






本文基于博客众多yolov5有关的使用教程,结合自己的实际情况,写下本篇教程。本人目前仍是一位才疏学浅的大学牲,在文章中如有纰漏,欢迎在评论区留言纠正!
因篇幅原因,对于配置环境,其它帖子里有更为详细的教程,本文在此不再一一列数,将环境部署的任务简要提及一下,以及一些注意事项。
首先先啰嗦一句,关于什么是YOLOv5 ,YOLOv5 是一种基于深度学习的目标检测模型,是一种功能强大、灵活且高效的目标检测模型,适合广泛的计算机视觉任务,特别适用于需要快速处理的应用场景,如视频监控、自动驾驶和无人机检测等。
使用yolov5之前需要进行的步骤:
1.安装Anaconda(可以实现创建一个独立的虚拟环境,便于在不同项目中使用不同的依赖版本,避免冲突),官网地址Download Anaconda Distribution | Anaconda
2.安装python和vscode(如果不用vscode也行,比如也可以用pycharm,本文将会使用vscode实现)
python下载地址:
vscode下载地址:Welcome to Python.org
Visual Studio Code - Code Editing. Redefined
pycharm下载地址:Download PyCharm: The Python IDE for data science and web development by JetBrains
3.下载yolov5框架及其模型
yolov5下载地址:ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
建议使用魔法上网,进入github会比较稳定些,偶尔不挂梯子也能进去。
