







前言:
模型训练相比预测,会稍稍麻烦一点,特别是构建自己的数据集用于目标检测,在数据集的处理上需要耗费大量时间与耐心,本文会带你从0到1处理自己的数据集并用于YOLO11的模型训练与目标检测。
另外,本文章只针对使用YOLO11在自己的数据集上的训练、预测与模型导出,如果对于YOLO11的部署及预测仍然不清楚,可以先看我的另一篇文章:
【YOLO11速通指南】本地快速部署及预测(目标检测+实例分割+姿态估计)![]() https://blog.csdn.net/2301_78753314/article/details/143943167
https://blog.csdn.net/2301_78753314/article/details/143943167
下面会带你完成一次数据集的处理,我推荐了2个广受好评且免费的标注工具,前提是自备图片数据集。
一、数据集标注:
数据集标注,简而言之就是给数据集里面的图片“画框”,在训练模型时,数据集的标注提供了“正确答案”,让模型知道每张图像中的目标是什么,以及它们的位置(如边界框)。通过这些标注,模型能够学习从输入图像到正确输出(如类别和位置)之间的映射关系,从而在面对新的、未见过的数据时,能够准确地预测目标的位置和类别。没有标注,模型就没有办法知道什么是正确的预测,无法学习有效的特征,如图1.1.5。
1.1 数据集标注工具 1:labelimg
1.1.1 创建conda环境,解释器版本>=3.8
1.1.2 激活环境

1.1.3 下载labelimg与依赖(顺序下载否则会报错)
# 顺序安装,否则会报错 pip install PyQt5 -i https://pypi.tuna.tsinghua.edu.cn/simple pip install pyqt5-tools -i https://pypi.tuna.tsinghua.edu.cn/simple pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
1.1.4下载完成后输入:labelimg进入图形化界面
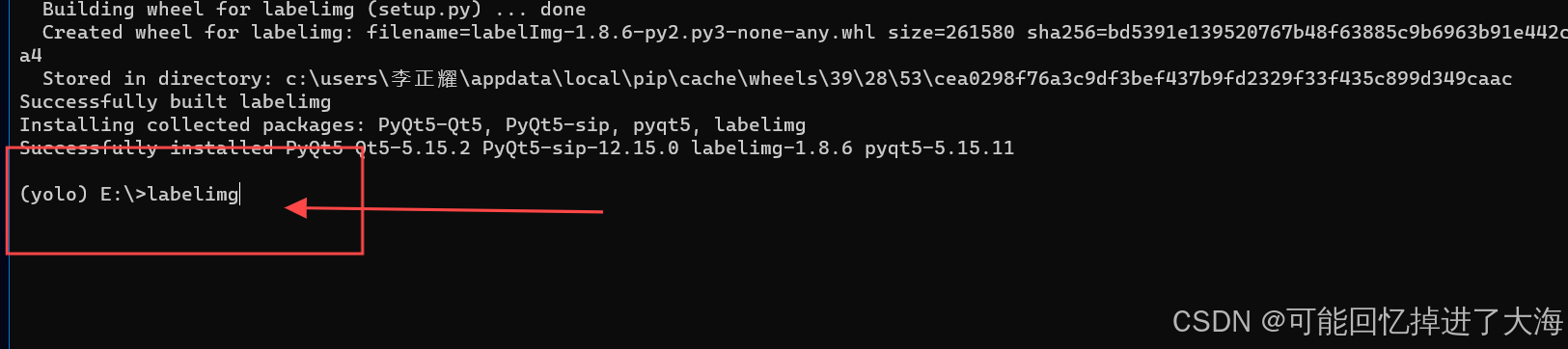
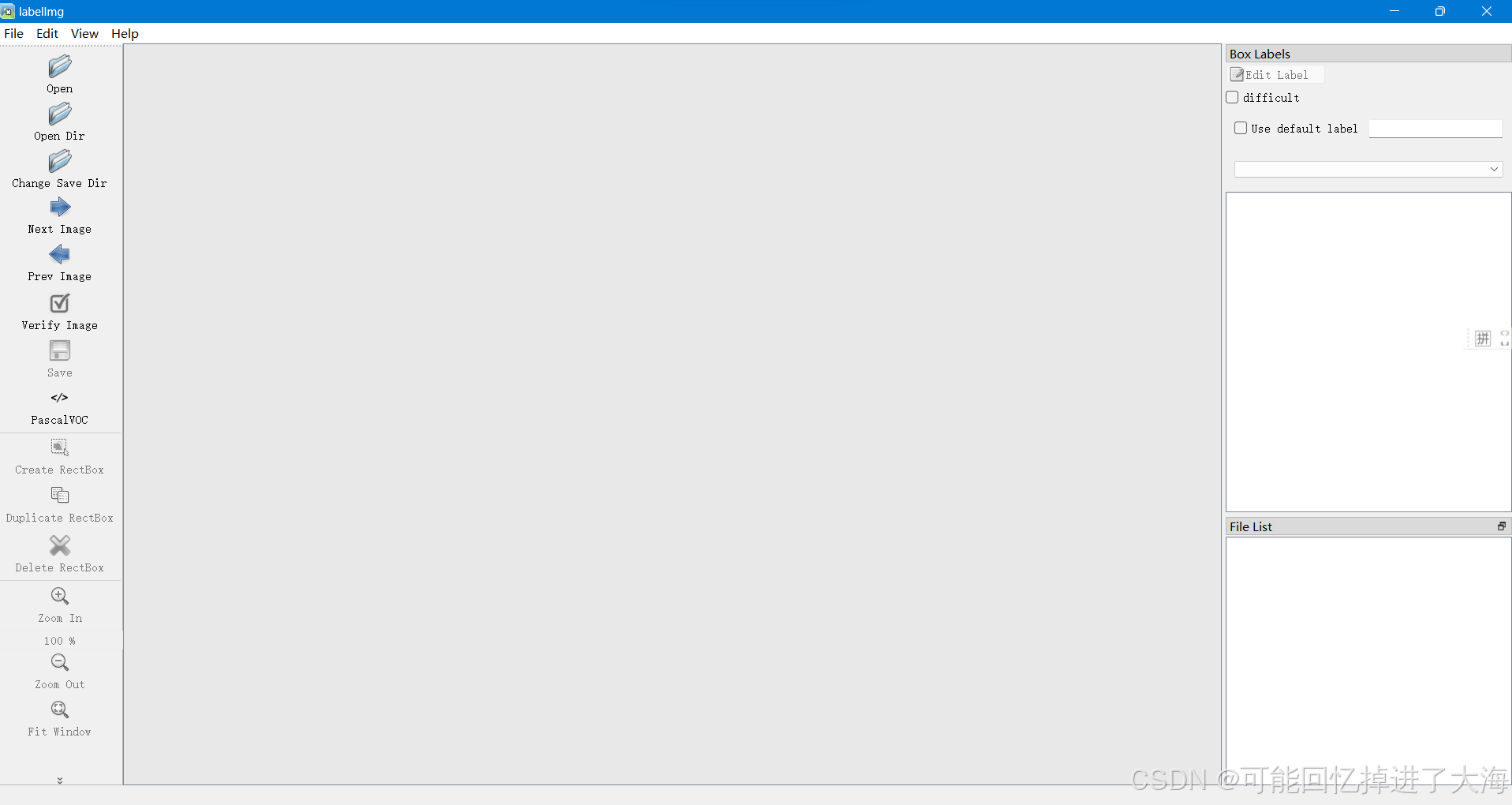
如下图所示:
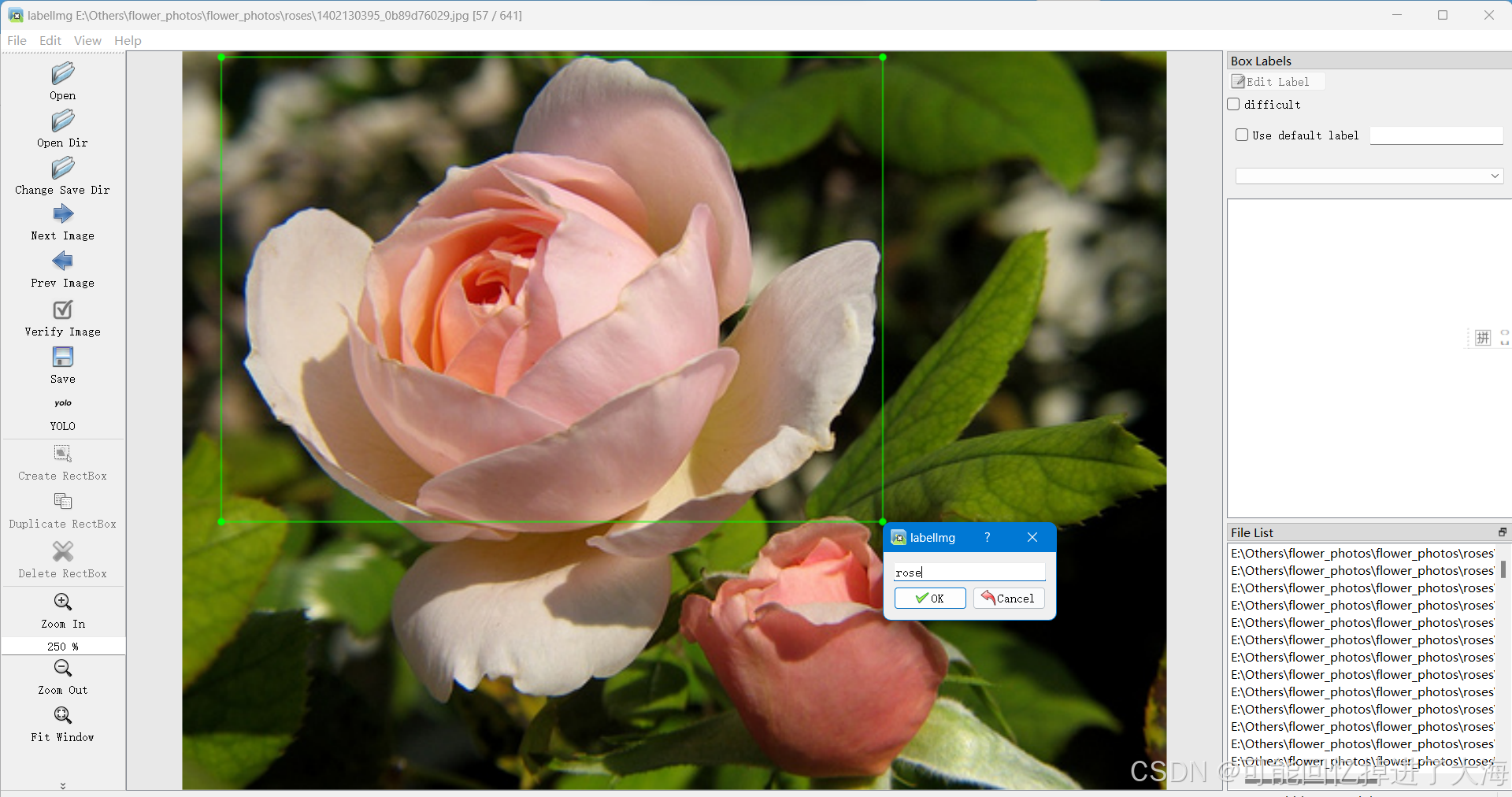
1.1.5 进行标注(图片示例):
1.1.6 详细安装参考:
