







在处理高维向量数据时,我们常常面临这样的困惑:通过嵌入模型生成的文本、图像向量动辄上百维,这些抽象的数值究竟如何反映数据的语义关联?如何快速判断向量质量并发现数据分布规律?这时,降维可视化技术就成了我们理解高维空间的 “望远镜”。今天,我们就来聊聊如何借助 Milvus 和 t-SNE,将晦涩的向量数据转化为直观的可视化图表,让数据分布规律一目了然。
一、核心技术:让高维向量 “看得见” 的两大法宝
在开始实践前,我们需要理解两个核心技术的分工与价值:
1. Milvus:高维向量的 “智能仓库”
作为高性能向量数据库,Milvus 解决了两个关键问题:
- 高效存储:支持存储千万级以上的高维向量(如 3072 维的文本嵌入),并通过索引技术(如 HNSW、IVF)实现毫秒级检索。
- 无缝集成:提供 Python SDK,方便与主流嵌入模型(如 OpenAI Embeddings、BERT)和降维工具(如 t-SNE、UMAP)对接,形成 “生成 - 存储 - 分析” 的完整链路。
2. t-SNE:高维数据的 “显微镜”
t-SNE(t 分布随机邻域嵌入)是降维可视化的黄金标准,特别适合:
- 局部结构保留:擅长捕捉高维空间中数据点的局部相似性,将距离近的点在二维图中也保持邻近,适合观察聚类边界和异常点。
- 非线性降维:相比 PCA 等线性方法,能更好地处理复杂流形结构,对文本、图像等语义向量的可视化效果更佳。
两者结合后,Milvus 负责高效管理向量数据,t-SNE 负责将高维向量 “翻译” 成人类可理解的二维分布,形成 “存储 - 分析 - 决策” 的闭环。
二、实战教程:从 Milvus 向量到可视化图表的全流程
我们以 Milvus 官方文档的 FAQ 页面为例,演示如何将文本转化为向量,存入 Milvus 并进行可视化分析,最终回答 “哪些 FAQ 内容在语义上更接近” 的问题。
1. 环境准备:安装必要工具
首先安装依赖库,注意 OpenAI 库和 Milvus 的兼容性:
bash
# 安装Milvus客户端、OpenAI嵌入模型、可视化工具
pip install pymilvus openai matplotlib scikit-learn tqdm
需要准备 OpenAI API 密钥(申请地址:OpenAI API),并设置环境变量:
python
运行
import os
os.environ["OPENAI_API_KEY"] = "[你的API密钥]" # 注意脱敏处理
2. 数据预处理:生成文本嵌入并入库
加载 FAQ 文本
读取 Milvus 文档中的 FAQ 页面,按章节分割内容:
python
运行
import glob
texts = []
for file_path in glob.glob("milvus_docs/en/faq/*.md"):
with open(file_path, "r", encoding="utf-8") as f:
# 按标题分割章节(假设每个### 开头为一个段落)
sections = f.read().split("### ")
texts.extend([s.strip() for s in sections if s.strip()])
生成 OpenAI 嵌入
使用 text-embedding-3-large 模型生成 1536 维的文本嵌入:
python
运行
from openai import OpenAI
client = OpenAI()
def get_embedding(text):
"""生成文本嵌入,自动处理超长文本(OpenAI最多支持8191 tokens)"""
return client.embeddings.create(
input=text,
model="text-embedding-3-large"
).data[0].embedding
# 批量生成嵌入(注意控制并发,避免API限流)
embeddings = []
for text in tqdm(texts, desc="Generating embeddings"):
embeddings.append(get_embedding(text))
存入 Milvus
连接 Milvus Lite(本地文件存储,适合小规模数据)并创建集合:
python
运行
from pymilvus import MilvusClient
# 初始化客户端(使用本地文件存储)
milvus = MilvusClient(uri="./milvus_demo.db")
collection_name = "faq_embeddings"
# 创建集合(自动生成主键id,存储向量和原始文本)
milvus.create_collection(
collection_name=collection_name,
dimension=1536, # 嵌入维度与模型输出一致
metric_type="IP", # 内积相似度(OpenAI嵌入默认使用cosine,内积等价于归一化后的cosine)
enable_dynamic_field=True # 自动添加text字段存储原始文本
)
# 插入数据(每条记录包含向量和文本)
data = [{"vector": emb, "text": txt} for emb, txt in zip(embeddings, texts)]
milvus.insert(collection_name=collection_name, data=data)
print(f"Inserted {len(data)} FAQs into Milvus.")
