







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的苏州市气象数据预测系统
设计思路
一、课题背景与意义
苏州市作为中国东部的重要城市,其气象条件对经济发展、农业生产和城市管理有着重要影响。随着气候变化的加剧,气象预测的准确性和及时性显得尤为重要。通过对苏州市历史气象数据的分析,建立有效的预测系统,为公众提供科学的天气预报和气候信息。这不仅可以提高防灾减灾能力,还可以有效指导农业生产、交通运输及其他社会活动。
二、算法理论原理
2.1 循环神经网络
现代深度学习架构大多数基于人工神经网络,尤其是深度神经网络。深度神经网络由多个隐藏层组成,相较于传统的浅层网络,能够更好地捕捉数据中的复杂模式。每个隐藏层中的神经元与其他神经元相互连接,并具有可调的权重,这些权重决定了神经元的状态信息对其连接的其他神经元的影响程度。这种结构使得深度学习能够在图像识别、自然语言处理和语音识别等领域取得显著成果。
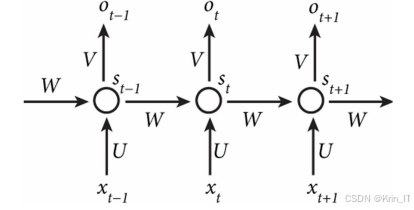
循环神经网络(RNN)是一种适合处理序列数据的深度学习模型,其结构设计使其能够有效地捕捉时间序列中数据的相关性。循环神经网络通过引入状态变量,存储过去一段时间的数据,并将其与当前输入序列共同决定当前的输出。这一特性使得循环神经网络在处理时序数据时表现出色,网络能够记忆前面的信息并应用于当前输出的计算中。具体来说,隐藏层之间的节点不再是无连接的,而是形成连接,从而使得网络能够在时间维度上进行信息传递。隐藏层的输入不仅包括当前的输入层输出,还包括上一时刻隐藏层的输出,这种具有环路的网络结构赋予了循环神经网络短期记忆的能力。
2.2 长短时记忆神经网络
长短时记忆神经网络(LSTM)是循环神经网络(RNN)的一个变种,专门设计用于解决传统RNN在处理长序列数据时面临的梯度消失和梯度爆炸问题。LSTM通过引入特殊的结构单元,能够有效地捕捉时间序列中的长期依赖关系。每个LSTM单元包含多个门控机制,包括输入门、遗忘门和输出门,这些门控机制通过调节信息的流入和流出,决定了哪些信息应该被保留或遗忘。通过这种方式,LSTM能够在长时间跨度内保持关键信息,从而使网络在处理序列数据时表现出更优的性能。这种特性使LSTM在语音识别、自然语言处理、时间序列预测等领域得到了广泛应用,可以有效地处理复杂的时序数据。
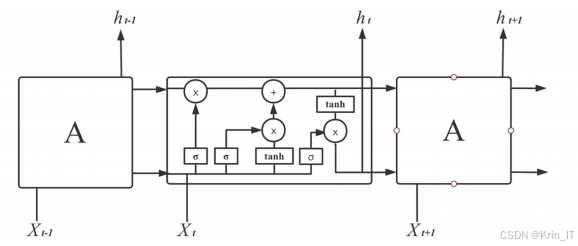
LSTM的核心在于其独特的门控结构。输入门控制当前输入信息的流入,遗忘门决定了先前状态信息的保留程度,而输出门则负责控制当前单元状态的输出。这种门控机制使得LSTM能够对输入信息进行动态调整,确保重要信息得以保留,而不相关的信息则被遗忘。此外,LSTM单元在每个时间步都维护一个细胞状态,这一状态可以理解为网络的长期记忆。通过细胞状态的更新和传递,LSTM能够在长序列中保持信息的连贯性与一致性,显著提升了模型对时间序列数据的建模能力。LSTM能够利用历史气象数据捕捉气候变化的规律,进行准确的短期和长期预测。通过分析过去的气象数据,LSTM可以识别出气候模式并作出相应的预测,为农业、交通和城市规划等各个领域提供科学依据和决策支持。由于LSTM能够处理不规则的时间间隔数据,因此在气象数据中存在缺失或不完整的情况下,仍然能够保持较好的预测性能。
三、检测的实现
3.1 数据集
从苏州市气象局和开放数据平台收集历史气象数据,确保数据的准确性和时效性。进行数据清洗,处理缺失值和异常值,并将数据格式化以确保一致性。在数据标注阶段,定义预测标签并将数据划分为训练集、验证集和测试集。通过数据增强技术增加数据集的多样性,生成额外特征以提升模型性能。进行数据质量检查,确保数据的完整性和一致性,并将最终数据集存储以便后续使用和分享。
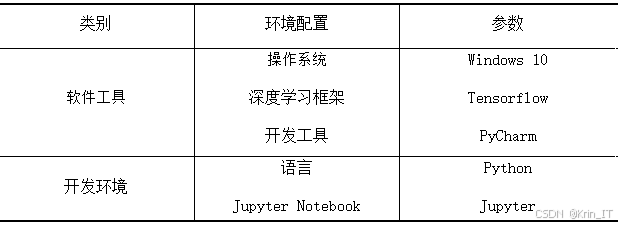
3.2 实验环境搭建
3.3 实验及结果分析
对于苏州市气象数据预测系统,首先需要从数据集中提取出相关的气象变量,如温度、湿度、降水量等。接着,进行数据清洗,包括处理缺失值和异常值,确保数据的准确性和完整性。此外,将时间序列数据格式化为适合LSTM模型输入的结构,通常需要将数据转换为三维数组格式,包含样本数、时间步长和特征数。最后,数据集需要划分为训练集、验证集和测试集,以便后续的模型训练和评估。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# 加载数据集