不熟悉github下载资源的小伙伴可以查看这里: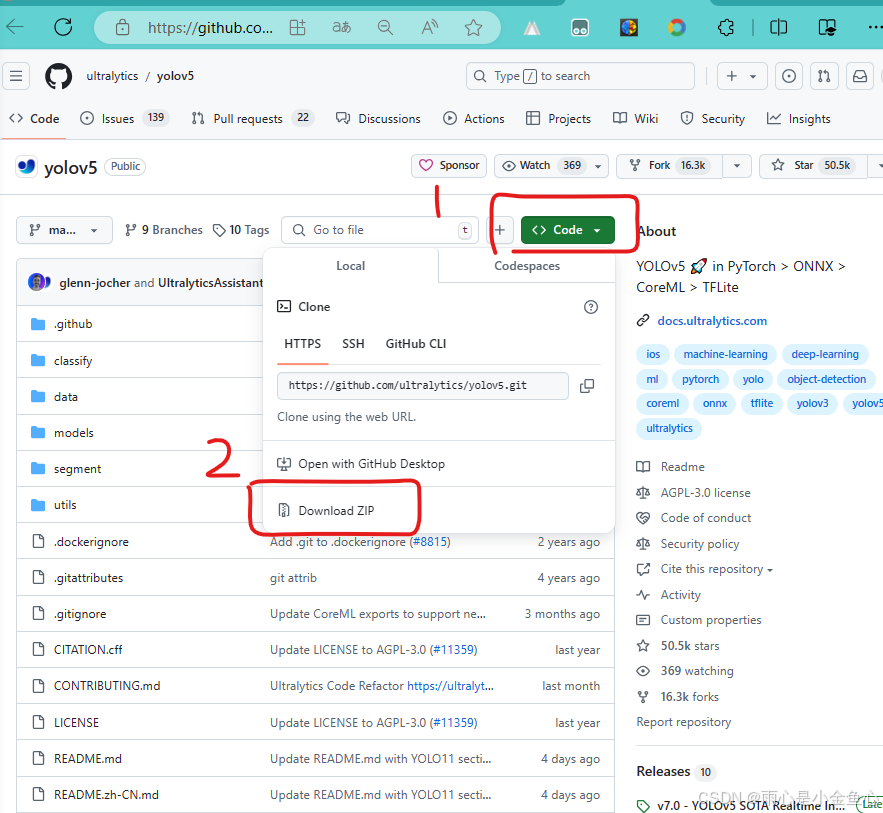
可以直接下载zip压缩包,解压到自己对应的路径下。如果安装过git包的,也可以直接克隆。
下载好之后,使用vscode打开该文件夹(yolov5-master),打开后vscode左侧栏会出现文件夹所对应的列表
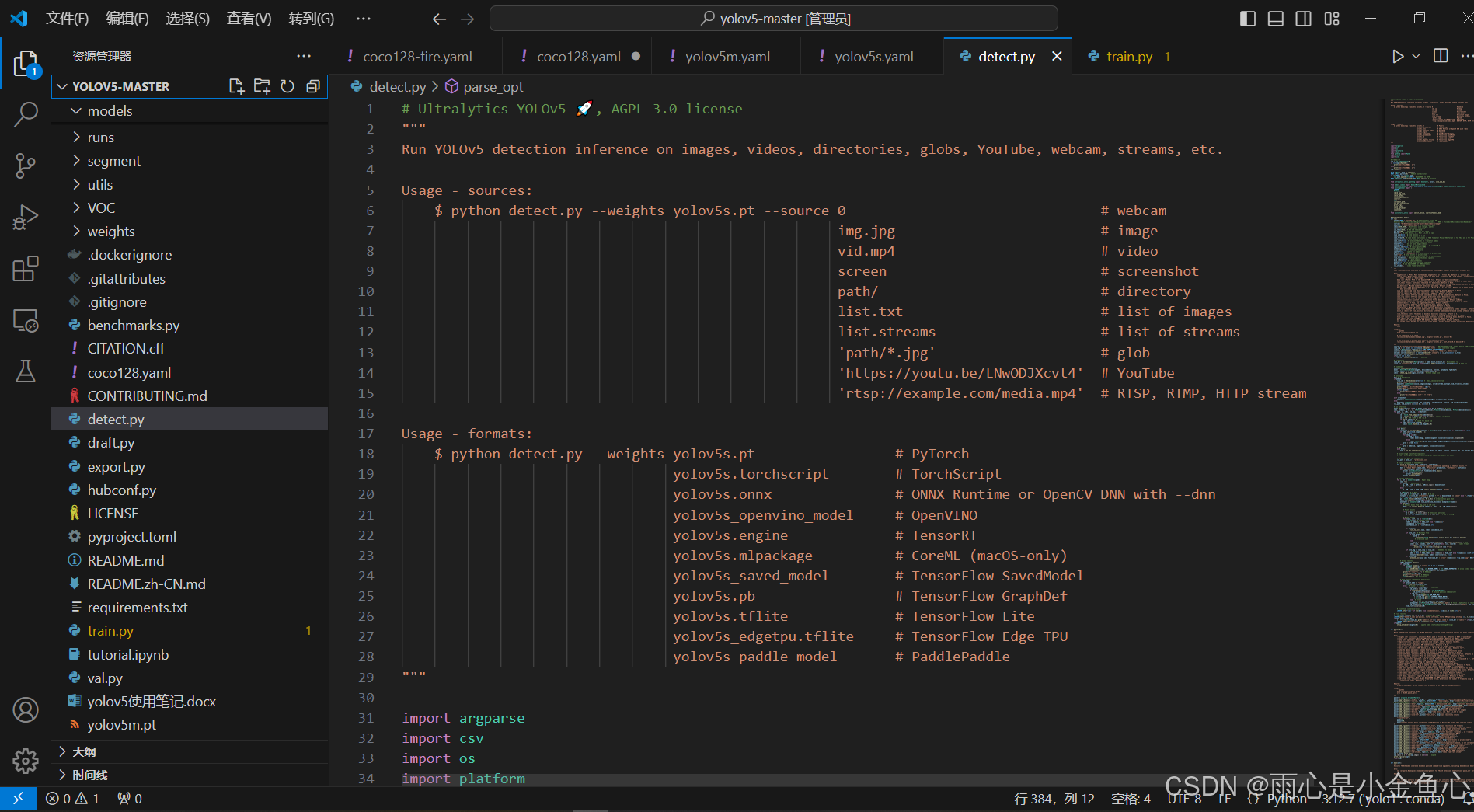
4.创建虚拟环境
win+r,输入cmd,再执行命令:
conda create -n yolo1 python=3.9
这里的yolo1是我自定义的虚拟环境名称,可以修改成别的。python是该虚拟环境下所配置的python版本,不同虚拟环境可以配置不同的python版本进行项目管理。
创建完毕之后,打开vscode终端,在终端激活虚拟环境:
conda activate yolo1
就可以出现如下所示的情况(前面有虚拟环境名称),证明激活成功:
然后在该虚拟环境下执行:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
这一步是下载安装依赖,因为yolov5-master下的目录里有requirements.txt,里面包含了所有需要用到的库的名称。
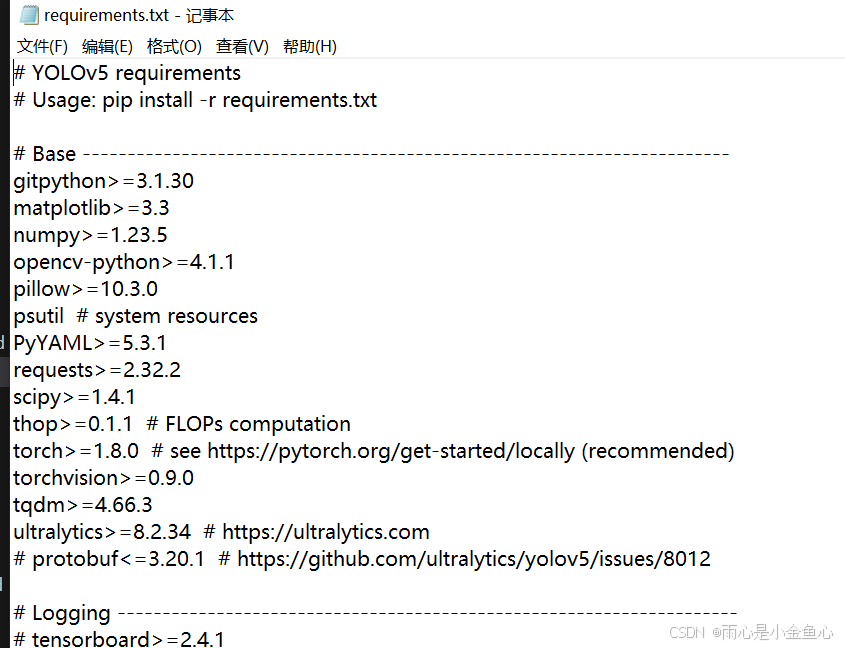
等安装完成之后,再在终端输入python train.py测试一下安装依赖是否成功,如果成功则会跑通。
出现类似代码说明代码可以跑通了。
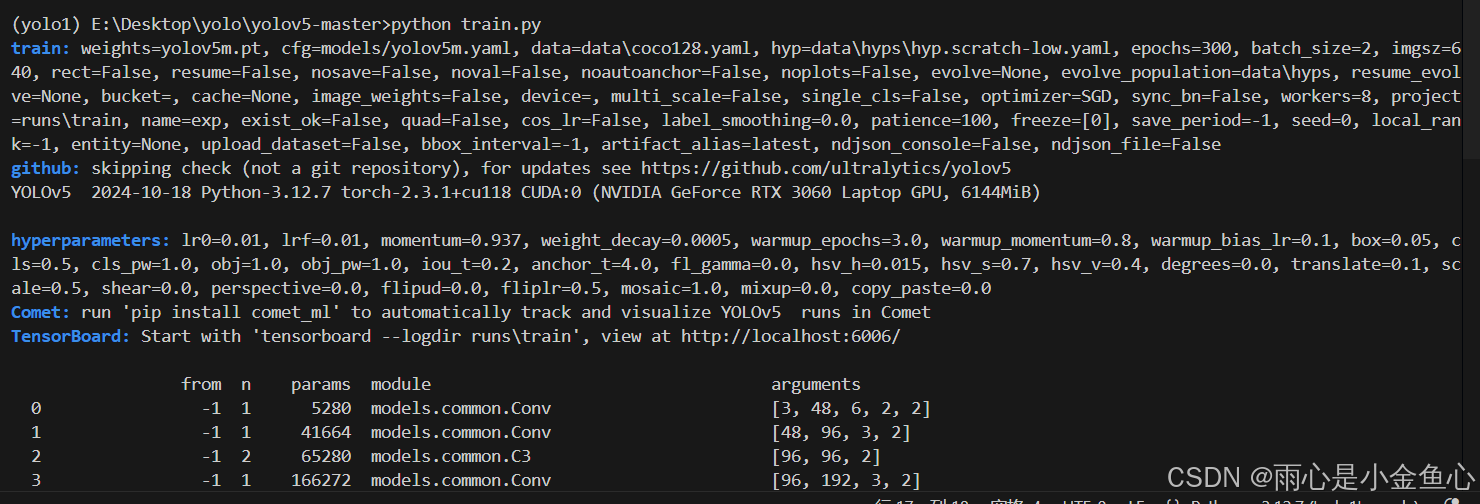
到目前为止虽然是跑通了,但是是用cpu进行训练的,速度远不及cpu,接下来为了使用gpu进行训练,将会提到如何配置pytorch以及cuda加速。
