







下面详细介绍YOLO配置、推理、训练相关步骤
简介
YOLO(ultralytics)是一种实时目标检测算法,通过将目标检测任务转化为回归问题,能够在一次前向传播中同时预测图像中的所有目标类别和位置,实现快速而准确的目标检测。
下面我将详细阐述如何从下载代码,推理图片到训练模型。
1.下载代码
所有命令都是基于python环境下的,你首先需要确保你已经安装了python!
你可以通过命令:
python --version
来检验你安装的python版本。
如果你仅仅只需要使用它的推理功能而不需要训练模型,你可以pip直接下载ultralytics 的包从而不需要下载代码,但是我建议下载代码并从代码安装ultralytics
两种下载方式:
如果你安装了git:
git clone https://github.com/ultralytics/ultralytics.git
下载压缩包:
进入官网https://github.com/ultralytics/ultralytics (能进但有点慢)
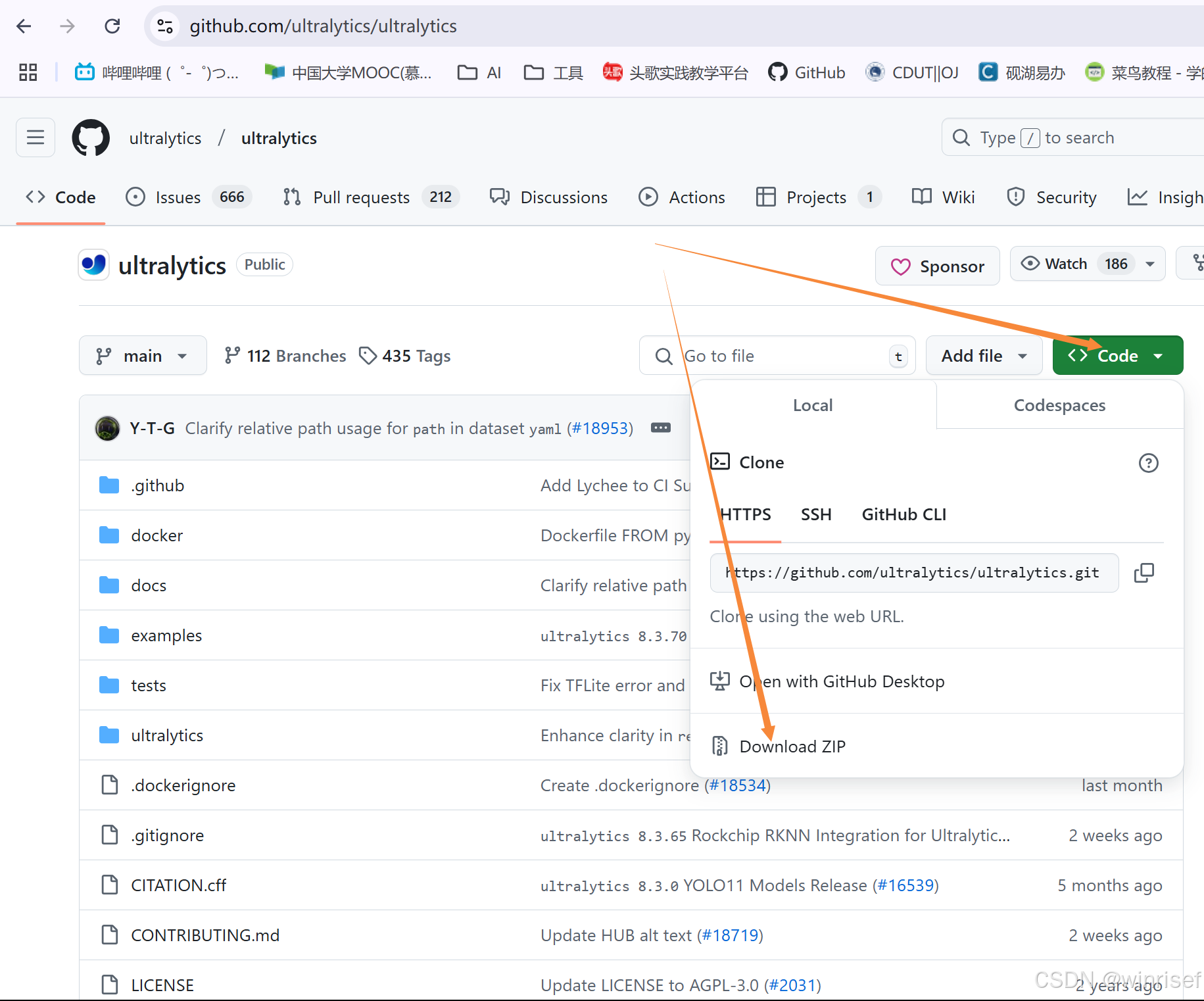
然后解压进入文件夹。
2.创建虚拟环境(下方所有代码使用终端cmd)
创建虚拟环境需要conda,你可以查看这篇文章从0到1的conda环境变量配置下载配置conda环境。
2.1创建并进入一个python3.10的虚拟环境
conda create --name YOLO11 python=3.10 //创建环境
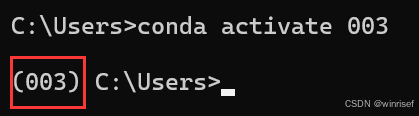
conda activate YOLO11 //进入环境
进入环境后左边有环境名称,比如我的环境名称为003:
2.2安装ultralytics
进入YOLO的文件夹:
cd E:\<你的路径>\ultralytics-main
pip install -e .
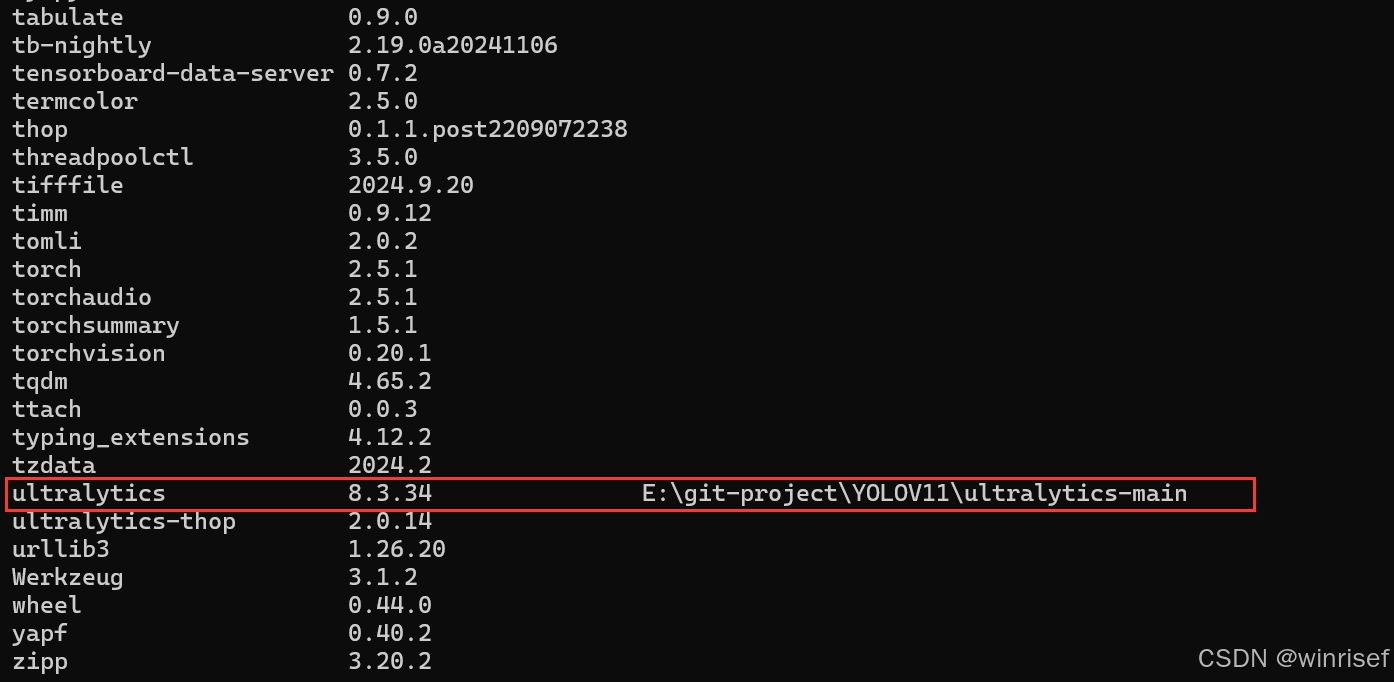
这段命令会安装你下载的ultralytics,安装完成后你就会发现包会有一个路径,就表示安装成功了:
pip list //查看安装包
3.安装pytorch
3.1查看显卡支持
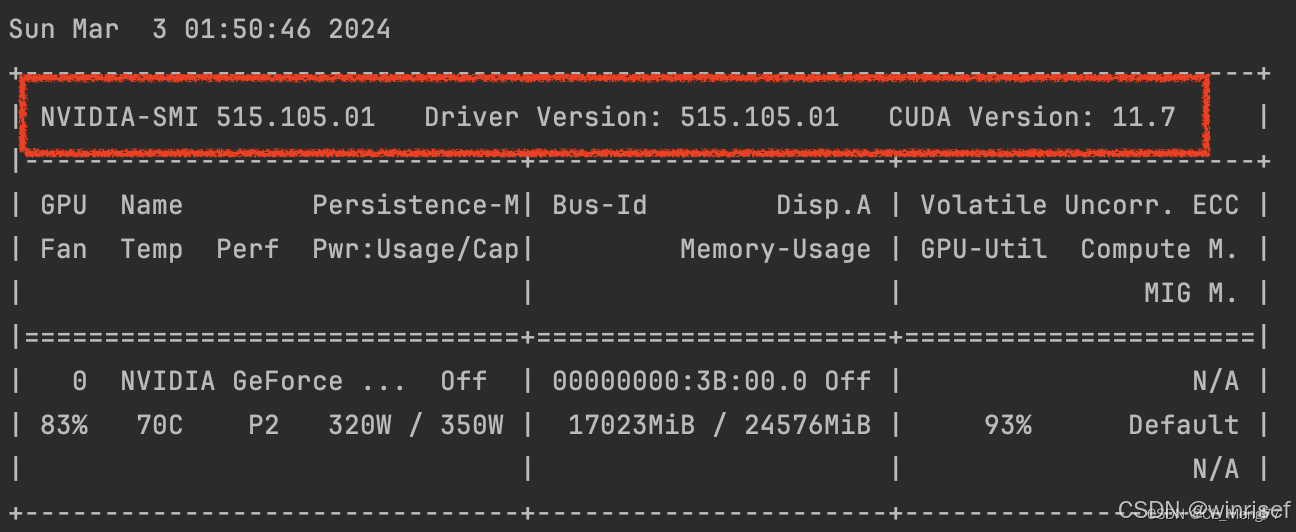
如果有nvidia显卡,可以查看支持的CUDA:
CUDA Version是驱动支持的最高版本
nvidia-smi
3.2进入pytorch官网查看支持版本
例如如果你的cuda version是12.8,就可以安装12.6的torch,如果驱动太旧,可以更新驱动安装,建议安装最新且性能更优。
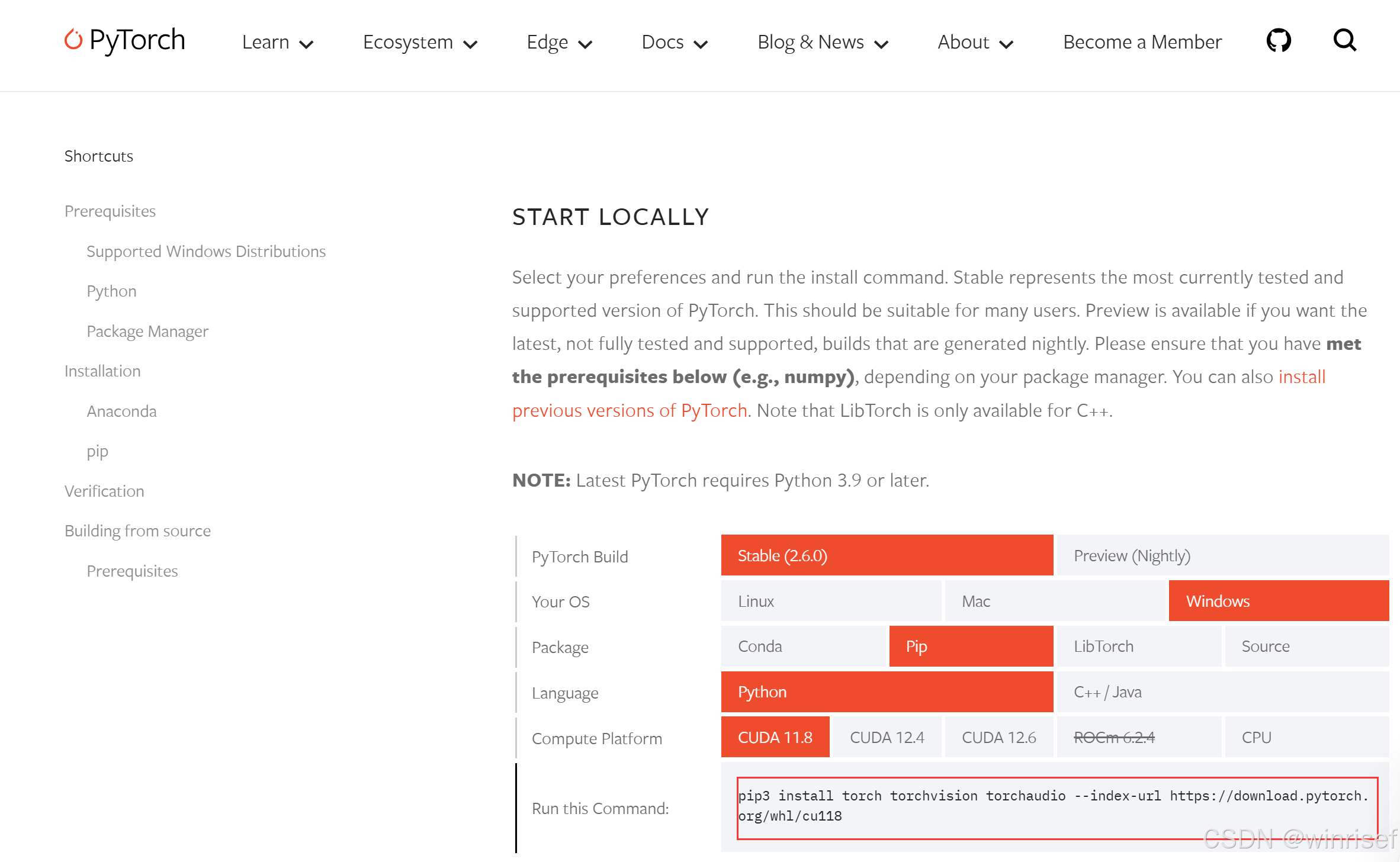
3.3选择合适的版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 //cuda11.8
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124 //cuda12.4
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126 //cuda12.6
如果下载慢可以用下面的国内源:
pip3 install torch torchvision torchaudio --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple --find-links https://download.pytorch.org/whl/cu126 //cuda12.6
