






 本文围绕基于Python的APP用户行为分析系统展开。介绍了课题背景与意义,阐述算法理论原理,包括特征量分布和中心性统计特征。还讲述检测实现,自制APP用户行为数据集,并进行实验分析,如网络节点度分布、社团结构等。
本文围绕基于Python的APP用户行为分析系统展开。介绍了课题背景与意义,阐述算法理论原理,包括特征量分布和中心性统计特征。还讲述检测实现,自制APP用户行为数据集,并进行实验分析,如网络节点度分布、社团结构等。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于python的APP用户行为分析系统
设计思路
一、课题背景与意义
随着移动互联网的快速发展,APP已成为人们日常生活中不可或缺的一部分。用户在使用APP时产生的行为数据蕴含着丰富的信息,对于理解用户习惯、优化产品设计和提升用户体验具有重要意义。基于Python的APP用户行为分析系统旨在通过收集、处理和分析用户行为数据,揭示用户行为的规律和趋势,为企业和开发者提供有力的数据支持。该系统的研究与实现,有助于推动移动互联网行业的持续发展和创新。
二、算法理论原理
2.1 特征量分布
在基于Python的APP用户行为分析系统中,特征量的分布起着关键作用。通过分析特征量的分布,可以了解用户行为模式、个性化推荐、异常检测和风险预测,以及用户留存和流失分析。Python的数据处理和分析库以及机器学习框架提供了丰富的工具和算法,使得特征提取、工程和分析变得高效和便捷。基于特征量分布的分析和应用,可以优化用户体验、提升产品价值,并采取相应的措施来改善用户满意度和业务成果。
基于特征量的分布,可以将用户进行分类或群体划分,以便更好地提供个性化的推荐和服务。例如,根据用户的行为特征,可以将用户分为活跃用户、潜在用户、流失用户等不同群体,并针对每个群体进行个性化的推荐和营销策略。特征量的分布可以帮助预测用户的留存和流失情况。通过分析用户在不同时间段内的行为特征和变化趋势,可以识别到用户可能面临的流失风险,并采取相应的措施提高用户留存率。
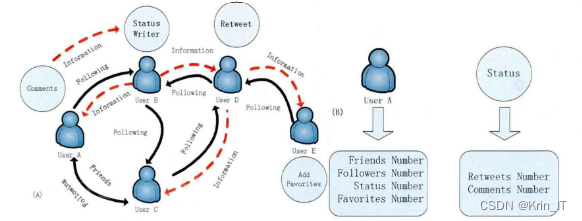
基于用户兴趣和交互行为影响的模型是利用用户历史行为数据和其他相关信息进行学习和预测的机器学习模型。这些模型可以根据用户的行为模式和关联来推断和预测用户的兴趣和行为,从而实现个性化推荐、广告定向投放和搜索排序等功能。常见的模型包括协同过滤、决策树、隐语义模型和深度学习模型,它们通过分析用户的兴趣和交互行为,提供个性化的推荐和体验,提高用户满意度和业务效果。在建模过程中,需要考虑数据质量和隐私保护,并进行模型评估和调优,以提高准确性和效果。
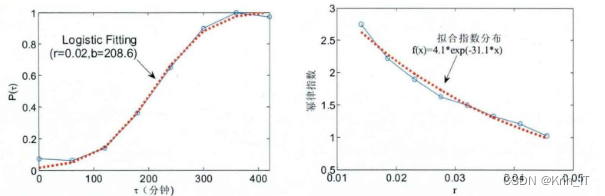
基于用户兴趣衰减服从 logistic 函数的模型是一种描述用户兴趣强度随时间衰减的数学模型。该模型假设用户对内容或物品的兴趣随着时间的推移逐渐减弱,并利用 logistic 函数来描述衰减过程。通过该模型,可以预测用户在不同时间点对内容的兴趣程度,从而实现更准确的个性化推荐。模型的参数需要根据实际情况和数据进行调整和优化,并进行数据分析和模型评估,以确保模型的准确性和实用性。
2.2 中心性统计特征
