







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的生活垃圾识别与分类系统
设计思路
一、课题背景与意义
随着城市化进程的不断推进,生活垃圾的处理和分类成为一个日益重要的问题。传统的垃圾分类方法需要人工参与,耗时耗力且容易出错。而基于深度学习的生活垃圾识别与分类系统能够通过图像识别和分类技术,实现对生活垃圾的自动识别和分类。这种系统具有高效、准确和可扩展性的优势,能够有效地提高垃圾分类的效率和准确度。此外,生活垃圾分类对环境保护和资源回收利用具有重要意义,通过建立基于深度学习的生活垃圾识别与分类系统,可以促进垃圾分类的智能化和自动化,为建设可持续发展的城市环境做出贡献。
二、算法理论原理
2.1 卷积神经网络
InceptionNet是一种深度卷积神经网络模型,通过增加网络的深度和宽度来提高模型的性能。它采用了Inception模块作为网络的基本单元,该模块通过堆叠不同尺寸的卷积核和分支网络来输出更大的通道,既提高了模型的表达能力,又减少了参数数量。通过使用1×1卷积网络进行特征组织和非线性变换,Inception模块能够高效地提取特征,并适应不同尺度的信息需求。这种设计方式显著提升了网络的性能,同时有效避免了过拟合的问题。
此外,InceptionNet还引入了批归一化(Batch Normalization,BN)结构,该结构可以提高模型的训练速度和分类精度。BN通过将每个批次数据的输出规范化到正态分布,减少了dropout并优化网络结构。它提高了模型的准确性、稳定性和可靠性,并需要相应的超参数调整和数据处理。
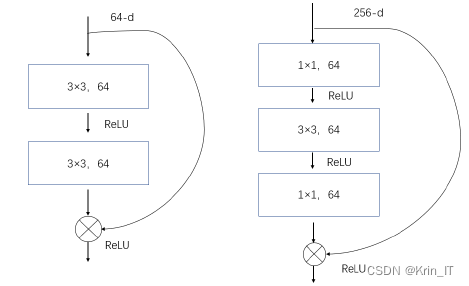
在传统的深度卷积神经网络中,随着网络层数的增加,优化的效果会逐渐减弱,准确性也会下降。这是由于网络深度增加导致了梯度爆炸和梯度消失等问题。为了解决这个问题,ResNet引入了残差连接的概念。残差连接的思想是将前一层的输出直接与后面层的输入相加,形成一个"跳跃连接"。这样可以通过直接传递梯度来解决梯度消失的问题,并且允许网络学习残差函数,即前一层输出与后一层输入之间的差异。通过这种方式,即使网络层数很深,信息也能够更加顺利地传递,让网络更容易训练。ResNet中的基本模块分为两种:BasicBlock和BottleNeck。BasicBlock适用于浅层网络(少于50层),而BottleNeck适用于深层网络(50层以上)。BottleNeck通过减少参数数量,同时保持较高的准确性,实现了更快的收敛和更高的计算效率。
DenseNet是一种基于注意力机制和卷积神经网络的垃圾识别与分类模型。它通过密集连接的方式将每一层与之前所有层相连,实现了高效的特征传递和重用。与ResNet相比,DenseNet能够以更少的参数和更低的计算成本获得更好的性能。它的设计理念允许参数共享和功能重复使用,提高了模型的效率。过渡模块解决了特征图尺寸不一致的问题,确保特征传递的一致性。
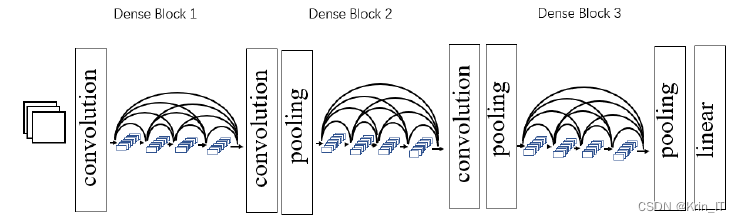