pip3 install torch torchvision torchaudio --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple --find-links https://download.pytorch.org/whl/cu118 //cuda11.8
pip3 install torch torchvision torchaudio --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple --find-links https://download.pytorch.org/whl/cu124 //cuda12.4
如果只是CPU,不使用显卡:
pip3 install torch torchvision torchaudio
安装完成后可以进行验证
4.验证,推理
创建一个python文件进行推理:
from ultralytics import YOLO
import os
import torch
from pathlib import Path
def detect_images():
# ======================= 配置区 =======================
# 模型配置
model_config = {
'model_path': r'E:\git-project\YOLOV11\ultralytics-main\weights\yolo11l.pt', # 本地模型路径
'download_url':'https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11l.pt' # 如果没有模型文件可在此处下载URL
}
# 路径配置
path_config = {
'input_folder': r'E:\git-project\YOLOV11\ultralytics-main\picture',
'output_folder': r'E:\git-project\YOLOV11\ultralytics-main\predict',
'auto_create_dir': True # 自动创建输出目录
}
# 推理参数
predict_config = {
'conf_thres': 0.25, # 置信度阈值
'iou_thres': 0.45, # IoU阈值
'imgsz': 640, # 输入分辨率
'line_width': 2, # 检测框线宽
'device': 'cuda:0' if torch.cuda.is_available() else 'cpu' # 自动选择设备
}
# ====================== 配置结束 ======================
try:
# 验证输入目录
if not Path(path_config['input_folder']).exists():
raise FileNotFoundError(f"输入目录不存在: {path_config['input_folder']}")
# 自动创建输出目录
if path_config['auto_create_dir']:
Path(path_config['output_folder']).mkdir(parents=True, exist_ok=True)
# 加载模型(带异常捕获)
if not Path(model_config['model_path']).exists():
if model_config['download_url']:
print("开始下载模型...")
