






一、任务目标与重点
-
理解时间序列数据预处理的重要性:数据预处理是时间序列分析的基础,直接影响模型的性能。
-
掌握标准化方法:将数据缩放到统一尺度,避免不同特征之间的量纲差异。
-
掌握去噪方法:去除数据中的噪声,提高数据的质量。
-
掌握分段处理方法:将长时间序列划分为多个短序列,适应模型的输入要求。
二、学习内容与步骤
1. 时间序列数据预处理概述
时间序列数据预处理的目标是提高数据质量,使其更适合模型训练。常见的预处理方法包括:
-
标准化:将数据缩放到统一尺度。
-
去噪:去除数据中的噪声。
-
分段处理:将长时间序列划分为多个短序列
2. 标准化方法
标准化是将数据缩放到统一尺度的方法,常见的标准化方法包括:
(1)Z-score标准化
-
将数据转换为均值为0、标准差为1的分布。
-
公式:
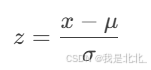
其中,μ是均值,σ是标准差。
(2)Min-Max标准化
-
将数据缩放到[0, 1]区间。
-
公式:
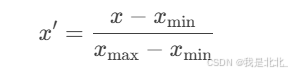
示例代码:
import numpy as np
# Z-score标准化
def z_score_normalization(data):
mean = np.mean(data)
std = np.std(data)
return (data - mean) / std
# Min-Max标准化
def min_max_normalization(data):
min_val = np.min(data)
max_val = np.max(data)
return (data - min_val) / (max_val - min_val)
# 测试标准化方法
data = np.array([1, 2, 3, 4, 5])
print("Z-score标准化:", z_score_normalization(data))
print("Min-Max标准化:", min_max_normalization(data))3. 去噪方法
去噪是去除数据中噪声的过程,常见的去噪方法包括:
(1)移动平均法
-
通过计算滑动窗口内的平均值来平滑数据。
-
公式:
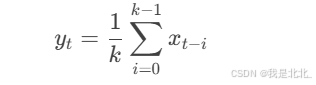
其中,kk是滑动窗口的大小。
(2)低通滤波
-
通过滤波器去除高频噪声,保留低频信号。
-
可以使用
scipy.signal库中的butter和filtfilt函数实现。
代码示例:
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import butter, filtfilt
# 移动平均法
def moving_average(data, window_size):
return np.convolve(data, np.ones(window_size)/window_size, mode='valid')
# 低通滤波
def low_pass_filter(data, cutoff, fs, order=5):
nyquist = 0.5 * fs
normal_cutoff = cutoff / nyquist
b, a = butter(order, normal_cutoff, btype='low', analog=False)
return filtfilt(b, a, data)
# 测试去噪方法
t = np.linspace(0, 1, 500)
data = np.sin(2 * np.pi * 5 * t) + 0.5 * np.random.normal(size=500)
# 移动平均法
smoothed_data = moving_average(data, window_size=10)
# 低通滤波
filtered_data = low_pass_filter(data, cutoff=3, fs=30)
# 可视化结果
plt.figure(figsize=(12, 6))
plt.plot(t, data, label='原始数据')
plt.plot(t[9:], smoothed_data, label='移动平均法')
plt.plot(t, filtered_data, label='低通滤波')
plt.legend()
plt.show()4. 分段处理方法
分段处理是将长时间序列划分为多个短序列的过程,常见的分段方法包括:
(1)固定长度分段
-
将时间序列划分为固定长度的子序列。
-
示例代码:
-
def segment_data(data, segment_length): num_segments = len(data) // segment_length segments = np.array_split(data[:num_segments * segment_length], num_segments) return segments # 测试分段处理方法 data = np.arange(100) segments = segment_data(data, segment_length=10) print("分段结果:", segments)(2)滑动窗口分段
-
使用滑动窗口生成重叠的子序列。
-
示例代码:
def sliding_window_segment(data, window_size, step):
segments = []
for i in range(0, len(data) - window_size + 1, step):
segments.append(data[i:i+window_size])
return segments
# 测试滑动窗口分段
data = np.arange(100)
segments = sliding_window_segment(data, window_size=10, step=5)
print("滑动窗口分段结果:", segments)三、建议与注意事项
-
理解每种方法的应用场景:标准化适用于不同量纲的数据,去噪适用于噪声较多的数据,分段处理适用于长时间序列。
-
调试代码:在编写代码时,逐步测试每一部分的功能,确保代码正确运行。
-
可视化结果:通过可视化方法(如Matplotlib)观察预处理前后的数据变化,直观理解预处理的效果。
-
参考文档:查阅相关库的官方文档(如NumPy、SciPy),深入学习函数的用法和参数。

















 3288
3288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









