







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的野生花卉识别分类算法系统
设计思路
一、课题背景与意义
野生花卉的识别和分类在植物学、生态学和环境保护等领域具有重要的研究意义和实际应用价值。然而,由于野生花卉种类繁多且形态差异大,传统的人工识别方法难以满足快速、准确的分类需求。基于深度学习的图像识别和分类技术为野生花卉识别带来了新的机遇。这种技术能够自动学习和提取图像特征,并通过训练模型实现对野生花卉进行准确的分类和识别。因此,开发一种基于深度学习的野生花卉识别分类算法系统,将为植物研究、野生生物保护和生态监测等领域提供强有力的工具和方法。
二、算法理论原理
2.1 卷积神经网络
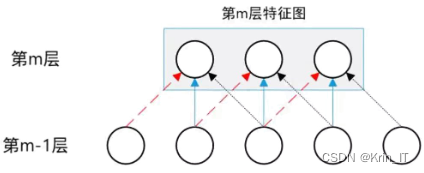
卷积神经网络(CNN)是基于传统神经网络发展而来的一种变种,具有局部连接和权值共享两大特性。局部连接意味着卷积核只与前一层的部分节点相连,从局部区域提取特征,这个连接区域被称为局部感受野(Receptive Field)。与全连接方式相比,局部连接可以更好地捕捉图像中的局部特征。这种概念源自于动物视觉皮层细胞的工作原理,动物的视觉神经元只对输入空间的特定子区域做出响应。在计算机视觉中,相邻像素之间存在较强的相关性,而远离的像素之间联系较弱。因此,通过局部连接的形式,底层神经元可以接收图像的局部信息,然后在高层对这些信息进行融合,以增强图像的表征能力。
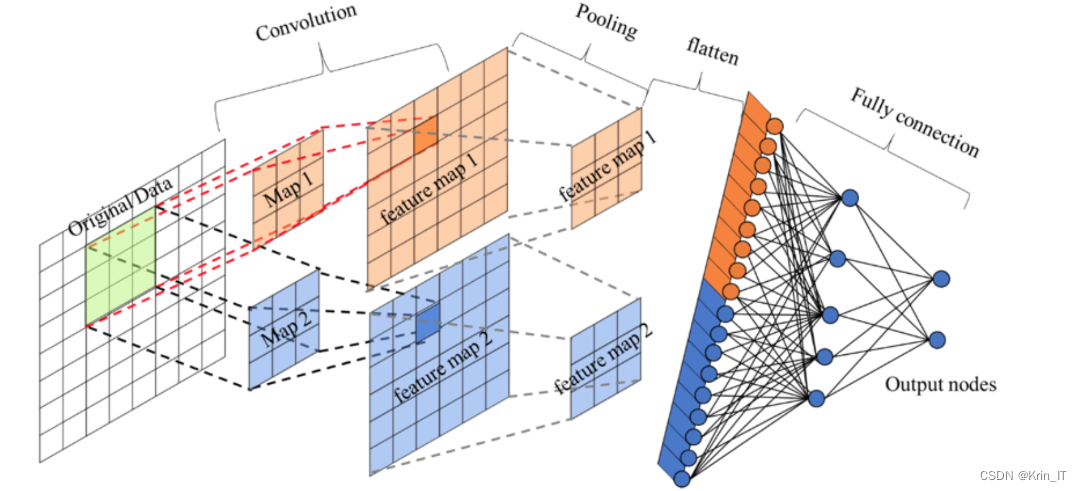
权值共享意味着不同的神经元可以使用相同的卷积核。图像的底层特征与特征的位置无关,因此采用同一卷积核能够检测到不同位置的所有特征。这使得CNN对于物体的平移、缩放、倾斜或其他变形具有不变性。通过使用多个卷积核提取多种特征,CNN可以得到多个特征映射。这种参数共享的机制大大减少了网络的参数量,避免了过拟合问题,并降低了网络的优化难度。
卷积运算是卷积神经网络的基本操作,通过卷积核与特征图的局部连接实现特征提取。卷积核代表不同的图像模式,可以检测到不同层次的特征,从低级特征如边缘到高级特征如纹理。卷积核的尺寸决定了其对像素空间的响应范围,较大的尺寸可以捕捉更大的图像区域。卷积核中的数值通过反向传播算法学习获得。
卷积核与特征图进行卷积运算,得到不同的图像特征响应。通常采用多个卷积核来提取多种特征,每个卷积核与上一层输出的通道数相同。更多的卷积核能够提取更丰富的图像信息,理解输入图像的全貌。卷积层由多个卷积核组成,通过卷积运算提取上一层输出特征图的特征。深层次的卷积层提取的特征更加抽象,蕴含更丰富的信息,能够学习图像的内在表示。卷积神经网络的构建是逐层进行特征提取的过程,从低层到高层逐渐提取更抽象的特征。
批标准化层(BN)是一种网络优化方法,通过对网络的中间层进行批量标准化,解决了收敛速度慢和梯度消失的问题。BN层可以使得网络训练速度更快、泛化能力更强,并减少调试超参数的复杂性。
2.2 正则化表达
Dropout是一种常用的正则化技术,用于减少神经网络的过拟合问题。在训练过程中,Dropout随机地将一部分神经元(节点)的输出置为零,即将其失活。这样可以使得网络不依赖于某些特定的神经元,强制网络学习到更加鲁棒和泛化的特征。Dropout策略在每次训练迭代时,以一定的概率(通常是0.5)随机地选择一部分神经元进行失活。这意味着该迭代期间,这些神经元的输出在前向传播和反向传播过程中都被忽略。由于每次迭代都会随机选择不同的神经元失活,相当于通过训练多个不同的神经网络,从而获得了一种集成学习的效果。
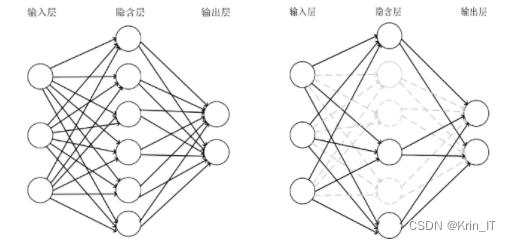
Dropout的主要作用是降低神经网络的复杂性,减少神经元之间的相互依赖,增强网络的泛化能力。通过随机失活一部分神经元,Dropout可以防止过拟合,减少网络对于特定样本的敏感性,提高模型的鲁棒性。此外,Dropout还可以减少网络中神经元之间的协同适应,促使网络学习到更加独立和有用的特征表示。
