







一、基础分类任务指标(二分类/多分类)
1. 混淆矩阵(Confusion Matrix)
- 定义:n×n矩阵(n为类别数),行表示真实类别,列表示预测类别
- 核心元素(以二分类为例):
- TP(真正例):正类预测为正类
- FP(假正例):负类预测为正类
- FN(假负例):正类预测为负类
- TN(真负例):负类预测为负类

2. 基础性能指标(二分类)
-
准确率(Accuracy):
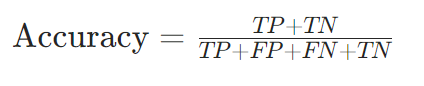
适用场景:数据平衡时全局性能评估,缺陷是对不平衡数据不敏感
-
精确率(Precision)(查准率):
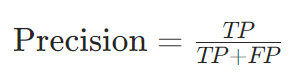
意义:预测为正类中实际为正类的比例,关注“误判”问题
-
召回率(Recall)(查全率/灵敏度Sensitivity):
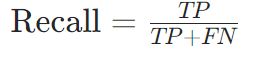
意义:实际正类中被正确预测的比例,关注“漏判”问题
-
特异度(Specificity):
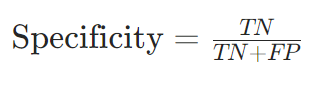
意义:实际负类中被正确预测的比例,衡量对负类的识别能力
3. 综合指标(二分类)
-
F1分数:
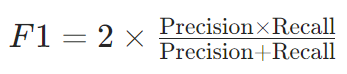
调和平均特性:平衡精确率与召回率,解决算术平均对极端值不敏感问题
-
P-R曲线(Precision-Recall Curve):
- 横轴召回率,纵轴精确率,曲线下面积(AUC-PR)反映综合性能
- 优势:在不平衡数据中比ROC曲线更有效
-
ROC曲线(Receiver Operating Characteristic):
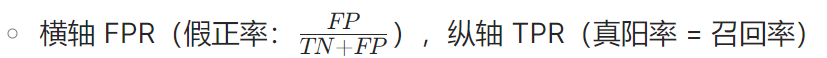
- AUC-ROC(曲线下面积):取值[0,1],0.5表示随机分类,1为完美分类
- AUC-ROC(曲线下面积):取值[0,1],0.5表示随机分类,1为完美分类
4. 多分类扩展指标
-
宏平均(Macro-average):
对每个类别单独计算指标(如Precision),再取算术平均
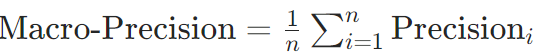
-
微平均(Micro-average):
全局计算TP、FP、FN后再计算指标
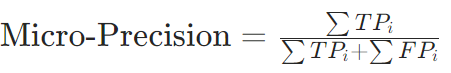
-
加权平均(Weighted-average):
按每个类别的样本数加权平均
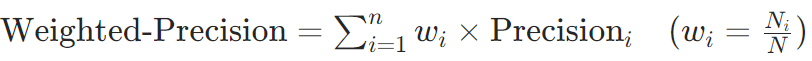
二、回归任务指标
1. 绝对误差指标
-
平均绝对误差(MAE):
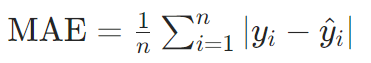
特性:对异常值鲁棒性强
-
平均绝对百分比误差(MAPE):
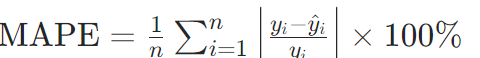
注意:y=0时无定义,需特殊处理
2. 平方误差指标
-
均方误差(MSE):
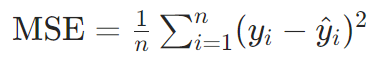
特性:放大异常值影响,梯度计算友好(平方可导)
-
均方根误差(RMSE):
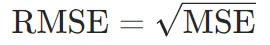
优势:与预测值量纲一致,更易解释
3. 相对误差指标
-
决定系数(R² Score):
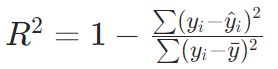
意义:模型解释数据方差的比例,1表示完美预测,<0表示不如基线模型
三、序列与结构化输出任务指标
1. 自然语言处理(NLP)
-
BLEU分数(双语评估辅助):
-
计算预测序列与参考序列的n-gram匹配度,常用于机器翻译
-
公式:
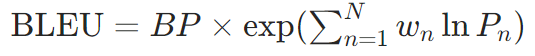
(BP为长度惩罚因子,( P n P_n Pn)为n元组精确率)
-
-
ROUGE(召回导向文本相似度):
- 基于召回率计算n-gram重叠,用于摘要任务
- 包含ROUGE-1(单字)、ROUGE-2(双字)、ROUGE-L(最长公共子序列)
2. 计算机视觉(CV)
-
交并比(IoU,Intersection over Union):
-
目标检测/语义分割基础指标:
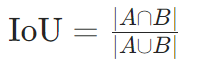
-
扩展:mIoU(多类别平均IoU)
-
-
平均精度均值(mAP,Mean Average Precision):