5.pytorch、cuda、cudnn版本选择及安装
win+R-cmd,运行nvidia-smi,右上角处表明你的电脑所支持的最高CUDA版本。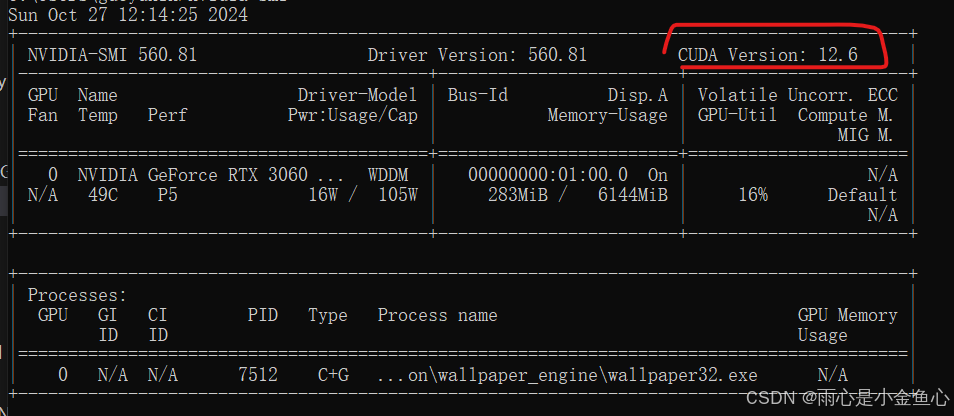
如图,本人电脑最高支持12.6版本的,下载cuda则不要超过这个版本。
下载pytorch:PyTorch
选择对应选项,下面会自动生成指令,将其复制到你的虚拟环境中国,回车即可安装pytorch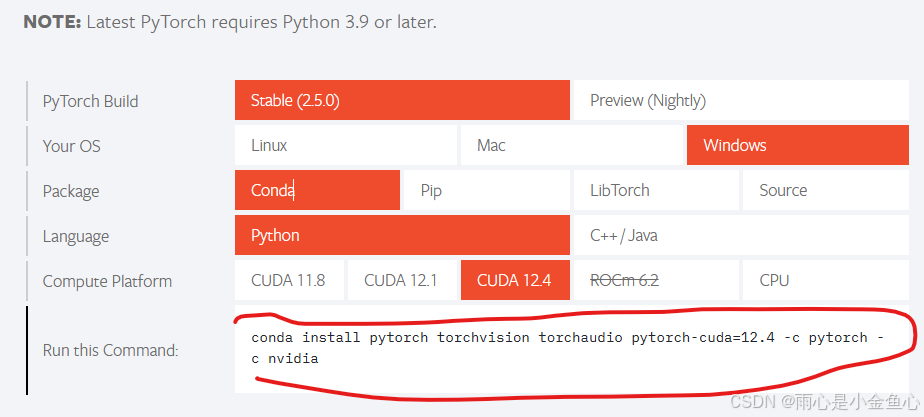
当然这个过程十分漫长,因此我推荐去镜像下载对应你电脑cuda版本以及python版本的whl文件。比上面的速度要快很多。
镜像链接:download.pytorch.org/whl/torch_stable.html
cu118-cp312-cp312-win_amd64.whl
镜像网站搜索本电脑适配的关键词👆(在镜像网站ctrl+f搜索,请在此基础上修改)
cu118表示你目前所安装的cuda版本(注意,不是你nvidia-smi之后所看到的哪个最高版本!!!),cp312表示该虚拟环境的python版本是3.12,请根据自己实际情况去下载对应的pytorch的whl文件。
pytorch文件一共需要下载三个,分别是:
torch、torchaudio、torchvision
本人下载的是以下三个:
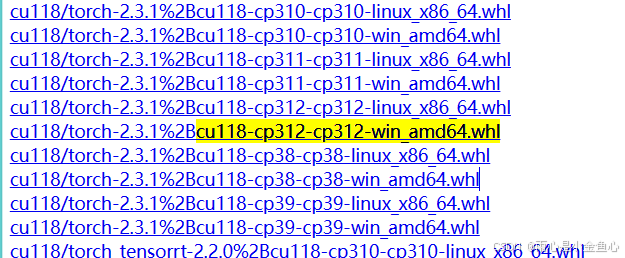
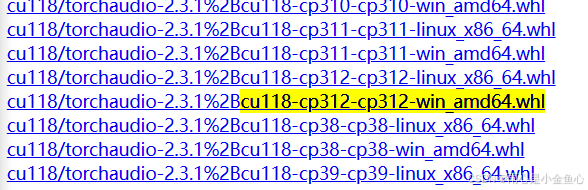

