







一、核心定义与本质
在卷积神经网络(CNN)中,感受野指特征图上某个神经元对应的原始输入图像的区域大小,即该神经元在输入图像中“看到”的空间范围。它决定了神经元整合信息的空间尺度,是CNN实现从局部到全局特征提取的关键机制。
- 本质:感受野反映了神经元对输入图像中不同区域的依赖程度,是卷积操作“空间连接性”的直接体现。
- 核心问题:如何通过卷积参数设计,让神经元有效捕获任务所需的局部细节(如边缘)或全局上下文(如物体整体结构)。
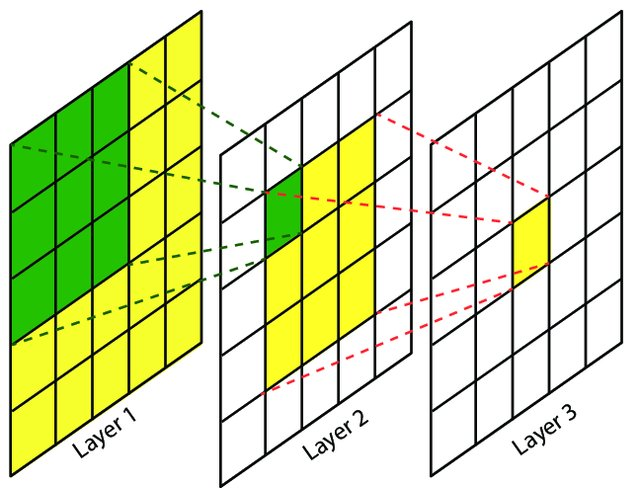
二、单层感受野计算(基础公式)
设单层卷积层参数为:
- 卷积核大小 (k)(如3×3、5×5),
- 步长 (s)(默认 (s=1)),
- 填充 (p)(单侧填充,默认 (p=0)),
- 空洞率 (d)(默认 (d=1),即普通卷积)。
1. 普通卷积((d=1))
- 无填充((p=0)):感受野大小等于卷积核大小,即 (RF = k)。
- 有填充((p>0)):填充不改变感受野大小(仅影响输入尺寸),感受野仍为 (k)。
2. 空洞卷积(扩张卷积,(d>1))
-
卷积核的“有效采样间隔”为 (d),实际覆盖的输入区域大小为: 有效核大小 = k + (k-1)(d-1)
例如,(k=3, d=2) 时,有效核大小为 (3 + 2×1 = 5),感受野为 5(相当于5×5普通卷积的感受野,但仅计算3×3个参数)。