中心性指标可以刻画节点在网络中的位置和重要性,从而描述网络中心节点的拓扑结构和特性。其中,度中心性是一种常用的中心性指标,用于衡量节点与其他节点之间的连接程度。节点的度中心性越高,意味着它在网络中具有更多的邻居节点和连接路径,可能处于网络的中心位置。此外,其他中心性指标如介数中心性、接近中心性和特征向量中心性等也可以用来描述节点在网络中的中心性和拓扑结构。通过对这些中心性指标的刻画和分析,我们可以深入理解网络中心节点的重要性、信息传播能力以及其在整体网络拓扑结构中的角色和特征。
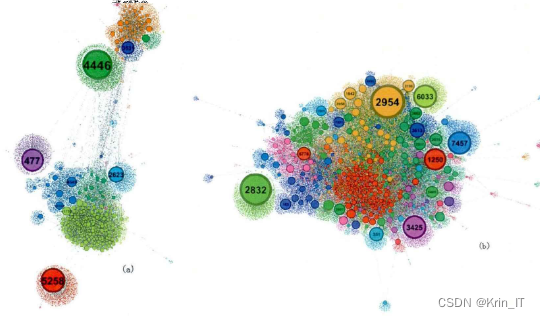
节点度和核数的可视化对于网络拓扑结构分析至关重要。通过观察节点度和核数的可视化图形,我们可以了解节点之间的连接情况、社区结构和整体形态。此外,可视化还有助于识别网络中的中心节点,分析社区结构,并检测异常节点。这些可视化结果揭示了网络节点的重要性、交互模式和组织结构,为我们深入理解网络提供了有价值的洞察。
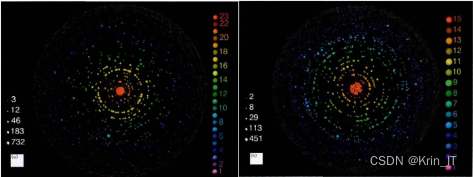
使用工具对两个网络的社区结构进行了可视化分析,将社区按照颜色进行分类,并在图中显示节点的大小与节点的度值成正比。通过观察图形可以看出,这两个网络都具有明显的社团结构,一些社团由一个度值较大的节点和众多度为小的节点构成,而另一些社团则由多个度值较大的节点和众多度小的节点构成。在这两个网络中,存在一些度值很大但并不处于整体网络中心的节点,这些节点与其周围的节点同处于网络的边缘,并且与其他社区连接的边关系较少。此外,这两个网络中也存在度值虽然较小但处于整体网络中心的节点,这些节点与其周围的节点共同处于网络的中心,与其他多个社区相连接的边关系较多。总的来说,通过可视化分析,我们可以直观地研究网络社区结构与节点中心性的关系,从中获得对网络拓扑特征的洞察。
相关代码示例:
import networkx as nx
# 创建一个示例图形(可以根据您的数据集创建网络图)
G = nx.Graph()
G.add_edges_from([(1, 2), (1, 3), (2, 3), (2, 4), (3, 4)])
# 计算度中心性
degree_centrality = nx.degree_centrality(G)
print("Degree Centrality:")
for node, centrality in degree_centrality.items():
print(f"Node {node}: {centrality}")
# 计算介数中心性
betweenness_centrality = nx.betweenness_centrality(G)
print("Betweenness Centrality:")
for node, centrality in betweenness_centrality.items():
print(f"Node {node}: {centrality}")三、检测的实现
3.1 数据集
现有的公开数据集并不能完全满足我的研究需求。为了提高系统的针对性和实用性,我决定自己收集一套真实的APP用户行为数据集。我通过设计数据收集方案,利用APP内置的日志记录功能,收集了用户在使用APP过程中产生的各种行为数据,包括点击、滑动、停留时间等信息。然后对这些数据进行清洗、整理和格式化处理,构建了一个包含丰富用户行为信息的数据集。这个数据集不仅覆盖了多个用户群体和时间段的行为记录,还包含了各种使用场景和交互方式的样本。通过这个自制的数据集,我能够更真实地反映用户行为的特点和规律,为系统的分析功能提供更准确、可靠的数据支持。我相信这个自制的数据集将为APP用户行为分析领域的研究提供有力的支持,并为该领域的发展做出积极贡献。