以上是本人根据自己python3.12,cuda11.8版本,所选择的whl文件。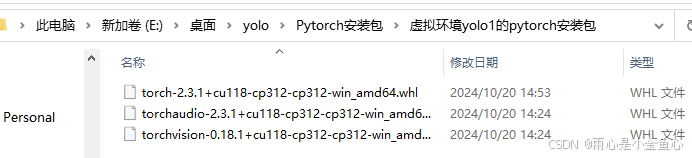
下载好之后如上保存到同一路径下,安装方式是先激活(yolo1)虚拟环境,然后在该虚拟环境下,将路径更换为放置这三个whl文件的文件夹所在路径
也就是:
cd 环境名称
比如我放置这三个whl文件的路径是 E:\Desktop\yolo\NEW_torch的话,那么只需要依次终端输入:
pip install E:\Desktop\yolo\NEW_torch\torch-2.3.1+cu118-cp312-cp312-win_amd64.whl
pip install E:\Desktop\yolo\NEW_torch\torchaudio-2.3.1+cu118-cp312-cp312-win_amd64.whl
pip install E:\Desktop\yolo\NEW_torch\torchvision-0.18.1+cu118-cp312-cp312-win_amd64.whl
这样。pytorch就安装好了。
其次是安装cuDNN,官网:cuDNN Archive | NVIDIA Developer
安装命令为:conda install cudnn=8.9 #示例,选择8.9版本,后面的小版本号不用管
安装完成之后测试一下以下代码,若能返回True,则说明可以使用gpu加速模型训练了。
python
import torch
print(torch.cuda.is_available())
5.Yolov5使用与调参
在yolov5-master同级目录下创建一个名为VOC的文件夹,里面的结构如图所示
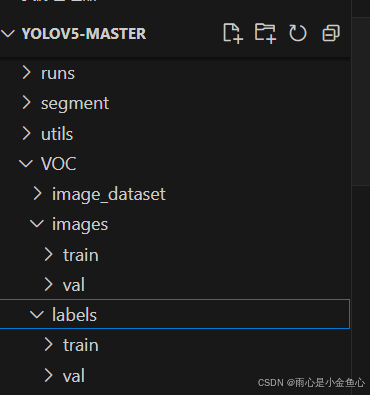