data = pd.read_csv('suzhou_weather_data.csv')
# 数据清洗
data.fillna(method='ffill', inplace=True) # 前向填充缺失值
# 数据格式化
def create_dataset(data, time_step=1):
X, y = [], []
for i in range(len(data) - time_step):
X.append(data[i:(i + time_step), 0])
y.append(data[i + time_step, 0]) # 假设预测第一个特征
return np.array(X), np.array(y)
data_values = data[['temperature', 'humidity', 'precipitation']].values # 选择相关特征
X, y = create_dataset(data_values, time_step=10) # 以10个时间步长为例
X = X.reshape(X.shape[0], X.shape[1], 1) # 转换为三维数组
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)LSTM模型因其能够有效捕捉时间序列中的长期依赖关系而被广泛应用。模型的构建通常包含多个LSTM层和全连接层。在设计模型时,应根据数据的复杂性和任务的需求来确定LSTM层的数量和每层的单元数。通常,输入层的形状应与训练数据相匹配,而输出层的形状依赖于预测目标的维度,例如预测单个变量时输出层为1。定义训练参数、进行多轮迭代训练以及监控训练过程中的损失变化。通过将训练数据输入模型,模型会根据预测结果与真实标签之间的损失进行反向传播,调整权重,以逐步提高预测准确性。训练过程中的验证集用于监控模型的泛化能力,避免过拟合现象的发生。
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(X_train.shape[1], 1))) # 第一层LSTM
model.add(Dropout(0.2)) # 防止过拟合
model.add(LSTM(50)) # 第二层LSTM
model.add(Dropout(0.2))
model.add(Dense(1)) # 输出层
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')利用测试集对训练好的模型进行评估,计算预测结果与真实标签之间的误差,常用的评价指标包括均方误差(MSE)、均方根误差(RMSE)等。这些指标能够直观反映模型的预测能力。同时,可以通过可视化预测结果与真实结果的对比,直观了解模型的表现。通过调整学习率、增加LSTM单元、优化网络结构、增加正则化手段等方式提升模型的性能。
from sklearn.metrics import mean_squared_error
# 进行预测
predictions = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, predictions)
rmse = np.sqrt(mse)
print(f'Mean Squared Error: {mse:.4f}')
print(f'Root Mean Squared Error: {rmse:.4f}')
# 可视化预测结果
plt.plot(y_test, label='True Values')
plt.plot(predictions, label='Predicted Values')
plt.title('Weather Prediction')
plt.xlabel('Time Steps')
plt.ylabel('Temperature')
plt.legend()
plt.show()实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