LabelImg安装与使用教程![]() https://blog.csdn.net/qq_42591591/article/details/140050354
https://blog.csdn.net/qq_42591591/article/details/140050354
另外,手工进行数据集标注是一个体力活,下面是一些快捷键以提高效率:
W:调出标注的十字架,开始标注A:切换到上一张图片D:切换到下一张图片Ctrl+S:保存标注好的标签del:删除标注的矩形框Ctrl+鼠标滚轮:按住Ctrl,然后滚动鼠标滚轮,可以调整标注图片的显示大小Ctrl+u:选择要标注图片的文件夹Ctrl+r:选择标注好的label标签存放的文件夹↑→↓←:移动标注的矩形框的位置
1.2 数据集标注工具 2:T-Rex Label
数据集标注工具较多,不限制具体使用哪种工具,但是要支持YOLO(TXT)格式,不然还需要用代码转格式:
YOLO格式的标注文件包含了对象的类别索引和对象边界框的相对坐标。每个对象的标注信息占一行,格式如下:
<object-class> <x_center> <y_center> <width> <height>
其中,<object-class>是对象类别的索引,<x_center>和<y_center>是边界框中心的相对坐标,<width>和<height>是边界框的相对宽度和高度。
由于篇幅限制,不赘述如何使用这些工具,可以参考其他针对性的文章教程,例如:
参考教程:【T-Rex Label基础教程】全新的自动化图片标注工具/软件 提高效率必备 可在线![]() https://blog.csdn.net/luokang21/article/details/142501950
https://blog.csdn.net/luokang21/article/details/142501950
二、数据集格式:
datasets/
├── train/ # 训练集
│ ├── images/ # images文件夹是用来存放图片的
│ └── labels/ # labels文件夹是用来存放图片对应的数据文件
└── val/ # 验证集
├── images/
└── labels/
注:images文件夹是图片文件,训练集和验证集的图片保持不一样,在未标注之前,训练集和验证集里面的labels文件夹是空的,待标注完成后会自动添加到labels文件夹中。
2.1 数据集的划分:
一般情况下对于数据量较小的数据集,train:val:test=8:1:1,由于我没有设置test测试集(一般情况下是需要设置的),我采用的比例是 train:val=8:2,即train文件夹160张,val文件夹40张。当然,更方便的是去找一段python代码对文件夹进行处理实现自动划分。
