









前言:
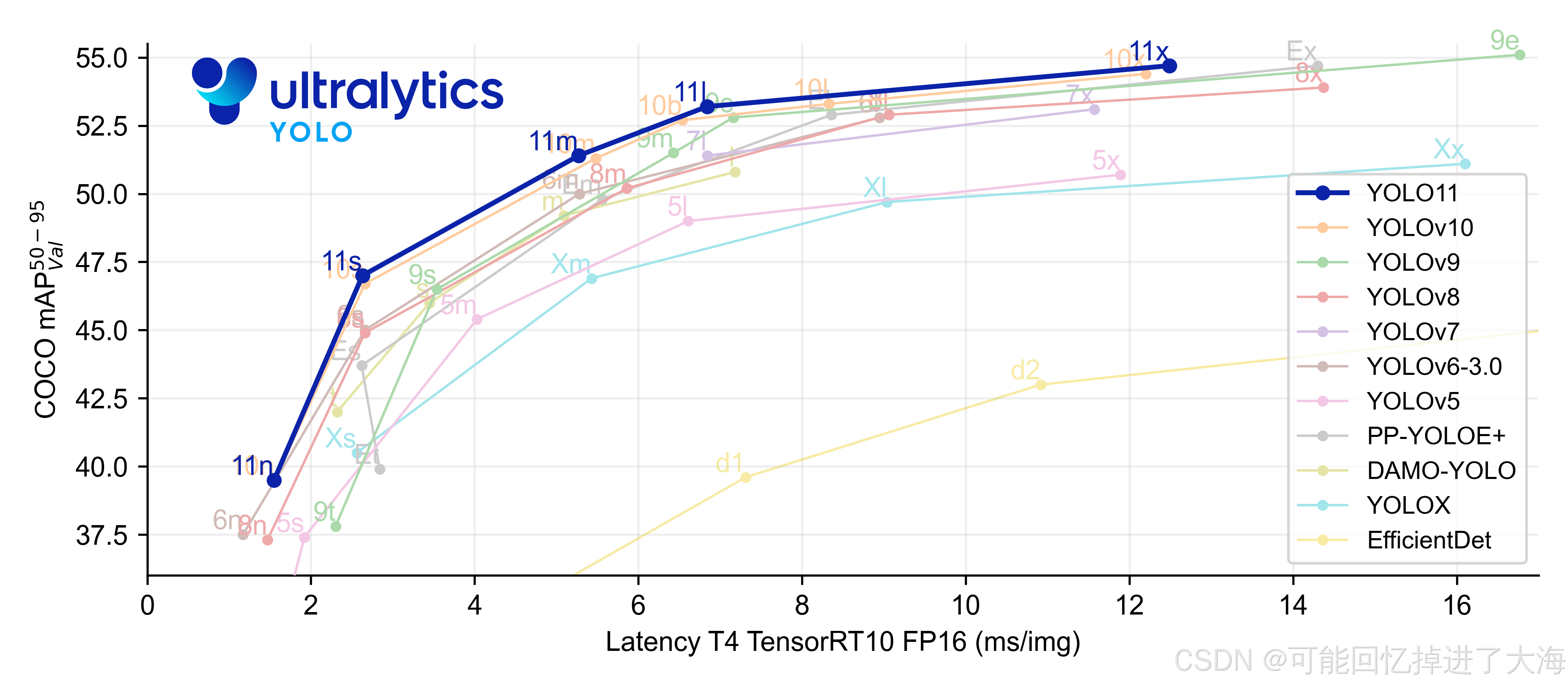
作为使用者来说,实际上YOLO系列目标检测模型性能迭代变化不大,特别是自v8以来,v9、v10、v11每代综合性能都略有提升,下面是官方发布的历代YOLO模型对比分析图:
总的来说,从Ultralytics官方的介绍来看,最新的YOLO11模型可在检测、分割、姿势估计、跟踪和分类等多项任务中提供最先进的 (SOTA) 性能,充分利用各种人工智能应用和领域的能力。
目前YOLO11没有发表论文,能参考的只有官方文档:
官方文档:YOLO11官方文档
https://docs.ultralytics.com/models/yolo11/
另外,如果你想更加深入的了解YOLO11,可以参考这篇文章:
一篇文章快速认识YOLO11 | 关键改进点 | 安装使用 | 模型训练和推理
这篇文章我将会带你手把手跑通YOLO11,有关在自有数据集进行模型训练的文章我会在文末给出:
一、clone代码与基础配置(下载源码到本地)
1.1 项目地址:GitHub - ultralytics/ultralytics: Ultralytics YOLO11 🚀

1.2 选择Download ZIP或者Clone都可以
clone:
1.3 如果不能科学上网,也可以通过我的百度网盘获取文件:YOLO11源码与weights权重
链接:https://pan.baidu.com/s/13i_w3GyuX_6DVQac4B_YZw 提取码:8888https://pan.baidu.com/s/13i_w3GyuX_6DVQac4B_YZw%C2%A0
注意:因为本文只目的只是为了快速跑通YOLO11,为了减少下载量且提高下载速度,所以weights文件夹里面只有YOLO11n系列权重,其中包括:
| yolo11n | 目标检测(base) |
| yolo11n-cls | 图像分类(Classify) |
| yolo11n-obb | 定向对象检测(Oriented Bounding Box) |
| yolo11n-pose | 姿态估计(Pose) |
| yolo11n-seg | 实例分割(Segment) |
接下来就是解压、使用IDE编辑器打开、创建一个虚拟环境(如果没有的话)、下载依赖库
1.4 打开 ultralytics-main\pyproject.toml 可以看到,python解释器版本要>=3.8:
[project] name = "ultralytics" dynamic = ["version"] description = "Ultralytics YOLO 🚀 for SOTA object detection, multi-object tracking, instance segmentation, pose estimation and image classification." readme = "README.md" requires-python = ">=3.8"
1.5 下载官方库:
pip install ultralytics
1.6 下载必要的外部库(IDE应该会提示自动下载):
# Required dependencies dependencies = [ "numpy>=1.23.0", "numpy<2.0.0; sys_platform == 'darwin'", # macOS OpenVINO errors https://github.com/ultralytics/ultralytics/pull/17221 "matplotlib>=3.3.0", "opencv-python>=4.6.0", "pillow>=7.1.2", "pyyaml>=5.3.1", "requests>=2.23.0", "scipy>=1.4.1", "torch>=1.8.0", "torch>=1.8.0,!=2.4.0; sys_platform == 'win32'", # Windows CPU errors w/ 2.4.0 https://github.com/ultralytics/ultralytics/issues/15049 "torchvision>=0.9.0", "tqdm>=4.64.0", # progress bars "psutil", # system utilization "py-cpuinfo", # display CPU info "pandas>=1.1.4", "seaborn>=0.11.0", # plotting "ultralytics-thop>=2.0.0", # FLOPs computation https://github.com/ultralytics/thop ]
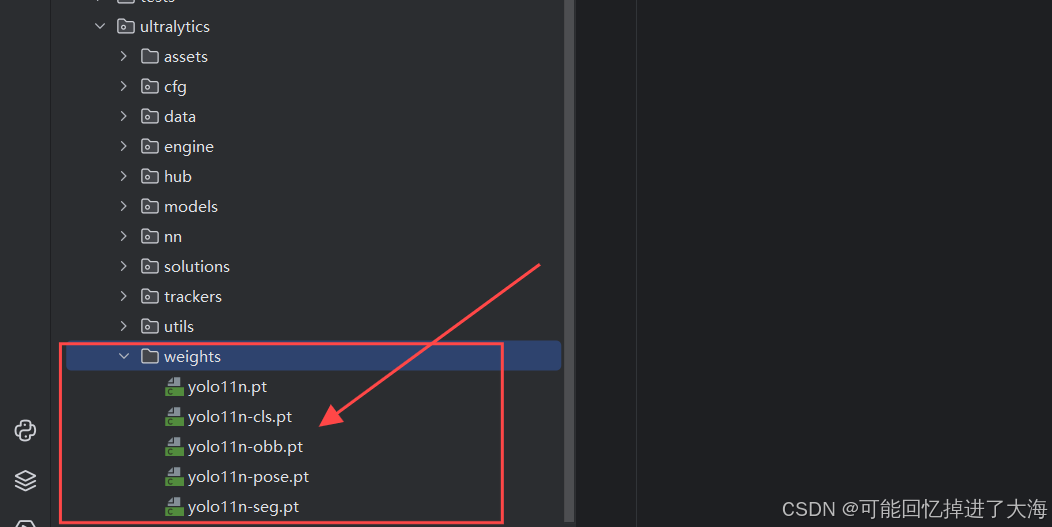
1.7 在ultralytics-main\ultralytics目录下新建weights目录,把下载的模型权重复制进去:
1.8 在ultralytics-main\ultralytics目录下新建predict.py文件
 接下来就可以写代码使用模型进行预测了,实际上YOLO11的预测代码、训练代码都很简单,几行就可以实现