DenseNet是一种基于密集连接的卷积神经网络模型,用于垃圾识别与分类。它具有注意力机制和卷积神经网络的特点。在DenseBlock中,每一层采用BN+ReLU激活函数+3x3卷积的结构,并输出k个特征图,其中k是增长因子。为了减少计算量,可以在DenseBlock内部使用1x1卷积来减少特征数量。Transition层通过1x1卷积和2x2平均池化层合并相邻的DenseBlock,并可通过压缩因子θ进一步压缩模型。DenseNet通过密集连接和参数共享实现高效的特征传递和重用,具有较少的参数和低计算成本的优势,适用于垃圾识别与分类任务。
2.2 目标检测算法
YOLOv7是一种快速而高效的单阶段目标检测算法,基于深度神经网络。其研究成果包括对网络体系结构的重参数化、标记分配方法的改进、以及引入了高效的ELAN网络架构。YOLOv7还提出了带辅助头的训练方法,通过放弃低训练成本来提升模型精度,并且不会延长推理时间。
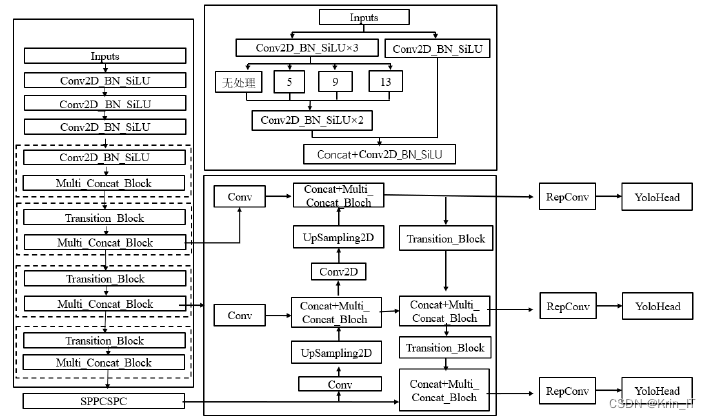
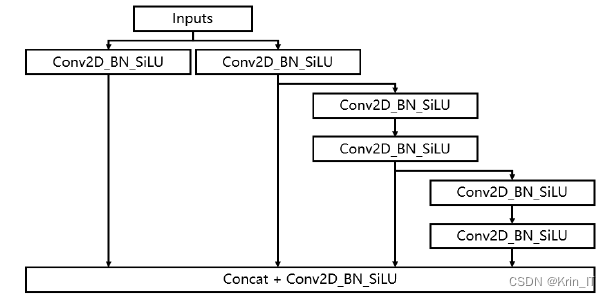
主干提取网络在YOLOv7中的功能是对输入的图像进行特征提取。首先,输入图像被缩放到大小为640x640x3。然后,通过一系列的卷积、标准化和激活函数操作对图像进行特征提取。在特征提取过程中,图像的高度和宽度不断压缩,通道数逐渐扩张。主干提取网络中包括一些特殊模块,如Multi_Concat_Block(多分枝堆叠模块)和Transition_Block。在Multi_Concat_Block中,对输入的特征层进行多次卷积、标准化和激活函数操作,其中一个分支再进行分支和特征提取,最后将分支结果堆叠并进行卷积、标准化和激活函数操作。Transition_Block是一个过渡模块,对输入的特征层进行分支,一个分支通过最大池化操作后进行下采样,另一个分支通过卷积、标准化和激活函数进行下采样,最后将两个分支的输出结果堆叠,从而压缩输入特征的尺寸。经过主干提取网络后,会得到三个有效的特征层,即stage 3、stage 4和stage 5。主干提取网络的作用是提取图像的有用特征,为后续目标检测任务提供输入。
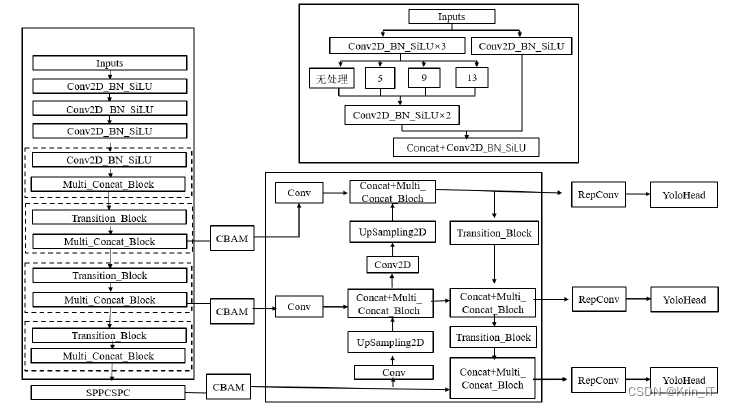
加强特征提取网络在YOLOv7中采用了CBAM注意力机制模块来进一步提升网络的训练效果。CBAM注意力机制模块包括通道注意力机制模块和空间注意力模块,用于学习重要的特征并增强它们的表示能力。利用CBAM注意力机制模块,加强特征提取网络可以在特征提取的过程中更好地捕捉关键特征,并提升网络的训练效果。这有助于改善目标检测的准确性和性能。
在加强特征提取网络的过程中,在三个卷积输出位置分别加入了CBAM注意力机制模块。这些位置可能是指20x20x1024、40x40x1024和80x80x256的特征层。通过通道注意力机制模块,网络可以自动学习每个通道的重要性权重,从而突出关键的特征通道。通过空间注意力模块,网络可以自动学习每个空间位置的重要性权重,以强调关键的空间信息。
三、检测的实现
3.1 数据集
由于网络上缺乏现有的合适数据集,我决定利用网络爬取的方式构建一个全新的生活垃圾数据集。通过搜索和收集各种类型的垃圾数据,包括水瓶、包装盒等,涵盖了不同环境、天气的情况。通过网络爬虫技术自动从公开数据源和相关数据库中获取信号样本,并进行整理和标注。这个自制数据集包含了大量的真实信号数据,可以用于生活垃圾检测算法的训练和评估。
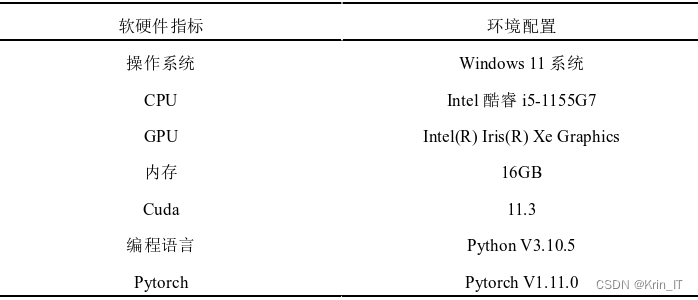
3.2 实验环境搭建
3.3 实验及结果分析