训练集标注
2.2、Open DIR:选择train下面的images
2.3、Change Save Dir:选择train下面的labels
2.4、开始标注,标注完毕进行2.5
验证集标注
2.5、Open DIR:选择val下面的images
2.6、Change Save Dir:选择val下面的labels
2.7、开始标注,标注完毕后退出labelimg
我的数据集是训练用于检测是否戴口罩的目标检测模型,原数据集包含3类标签(戴口罩、没戴口罩、有口罩但没戴好),但是由于只是用于测试,就偷个懒只设置了两个类别(戴口罩、没戴口罩),我的标注示例train/images下面160张,val/images下面40张,不要太少,同时,标注框尽量贴合和对准目标,也不要把框打得太大或太小,不然效果会大打折扣。
示例如图:

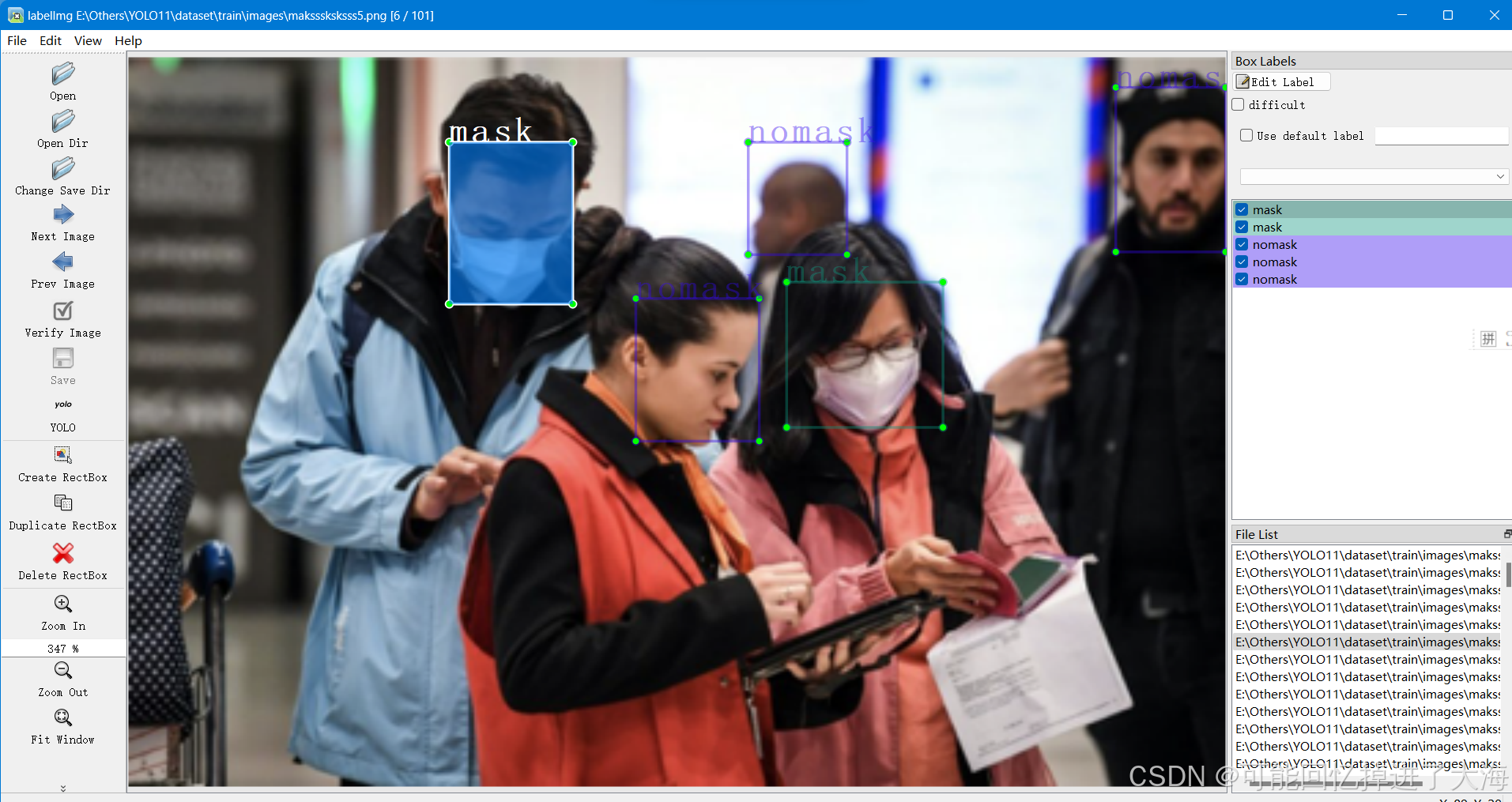
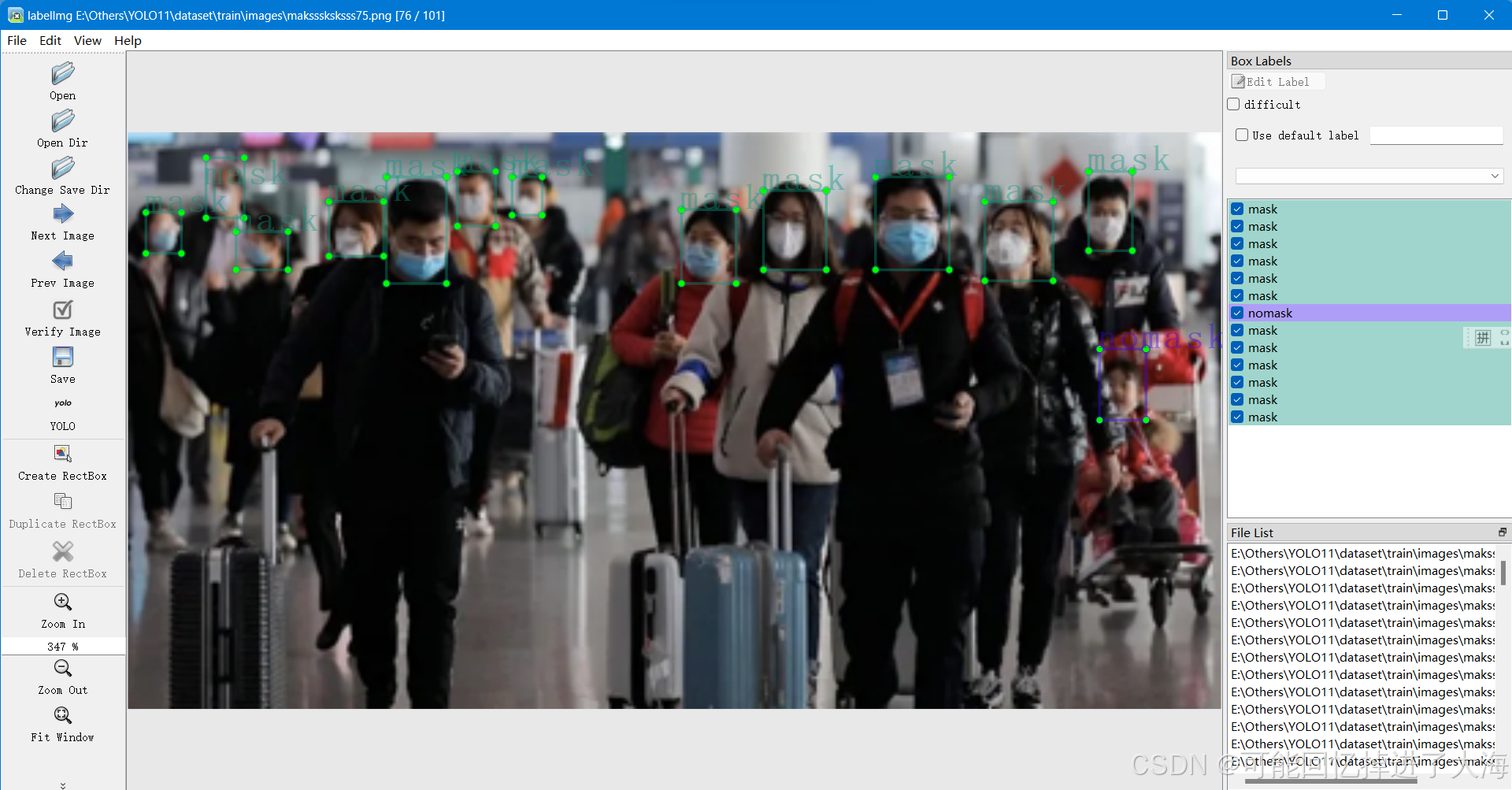
2.8 标注200张不是一个轻松的事情,特别是耐心差、脾气差就不要手动标注了(实话勿喷),可以试试自动标注工具,只是需要把标注的内容核对一遍,大大降低了难度。
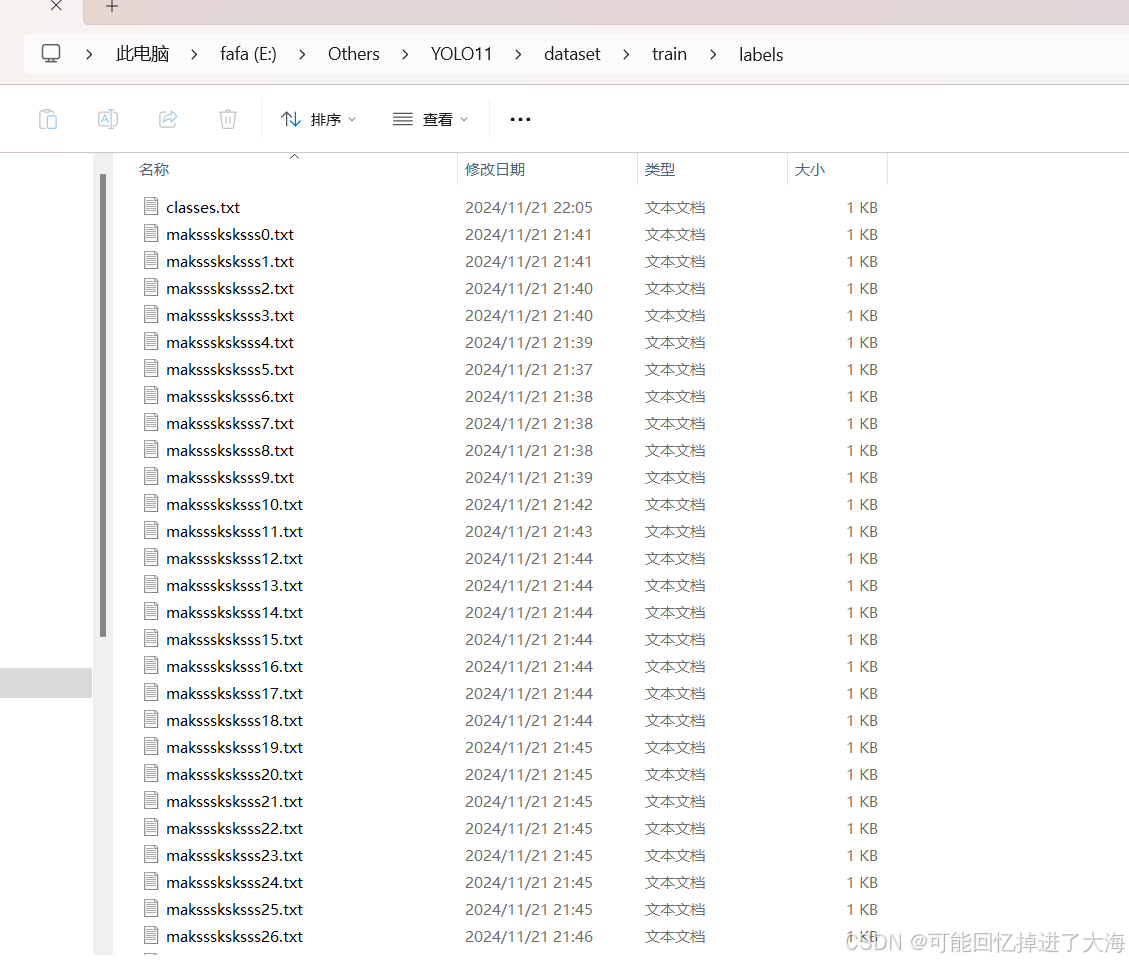
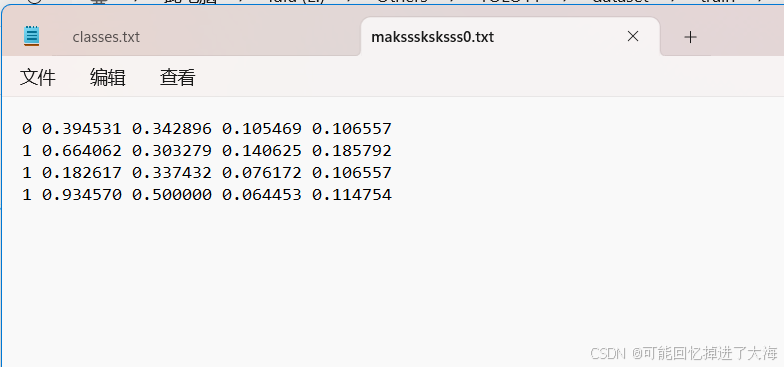
2.9 接下来你会得到labels内容如下:
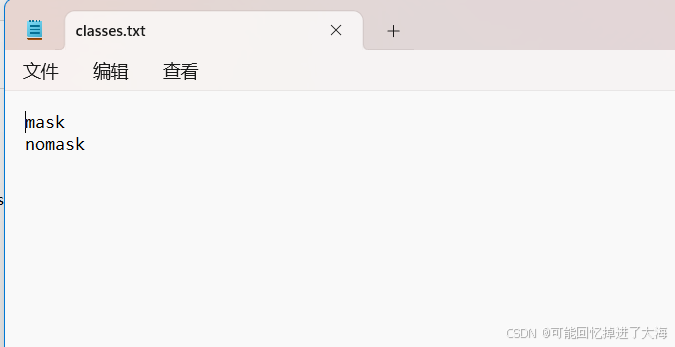
2.10 classes.txt文件里面实际上就是类别,我这里只有“口罩”,“无口罩”两类,是根据我打的标签自动生成的。
2.11 这下面的.txt文件实际上就是每张图片标注框的位置,名称是图片名称,不用管。
具体解释请看:
LabelImg标注的YOLO格式txt标签中心坐标和物体边界框长宽的转换![]() https://blog.csdn.net/Keep_Trying_Go/article/details/128224748
https://blog.csdn.net/Keep_Trying_Go/article/details/128224748
到此为止,自己的数据集已经准备好了,注意把数据集copy到ultralytics文件夹下,里面还要新建一个yaml文件(具体步骤见下方3.3),接下来就是在YOLO11的框架上对自己的数据集进行训练:
三、模型训练
模型训练最好使用GPU(如果有英伟达显卡),配置教程如下:
CUDA与CUDNN在Windows下的安装与配置(超级详细版)![]() https://blog.csdn.net/YYDS_WV/article/details/137825313
https://blog.csdn.net/YYDS_WV/article/details/137825313
如果配置好了CUDA,还需要在虚拟环境中下载Pytorch(gpu),教程如下:
全网最详细的安装pytorch GPU方法,一次安装成功!!包括安装失败后的处理方法!![]() https://blog.csdn.net/qlkaicx/article/details/134577555
https://blog.csdn.net/qlkaicx/article/details/134577555
模型训练需要YOLO11源码,如果没有,可以通过我的网盘快速获取:
3.1 在ultralytics下新建train.py:
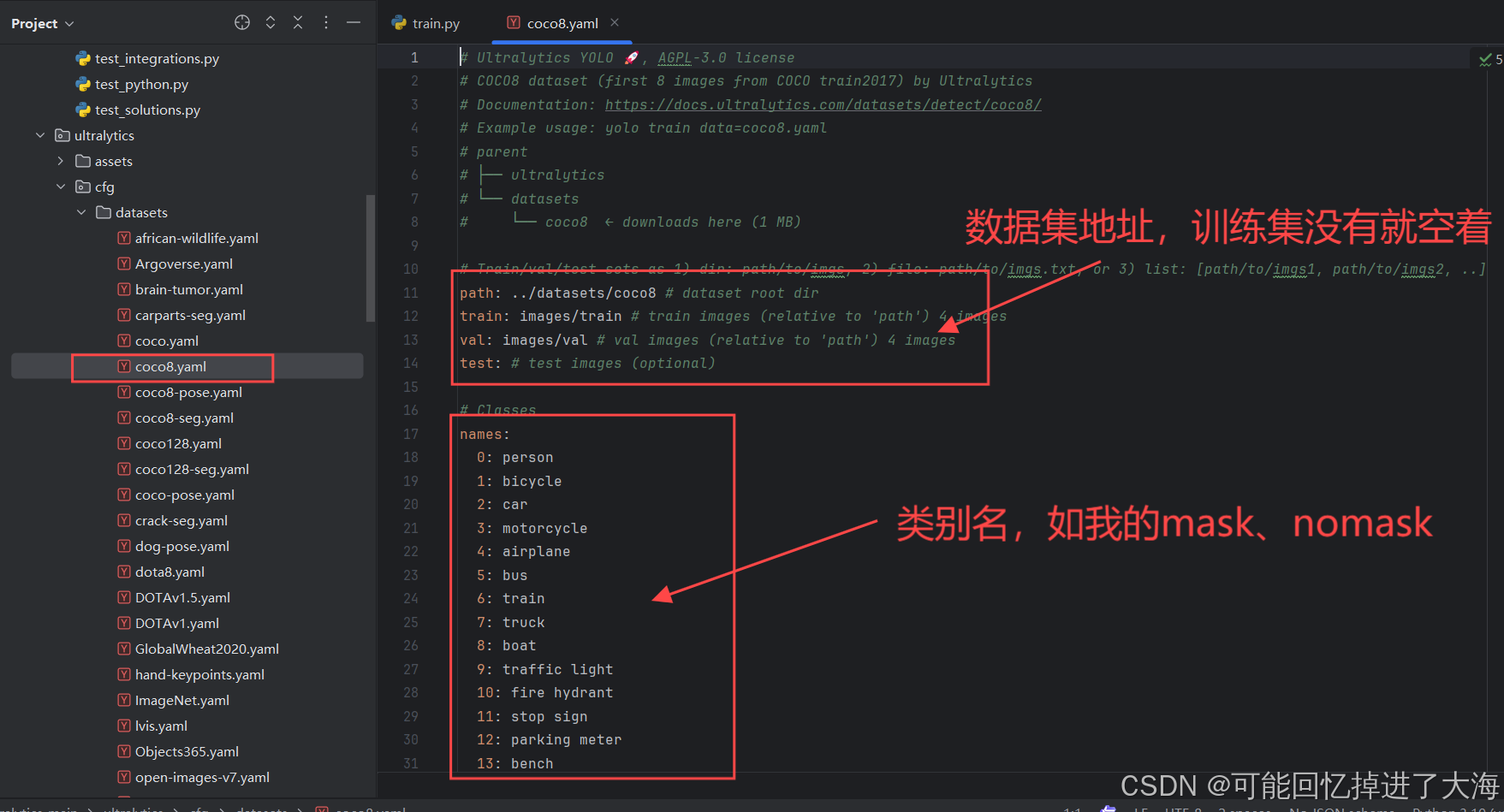
3.2 先研究一下ultralytics/cfg/datasets目录下的coco8.yaml文件:
如图所示,结合官方文档的训练示例,训练所需要的.yaml文件实际上就是一个配置文件,用于指向数据集的位置及classes信息
3.3 把数据集放到ultralytics/datasets目录下,并且新建first_trian.yaml
# 指向训练集 train: E:\Others\YOLO11\ultralytics-main\ultralytics-main\ultralytics\datasets\train # 指向验证集 val: E:\Others\YOLO11\ultralytics-main\ultralytics-main\ultralytics\datasets\val # 指向测试集 test: nc: 2 # 类别数 names: ['mask', 'nomask'] # 类别名称
3.4 给train.py添加代码:
有GPU尽量使用进行GPU训练,没有GPU设置device='cpu'
