







简介
图像分割(Image Segmentation)是一种计算机视觉领域的技术,旨在将图像分成若干个特定的、具有语义意义性质的区域。图像分割可以用于许多领域,包括目标检测、图像编辑、医学图像分析等。它是由图像处理到图像分析的关键步骤。
发展史
- 传统方法:在早期计算机时代我们对图像分割采用的是传统方法,它基于灰度值的不连续和相似的性质对图像进行超像素分割。简单来说就是将不同的物体区域分开。
基于深度学习的方法:利用卷积神经网络,把每个像素都标注上与其对应的类别。
图像分割的三个任务等级有:语义分割(Semantic Aegmentation)、实例分割(Instance Segmentation)、全景分割(Panoptic Segmentation)。【当前讨论的图像分割一般泛指基于深度学习的分割方法,也称之为语义分割】
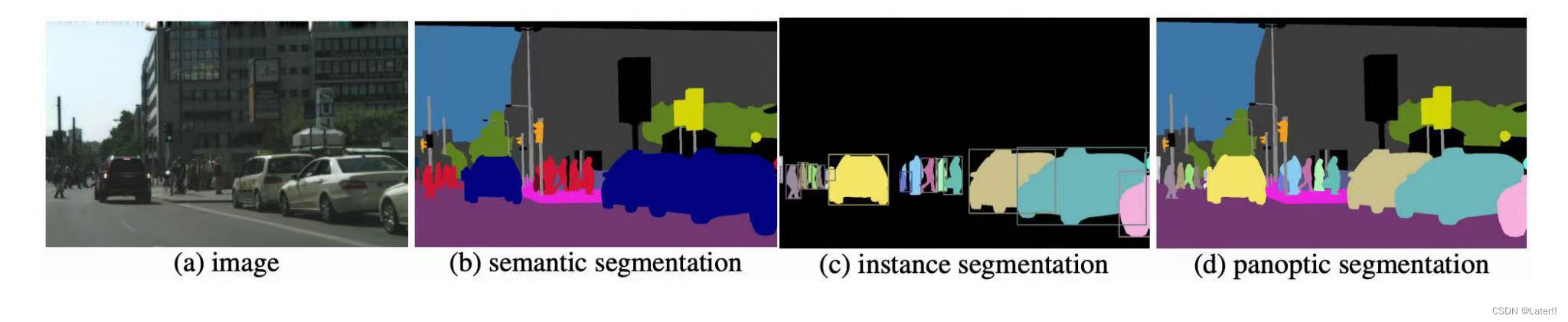
- (1)语义分割:语义分割的目的是把图像中的每个像素分为特定的语义类别,属于特定类别的像素仅被分类到该类别,而不考虑其他信息,例如:人、车、树、狗等这就是不同的类别。它与普通的图像分割任务不同,语义分割要求对图像中的每个像素进行细粒分类,以便我们能够准确的理解图像中的内容。语义分割在自动驾驶、医学图像分析、图像理解等领域具有重要的应用价值。
语义分割的方法:基于全卷积网络(FCN)、深度解码网络(DeepLab)、U-Net、图像分割神经网络(SegNet)、Mask R-CNN等。
(2)实例分割:实例分割根据“实例”而不是类别将像素分类,实例分割的目的是将图像中的目标检测出来,它不仅要对图像中的每个像素进行语义类别的分类,还要将同一类别的不同实例进行区分,并且对目标的每个像素分配类别标签以区分它们。实例分割能够对前景语义类别相同的不同实例进行区分。这种技术在物体检测、图像分析和医学图像处理等领域具有重要的应用,实现更精细的图像分析和理解。实例分割模型一般由三部分组成:图像输入、实例分割处理、分割结果输出。
实例分割的方法:Mask R-CNN、ShapeMask、全卷积实例分割(Fully Convolutional Instance Segmentation,FCIS)、PANet、YOLACT等。
(3)全景分割:全景分割是最新开发的分割任务,可以表示为语义分割和实例分割的组合,其中图像中对象的每个实例都被分离,并预测对象的身份。和实例分割的区别在于,将整个图像都进行分割。与实例分割不同,全景分割不需要将像素分配给特定的实例,而是将其分为不同的语义类别。全景分割在自动驾驶、机器人导航、视觉增强现实、医学影像分析、地球观测和遥感、图像编辑和艺术创造等领域都有应用,随着深度学习和计算机视觉的发展,全景分割在更多领域中的应用也会不断增加。
全景分割的方法:Fully Convolutional Network (FCN)、U-Net、DeepLab、Mask R-CNN、PANet等。
图像分割必要准备
图像分割常用数据集
PASCAL VOC数据集:该数据集包含了来自20个不同类别的物体的图片和对应的标注信息,如人、车、猫、狗等,同时还包含了大量的难以识别的背景图片。每张图像都包含一个 .xml 格式的标注文件,记录了图像中的目标类别、位置、大小等信息。同时,每个目标都有一个唯一的ID标识,可以方便地在多个图像中进行跟踪。Train + validation = 2913张。

Cityscapes数据集:一个用于城市场景理解的大规模数据,该数据集主要用于场景分析、车辆自主驾驶等方向的研究。每个图像都标注了精细的像素级别的分割标签,包含了19个不同的类别,如道路、人行道、建筑物、车辆、行人等。它还提供了一个真实的场景理解挑战,因为城市场景通常包含复杂的背景、遮挡、多样化的物体和不同的光照条件。Train + validation = 3475张。
CamVid数据集:一个广泛用于图像分割领域的数据集,包含了701个图像序列,每个图像序列都是由视频中连续帧截取得到的。这些序列涵盖了多种交通场景,如城市道路、人行道、建筑物、车辆、行人等。每个图像都标注了精细的像素级别的分割标签,包含了32个不同的类别,如道路、人行道、建筑物、车辆、行人等。Train + validation = 701张。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