生活垃圾识别与分类系统的设计思路如下:
- 数据收集和预处理:首先,需要收集包含不同类型的生活垃圾的数据集。数据集应涵盖各种常见的生活垃圾类别,如可回收物、有害垃圾、厨余垃圾和其他垃圾等。收集的数据需要进行预处理,包括图像标准化、图像增强和数据平衡等,以确保数据的一致性和质量。
- 深度学习模型选择:选择适合生活垃圾识别与分类任务的深度学习模型。常用的模型包括卷积神经网络(CNN)、预训练的模型(如ResNet、Inception等)以及目标检测模型(如YOLO、Faster R-CNN等)。根据任务需求和计算资源,选择合适的模型架构。
- 模型训练和优化:使用预处理后的数据集对深度学习模型进行训练。训练过程中,可以采用迁移学习技术,将预训练的模型作为初始权重,以加快模型的收敛速度和提高准确性。同时,通过调整学习率、批次大小和优化器等超参数,进行模型的优化和调优。
- 数据增强和正则化:为了增加数据的多样性和模型的泛化能力,可以采用数据增强技术,如随机裁剪、翻转、旋转和颜色变换等。此外,还可以应用正则化技术,如权重衰减和Dropout等,以减少过拟合现象,提高模型的鲁棒性。
- 模型评估和调整:使用预留的测试集对训练好的模型进行评估。通过计算准确率、召回率、F1分数等指标,评估模型的性能。根据评估结果,可以进行模型的调整和改进,包括调整阈值、增加训练数据、调整模型架构等,以提高分类准确性和性能。
相关代码示例:
class SpatialAttention(nn.Module):
def __init__(self):
super(SpatialAttention, self).__init__()
self.conv = nn.Conv2d(2, 1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.conv(out)
out = self.sigmoid(out)
return out * x
class EnhancedFeatureExtraction(nn.Module):
def __init__(self, in_channels):
super(EnhancedFeatureExtraction, self).__init__()
self.sppcspc = SPPCSPC(in_channels)
self.fusion = Fusion(in_channels)
self.multi_concat_block = Multi_Concat_Block(in_channels)
self.transition_block = Transition_Block(in_channels)
def forward(self, x):
x = self.sppcspc(x)
x = self.fusion(x)
x = self.multi_concat_block(x)
x = self.transition_block(x)
x = self.multi_concat_block(x)
x = self.transition_block(x)
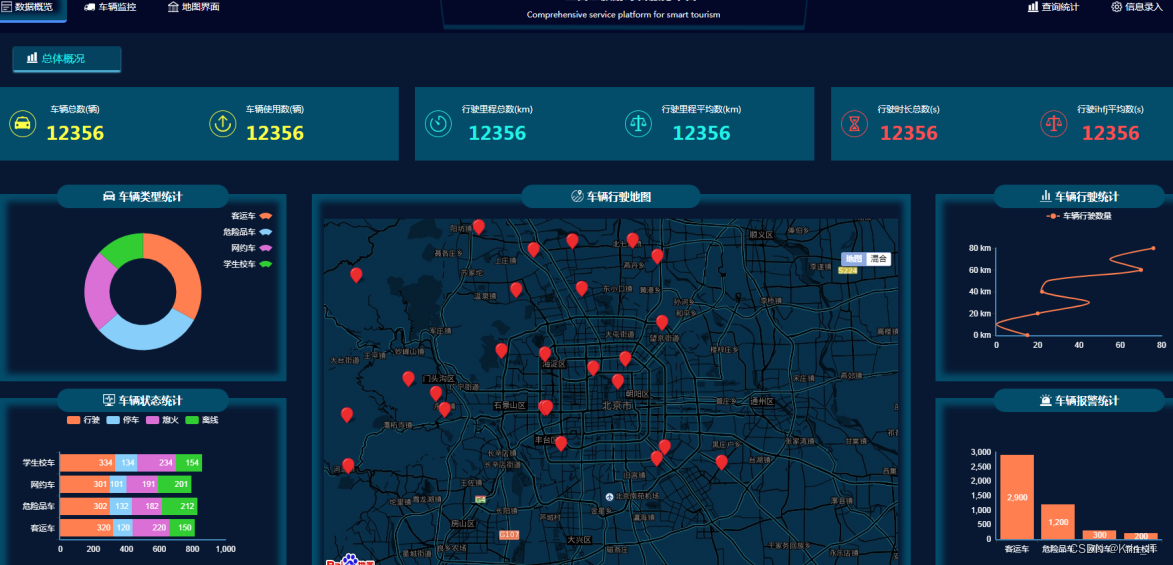
return x实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









