







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的驾驶员疲劳状态监测
设计思路
一、课题背景与意义
疲劳驾驶是造成交通事故的重要因素之一,严重威胁着驾驶员的安全和道路交通的顺畅。随着智能交通系统的发展,基于人脸识别技术的疲劳驾驶检测系统应运而生。通过对驾驶员面部特征的实时监测,系统能够识别出疲劳状态并及时发出警报,从而有效降低因疲劳驾驶引发的交通事故风险。传统的疲劳检测方法多依赖于驾驶员自我评估或简单的生理参数监测,准确性和实时性均有限。而结合深度学习的人脸识别技术,可以精准捕捉驾驶员的面部特征变化,提升疲劳检测的准确性和实时性。
二、算法理论原理
2.1 卷积神经网络
人工神经网络是一种模拟生物神经系统的计算模型,由大量简单的人工神经元相互连接而成。通过学习从输入到输出的映射关系,能够解决复杂的模式识别和预测问题。神经网络在模拟大脑时体现在两个方面:一是通过从外界环境中接收信息获取知识;二是内部神经元的连接强度,即突触权值,用于存储和记忆这些知识。最早的神经网络模型是感知机,用于解决模式分类问题。
卷积神经网络工作过程是利用卷积层进行图像识别,首先输入经过规则化的图像,将图像分解为一系列有重叠的像素块,输入到一个简单的单层神经网络中,保持权重不变。这一步将像素块转化为矩阵,输出值排成矩阵,以数据形式表示图像中每个区域的内容,然后通过卷积操作提取特征。卷积操作是指卷积核在输入数据上滑动并与其进行逐点相乘,求和生成新的特征图,通过激活函数对卷积操作后的特征图进行非线性变换,增强网络的表达能力,池化操作对特征图进行下采样,减小特征图的维度,同时保留主要特征,将多个卷积层、激活层和池化层堆叠起来,形成深度卷积神经网络,以提取更高级别的特征。此外,卷积神经网络可能包含归一化层、Dropout层等辅助结构,用于提高模型性能和防止过拟合。
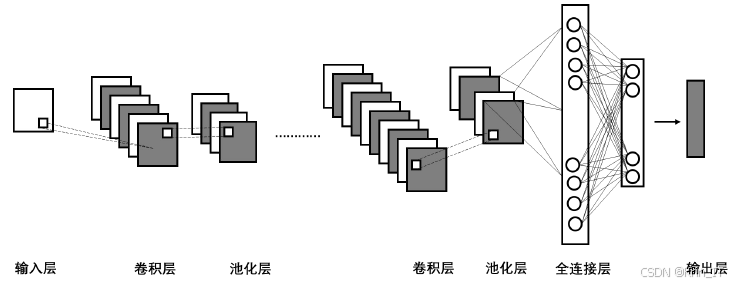
- 卷积层:卷积层在卷积神经网络中占据重要地位,能够有效提取输入数据中的关键和有用信息。通过使用卷积运算,对输入数据进行局部连接和参数共享,实现对图像或数据的空间特征提取。卷积层的核心是卷积核,对输入数据进行逐点乘积累加运算,得到输出特征图。每个神经元只与输入数据的一个局部区域相连,这种局部连接方式有助于捕获输入数据的局部特征。卷积核滑动,对不同的局部区域进行卷积运算,实现参数共享,减少模型的参数数量,降低模型的复杂度。
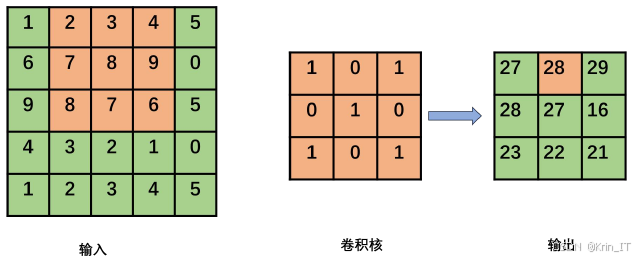
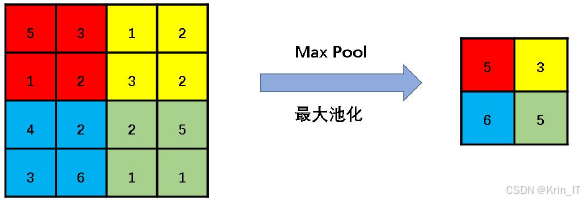
- 池化层:池化层用于降低数据维度、提取有效特征和防止过拟合。它在卷积层之后使用,对卷积层的输出进行下采样,减少数据的空间尺寸,同时保留重要特征。池化层的作用包括降低维度,通过下采样减少数据的空间尺寸,提高计算效率和模型泛化能力;特征提取,通过聚合操作提取输入数据中的宏观特征,有助于后续分类或识别任务的完成;防止过拟合,常用的池化层类型有最大池化层和平均池化层。最大池化层通过选择局部区域最大值作为输出,平均池化层通过计算局部区域平均值,具有平滑数据的功能,降低噪声和异常值的影响。