在测试阶段,为了保持网络的稳定性,一般会关闭Dropout操作,但需要将训练时失活的神经元的输出按比例缩放。这是因为在训练过程中,由于部分神经元失活,每个神经元的输出会被缩小,为了保持输出的期望值不变,需要进行缩放。
三、检测的实现
3.1 数据集
由于网络上没有现有的合适的野生花卉数据集,我决定自己通过相机拍摄和网络爬取两种方式,收集了大量具有多样野生花卉的图像样本来构建一个全新的数据集。通过编写网络爬虫程序,我能够从各种在线图像库、植物数据库和社交媒体上获取具有多样特征的野生花卉图像,并对这些图像进行标注和分类。这个自制的数据集包含了各种野生花卉的图像样本,覆盖了不同种类、颜色和形态的花卉。

3.2 实验环境搭建
实验环境使用Windows操作系统,并利用Python作为主要的编程语言进行算法和模型的实现。使用PyTorch作为深度学习框架,构建和训练神经网络模型。借助Pandas等库,完成数据的加载、处理和转换。这样的实验环境提供了一个方便和高效的平台,用于开发和测试算法系统。
3.3 实验及结果分析
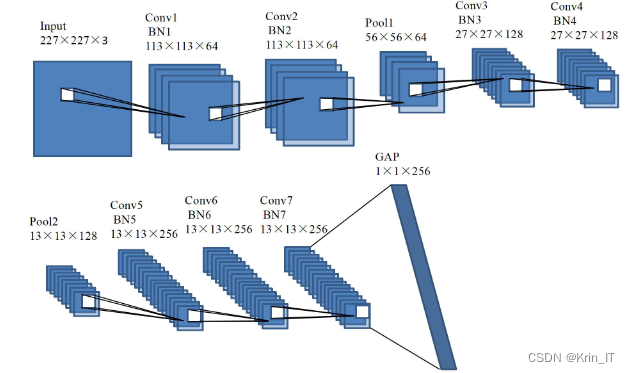
改进后的网络模型包含7个卷积层、7个批标准化层、2个池化层和1个全局平均池化层。具体参数设置如下:
- 输入层:输入为三通道彩色图像,进行归一化和数据增强,调整为227×227×3的尺寸。
- Conv1、BN1:Conv1是一个具有64个3×3卷积核的卷积层,步长为2,填充方式为'Valid'。学习的权重参数数量为(3×3×3+1)×64=1792,输出特征图的大小为113×113×64。BN1层用于对批量样本的特征图进行标准化,然后采用ReLU激活函数。
- Conv2:Conv2是一个具有64个3×3卷积核的卷积层,填充方式为'Same'。学习的权重参数数量为(3×3×64+1)×64=36928,输出特征图的大小为113×113×64。Conv2层后连接BN_ReLU2层。
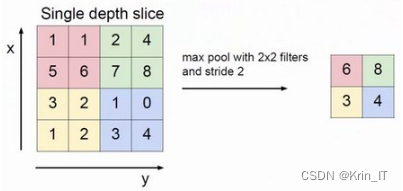
- Pool1:Pool1是一个最大池化层,过滤器大小为3×3,步长为2,填充方式为'Valid'。输出特征图的大小为56×56×64。
- Conv3:Conv3是一个具有128个3×3卷积核的卷积层,步长为2,填充方式为'Valid'。学习的权重参数数量为(3×3×64+1)×128=73856,输出特征图的大小为27×27×128。Conv3层后连接BN_ReLU3层。
- Conv4:Conv4是一个具有128个3×3卷积核的卷积层,填充方式为'Same'。学习的权重参数数量为(3×3×128+1)×128=147584,输出特征图的大小为27×27×128。Conv4层后连接BN_ReLU4层。
- Pool2:Pool2是一个最大池化层,过滤器大小为3×3,步长为2,填充方式为'Valid'。输出特征图的大小为13×13×128。
- Conv5、Conv6、Conv7:这三个卷积层均具有256个3×3卷积核,填充方式为'Same'。Conv5需要学习的权重参数数量为(3×3×128+1)×256=295168,输出特征图的大小为13×13×256。Conv6和Conv7需要学习的权重参数数量均为(3×3×256+1)×256=590080,输出特征图的大小均为13×13×256。这三个卷积层后连接BN_ReLU层进行标准化和非线性激活。
- GAP:GAP是一个全局平均池化层,用于计算输入特征图所有像素的均值,代替全连接层。输出特征图的大小为1×1×256。
通过使用传统机器学习算法中的支持向量机(SVM)和随机森林分类器来替代卷积神经网络(CNN)中的Softmax层,可以进一步提升对于小样本、高维数据的分类性能,尤其是在数据量较少、容易产生过拟合现象的情况下。具体的分类步骤包括以下几个阶段:
- 对花卉训练集进行数据增强,并利用该数据集对设计的卷积神经网络进行训练,然后保存网络模型。
- 加载保存的模型,并提取训练集和测试集在网络全局平均池化层的特征向量,并为它们创建相应的标签。