这里简单介绍一下,iamges分为train和val(训练集图片和验证集图片),labels分为train和val(训练集标签和验证集标签)。关于如何快速获得训练集和打标签,这里推荐使用Roboflow平台(需要魔法上网):Sign in to Roboflow
Robofow是一个免费开源数据集管理平台,它不仅提供免费的数据集,还支持上传自己的数据集并进行打标签,比传统使用的labeling效率要高太多了。下图展现的是roboflow标注数据集并打标签的一个功能。
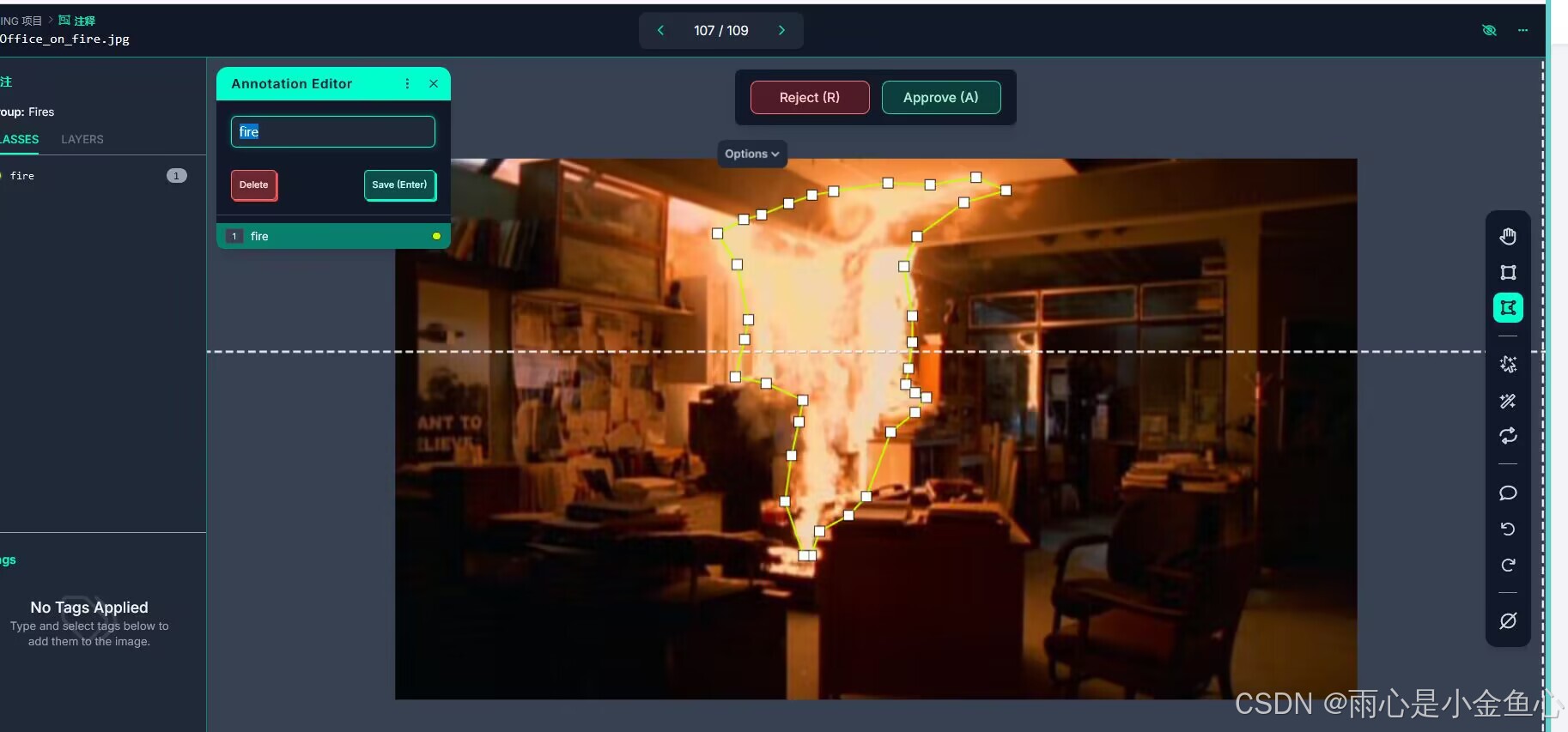
该平台具体使用教程推荐:Roboflow标注平台使用----小白都能看懂-CSDN博客
通过roboflw平台标注,可以获得标签数据集,如下图所示。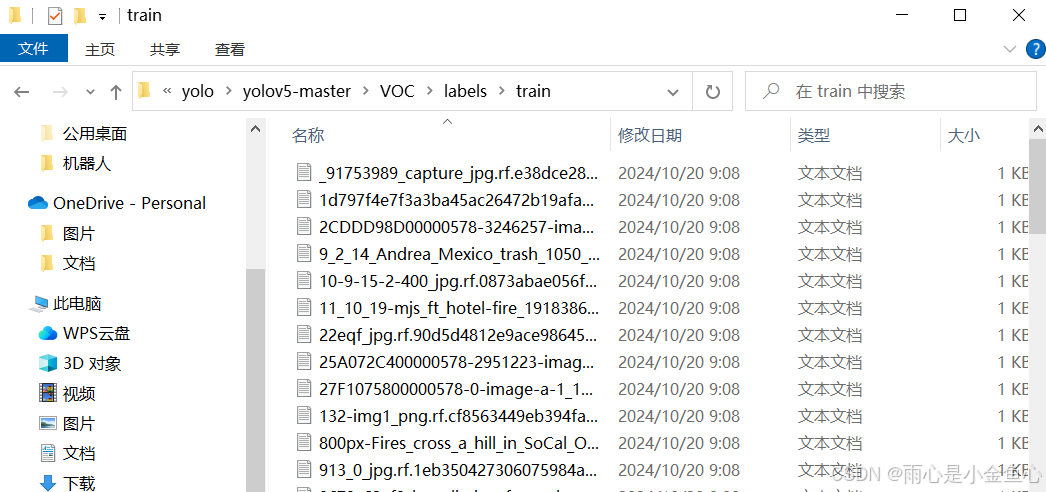
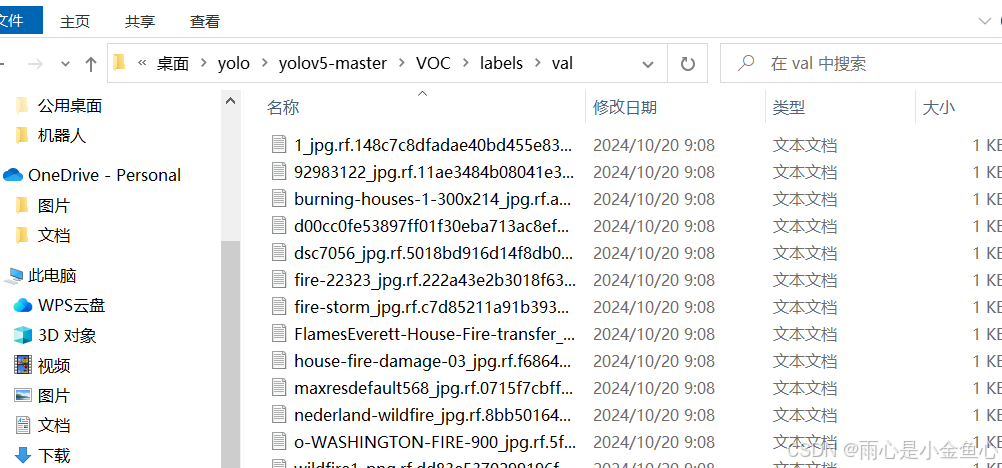
将数据集都打标签好了之后,推荐将数据集按照8:2比例划分成训练集和验证集,然后就可以开始进行配置文件的修改啦!
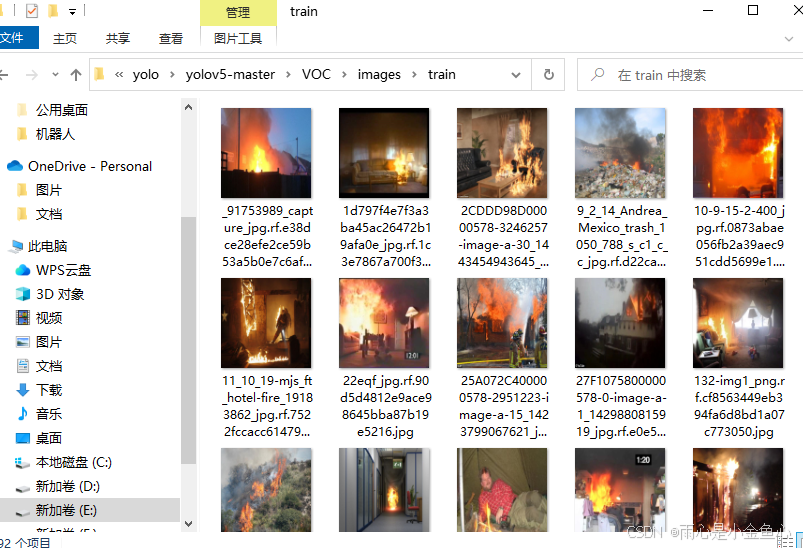
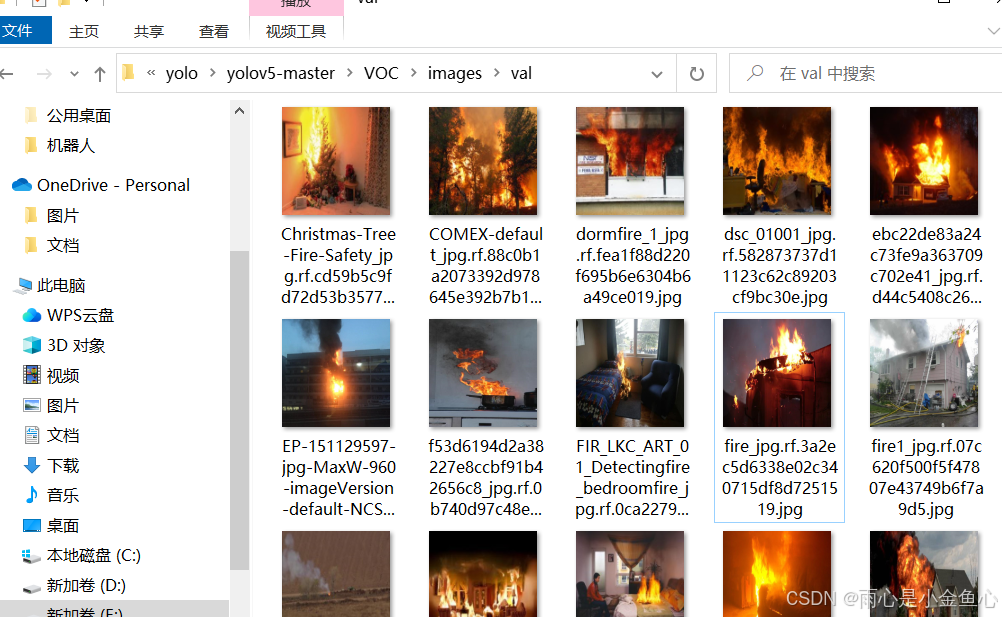
以上是我已经分配好的火灾检测数据集,注意路径要放置正确。
然后开始对配置文件进行修改。
首先修改yolov5-master\models的yolov5m.yaml,将nc这行参数改成你的标签种类数目(本人只检测“fire”,所以这里是1)
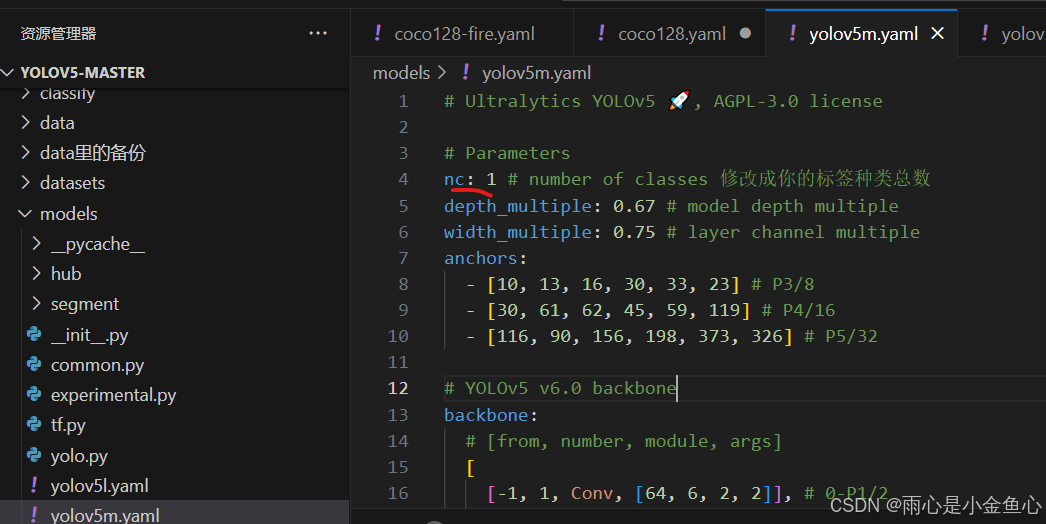