YOLO(model_config['download_url']).download(model_config['model_path'])
else:
raise FileNotFoundError(f"模型文件不存在: {model_config['model_path']}")
# 初始化模型
model = YOLO(model_config['model_path']).to(predict_config['device'])
print(f"✅ 模型加载成功 | 设备: {predict_config['device'].upper()}")
# 执行推理
results = model.predict(
source=path_config['input_folder'],
project=path_config['output_folder'],
name="exp",
save=True,
conf=predict_config['conf_thres'],
iou=predict_config['iou_thres'],
imgsz=predict_config['imgsz'],
line_width=predict_config['line_width'],
show_labels=True,
show_conf=True
)
# 统计信息
success_count = len(results)
save_dir = Path(results[0].save_dir) if success_count > 0 else None
print(f"\n🔍 推理完成 | 处理图片: {success_count} 张")
print(f"📁 结果目录: {save_dir.resolve() if save_dir else '无'}")
# 显示首张结果(可选)
if success_count > 0:
results[0].show()
except Exception as e:
print(f"\n❌ 发生错误: {str(e)}")
print("问题排查建议:")
print("1. 检查模型文件路径是否正确")
print("2. 确认图片目录包含支持的格式(jpg/png等)")
print("3. 查看CUDA是否可用(如需GPU加速)")
print("4. 确保输出目录有写入权限")
if __name__ == "__main__":
detect_images()
注意更改路径为你安装目录model_path(模型路径),input_folder(输入图片文件夹,把图片放入文件夹推理文件夹所有图片),output_folder(输出图片文件夹),下载权重文件可能需要网络需求。
对于YOLO11的权重文件我已上传资源,可以自行下载https://download.csdn.net/download/2301_79442295/90333333
验证如图:

证明安装正确,可以推理。
5.训练
YOLO11虽然有已经训练好的模型,但是YOLO 的官方预训练模型(如 COCO 数据集训练的模型)只能识别通用类别(如人、车、动物等)。如果你的任务需要检测特殊物体(如工业零件、医疗图像、特定商品等),必须训练自己的模型,才能实现检测效果。
训练建议: 想要训练模型,显卡是必不可少的,如果使用CPU进行训练,显卡一个小时的训练CPU可能需要10个小时;同时训练需要数据集,YOLO系列采用的是txt文本数据集,你可以从数据集网站上下载(例如我常用的workflows数据集https://app.roboflow.com/ ,这可能需要点魔法),也可以通过标注网站对自己的图片进行标注。下面我以workflows上下载的数据集为例进行训练。
5.1训练集
训练集结构如下
├── 训练集名称
│ ├── train
│ │ ├── images
│ │ └── labels
│ ├── val
│ │ ├── images
│ │ └── labels
│ └── test
│ ├── images
│ └── labels
主文件夹下有三个文件(train,val,test),每个文件夹下有images和labels