3. 降维处理:用 t-SNE 将 1536 维降至 2 维
加载所有向量
python
运行
# 查询所有向量(注意大规模数据需分页查询,此处为演示简化)
vectors = milvus.query(
collection_name=collection_name,
output_fields=["vector", "text"],
limit=1000 # 限制查询数量,避免内存溢出
)
# 提取向量和文本
X = np.array([v["vector"] for v in vectors])
texts_subset = [v["text"] for v in vectors]
执行 t-SNE 降维
python
运行
from sklearn.manifold import TSNE
# 配置t-SNE参数(重点调整困惑度和迭代次数)
tsne = TSNE(
n_components=2, # 降至2维
perplexity=30, # 控制局部邻域大小,通常设为5-50
n_iter=1000, # 迭代次数,足够大以确保收敛
learning_rate=200, # 学习率,控制优化步长
random_state=42, # 固定随机种子,确保结果可复现
verbose=1 # 输出进度信息
)
X_tsne = tsne.fit_transform(X) # 耗时较长(1000维数据约需1-2分钟)
4. 可视化分析:绘制语义分布图谱
标记重点数据点
假设我们关注 “数据存储” 相关的 FAQ,手动标记包含关键词的文本索引:
python
运行
# 示例:标记包含“storage”或“etcd”的文本
mark_indices = [i for i, txt in enumerate(texts_subset) if "storage" in txt.lower() or "etcd" in txt.lower()]
绘制可视化图表
python
运行
import matplotlib.pyplot as plt
import seaborn as sns
# 初始化画布
plt.figure(figsize=(12, 8))
sns.set_style("whitegrid")
# 绘制所有点(透明度降低,突出重点)
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c="#3498db", alpha=0.6, label="All FAQs")
# 标记重点数据点(红色加粗)
plt.scatter(X_tsne[mark_indices, 0], X_tsne[mark_indices, 1], c="red", s=100, edgecolors="black", label="Storage-related FAQs")
# 添加文本标签(选择前5个点,避免图表拥挤)
for i in range(5):
plt.text(X_tsne[i, 0]+0.1, X_tsne[i, 1], texts_subset[i][:20]+"...", fontsize=8, color="gray")
# 添加标题和图例
plt.title("t-SNE Visualization of Milvus FAQ Embeddings", fontsize=14)
plt.xlabel("t-SNE Dimension 1")
plt.ylabel("t-SNE Dimension 2")
plt.legend()
# 显示图表
plt.show()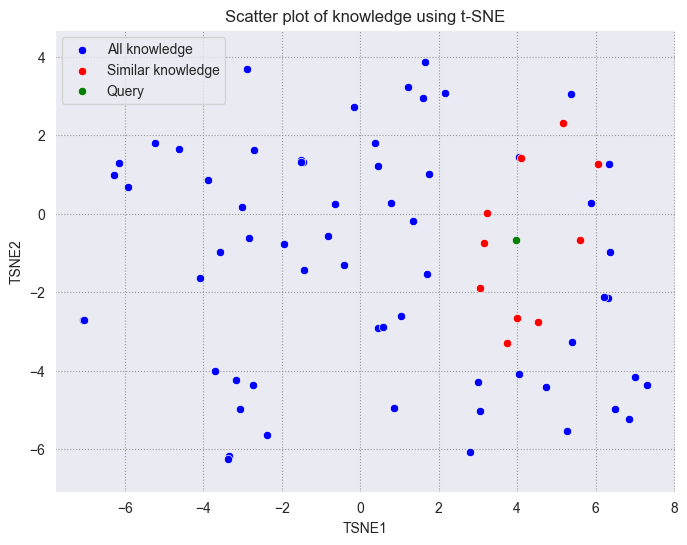
三、实践中的关键技巧与避坑指南
1. 提升降维效率的 3 个技巧
- 数据抽样:当向量规模超过 1 万时,先随机抽样 1000-2000 个点进行可视化,快速定位全局结构,再对感兴趣的局部区域进行全量分析。
- 增量计算:使用