其次是修改data/coco128.yaml,train和val修改路径为VOC文件夹里的train和val文件夹路径(这里的train和val都是相对路径),其次是修改nc,与之前同理。names这里要修改的是所识别的目标的所有名称。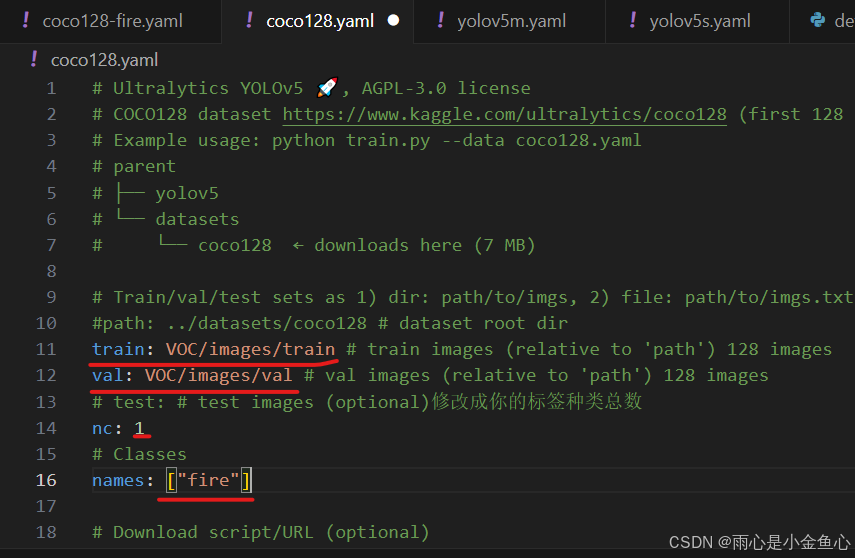
然后是修改和运行train.py文件:
打开train.py文件,ctrl+f,输入def parse_opt(known=False):,迅速定位到以下位置。
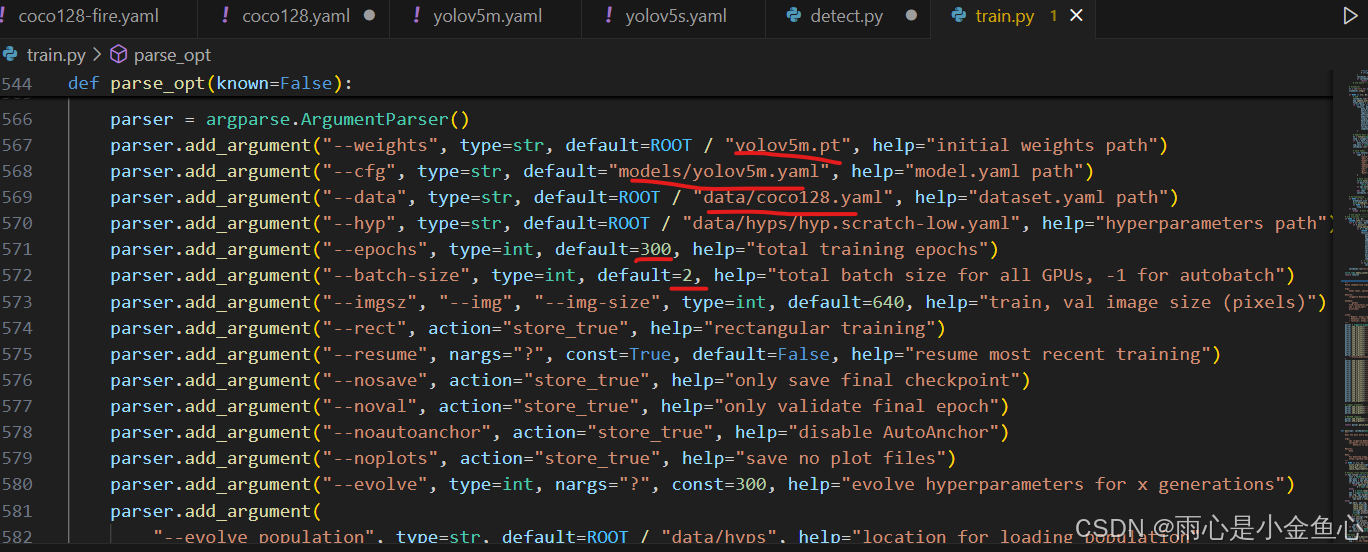
这里要修改的地方依次是
1.你所使用的pt模型文件(可在官网下载),本人使用的是yolov5m.pt,并且它在yolov5-master/weights文件夹里。该pt模型下载来源:ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
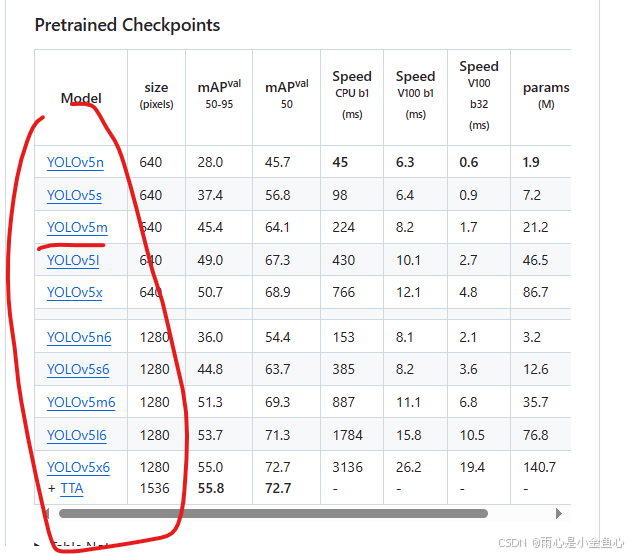
我们要进行的yolov5的模型训练,是要在官方pt模型的基础上训练出来的,不同的pt模型性能各不相同,笔者在此不再一一赘述。
2.此处换成修改的models/yolov5m.yaml文件
3.此处换成刚才修改的data/coco128.yaml文件
4.epochs是模型训练的迭代次数,一般默认为300次。
5.batch_size:是表示一次训练图片的张数,要根据自己电脑的gpu实际情况来选择,如果数值设置太大就会爆显存,以至于训练中断。本人电脑的gpu是NVIDIA GeForce RTX 3060 Laptop GPU,显存6gb。(可在任务管理器查看)因此我设置张数为2.