import multiprocessing from ultralytics import YOLO # 设置多进程启动方法为 'spawn'(适用于 Windows) multiprocessing.set_start_method('spawn', force=True) if __name__ == "__main__": # 加载模型权重 model = YOLO("ultralytics/cfg/models/11/yolo11.yaml") # 开始训练 model.train( # 指定 .yaml 配置文件 data="ultralytics/datasets/first_trian.yaml", # 训练轮次 epochs=50, batch=16, imgsz=640, # 保存训练结果路径 project='runs/train', # 指定使用的设备('0'代表第一张GPU,如果没有GPU使用'cpu') device='0' )
3.5 常用参数:
参数 默认值 说明 modelNone用于训练的模型文件的路径。 dataNone数据集配置文件的路径(例如 coco8.yaml).epochs100训练历元总数。 batch16批量大小,可调整为整数或自动模式。 imgsz640用于训练的目标图像大小。 deviceNone用于训练的计算设备,如 cpu,0,0,1或mps.saveTrue可保存训练检查点和最终模型权重。
3.6 运行train.py开始训练
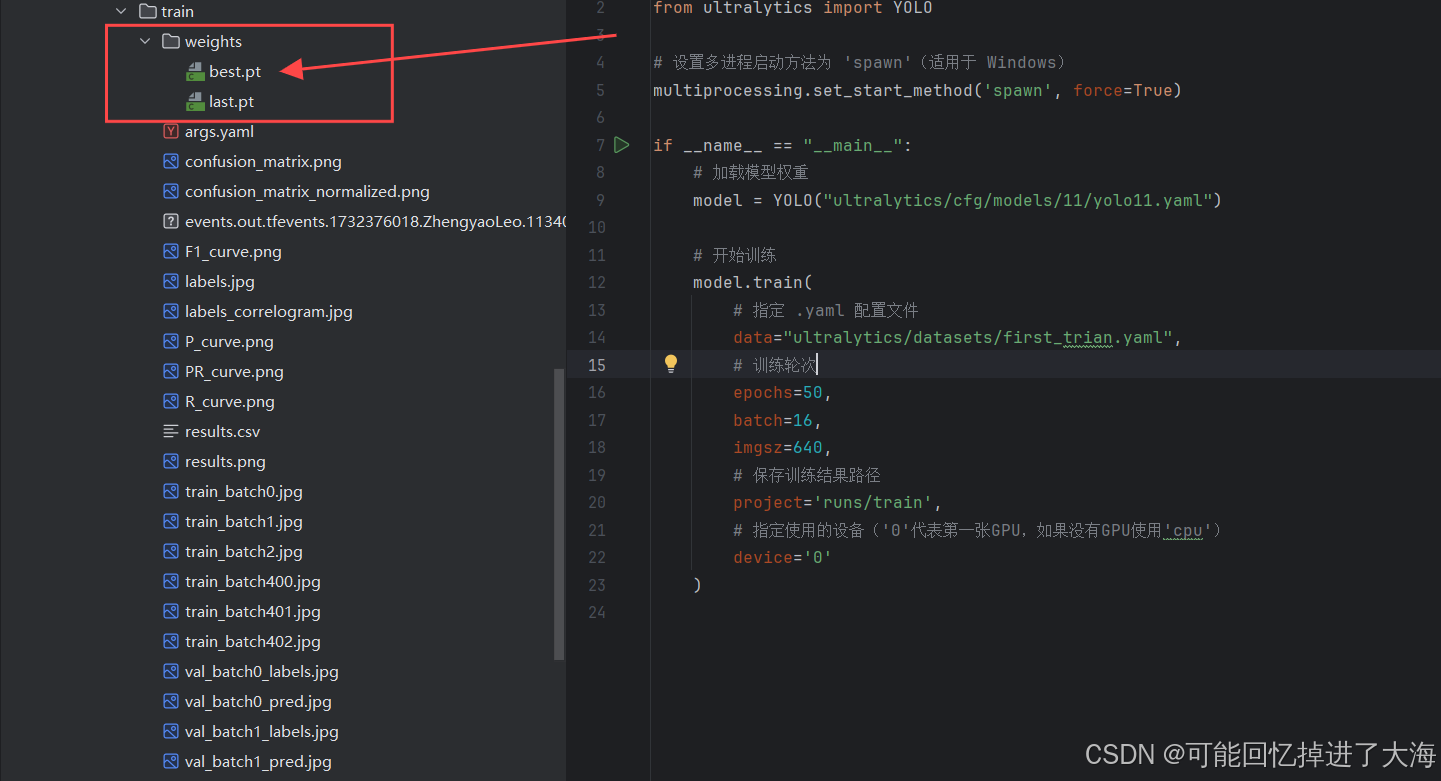
开始训练:
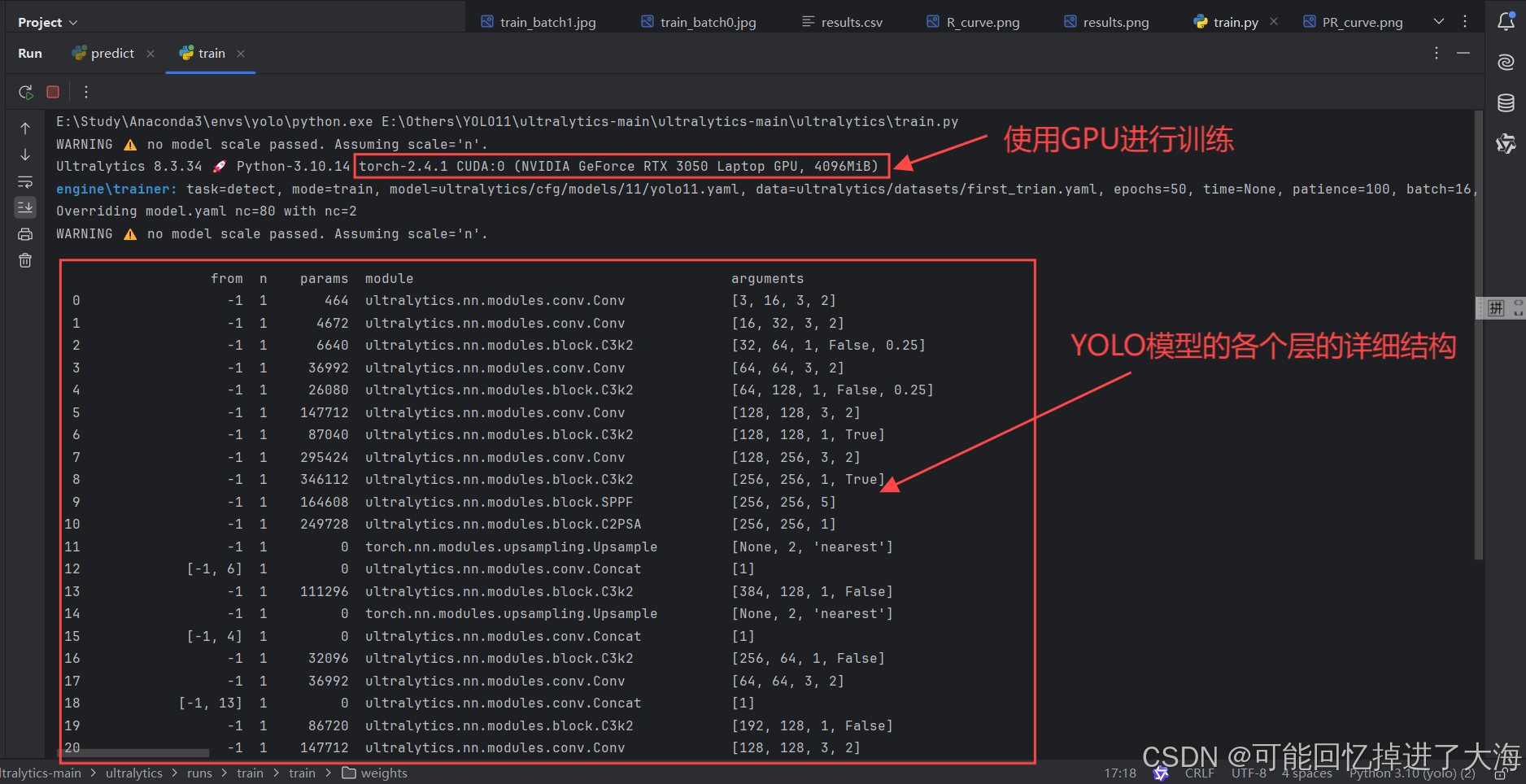
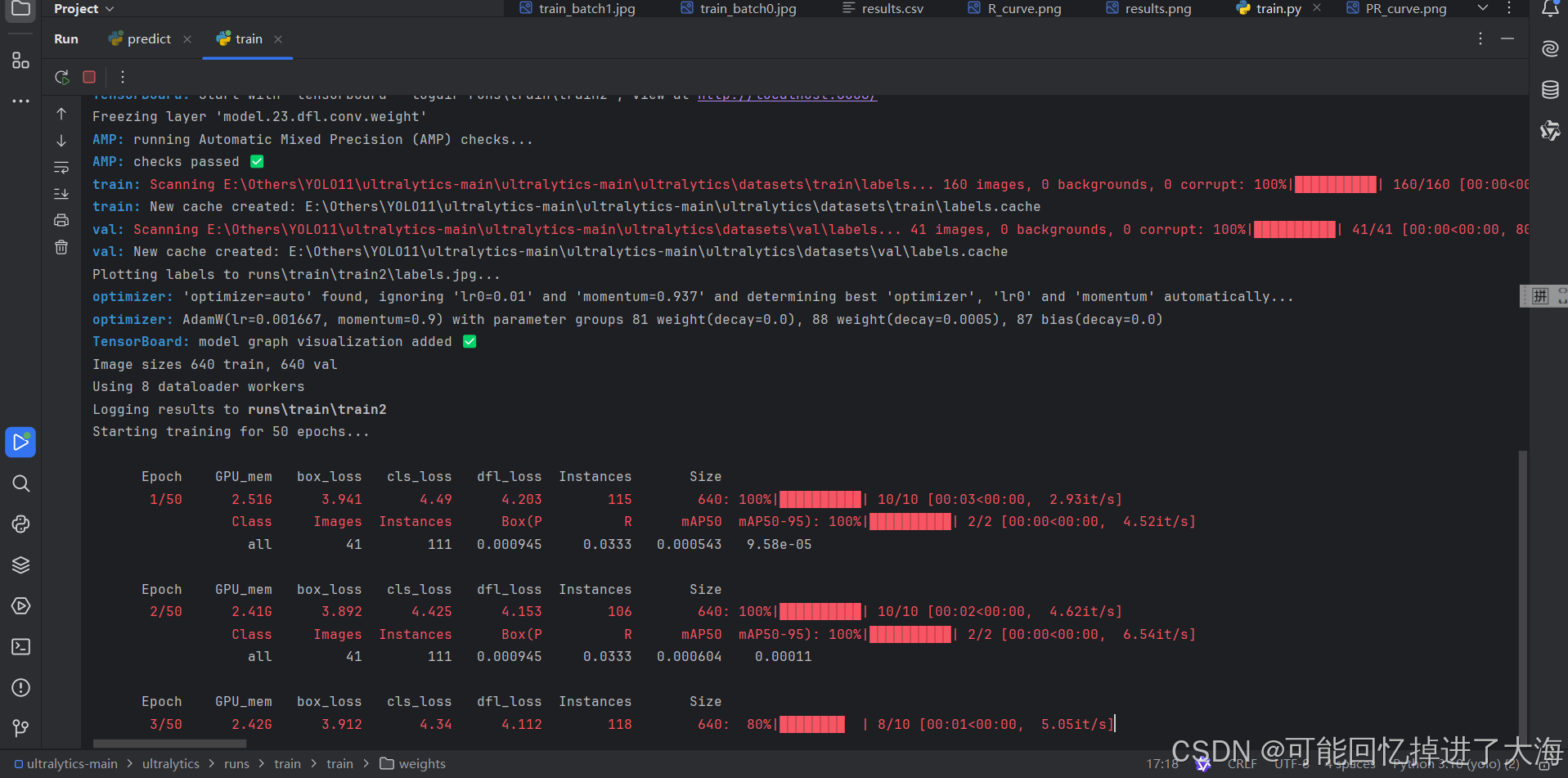
3.7 我们就得到了训练后的模型权重(weights),通常我们使用best.pt作为训练成功的模型,用于针对性的预测:
3.8 使用自己的模型进行预测(测试图片一定不能用标注、训练过的数据集内的图片!!!):
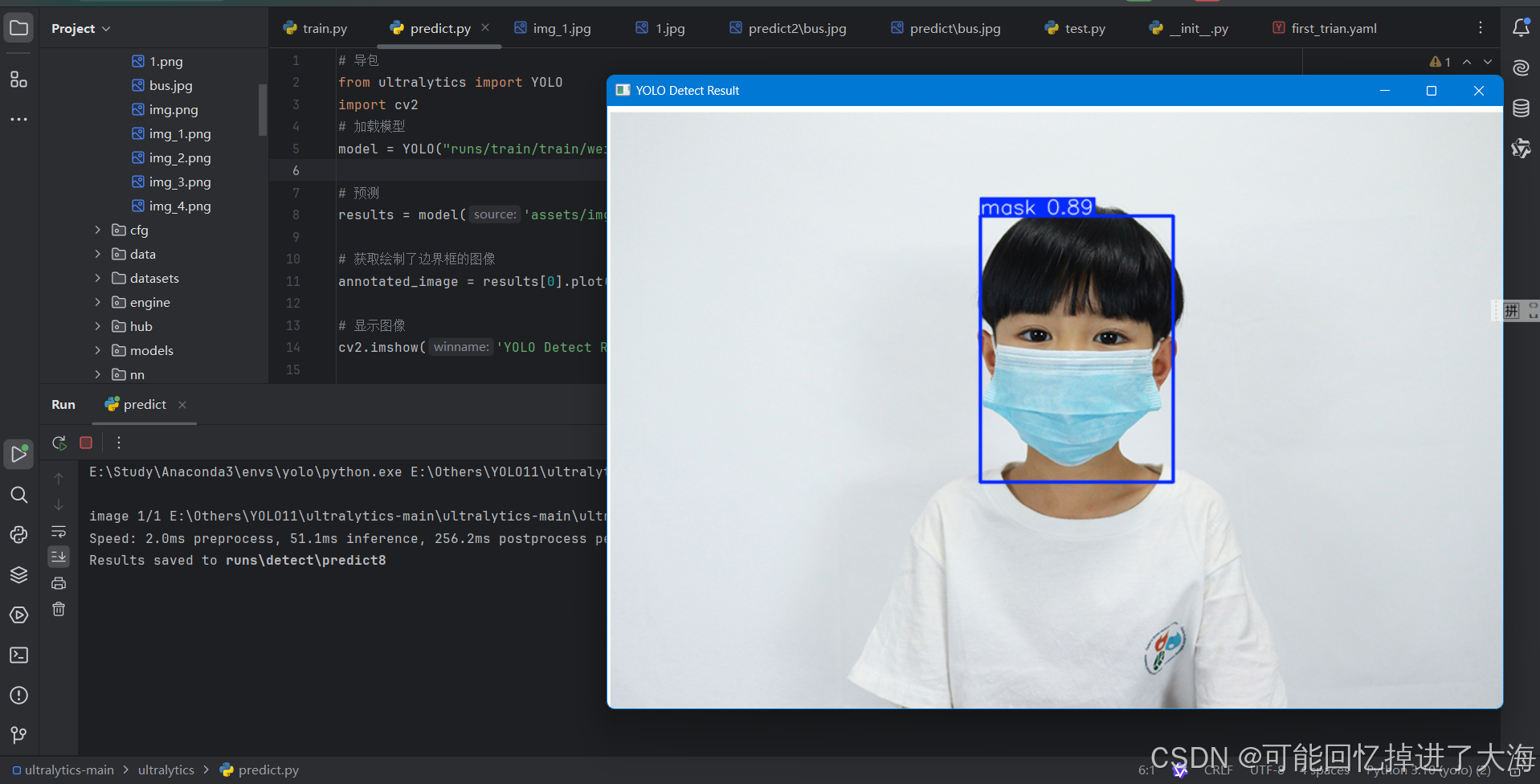
这个时候可以看到,我们的模型训练得比较成功,起码有一定的泛化能力,对于没有训练过的图片也可以成功预测到目标,对于模型训练的数据,可以查看与weights同目录下的相关性能指标文件:
例如:
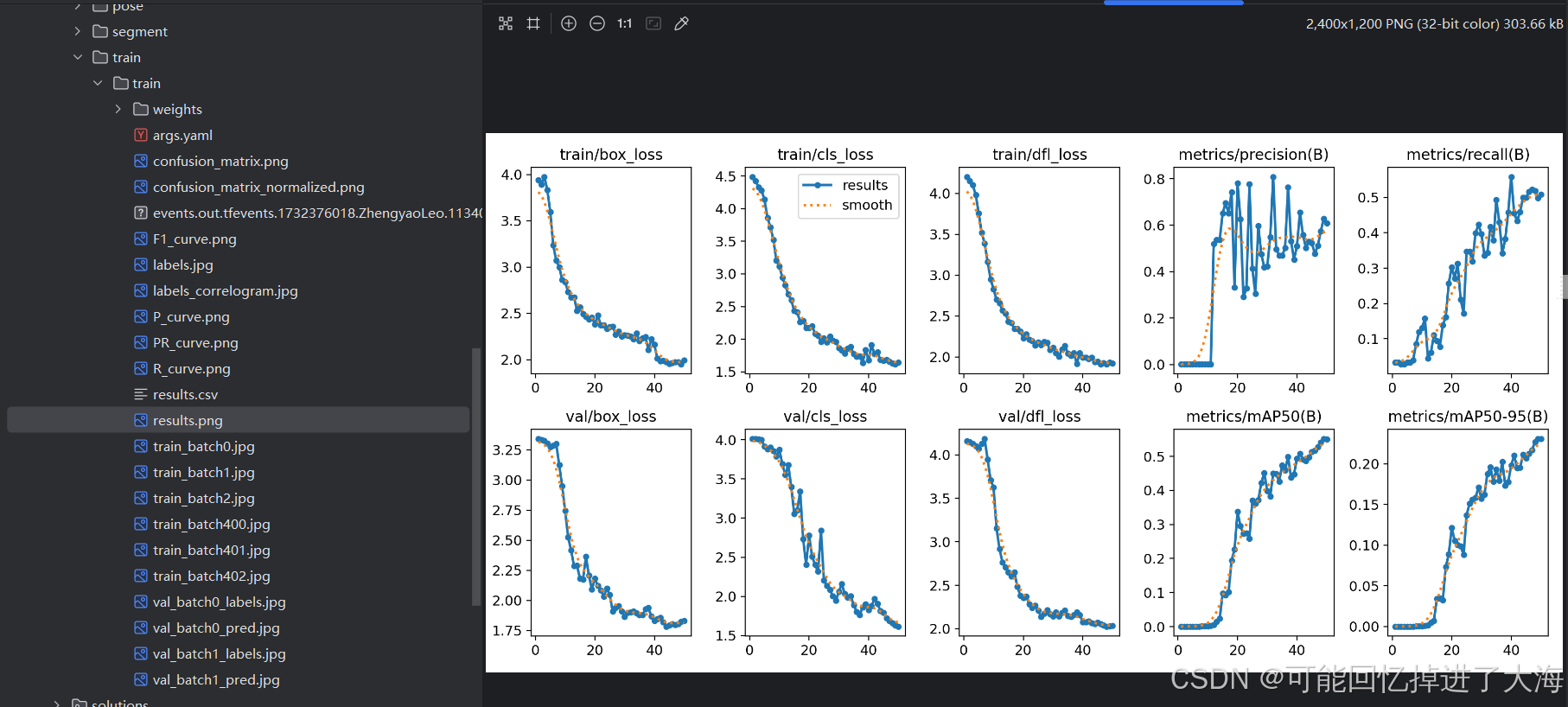
到这里,整个训练过程就已经结束了,请注意,具体文件的位置可以随心所欲,只要自己能找到就行,但是在使用时一定要写正确地址,尽量把需要用的文件如.yaml、datasets数据集放到项目里面,然后使用相对路径,在pycharm中按住CTRL,鼠标移到对应路径的代码中,是可以直接跳转的,如果不能跳转,就要反复确认地址是否正确了。
四、模型导出