接下来就可以写代码使用模型进行预测了,实际上YOLO11的预测代码、训练代码都很简单,几行就可以实现
二、使用代码进行图片、视频预测(目标检测、实例分割、姿态估计)
2.1 目标检测_图片:
# 导包 from ultralytics import YOLO # 加载模型 model = YOLO("weights/yolo11n.pt") # 预测 results = model('assets/bus.jpg') # 括号里面是图片地址
如果需要保存结果或显示结果:
# 导包 from ultralytics import YOLO import cv2 # 加载模型 model = YOLO("weights/yolo11n.pt") # 预测 results = model('assets/bus.jpg', save=True) # 括号里面是图片地址 # 获取绘制了边界框的图像 annotated_image = results[0].plot() # 显示图像 cv2.imshow('YOLO Detect Result', annotated_image) # 按下任意键关闭窗口 cv2.waitKey(0) # 关闭所有窗口 cv2.destroyAllWindows()
运行后即可得到:
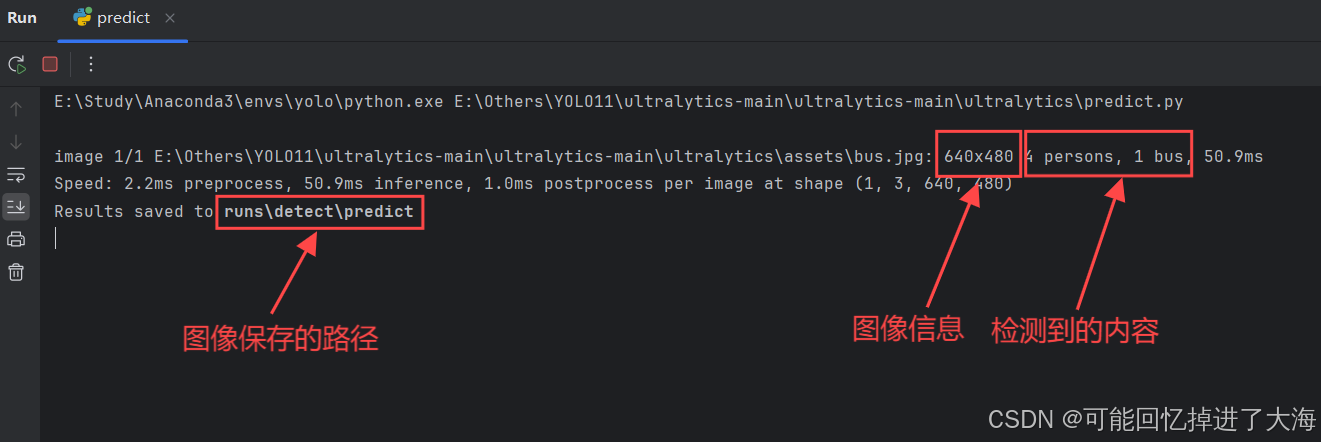
因为使用了cv2用于显示处理后的图像,所以结果不仅会保存到指定目录,也会弹窗显示出来:

如果需要对视频进行检测
在 ultralytics/assets文件夹下新建video文件夹用于保存视频数据
在 ultralytics/runs文件夹下新建detect_video文件夹用于保存输出结果
新建 ultralytics/predict_video.py
2.2 目标检测_视频:
from ultralytics import YOLO import cv2 # 1、加载YOLO模型(YOLOv5或YOLOv8的权重文件) model = YOLO("yolov8n.pt") # 使用YOLOv8的小模型。你也可以替换成YOLOv5的权重,如 "yolov5s.pt" # 2、输入视频文件路径 video_path = 'assets/video/scujj.mp4' # 3、使用OpenCV读取视频 cap = cv2.VideoCapture(video_path) # 4、获取视频的帧率和尺寸 fps = cap.get(cv2.CAP_PROP_FPS) frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 5、定义视频输出路径,保存检测结果 output_video_path = 'runs/output_video/scujj.mp4' # 设置视频编码方式(例如 mp4v 用于 .mp4 格式) fourcc = cv2.VideoWriter_fourcc(*'mp4v') out = cv2.VideoWriter(output_video_path, fourcc, fps, (frame_width, frame_height)) while cap.isOpened(): # 6、读取每一帧 ret, frame = cap.read() if not ret: # 7、如果没有读取到帧,退出循环 break # 8、使用YOLO模型进行推理 results = model(frame) # 推理每一帧 # 9、获取检测结果,并绘制边界框和标签 annotated_frame = results[0].plot() # 10、调整视频帧大小以适应窗口 resized_frame = cv2.resize(annotated_frame, (450, 800)) # 11、将处理后的帧写入到输出视频 out.write(resized_frame) # 12、实时显示结果(可在10处设置窗口大小) cv2.imshow('YOLO Detection', resized_frame) # 13、按 'q' 键退出 if cv2.waitKey(1) & 0xFF == ord('q'): break # 14、释放资源 cap.release() out.release() cv2.destroyAllWindows() print(f"检测结果已保存至: {output_video_path}")
结果如下(这里引用了四川大学锦江学院官方抖音号国庆节相关视频 ):

完整预测视频观看链接🔗:
scujj_detected-CSDN直播目标检测https://live.csdn.net/v/435159
以上就是目标检测的全部内容,由于篇幅,接下来只简单演示实例分割、姿态估计。
图像分类、定向对象检测就自行测试,都几乎是一样的。
| yolo11n | 目标检测(base) |
| yolo11n-cls | 图像分类(Classify) |
| yolo11n-obb | 定向对象检测(Oriented Bounding Box) |
| yolo11n-pose | 姿态估计(Pose) |
| yolo11n-seg | 实例分割(Segment) |