- 目标检测核心指标:
- 对每个类别计算AP(P-R曲线下面积)
- 所有类别AP的平均值
- 常带后缀(如mAP@0.5,mAP@[0.5:0.95])表示不同IoU阈值下的评估
- 目标检测核心指标:
3. 序列标注
- 序列准确率(Sequence Accuracy):预测标签序列与真实完全一致的比例
- 标记级别F1:每个位置独立计算F1后取平均(忽略序列顺序)
四、生成模型与复杂任务指标
1. 图像生成
-
inception分数(IS,Inception Score):
- 基于预训练Inception模型,衡量生成图像的多样性(熵)和真实性(条件概率)
- 公式:
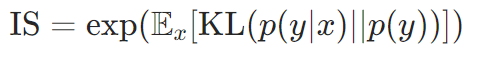
-
弗雷歇初始距离(FID,Frechet Inception Distance):
- 计算生成图像与真实图像在Inception特征空间的均值和协方差距离
- 比IS更敏感于分布差异,避免模式崩溃问题
2. 文本生成
-
困惑度(Perplexity):语言模型核心指标,衡量预测下一个词的不确定性
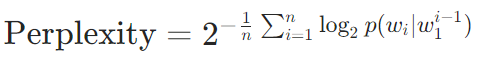
-
人工评估指标:如人类评分(Human Ratings)、ATEC(文本生成评估基准)
五、特殊场景与进阶指标
1. 不平衡数据处理
-
几何平均(G-mean):
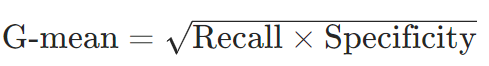
优势:平衡正负类召回率,适用于类别失衡场景
-
Cost-sensitive指标:引入误分类成本矩阵,计算加权误差
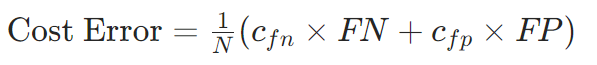
2. 模型复杂度与效率
- 参数量(Parameters):模型可训练参数总数,反映存储成本
- 浮点运算量(FLOPs):每秒浮点运算次数,衡量计算复杂度
- 推理速度(Latency):单样本前向传播时间(ms/样本),受硬件影响
- 内存占用(Memory Usage):运行时显存/内存消耗,影响部署可行性
3. 鲁棒性与安全性
- 对抗鲁棒性指标:
- 对抗样本成功率(Adversarial Success Rate)
- 干净样本 vs 对抗样本的准确率下降幅度
- 对抗训练评估:在FGSM、PGD等攻击下的性能保持能力
4. 长尾分布与少样本学习
- 长尾指标:评估稀有类别上的Recall@K、F1-score
- 小样本指标:Few-shot场景下的元学习准确率、遗忘曲线
六、多任务与多输出指标
1. 多任务学习
- 联合指标:对每个任务指标加权平均(如分类准确率+回归MSE)
- 任务平衡度:各任务性能方差,避免优势任务主导优化
2. 多标签分类(每个样本可属多个类别)
- 标签级别指标:对每个标签独立计算Precision/Recall,再取宏/微平均
- 样本级别指标:
-
汉明损失(Hamming Loss):错误标签比例
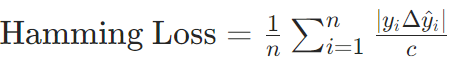
(Δ为对称差集,c为总标签数)
-
七、指标选择原则与陷阱
- 任务匹配:分类用准确率/F1,回归用MSE/R²,生成用FID/IS
- 数据分布:不平衡数据避免单纯依赖准确率,使用G-mean或加权指标
- 业务导向:医疗场景优先Recall(减少漏诊),推荐系统优先Precision(减少误推)
- 多指标组合:单一指标无法全面评估,需结合业务目标构建指标体系
- 避免指标欺骗:高准确率可能掩盖类别不平衡问题,AUC-ROC在极度不平衡时可能虚高
八、前沿扩展(研究级指标)
- 校准误差(Calibration Error):模型置信度与实际准确率的一致性,如ECE(Expected Calibration Error)
- 公平性指标:不同子群体间的性能差异(如性别/种族的分类准确率差异)
- 可解释性指标:显著性图的像素重要性分布、模型决策的逻辑一致性
- 时间序列指标:动态时间规整(DTW)距离、自相关函数匹配度
总结
深度学习评价指标体系需根据任务类型(分类/回归/生成)、数据特性(平衡/不平衡/长尾)、应用场景(医疗/推荐/安全)综合选择。核心是理解每个指标的数学定义、适用边界及业务含义,避免单一指标依赖,构建多维评估框架。实际应用中,常需结合领域知识设计定制化指标(如语音识别的WER,视频理解的mAP@N帧),并注意指标与优化目标的一致性(如优化MSE时R²可能非单调变化)。


















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