将模型导出为ONNX可以实现跨框架兼容,支持在不同深度学习平台(如TensorFlow、ONNX Runtime)上运行,同时适用于多种硬件(如GPU、嵌入式设备)。ONNX优化推理速度,支持量化(FP16、INT8)降低计算成本,便于模型部署到云端、边缘和移动设备。此外,ONNX模型便于存储、调试和共享,是生产环境中轻量高效的标准格式。
这里参考了这篇文章:
YOLO11 实例分割 | 导出ONNX模型 | ONNX模型推理![]() https://blog.csdn.net/qq_41204464/article/details/1429222234.1 导出为ONNX模型(best.pt的路径换成自己的):
https://blog.csdn.net/qq_41204464/article/details/1429222234.1 导出为ONNX模型(best.pt的路径换成自己的):
from ultralytics import YOLO
# 加载一个模型,路径为 YOLO 模型的 .pt 文件
model = YOLO("runs/train6/weights/best.pt")
# 导出模型,格式为 ONNX
model.export(format="onnx")在同目录的文件夹下会生成一个新的best.onnx文件
4.2 如果你想自定义参数而不是使用默认参数:
from ultralytics import YOLO
# 加载一个模型,路径为 YOLO 模型的 .pt 文件
model = YOLO(r"runs/train/weights/best.pt")
# 导出模型,设置多种参数
model.export(
format="onnx", # 导出格式为 ONNX
imgsz=(640, 640), # 设置输入图像的尺寸
keras=False, # 不导出为 Keras 格式
optimize=False, # 不进行优化 False, 移动设备优化的参数,用于在导出为TorchScript 格式时进行模型优化
half=False, # 不启用 FP16 量化
int8=False, # 不启用 INT8 量化
dynamic=False, # 不启用动态输入尺寸
simplify=True, # 简化 ONNX 模型
opset=None, # 使用最新的 opset 版本
workspace=4.0, # 为 TensorRT 优化设置最大工作区大小(GiB)
nms=False, # 不添加 NMS(非极大值抑制)
batch=1, # 指定批处理大小