特别注意:images中的每张图片名称要与labels每个标注相对应,例如cat1.png的标注名称必须是cat1.txt,不然无法匹配,建议按照train8:val1:test1分配图片。
特别注意:标注文件txt中如果有标注多个种类一定要与下方data.yaml文件中names相对应,如果是下载的训练集可以忽略,如果是自己标注需要顺序匹配,例如假如names: [‘cat’, ‘dog’]有两类那么图片中cat的类别为0,dog类别为1,框cat的为0,框dog的为1,注意和data.yaml文件names的顺序一致就行
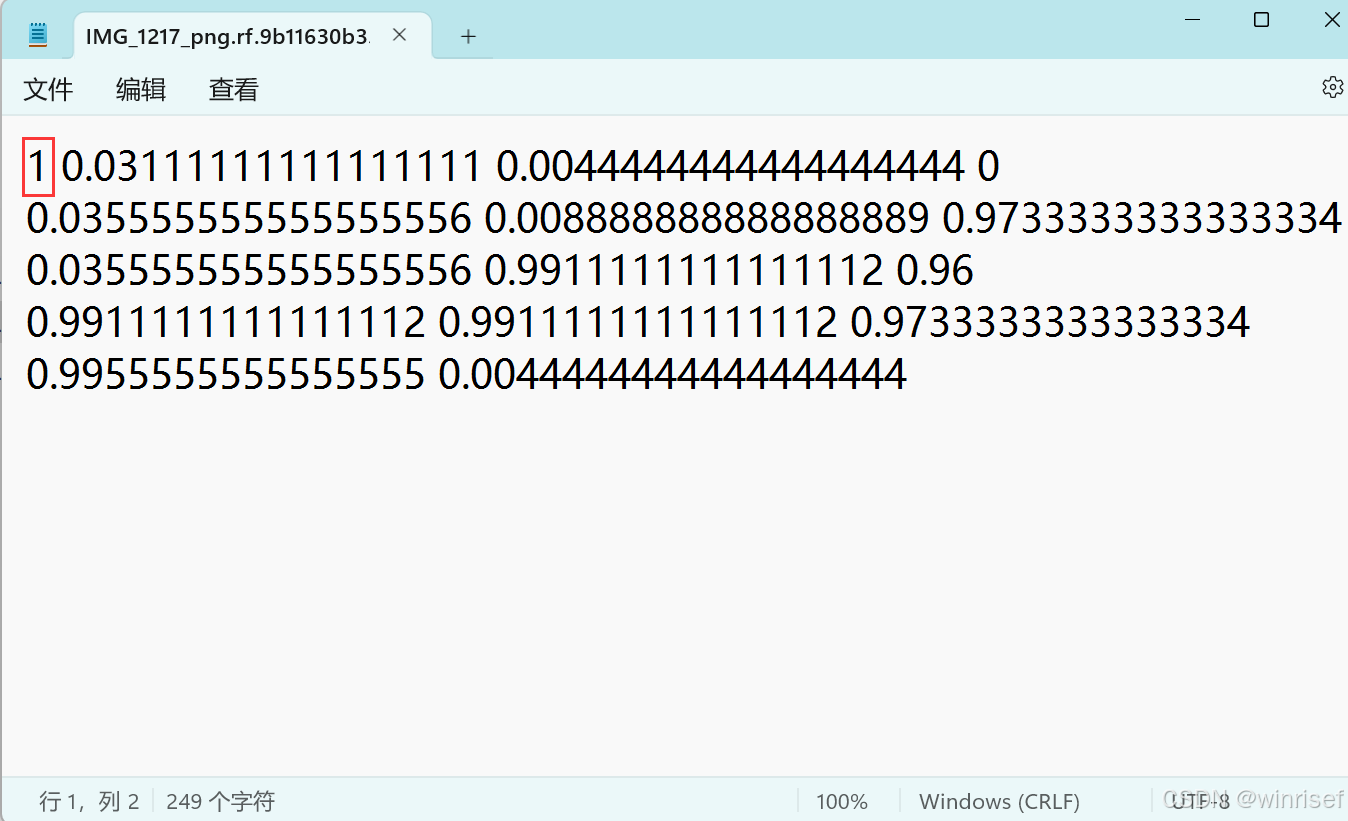
比如下面标注表示图片有一个dog
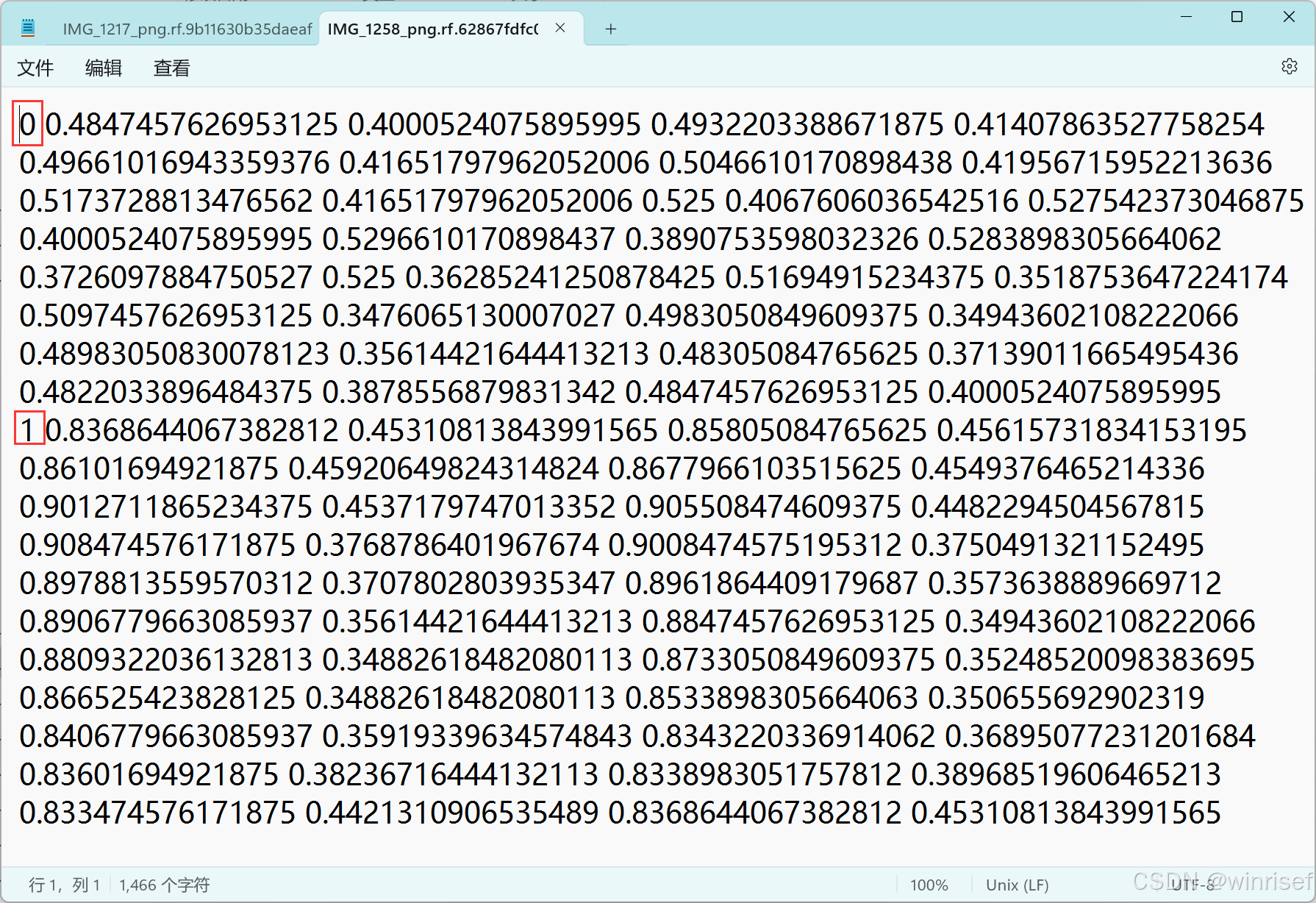
这个表示标注对应的图片有一个cat,一个dog
5.1.1下载训练集
训练集建议图片要超过100张,不然训练效果较差,图片越多训练效果越好
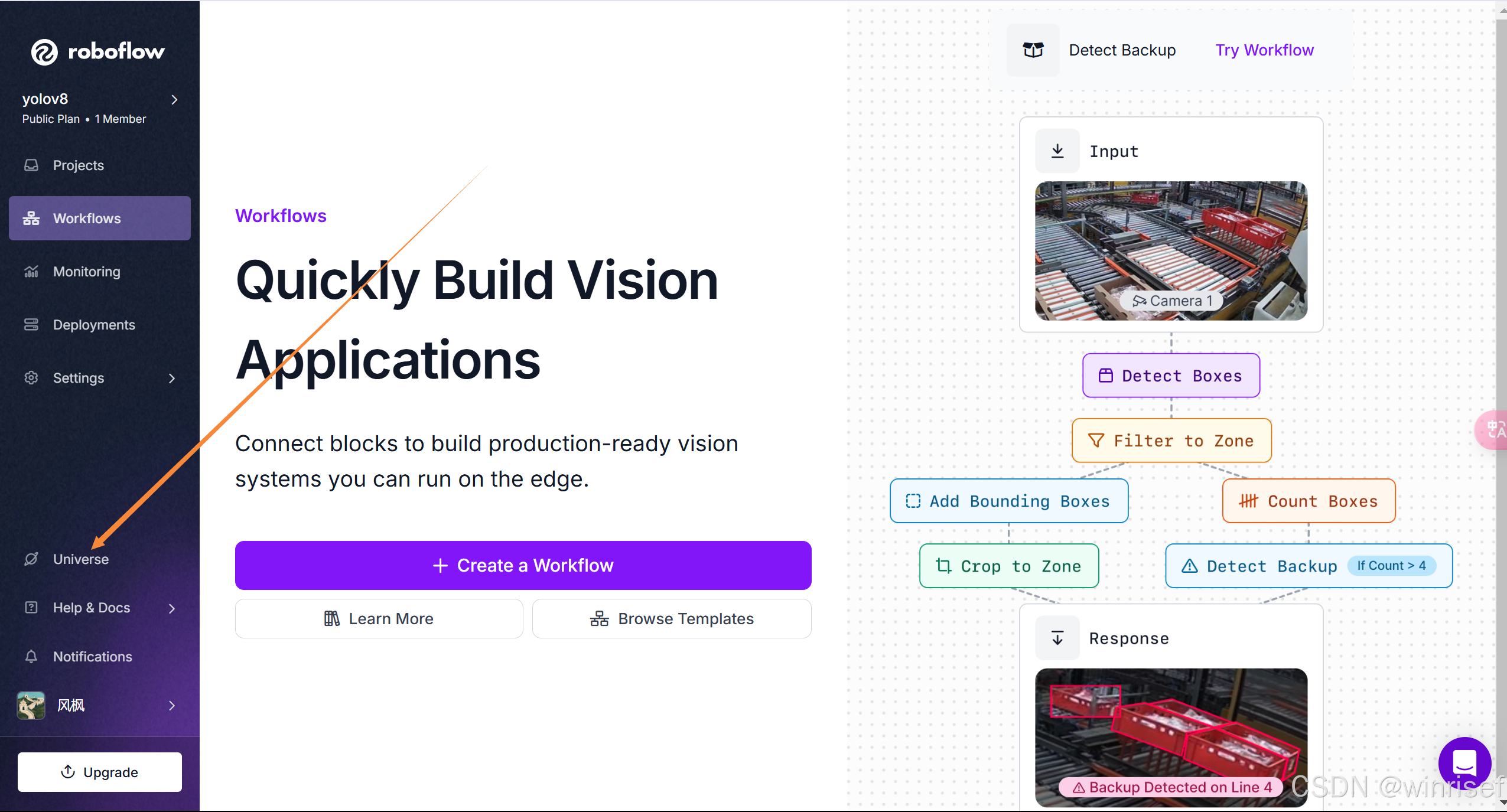
选择训练集,我这里选了一个检测路标的数据集,然后fork这个项目

然后进行预处理(比如将图片增强对比度、翻转、剪切、灰度调整、旋转等,也可以不预处理直接继续)。
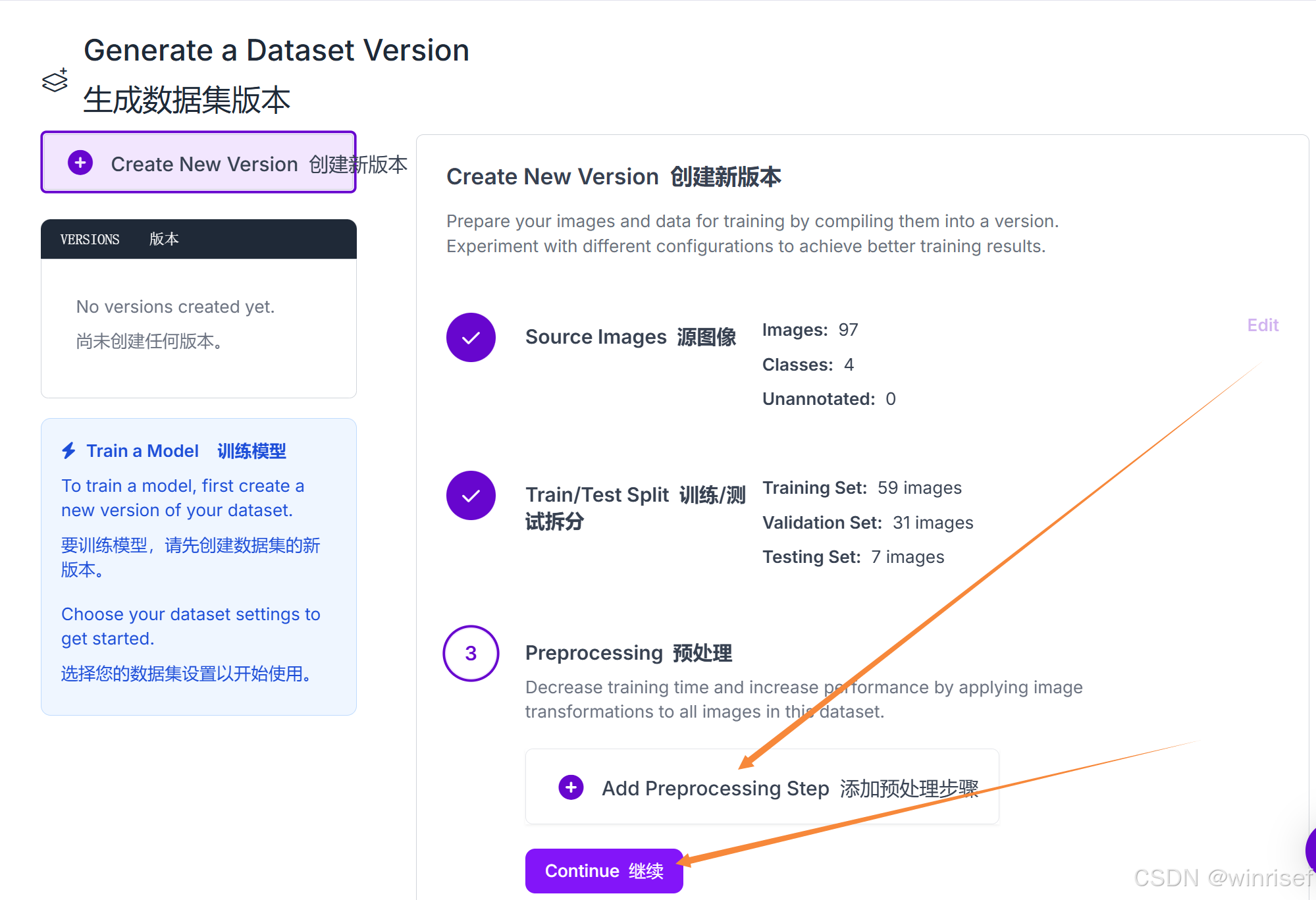
点击create创建:
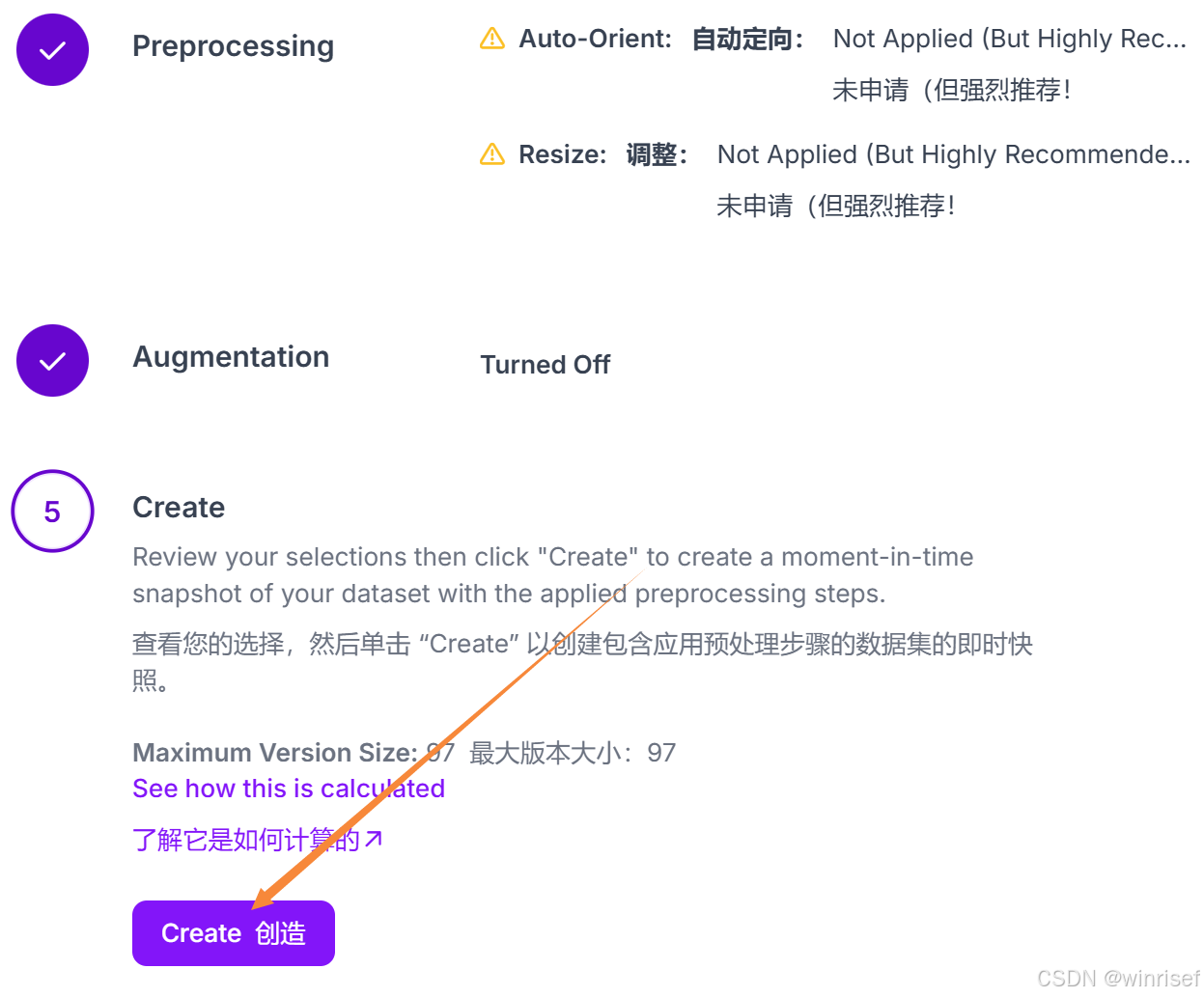
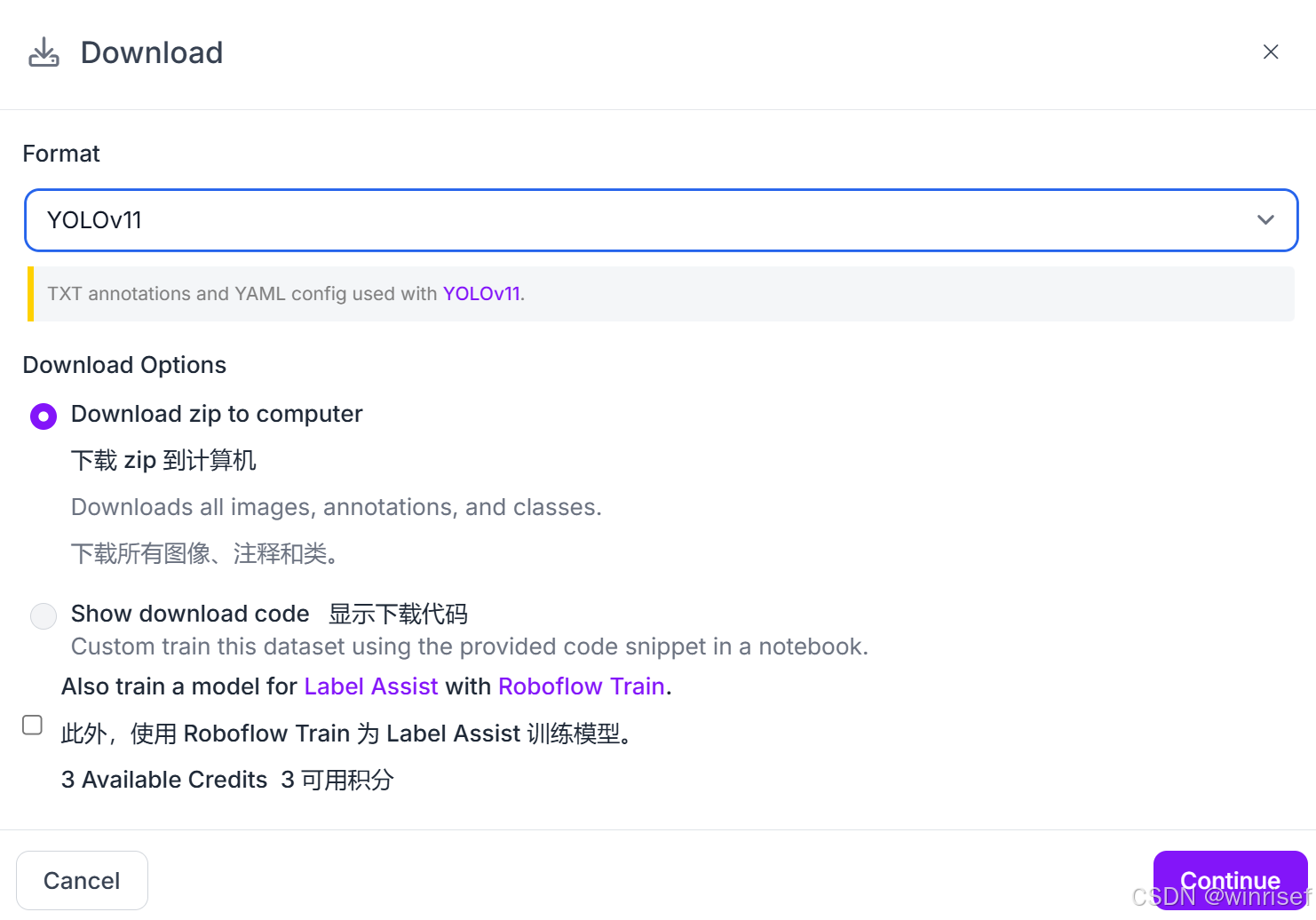
下载数据集,选择标注格式为YOLOv11,zip格式:
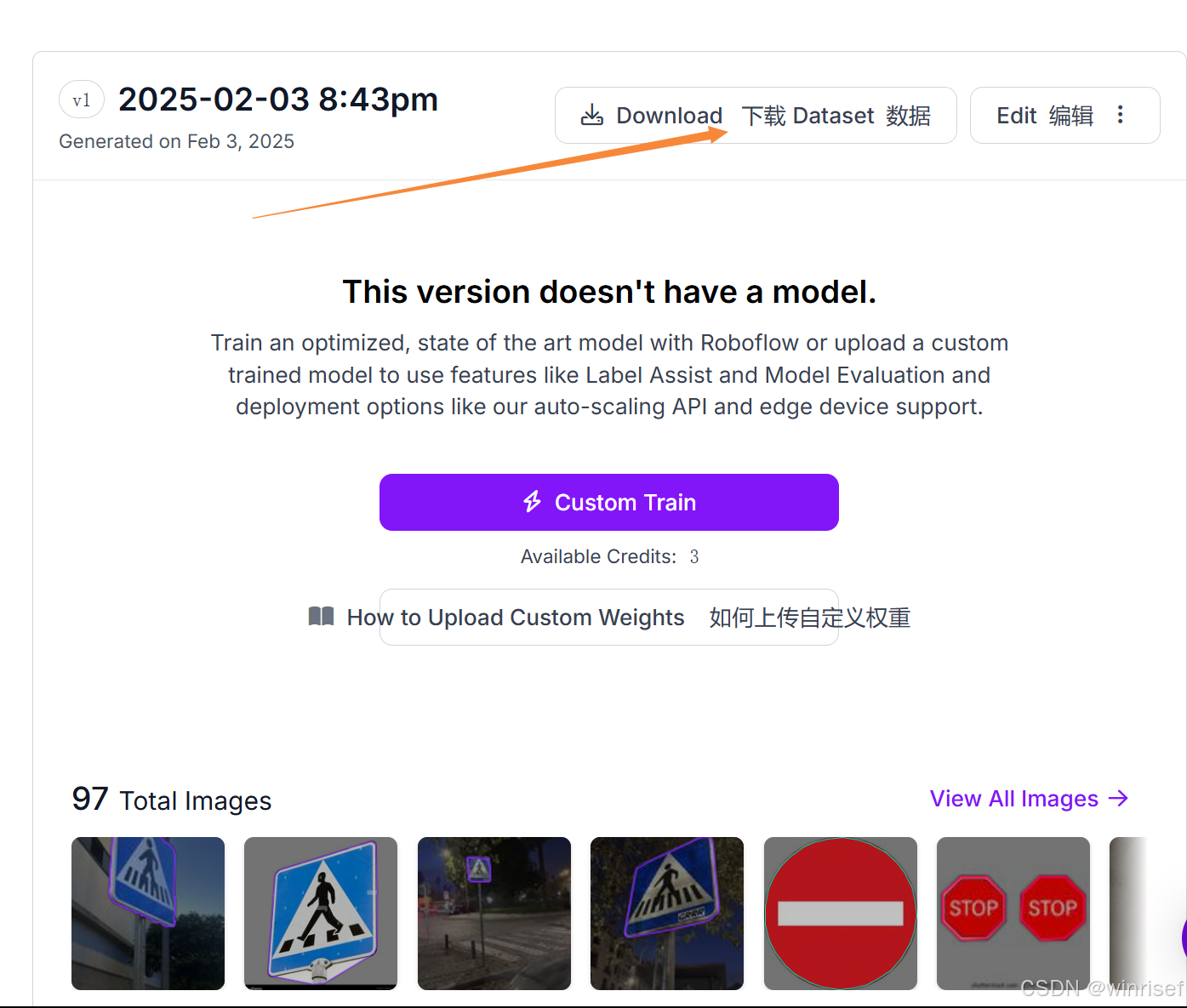
下载解压完成后文件如下:
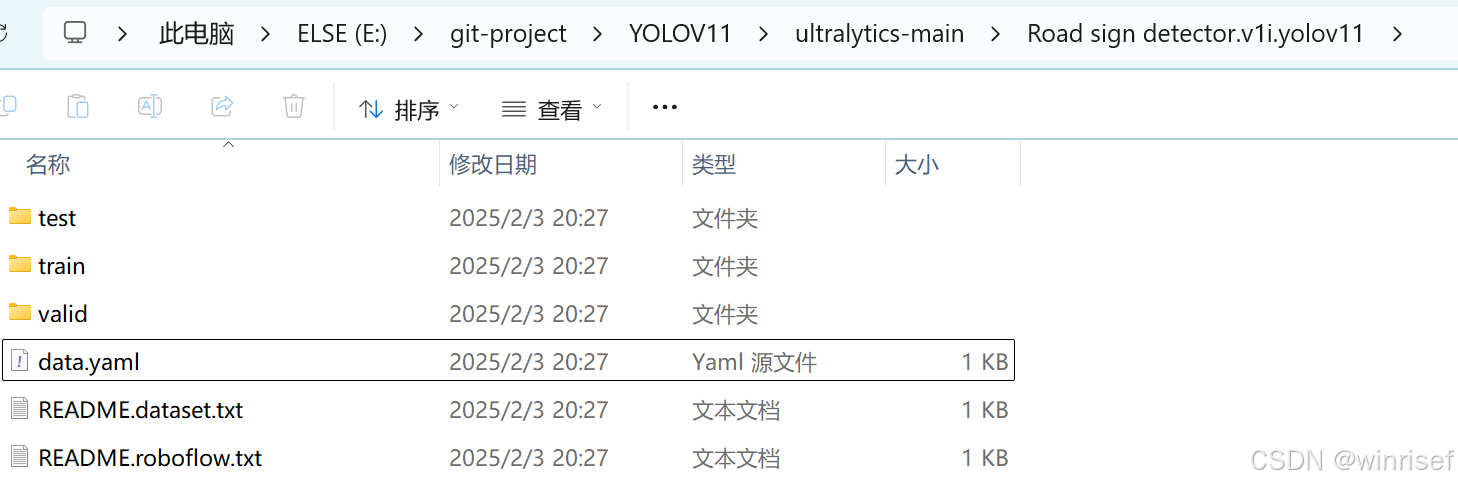
可以看到文件夹下有test,train,valid三个文件夹和data.yaml文件,详细解释:
train(训练集):用于模型的训练,即通过反向传播调整模型权重。数据量通常最大(如占总数据的70-80%)。每个图像需有对应的标注文件(如.txt格式的边界框和类别信息)。
valid/val(验证集):在训练过程中监控模型性能,防止过拟合(如通过早停机制)。用于调整超参数(如学习率、批次大小)或选择模型结构。不参与训练,仅在每个epoch后评估指标(如mAP、损失值)。数据量通常为10-20%,需与训练集分布一致但不重叠。
test(测试集):最终评估模型在“未见数据”上的泛化性能。反映模型在真实场景中的表现。
仅在训练完成后使用一次,确保评估结果无偏。数据量通常为10-20%,严格与训练集、验证集无重叠。
每个文件夹下有images(图片)和labels(标注)两个文件夹。
特别注意的是三个部分的图片一定不能有重复部分,如果一图多用你就会发现训练结果宇宙无敌好(mAP直接爆表),但实际上是一坨,就相当于考试出原题,考满分,然后感叹考试简单。
将data.yaml拖出到ultralytics-main文件夹下,原来的data.yaml文件如下:
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 3
names: ['No entry sign', 'Pedestrian sign', 'Stop sign']
修改yaml文件,修改为绝对路径,删除不需要部分(比如我的路径如下,注意是 / 不是\):
train: E:/git-project/YOLOV11/ultralytics-main/Road sign detector.v1i.yolov11/train/images
val: E:/git-project/YOLOV11/ultralytics-main/Road sign detector.v1i.yolov11/valid/images
test: E:/git-project/YOLOV11/ultralytics-main/Road sign detector.v1i.yolov11/test/images
nc: 3