到这里就是都修改完毕了,然后我们在终端里先进入虚拟环境(conda activate yolo1),输入python train.py运行,就开始模型训练了。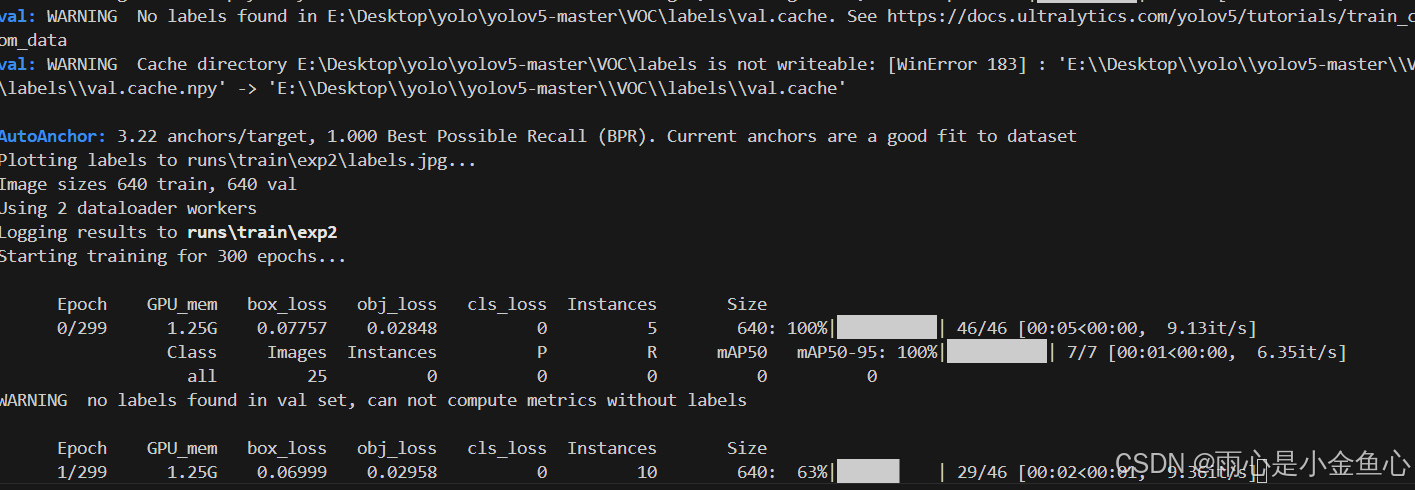
最后训练好的模型会保存到以下路径:
runs/train/exp/weights
打开该文件夹,会发现有两个训练好的模型,best.py和last.py。
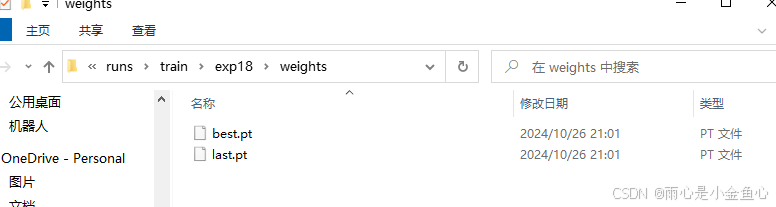
其中best.pt是训练过程中在验证集上表现最好的模型权重文件,通常我们会选择使用这个pt模型,而last.pt是训练过程结束时的最后一个模型权重文件,包含了训练过程中的最新状态,器性能通常不及best.pt模型。
接下来就是使用我们刚刚训练得到的best.pt模型进行目标检测任务了,这一步就意味着我们要看看新训练出来的模型效果怎么样。
6.修改detect.py 文件
打开detect.py,修改如图所示的位置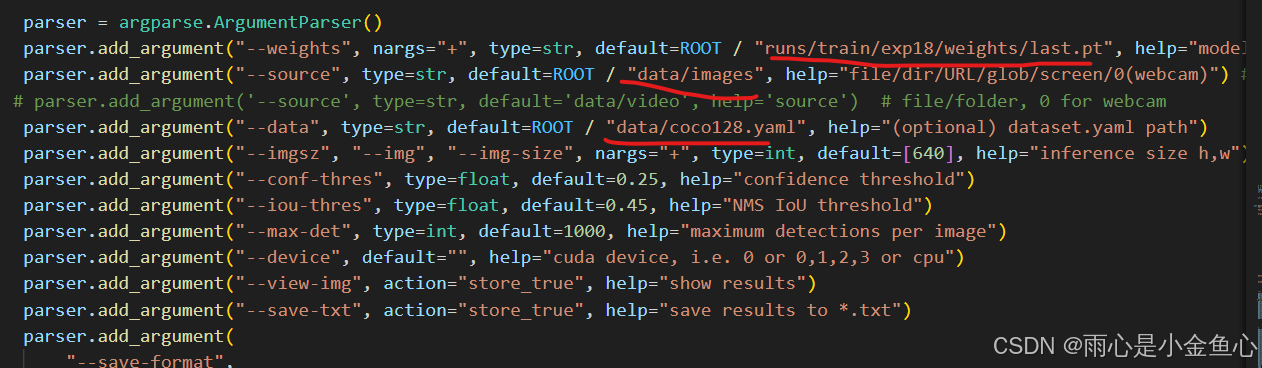
第一处:改成你best.py模型所在位置
第二处:存放需要检测的验证集图像的位置
第三处:data/coco128.yaml
然后进入虚拟环境,运行:python detect/py
【附注】detect.py有一行代码是: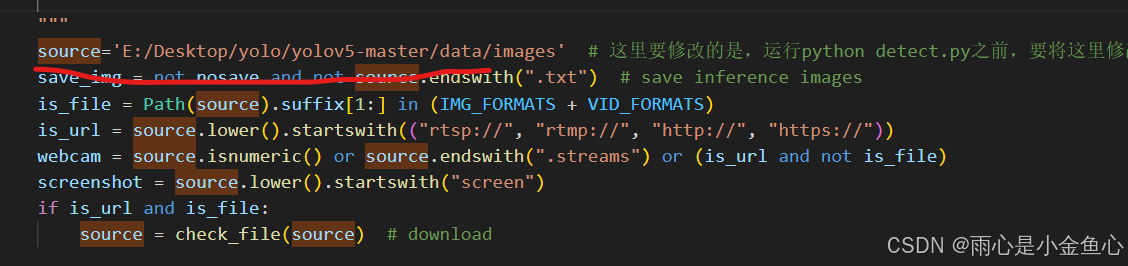
此处source路径要更改为你需要检测的检测集的路径,它会覆盖掉之前你修改过的这里的路径(也就是说以上面source所改的路径优先,因为会覆盖掉下面的路径):
出现类似以下情况说明检测结果完毕:
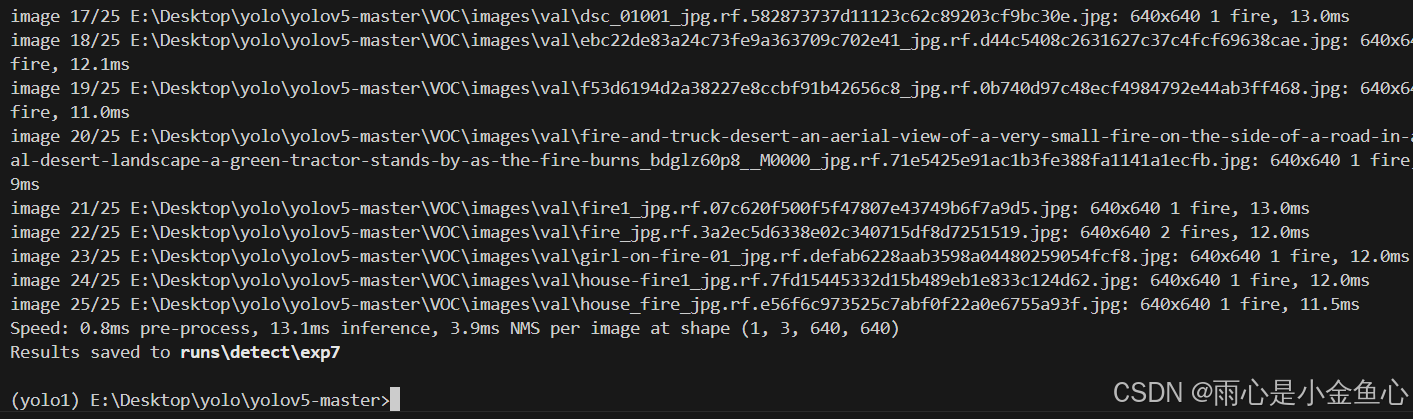
倒数第二行表示检测结果存放在了runs\detect\exp7路径下。
我们看看runs\detect\exp7。