- 全连接层:全连接层用于处理分类和回归问题,将前一层提取到的局部特征整合为全局特征表示。通过权重矩阵,将不同位置、不同大小的局部特征映射到同一空间维度,实现特征融合。全连接层通常位于神经网络的最后几层,进行分类或回归任务。在分类任务中,将整合后的特征映射到分类空间,输出每个类别的概率;在回归任务中,根据问题需求输出预测值。全连接层能够关联输入数据中的上下文信息。
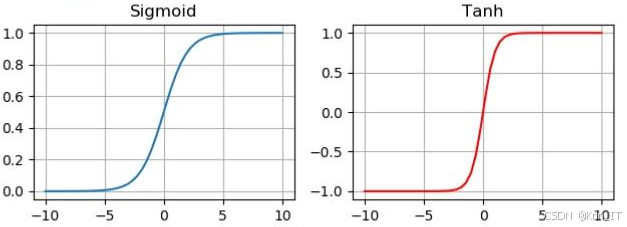
- 激活函数:激活函数在神经网络中扮演重要角色,引入非线性特性,使网络能够学习和理解复杂输入数据。通过引入激活函数,神经网络可以学习更复杂的函数关系,提高拟合能力和泛化能力。
2.2 注意力机制
注意力机制是一种模仿人类视觉系统的机制,允许模型在学习过程中关注输入数据中的重要部分,从而提高模型的性能和效率。注意力机制的核心思想是在处理输入数据时,模型可以关注不同的部分,并赋予它们不同的权重。权重越高,表示该部分对模型的预测结果影响越大。通过学习权重,模型自动识别输入数据中的重要特征和模式,而不需要手动指定。注意力机制的实现方式有多种,其中最常见的是加权平均法,即每个输入元素的权重根据其与当前模型上下文相关性的大小来计算。
注意力机制主要分为通道注意力机制、空间注意力机制和混合注意力机制三种。通道注意力机制主要用于图像处理和计算机视觉任务,通过对不同通道的特征进行加权,增强模型对不同通道特征的关注度。通道注意力机制允许模型根据任务需求自适应地关注不同通道的特征,从而有效融合不同通道的特征。通过赋予不同通道不同的权重,模型可以更好地理解和处理多通道输入数据,自动识别哪些通道特征对当前任务重要,减少冗余特征的干扰,提高效率和准确性。在计算机视觉任务中,通道注意力机制帮助模型在不同光照、颜色和角度变化的情况下保持稳定性能,提高鲁棒性。
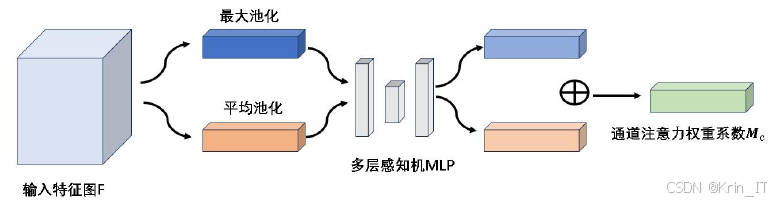
空间注意力机制主要用于处理序列数据和二维图像数据。它通过关注输入数据中的空间位置信息,使模型能够更好地理解和处理不同位置的特征。空间注意力机制允许模型关注关键区域,将更多计算资源集中在这些区域上,减少冗余计算,提高准确性。空间注意力机制通过关注不同位置的特征帮助模型提取重要信息,增强表示能力和鲁棒性,使其更好地处理复杂和动态的数据。空间注意力机制的可视化有助于理解模型在处理输入数据时的关注点,提高可解释性和可靠性,在医疗、金融等重要领域得到更广泛的应用。
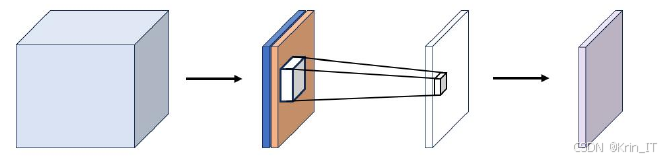
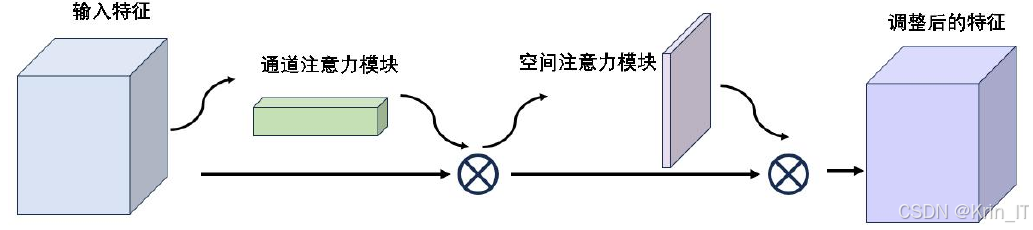
