归时的组合关系,也就是如何从众多可能的模型中选择最佳的模型呢?
我们可以使用AIC()函数来比较模型
AIC()函数是赤池信息准则的计算方法,这个准则考虑了模型统计拟合度以及用来拟合的参数数目,用于在估计多个模型中选择最佳模型
赤池信息准则的计算公式为 AIC = -2 * log(L) + 2 * k,其中 L 表示模型的最大似然估计值,k 表示模型中的参数数量。AIC 的值越小,表示模型的拟合度越好且考虑到模型参数的数量。
fit1 <- lm(Murder~Population+Illiteracy+Income+Frost,data=states)
fit2 <- lm(Murder~Population+Illiteracy,data=states)
> AIC(fit1,fit2)
df AIC
fit1 6 241.6429
fit2 4 237.6565
#结果显示,fit2的拟合度更好
3.4
但是如果变量数过多,那么组合起来的拟合模型数将是巨大的,再用AIC()两两比较就不太可行了,
这个时候,对于变量的选择可以使用逐步回归法和全子集回归法。
逐步回归法中,模型会依次添加或者删除一个变量直到达到某个节点为止,这个节点就是继续添加或者删除变量,模型不再继续变化。如果每次是增加变量,那么就是向前逐步回归,如果每次是删除变量,那么就是向后逐步回归
全子集回归法是取所有可能的模型,然后从中计算出最佳的模型,很显然全子集回归法要比逐步回归法要好,因为会检测到所有的模型,把可能的模型都纳入考虑之中,但是缺点就是如果变量数太多,会涉及到大量的计算,运算会比较慢。
#MASS包中的stepAIC()函数可以进行逐步回归法的计算
library(MASS)
states%>% class()
fit1 <- lm(Murder~Population+Illiteracy+Income+Frost,data=states)
stepAIC(fit1,direction = "backward")
#Leaps包中的regsubsets()函数可以进行全子集回归的计算
library(leaps)
?regsubsets()
四、回归诊断
找到回归模型之后,我们仍需要解决以下的问题:
- 这个模型是否是最佳的模型?
- 模型最大程度满足OLS模型的统计假设?