names: ['No entry sign', 'Pedestrian sign', 'Stop sign']
5.2创建训练脚本
yaml文件改好后就在ultralytics-main目录下新建一个train.py文件:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolo11.yaml')
model.load('yolo11n.pt') # 是否加载预训练权重
model.train(data='data.yaml', #替换数据集的Yaml文件地址
cache=False,
imgsz=640,
epochs=100, #训练轮数
single_cls=False, # 是否是单类别检测
batch=16,
close_mosaic=0,
workers=0,
device='0', #选择'cpu'或者'0'
optimizer='SGD', # using SGD
#resume='runs/train/exp/weights/last.pt', # 续训设置last.pt的地址
amp=True,
project='runs/train',
name='exp',
)
metrics = model.val() # 运行验证并返回评估指标
参数及意义:
1.model = YOLO(‘yolo11.yaml’)是模型的网络结构,新手不建议更改,保持原样即可。
2.model.load(‘yolo11n.pt’) 预训练权重,如果想要快速得到较好的模型就使用,有yolo11n.pt,yolo11s.pt,yolo11m.pt,yolo11l.pt,yolo11x.pt可以选择,但是对继续训练的提升不大,理论上如果模型越大训练时间越长效果越好,比如x>l>m>s>n,但是如果使用x的话实测4060跑起来有点困难,新手建议使用yolo11n.pt。
3.data=‘data.yaml’,替换成yaml文件的地址,如果train.py和data.yaml在相同目录(在ultralytics-main)下就填这个。