- 使用训练集的特征向量来训练支持向量机和随机森林分类器。通过网格搜索交叉验证法确定支持向量机和随机森林分类器的最佳参数。
- 将测试集的特征向量输入到得到最优参数的支持向量机和随机森林分类器中,进行分类并比较两种分类器的精度。
相关代码示例:
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
# Step 1: Train the CNN model and save it
# Assuming you have trained and saved your CNN model
cnn_model = ... # Your trained CNN model
# Step 2: Load the model and extract features
# Assuming you have training and testing data with labels
train_features = cnn_model.predict(train_data) # Extract features from the CNN model for training data
test_features = cnn_model.predict(test_data) # Extract features from the CNN model for testing data
train_labels = train_labels # Assuming you have training labels
test_labels = test_labels # Assuming you have testing labels
# Step 3: Train the SVM classifier
svm = SVC()
svm_param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
svm_grid_search = GridSearchCV(svm, svm_param_grid, cv=5)
svm_grid_search.fit(train_features, train_labels)
svm_best_model = svm_grid_search.best_estimator_
# Step 4: Train the Random Forest classifier
rf = RandomForestClassifier()
rf_param_grid = {'n_estimators': [100, 200, 300], 'max_depth': [None, 5, 10]}
rf_grid_search = GridSearchCV(rf, rf_param_grid, cv=5)
rf_grid_search.fit(train_features, train_labels)
rf_best_model = rf_grid_search.best_estimator_
# Step 5: Evaluate the classifiers
svm_predictions = svm_best_model.predict(test_features)
svm_accuracy = accuracy_score(test_labels, svm_predictions)
rf_predictions = rf_best_model.predict(test_features)
rf_accuracy = accuracy_score(test_labels, rf_predictions)
print("SVM Accuracy:", svm_accuracy)
print("Random Forest Accuracy:", rf_accuracy)实现效果图样例:




创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