- 模型是否经得起更多数据的检验?
- 如果拟合出来的模型指标不好,该如何继续下去?
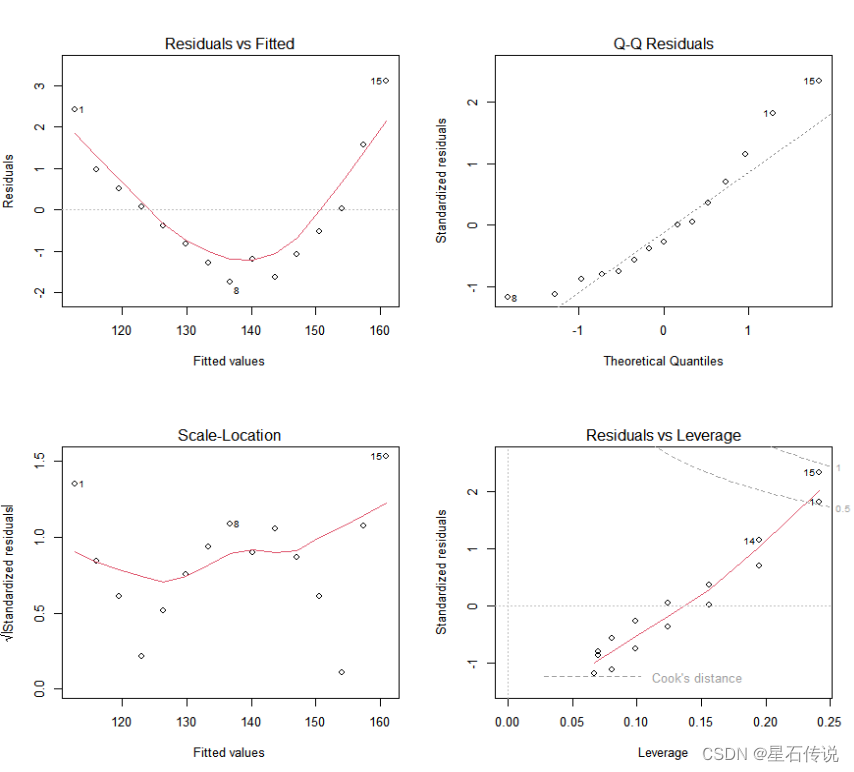
除了利用summary()函数统计出来的各个指标进行检验,还可以用plot()函数进行绘图,可以生成评价拟合模型的四幅图
opar <- par(no.readonly = TRUE)
fit <- lm(weight~height,data=women)
summary(fit)
par(mfrow=c(2,2))
plot(fit)
-
第一幅图是残差与拟合的图,这幅图用来表示因变量与自变量是否呈线性关系,图中的点是残差值的分布,线为拟合曲线。如果图中是一个曲线的分布,说明可能存在二次项的分布
-
第二幅图是R中比较常见的qq图,QQ图用来描述正态性,如果数据呈正态分布,那么在QQ图中就是一条直线
-
第三幅图是位置与尺寸图,用来描述同方差性,如果满足不变方差的假设,那么图中水平线周围的点应该是随机分布的
-
第四幅图是残差与杠杆图,提供了对单个数据值的观测,从图中可以看到哪些点偏差较远,可以用来鉴别离群点、高杠杆点和强影响点
#但是这四幅图没办法说明数据是否具有独立性
#只能从收集的数据中验证,要判断收集的数据是否独立,我们可以拟合函数再加一个二次项,再绘制一次图看一下。
fit2 <- lm(weight ~ height+I(height^2),data = women)
opar <- par(no.readonly = TRUE)
par(mfrow=c(2,2))
plot(fit2)
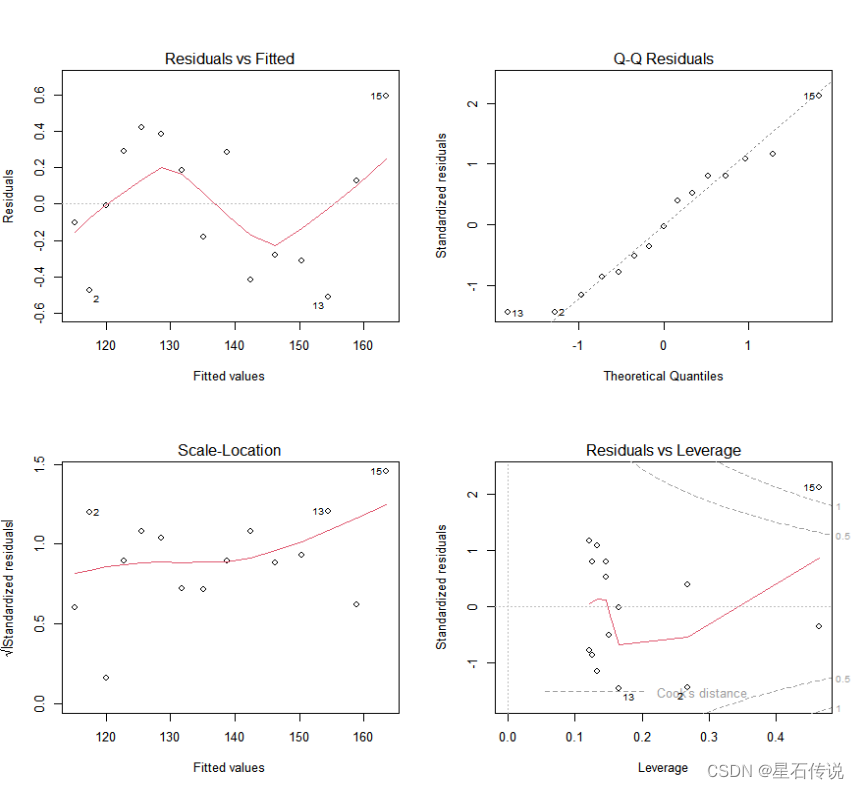
如果数据具有独立性,拟合的二次函数应该能够更好地描述数据的变化趋势。通过观察重新绘制的图形,我们可以更好地评估数据是否符合独立性的假设。
总结
回归模型的得到要经过多次的回归诊断,根据回归结果以及图表可判断回归模型的可行性,再经过调整,以便取得最佳回归模型。
耳得之而为声,目遇之而成色。
–2023-7-29 筑基篇


















 7369
7369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