3.2 实验分析
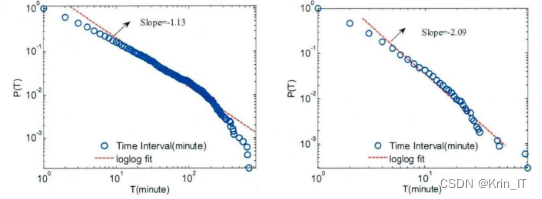
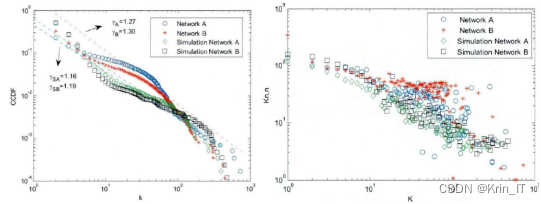
两个真实微博用户的双向关注网络在双对数坐标中展示出节点度的累积分布曲线比较平缓,并且都呈现出分段幂律形态。这与无标度网络中节点度的直线幂律分布形态存在一定的区别,表明二者在网络生成机制上也有所不同。通过最小二乘法拟合节点度的分布,得到幂律指数分别为α和β,拟合优度为R1和R2。幂律指数与之前真实社会网络的节点度分布情况吻合,即α约为2.5-3.0。两个仿真网络与真实网络具有相似的度分布特征,它们的累积度分布都近似服从幂律分布,幂律指数相近,并且都存在分段现象。
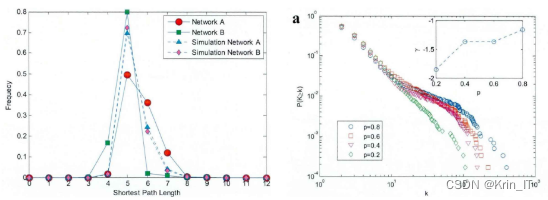
初期的社团都是由少量节点和边组成,之后会逐渐吸引新的节点加入。新加入的节点更愿意加入规模更大的社团。不同社团吸引新节点数量不同导致各社团的规模存在显著差异。根据仿真网络中全部节点和边关系数据,采用算法进行社团结构划分,然后利用工具绘制整个网络。富人俱乐部现象在网络中普遍存在,表现为具有大量连接的节点倾向于相互连接,形成密集的子网。富人俱乐部系数用于描述这种现象,并通过平均路径长度和直径来度量网络的结构特征。两个真实网络和仿真网络都展现出类似的富人俱乐部特征,其中社团的规模差异显著,社团内部的用户关注关系密切,而社团之间的关注关系相对疏远。
相关代码示例:
import pandas as pd
data = pd.read_csv('user_data.csv')
print(data.head())
user_tweet_count = data.groupby('user_id')['tweet_id'].count()
print(user_tweet_count)
user_avg_likes = data.groupby('user_id')['likes'].mean()
user_avg_retweets = data.groupby('user_id')['retweets'].mean()
print(user_avg_likes)
print(user_avg_retweets)
top_users = user_tweet_count.nlargest(10)
print(top_users)
import matplotlib.pyplot as plt
plt.hist(user_tweet_count, bins=20)
plt.xlabel('Number of Tweets')
plt.ylabel('Number of Users')
plt.title('Distribution of User Tweet Counts')
plt.show()实现效果图样例:




创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