2.3 实例分割_图片(只是把权重替换成了yolo11n-seg.pt):
# 导包 from ultralytics import YOLO import cv2 # 加载模型 model = YOLO("weights/yolo11n-seg.pt") # 预测 results = model('assets/bus.jpg', save=True) # 括号里面是图片地址 # 获取绘制了边界框的图像 annotated_image = results[0].plot() # results[0].plot() 返回带有检测框的图像(NumPy 数组) # 显示图像 cv2.imshow('YOLO Detect Result', annotated_image) # 显示带有检测框的图像 # 按下任意键关闭窗口 cv2.waitKey(0) cv2.destroyAllWindows() # 关闭所有窗口
结果如下:

2.4 姿态估计(只是把权重替换成了yolo11n-pose.pt):
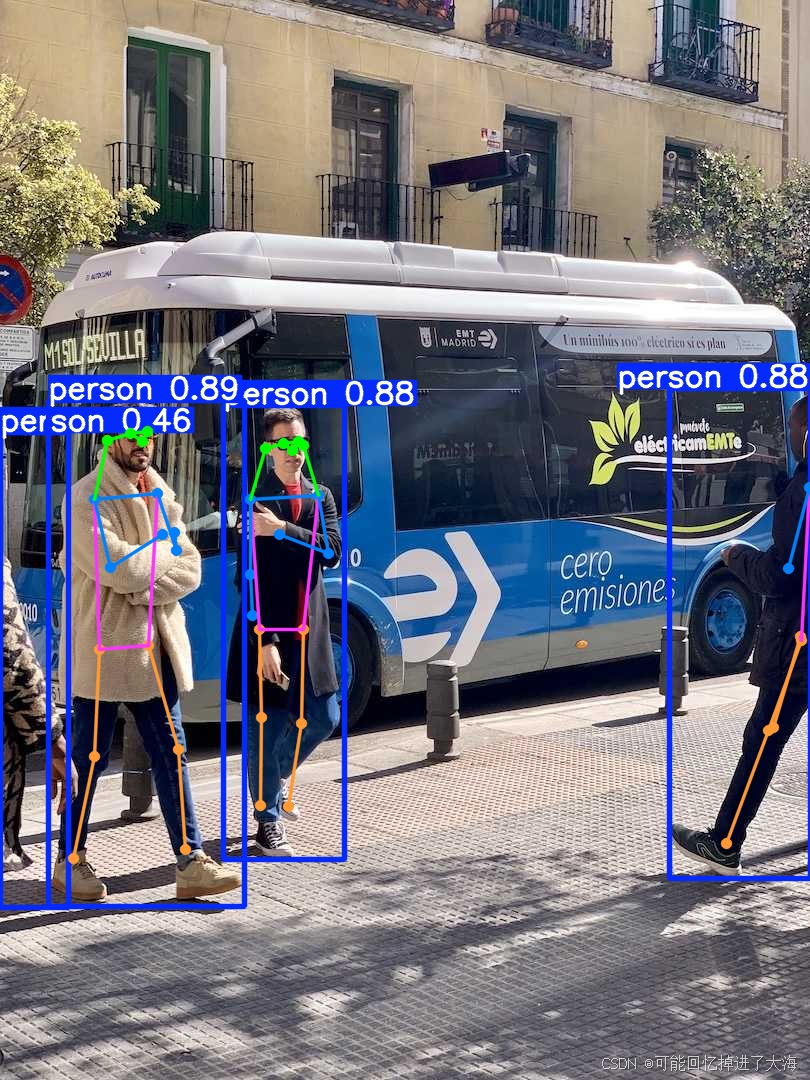
由此可见,使用YOLO11进行预测是非常简便且简单的,代码几乎一样,只是更改了模型权重(weights)文件,对应关系如上表。如果你需要对视频进行实例分割、姿态估计等等,也只是需要把对应的权重从目标检测修改过来即可。
如果你对YOLO11的模型训练感兴趣,可以参考我的另一篇文章
如果你对YOLO的单目深度估计感兴趣,可以参考我的另一篇文章:
【YOLO简单测距】单目测距——基于YOLOv5的单目深度估计算法的实现![]() https://blog.csdn.net/2301_78753314/article/details/140220033
https://blog.csdn.net/2301_78753314/article/details/140220033
如果你对YOLO11的安卓部署,可以参考我的另一篇文章:
【YOLO11安卓部署】10分钟快速高效的把YOLO11部署到安卓端![]() https://blog.csdn.net/2301_78753314/article/details/143966676
https://blog.csdn.net/2301_78753314/article/details/143966676

















 9469
9469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