device="cpu" # 指定导出设备为CPU或GPU,对应参数为"cpu" , "0"
)参数类型及说明:
model.export( )函数内各项参数:
format="onnx":指定导出模型的格式为 onnx。imgsz=(640, 640):输入图像的尺寸设为 640x640。如果需要其他尺寸可以修改这个值。keras=False:不导出为 Keras 格式的模型。optimize=False:不应用 TorchScript 移动设备优化。half=False:不启用 FP16(半精度)量化。int8=False:不启用 INT8 量化。dynamic=False:不启用动态输入尺寸。simplify=True:简化模型以提升 ONNX 模型的性能。opset=None:使用默认的 ONNX opset 版本,如果需要可以手动指定。workspace=4.0:为 TensorRT 优化指定最大工作空间大小为 4 GiB。nms=False:不为 CoreML 导出添加非极大值抑制(NMS)。batch=1:设置批处理大小为 1。- device="cpu", 指定导出设备为CPU或GPU,对应参数为"cpu" , "0"
YOLO11不仅只支持导出为ONNX格式,下面是支持的所有导出的格式:
| 支持的导出格式 | format参数值 | 生成的模型示例 | model.export( )函数的参数 |
|---|---|---|---|
| PyTorch | - | yolo11n.pt | - |
| TorchScript | torchscript | yolo11n.torchscript | imgsz, optimize, batch |
| ONNX | onnx | yolo11n.onnx | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolo11n_openvino_model/ | imgsz, half, int8, batch |
| TensorRT | engine | yolo11n.engine | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolo11n.mlpackage | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolo11n_saved_model/ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolo11n.pb | imgsz, batch |