sklearn的PartialTSNE类,分批次处理大规模数据,避免内存溢出。 - 硬件加速:在 GPU 上运行 t-SNE(需安装
cupy库),处理速度可提升 5-10 倍,适合百万级向量可视化。
2. 解读可视化结果的 3 个维度
- 聚类紧凑度:同类数据点是否聚集为紧密的簇?松散的分布可能意味着嵌入模型未能捕捉到关键特征(如文本预处理不足、模型选择不当)。
- 簇间距离:不同类别的簇是否明显分离?若重叠严重,可能需要调整嵌入模型(如换用多模态模型)或增加文本清洗步骤。
- 异常点检测:是否存在远离所有簇的孤立点?可能是数据中的噪声(如错误标注的文本)或特殊样本(如跨领域的边缘案例)。
3. Milvus 查询优化
- 分页查询:使用
limit和offset参数分批获取向量(如每次查询 1000 条),避免单次查询返回数据过大:python
运行
# 分页查询示例 page_size = 1000 total = milvus.count(collection_name) for offset in range(0, total, page_size): batch = milvus.query(collection_name, limit=page_size, offset=offset) # 处理批次数据 - 过滤条件:通过
expr参数添加过滤条件,减少需要处理的数据量:python
运行
# 仅查询包含“vector”关键词的文本对应的向量 filtered_vectors = milvus.query(collection_name, expr='text contains "vector"')
四、应用场景:可视化如何赋能实际业务
1. RAG 系统调试(以文档问答为例)
- 问题:用户提问 “如何优化 Milvus 检索性能”,但检索结果包含大量无关文档。
- 可视化价值:将用户问题嵌入与检索结果嵌入可视化,观察是否形成紧密簇。若提问向量远离检索簇,说明嵌入模型可能未正确捕捉 “优化性能” 的语义,需调整文本预处理(如增加领域关键词权重)或更换更专业的嵌入模型。
2. 推荐系统冷启动
- 场景:新用户注册时,通过其填写的兴趣标签生成嵌入,与历史用户嵌入可视化。
- 关键观察:新用户嵌入是否靠近某个已有用户簇?若孤立存在,需设计个性化引导流程;若靠近多个簇,可优先推荐对应簇的热门内容。
3. 模型效果对比
- 实验设计:分别使用 text-embedding-3-large 和 BERT 生成同一批文本的嵌入,可视化对比两者的簇结构。
- 决策依据:若 BERT 的可视化结果中同类文本聚集更紧密,则优先选择 BERT 作为嵌入模型。
五、总结与建议
通过 Milvus 与 t-SNE 的结合,我们实现了从高维向量到直观图表的转化,核心价值在于:
- 快速验证:通过可视化即时反馈嵌入质量,避免在低质量向量上浪费算力。
- 规律发现:直观呈现数据分布,帮助定位数据噪声、模型缺陷或业务场景中的潜在规律。
- 沟通桥梁:让非技术人员也能理解复杂的向量语义,促进跨团队协作。
如果你想尝试,建议:
- 从小规模数据开始:先用 100-200 条数据调试流程,熟悉 t-SNE 参数对可视化效果的影响(如
perplexity设为 20-40)。 - 结合业务标注:在图表中手动标记关键数据点(如 “优质客户”“高流失风险用户”),观察其分布特征。
- 探索进阶工具:尝试 UMAP(比 t-SNE 更快,适合大规模数据)或交互式可视化库(如 Plotly,支持鼠标悬停查看原始文本)。
希望这篇实践能帮你打开向量可视化的大门。如果你在操作中遇到参数调优、模型适配等问题,欢迎在评论区留言交流!觉得有用的话,别忘了点击关注,后续会分享更多 Milvus 与机器学习结合的实战经验~


















 1473
1473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