需要的参数更少了,这在很多情况下是非常重要的。
三、多层级联感受野计算(核心递推公式)
设网络有 (L) 层,从输入层到输出层依次为第1层到第(L)层。
1. 正向递推(从输入到输出)
第
l
l
l 层的感受野
R
F
l
RF_l
RFl由前一层感受野
R
F
l
−
1
RF_l-1
RFl−1 和当前层参数决定:
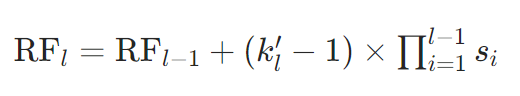
其中, k l ′ k_l' kl′ 为第 l l l 层的有效核大小(考虑空洞率), s i s_i si 为第 i i i 层的步长。
2. 反向递推(从输出到输入,更常用)
从输出层(假设感受野为1,对应特征图上一个点)倒推输入层感受野:
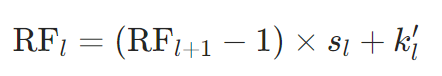
示例:两层3×3普通卷积((s=1, d=1))
- 第2层(输出层):初始 R F 2 RF_2 RF2 = 1
- 第1层(输入层): R F 1 RF_1 RF1 = (1-1)×1 + 3 = 3(单层感受野)
- 若再加第三层3×3卷积((s=1)): R F 0 RF_0 RF0 = (3-1)×1 + 3 = 5
3. 含步长的多层计算((s>1))
两层3×3卷积,第1层步长 (s_1=2),第2层步长 (s_2=1):
- R F 2 RF_2 RF2 = 1
- R F 1 RF_1 RF1 = (1-1)×1 + 3 = 3
- R F 0 RF_0 RF0 = (3-1)×2 + 3 = 7
四、有效感受野(Effective Receptive Field)
1. 理论 vs 实际感受野
- 理论感受野:假设卷积核内所有像素对输出的贡献均等(数学上的“全连接”区域)。
- 实际感受野:由于卷积操作的权重分布和非线性激活(如ReLU),边缘像素的贡献呈高斯分布(中心区域权重高,边缘权重指数衰减),实际有效区域远小于理论值。
- 研究表明,有效感受野约为理论感受野的 1/3~1/2,且随网络深度增加,分布更趋近高斯模糊。
2. 数学本质
输出神经元的值是输入区域的加权和,权重由卷积核参数和网络层级联决定。边缘像素的权重因多层卷积的累积效应而降低,形成“中心偏倚”。
五、核心影响因素(参数设计指南)
1. 卷积核大小((k))
- 直接扩大初始范围:更大的核(如5×5)单层感受野更大,但增加参数(5×5核参数是3×3的2.78倍)。
- 实际应用:浅层常用3×3核(平衡感受野与参数效率),深层可通过空洞卷积间接扩大感受野。
2. 步长((s)
- 控制下采样速率:(s=2) 使感受野覆盖间隔像素,加速下采样,但可能导致细节丢失(如小目标漏检)。
- 注意:步长影响感受野的“跳跃性”,过大步长(如(s>2))可能导致有效感受野覆盖不连续区域。
3. 空洞率((d)
- 无参数扩大感受野:通过插入“空洞”增加采样间隔,在不增加计算量的前提下扩大感受野(如ResNet中的空洞卷积用于语义分割)。
- 潜在问题:空洞率过大(如(d>3))可能导致“棋盘效应”(采样点稀疏,特征不连续)。
4. 网络深度
- 层级递增性:每增加一层,感受野按步长乘积的比例扩大。例如,10层3×3、(s=1) 的网络,感受野为 (1 + 2×10 = 21)(反向递推)。
- 过深网络的挑战:深层感受野可能包含过多无关背景,需结合注意力机制(如SE模块)聚焦有效区域。
六、在网络架构设计中的应用
1. 浅层网络(低层级)
- 作用:捕捉边缘、纹理等局部特征,感受野小(如3×3、5×5)。
- 典型案例:AlexNet的前两层使用11×11((s=4))和5×5卷积,快速扩大感受野以捕捉图像整体结构。
2. 深层网络(高层级)
- 作用:整合全局上下文(如物体类别、场景布局),感受野大(如ResNet-50的最后一层感受野覆盖整个输入图像)。
- 挑战:深层特征分辨率低,需通过跳跃连接(如ResNet残差连接)或多尺度融合(如FPN)保留细节。
3. 特定任务优化
(1)目标检测
- 小目标:需浅层特征(高分辨率+小感受野),常用特征金字塔(FPN)融合多层特征。
- 大目标:深层大感受野捕捉整体形状,如RetinaNet的深层卷积层配合大 anchors。
(2)语义分割
- 矛盾:需要高分辨率(保留细节)和大感受野(全局上下文)。
- 解决方案:
- 空洞卷积(DeepLab系列):在不降低分辨率的前提下扩大感受野。
- 金字塔池化(PSPNet):通过不同尺度的池化层融合多感受野特征。
(3)图像分类
- 关键:深层大感受野整合全局信息,如VGGNet通过堆叠3×3卷积(每两层扩大感受野4)实现高效特征提取。
七、高级技术与研究进展
1. 空洞卷积(Dilated Convolution)
- 核心优势:在保持分辨率和参数数量的同时,指数级扩大感受野。
- 例:3层3×3空洞卷积,(d) 分别为1、2、4,感受野为 (3 + 2×1 + 2×2 + 2×4 = 15)(等效于15×15普通卷积,但参数仅3×3×3=27)。
- 应用场景:语义分割(DeepLab v3+)、图像生成(扩大上下文依赖)。
2. 可变形卷积(Deformable Convolution)
- 突破固定形状:卷积核的采样点可自适应偏移(学习偏移量Δx, Δy),使感受野形状适应物体轮廓(如弯曲边缘、不规则物体)。
- 效果:在目标检测(如Deformable R-CNN)中,感受野可动态“聚焦”物体区域,提升对不规则目标的检测精度。
3. 动态感受野机制
- CondConv:根据输入动态选择卷积核参数(包括核大小、空洞率),实现“按需调整”感受野。
- GCNet:通过全局上下文建模(如空间注意力),显式增强有效感受野的权重分布,抑制无关背景。
4. 感受野可视化技术
- 反卷积(DeconvNet):将特征图反向映射到输入图像,直观显示感受野区域。
- 类激活映射(CAM):通过梯度反向传播,定位对分类结果贡献最大的输入区域(如识别“猫”时,聚焦眼睛、胡须等局部感受野)。
八、常见误区与最佳实践
1. 误区澄清
- 填充不影响感受野:填充仅改变输入尺寸,感受野由卷积核和步长决定(如3×3、(p=1)、(s=1) 的感受野仍为3)。
- 深层感受野一定更好:过大感受野可能包含噪声,需结合任务调整(如小目标检测需浅层特征)。
2. 最佳参数设计
- 浅层:3×3核 + (s=1) + 适度空洞(如(d=1)),捕捉局部细节。
- 中层:引入(s=2) 下采样,配合空洞卷积((d=2))维持感受野增长,避免分辨率骤降。
- 深层:可变形卷积 + 注意力机制,动态优化感受野形状和权重分布。
九、总结:感受野的核心价值
- 特征尺度调节器:通过卷积参数((k, s, d))精确控制神经元的信息整合范围,实现从局部到全局的特征层级构建。
- 网络优化基石:指导架构设计(如ResNet的残差连接平衡深度与感受野)、任务适配(如FPN的多尺度感受野融合)。
- 跨技术融合桥梁:与注意力机制(聚焦有效区域)、动态卷积(自适应调整)结合,推动CNN向更智能的特征提取范式发展。
掌握感受野的计算与设计,是理解CNN如何“看”图像的关键,也是解决视觉任务(检测、分割、生成)的核心突破口。未来,随着动态感受野、自监督学习的发展,其理论与应用将持续深化。


















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