混合注意力模块是一种通道注意力机制与空间注意力机制混合的注意力机制。混合注意力机制实现在通道和空间维度上的注意力权重推断,从而显著提升整体性能。通道注意力机制致力于发掘特征图中富含信息的内容部分,空间注意力机制则专注于精确定位特征图中有效信息的所在位置。这样,模型可以同时关注输入数据中在通道和空间两个维度上都重要的信息,提高任务的性能。
残差网络的基本思路是通过引入残差连接来帮助网络更好地学习恒等映射,从而提高深层网络的性能。神经网络中的每个非线性单元,其输入与输出的维度相同。每个单元需要拟合的函数可以被分解为两部分:恒等映射和残差函数。通过这种分解,神经网络可以更有效地学习恒等映射,进而提升性能。残差模块采用跳跃连接技术,直接将模块的初始输入与经过卷积处理后的输出相加,得到该模块的最终输出结果。残差网络通过这种跳跃连接的设计能够更有效地学习数据的特征表示,提高网络性能和训练速度。
三、检测的实现
3.1 数据集
驾驶员疲劳状态图像采集选择自主拍摄和互联网采集相结合的方式,确保数据的多样性和代表性。自主拍摄可通过在不同驾驶环境和条件下拍摄,捕捉真实场景中的驾驶员状态,而互联网采集则可以获取大量已有的相关图片和视频资料,以丰富数据集的内容。采用标注工具进行数据标注,确保每一帧图像都能够准确反映驾驶员的疲劳状态。标注过程中,需对驾驶员的面部表情、眼睛状态和整体姿态进行细致观察,标记出疲劳与非疲劳状态的类别,从而为后续的模型训练提供可靠的标签支持。

将数据集分为训练集、验证集和测试集,以确保模型训练的有效性和泛化能力。同时,通过数据增强技术,如旋转、缩放、翻转和颜色变换等,对原始图像进行扩展,增加样本数量,提升模型在不同场景下的鲁棒性。这一系列步骤确保了数据集的质量与适用性,为驾驶员疲劳状态监测的研究提供了坚实的基础。
3.2 实验环境搭建

3.3 实验及结果分析
对收集到的数据集进行准备和预处理。这包括数据清洗、去除无效样本,并进行数据标注。同时,对图像进行归一化处理,以确保输入数据在相同的尺度下,避免因数据分布不均导致模型训练不稳定。常见的预处理操作还包括图像的旋转、缩放和裁剪,以提高数据的多样性,从而增强模型的泛化能力。
import cv2
import numpy as np
def preprocess_image(image):
image = cv2.resize(image, (224, 224)) # 调整图像尺寸
image = image / 255.0 # 归一化处理
return image针对传统ResNet网络在提取面部细微表情变化方面的不足,设计了混合注意力机制下的优化ResNet网络。每个残差单元被改进为由BN层、ReLU激活函数和卷积层组成的新结构,并在第三个卷积层后添加CBAM模块,以更有效地提取人脸关键部位的特征。这样的设计使得网络能够更加关注面部表情的细微变化,提高了表情识别的准确率。
from tensorflow.keras.layers import Conv2D, BatchNormalization, ReLU, Add