| TF Lite | tflite | yolo11n.tflite | imgsz, half, int8, batch |
| TF Edge TPU | edgetpu | yolo11n_edgetpu.tflite | imgsz |
| TF.js | tfjs | yolo11n_web_model/ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolo11n_paddle_model/ | imgsz, batch |
| NCNN | ncnn | yolo11n_ncnn_model/ | imgsz, half, batch |
到此为止,本文讲解的使用YOLO11在自己的数据集上进行简单的模型训练、预测与导出已经全部完成,关于预测部分并不详细,如果你想了解更多,可以参考我的另一篇文章链接附下。如果你有任何问题和需求可以通过私信联系我。
如果你想了解更多关于如何使用YOLO11模型进行预测,可以参考我的另一篇文章:
【YOLO11速通指南】本地快速部署及预测(目标检测+实例分割+姿态估计)![]() https://blog.csdn.net/2301_78753314/article/details/143943167
https://blog.csdn.net/2301_78753314/article/details/143943167
如果你对YOLOv5的单目深度估计感兴趣,可以参考我的另一篇文章:
【YOLO简单测距】单目测距——基于YOLOv5的单目深度估计算法的实现![]() https://blog.csdn.net/2301_78753314/article/details/140220033
https://blog.csdn.net/2301_78753314/article/details/140220033
如果你对YOLO11的安卓部署,可以参考我的另一篇文章:
【YOLO11安卓部署】10分钟快速高效的把YOLO11部署到安卓端![]() https://blog.csdn.net/2301_78753314/article/details/143966676
https://blog.csdn.net/2301_78753314/article/details/143966676

















 9123
9123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









