







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的交通路面障碍物目标检测系统
设计思路
一、课题背景与意义
在现代交通领域,随着车辆保有量的急剧增加和道路运输的日益繁忙,交通路面状况变得愈发复杂。交通路面障碍物作为影响交通安全的关键因素之一,对其进行准确检测成为亟待解决的问题。交通路面障碍物来源广泛。可能是因车辆故障而遗留在道路上的零部件,如轮胎、保险杠等;也可能是自然灾害导致的,如树枝、石块等掉落物;还包括一些非法丢弃在道路上的大型物品。这些障碍物的存在严重威胁着道路使用者的生命安全和车辆的正常行驶。减少路面障碍物可以使车辆行驶更加平稳和安全,降低因障碍物碰撞对车辆造成的损害,提高道路使用者的满意度。同时,也有利于延长道路基础设施的使用寿命,减少因交通事故和障碍物清理对道路的破坏。
二、算法理论原理
YOLOV5 模型是一个复杂且功能强大的目标检测模型,由 Input、Neck、Backbone 和 Prediction 四个部分构成。Input 作为数据入口为后续处理准备信息。Backbone 是特征提取关键部分,其新增的 Foucs 操作里切片操作至关重要且过程逐步变化,通过多种操作将原始图像转化为有代表性的高层次特征。Neck 的 FPN(自上而下) + PAN(自底向上)特征金字塔结构很精妙,FPN 用上采样传递和融合信息,使高低层特征互补,获取更准确预测结果图。Prediction 的两大组成部分 NMS 和 Bounding box 损失函数作用显著,Bounding box 中的 GIOU_Loss 函数衡量预测框与真实框差异指导训练,NMS 在预测结果处理阶段解决重合边框和筛选问题,得到准确结果。同时,模型基于基础锚框模拟预测框,若预测框与实际差异大,可通过改代码关闭自动锚功能,优化性能以适应不同场景和数据集特点。
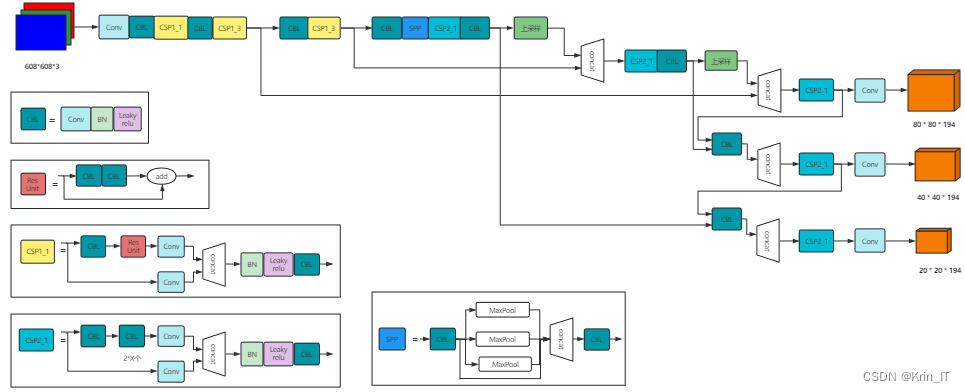
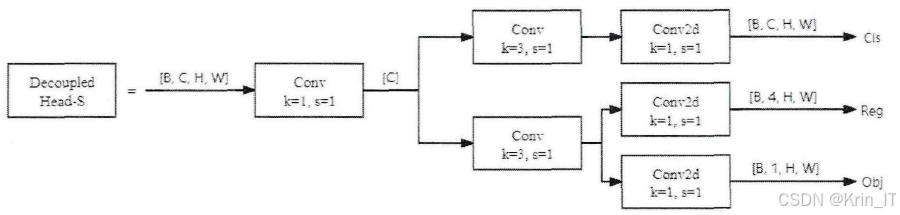
在目标检测领域,YOLOv5 虽高效准确但原始检测头有局限,其耦合结构在处理类别预测和位置回归时,难以挖掘两者潜在关系影响精度,于是引入解耦头成为提升性能的方向。解耦头将分类和回归任务分开,有独立分支,各自根据任务特点设计网络层和参数,避免相互干扰,从而能更好适应不同任务需求。引入解耦头有诸多优势,能提高检测精度,更精准地学习类别和位置特征,减少小目标和密集目标检测的误检、漏检;可增强模型泛化能力,适应不同场景和数据集,减少过拟合;还便于模型优化和扩展,可针对分支调整参数、添加模块等。不过实现过程中有挑战,参数调整需重新优化参数,可通过实验性搜索和自动化工具解决;训练效率方面,可共享卷积层、用多 GPU 并行训练和优化数据加载预处理来缓解。