from tensorflow.keras import Model
def residual_block(input_tensor, filters):
x = BatchNormalization()(input_tensor)
x = ReLU()(x)
x = Conv2D(filters, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = ReLU()(x)
x = Conv2D(filters, (3, 3), padding='same')(x)
return Add()([input_tensor, x]) # 残差连接将数据集划分为训练集和验证集,使用交叉熵损失函数和Adam优化器进行训练。通过引入CBAM模块,模型能够自适应地关注不同的特征通道和空间位置,提高了训练的精度。训练过程中应定期评估模型的表现,以避免过拟合,并通过调整学习率和其他超参数来优化训练过程。
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
model = Sequential()
model.add(residual_block(input_tensor, 64)) # 添加残差块
# 添加更多的层和模块
model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(train_data, train_labels, validation_data=(val_data, val_labels), epochs=50, batch_size=32)完成模型训练后,进行实验并与传统ResNet网络、添加通道注意力机制的ResNet网络、添加空间注意力机制的ResNet网络进行对比。使用公开数据集,评估模型在表情识别任务上的性能。通过混淆矩阵分析不同表情的识别准确率,验证所设计网络在处理细微表情方面的优势。
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
y_pred = model.predict(test_data)
cm = confusion_matrix(test_labels.argmax(axis=1), y_pred.argmax(axis=1))
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True, fmt='d')
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.title('Confusion Matrix')
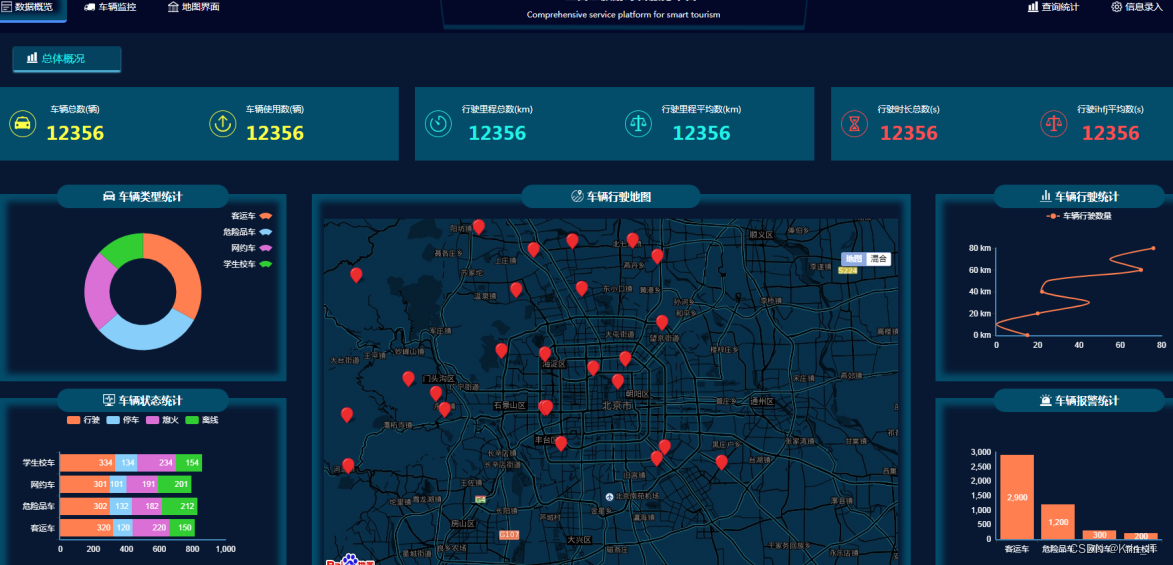
plt.show()实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