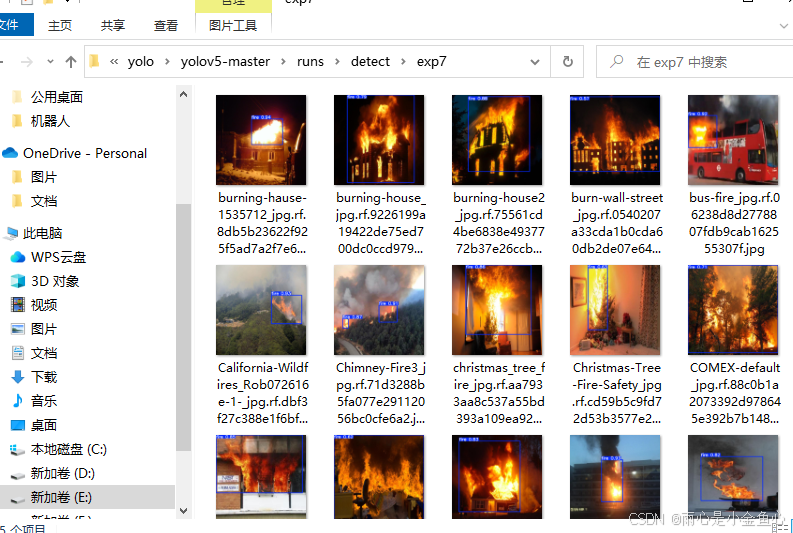
可以看到被检测的图片都被识别出来了目标,这里是火灾的识别效果,打开其中一张查看。

数字0.87和0.91是置信度,置信度数值越趋近于1说明训练效果越好。从该检测结果的置信度来看,检测效果还不错。值得一提,如果想要检测视频的话,那么就直接将验证集里的数据换成视频格式的文件就好了(比如mp4),模型检测时会将视频一帧一帧地处理,在终端你可以查看到它的当前任务进度,随后会得到mp4文件并保存到runs\detect某个exp文件里,视频中会出现跳动的识别框。
至此,你已经可以自己尝试动手做模型训练啦,感谢你愿意浏览我这篇拙笔之作,希望它对你有所帮助!我是才疏学浅的雨心,本文出现纰漏在所难免,欢迎在评论区纠正我的错误。
————————【后记】————————————
分享一个可以免费下载数据集的网站,这是我最近发现的:超过 8000 个关于“森林火灾”和“森林”的免费视频、高清及 4K 视频片段 - Pixabay
至于其它获取数据集的途径,常见的还有github和以下链接等,都是从网上找到的:
http://academictorrents.com
https://github.com/awesomedata/awesome-public-datasets
https://blog.csdn.net/u012735708/article/details/82682673
https://www.cnblogs.com/ansang/p/8137413.html
http://vision.stanford.edu/resources_links.html
http://slazebni.cs.illinois.edu

















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