4.epochs=100,训练轮数,理论上轮数越大效果越好,可以按需填,一般100就差不多。
5.single_cls=False, 是否是单类别检测,看data.yaml文件中nc的值,文中nc: 3表示类别三种,如果nc:1就填true。
6.device=‘0’,使用什么训练(是GPU还是CPU),填'0'或者'cpu'分别表示用显卡和用cpu计算。
7.resume=‘runs/train/exp/weights/last.pt’, 训练出来的模型效果不好可以续训,设置好上次训练出的权重文件的地址就行,实测不一定有提升或者提升有上限,初次训练就注释掉。
8.其它参数意义不大或者对新手不建议更改,就不阐述了。
完成后保存执行文件(注意在虚拟环境下,在ultralytics-main目录下):
python train.py
5.1.2标注图片训练
训练集建议图片要超过100张,不然训练效果较差,图片越多训练效果越好
可以从网上下载相关图片进行标注,常见的标注软件如Labelimg,Labelme,还有MakeSense.ai等免费标注网站进行标注,标注后格式输出为txt文件。
5.3训练情况
如下(我这里设置了训练10轮次):
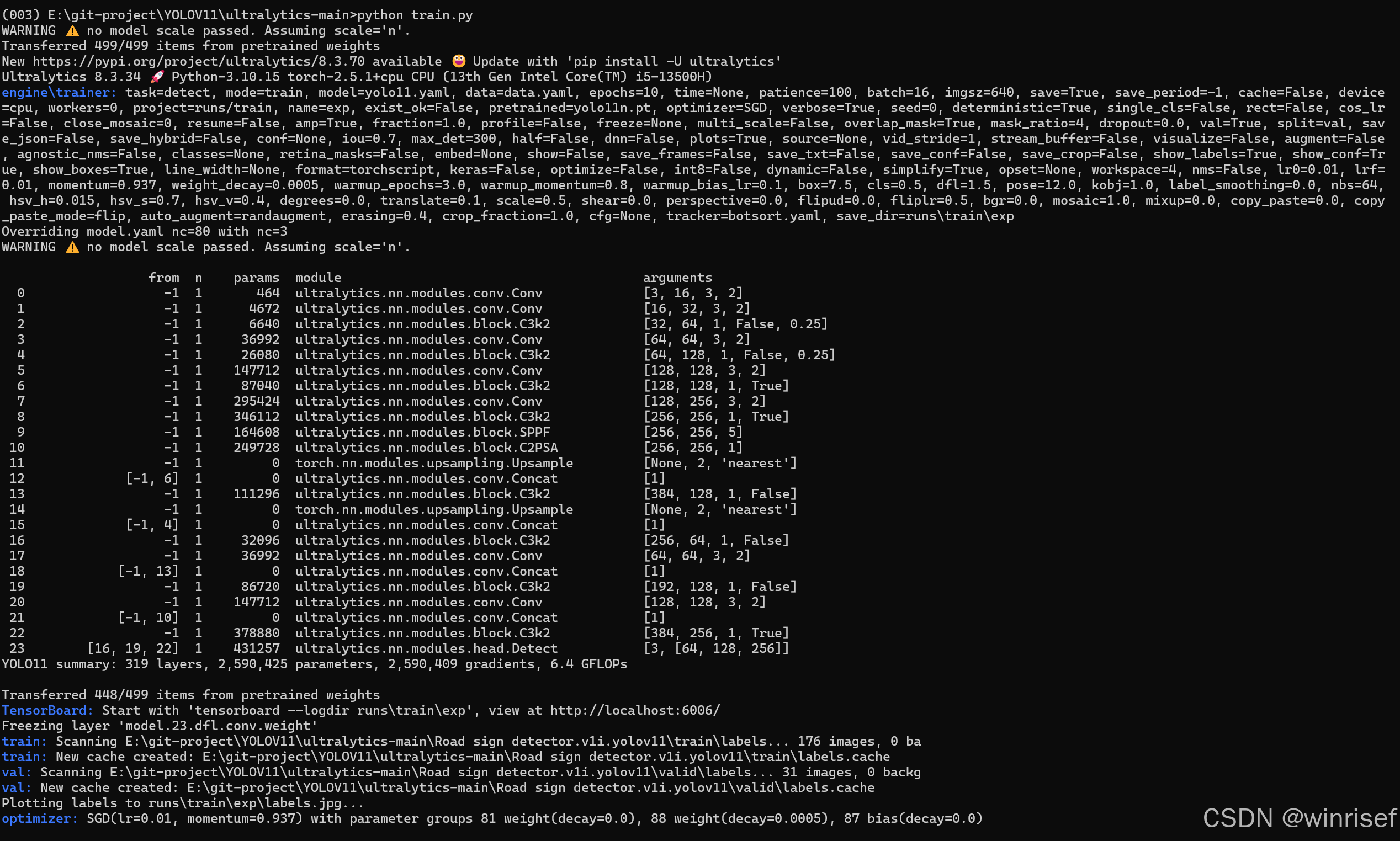
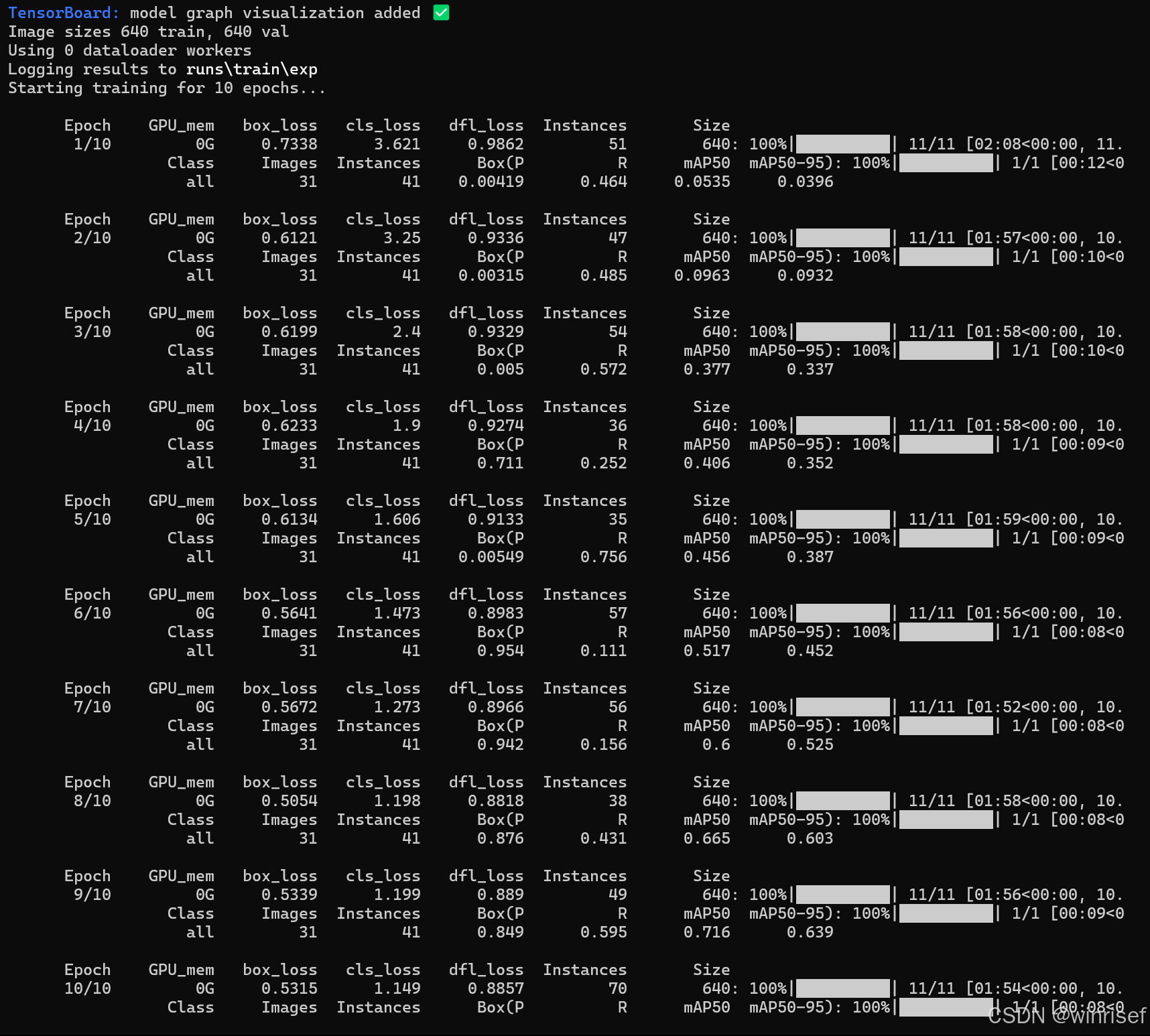
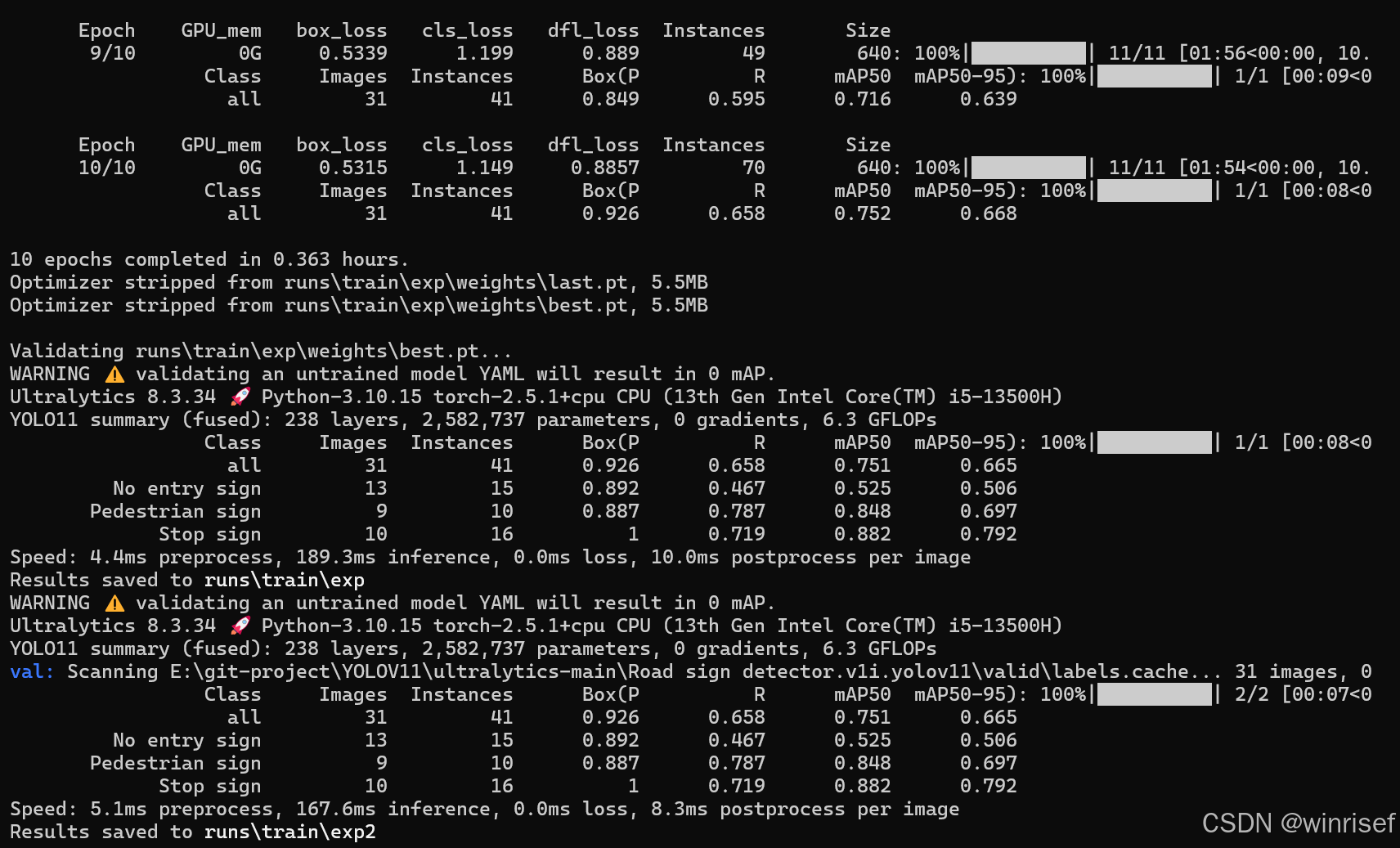
结果保存在runs\train\exp文件夹下,可以看到有weights文件夹,里面有best.pt(最好)和last.pt(最差)文件:
同时还包括PR曲线图片,训练过程图片等衡量训练效果的图片,至于怎么衡量训练效果我这里不再阐述。
5.4检验训练效果
使用新训练的best.pt推理网上下载的图片,可以看到能够推理。


















 7953
7953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