引入解耦头后,模型的参数数量和复杂度增加,需要重新调整参数以达到最佳性能。这涉及到对每个分支的卷积核大小、层数、步长等参数的细致优化。为了解决这个问题,通常采用实验性的参数搜索方法,如在一定范围内逐步调整参数,并在验证集上评估模型性能,找到最优的参数组合。同时,可以利用一些自动化的超参数优化工具,如基于贝叶斯优化的算法,来加速参数搜索过程。解耦头的独立训练可能会导致训练时间增加,因为需要分别对分类和回归分支进行计算和更新。为了提高训练效率,可以采用一些技巧,如共享部分卷积层来减少计算量,或者使用多 GPU 并行训练技术。此外,优化训练数据的加载和预处理过程,也能在一定程度上缓解训练效率问题,确保模型在合理的时间内完成训练并达到较好的性能。
相关代码:
import torch
import torch.nn as nn
class DecoupledHead(nn.Module):
def __init__(self, num_classes, anchors_per_scale, in_channels):
super(DecoupledHead, self).__init__()
self.num_classes = num_classes
self.anchors_per_scale = anchors_per_scale
# 分类分支
self.classification_branch = self._build_branch(num_classes, anchors_per_scale, in_channels)
# 回归分支
self.regression_branch = self._build_branch(4, anchors_per_scale, in_channels)
def _build_branch(self, out_channels, anchors_per_scale, in_channels):
layers = []
for _ in range(len(in_channels)):
layers.append(nn.Conv2d(in_channels=in_channels.pop(), out_channels=out_channels * anchors_per_scale, kernel_size=3, padding=1))
layers.append(nn.BatchNorm2d(num_features=out_channels * anchors_per_scale))
layers.append(nn.ReLU())
return nn.Sequential(*layers)
def forward(self, x):
classification_outputs = []
regression_outputs = []
for feature_map in x:
classification_outputs.append(self.classification_branch(feature_map))
regression_outputs.append(self.regression_branch(feature_map))
return classification_outputs, regression_outputs三、检测的实现
3.1 数据集
在制作数据集时,先确定采集地点和场景,在城市道路的主干道不同时段、不同车道,十字路口各方向和俯瞰视角(若有条件),高架桥考虑天气、隧道留意光线的情况下采集;高速公路在路段中间考虑车速和光照、服务区进出口及其周边采集;乡村公路体现环境特征、桥梁和涵洞关注杂物和掉落物的情况采集。然后考虑环境因素,晴天不同时段、雨天不同雨强、雾天不同浓度、雪天不同雪量和融化阶段拍摄,光照方面除白天不同时段还在夜晚针对路灯和车辆大灯不同情况拍摄。最后使用高清摄像机或高像素相机,以特定手持角度稳定拍摄,对视频按帧率抽关键帧作图像数据。
使用 Labelimg 标注数据集时,先做好图像整理与熟悉标注工具的准备工作,然后加载图像,仔细识别障碍物并精确绘制边界框,再准确标注类别,过程中要处理光照不均、雨天、遮挡等复杂情况,完成一张图像标注后妥善保存标注信息,标注一定量后还需定期检查复查,保证边界框和类别标注准确,整个过程极具挑战且对保证数据集质量意义重大。

3.2 实验及结果分析
模型训练先进行数据准备,包括加载划分好的训练、验证和测试集,对输入数据进行归一化或标准化处理。同时要依据目标检测任务和数据集特点选择合适模型架构,并对模型参数初始化,还要针对任务定义包含分类和定位损失的损失函数及选择合适优化算法。
import torch
import torchvision
import torchvision.transforms as transforms
# 定义数据预处理操作
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载训练集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
# 加载验证集
validset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
validloader = torch.utils.data.DataLoader(validset, batch_size=4,
shuffle=False, num_workers=2)训练过程包括前向传播,即将训练样本输入模型得预测结果;计算损失,根据预测和真实标签算损失值;反向传播,利用损失值计算参数梯度;参数更新,用优化算法依梯度调整参数。重复这些步骤对训练集多次迭代训练。
import torch.nn as nn
import torch.nn.functional as F
# 定义简单卷积神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# 定义损失函数(交叉熵损失)和优化算法(随机梯度下降)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)训练中要在验证集评估模型,计算准确率、召回率、mAP 等指标,据此判断模型是否过拟合或欠拟合,调整学习率、批大小、模型复杂度等超参数,保存验证集上性能最佳的模型用于测试集评估和实际应用。
相关代码如下:
# 在验证集上评估模型(这里只是简单示例,计算准确率)
correct = 0
total = 0
with torch.no_grad():
for data in validloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct / total}%')实现效果图样例
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









