






时序数据预处理
对于数据科学来说,凡事“预”则立,不“预”则废。数据的质量直接决定数据挖掘的结果。本文旨在一站式的梳理时序数据的预处理步骤。
数据预处理的目的是将脏数据变成我们想要的干净的数据,这里的干净指的是:
- 准确
- 完整
- 简单
- 一致
- 平稳(大多数时序数据以平稳性作为假设,但也有例外)
- 面向模型性能,这是一切的核心!
主要步骤(按先后顺序)为:
- 数据清洗 --> 保证准确性和完整性
- 数据集成 --> 保证一致性
- 数据转换
- 数据规约(或特征提取)
- 数据集划分
- 其他处理
本文基于pandas和sklearn给出示例。偏重实际应用场景,省略数学原理。
1. 数据清洗
数据清洗主要解决四个问题:
- 去除重复项
- 缺失值
- 离群点
- 噪声
在一切开始前,应尽可能了解所有字段的含义,并作如下操作:
- 将不能反映分布规律的数据去除掉。比如车辆运行数据中的VIN号等。
- 明确区分数值字段和分类字段。任何操作都要注意区分数值型和分类型。
1.1去除重复项(时间戳)
时序数据中的重复项一般认为是重复记录或输入错误导致的错误数据,多处重复只保留第一项。
一般使用DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
import pandas as pd
print(df) # 去除重复项前
Time Value
0 2021-01-01 00:00:00 1
1 2021-01-01 00:00:00 1
2 2021-01-01 00:01:00 2
df_deduplicated = df.drop_duplicates(subset=["Time"]) # 去除重复项
print(df_deduplicated) # 去除重复项后
Time Value
0 2021-01-01 00:00:00 1
2 2021-01-01 00:01:00 2
1.2 缺失值
一般采取填充的方法处理缺失值。时序数据前后相互关联,不建议使用定值填充(作为区分,非时序数据经常用类似-9999这样的值来标识缺失值。)。
1.2.1 删除无效变量
若某一字段缺失值非常多,以至于它的分布规律已经没有意义了,应当首先将它们删除。使用DataFrame.isnull().mean()统计缺失值比例,找到你希望删除的字段,并用DataFrame.drop()方法将他们删除。
print(df) # 假设的数据
A B C
0 1.0 NaN 1
1 NaN NaN 2
2 3.0 NaN 3
3 4.0 NaN 4
4 5.0 2.0 5
missing_percentage = df.isnull().mean() # 统计每个字段缺失值比例
A 0.2
B 0.8
C 0.0
# 假设我们希望删除缺失比例超过50%的字段
columns_to_drop = missing_percentage[missing_percentage > 0.5].index
Index(['B'], dtype='object') # B列即为我们要删除的字段
df_dropped = df.drop(columns=columns_to_drop) # 删这一列列
A C
0 1.0 1
1 NaN 2
2 3.0 3
3 4.0 4
4 5.0 5
1.2.2 邻值填充
**仅数值型做邻值填充,分类数据是否可以做邻值填充要看具体的字段含义。**邻值填充就是用最近时刻的值来填充,可向前或向后填充。使用fillna()方法,指定method='ffill'进行前向填充,method='bfill'进行后向填充。
print(df) # 假设的数据
A
2023-03-01 0.359814
2023-03-02 -0.323262
2023-03-03 NaN
2023-03-04 -0.270505
2023-03-05 2.242180
2023-03-06 0.382071
df_ffill = df.fillna(method='ffill') # 前向填充
print(df_ffill) # 填充结果
A
2023-03-01 0.359814
2023-03-02 -0.323262
2023-03-03 -0.323262
2023-03-04 -0.270505
2023-03-05 2.242180
2023-03-06 0.382071
1.2.3 插值填充
**仅适用数值型。**邻值填充的方法看起来有点呆。针对时序数据的平滑性,使用插值方法填充更加接近真实数据。
pandas有多种插值的方法,如线性插值、多项式插值等等…
最常用的是DataFrame.interpolate()线性插值。
print(df_time_series) # 假设的数据
Value
Time
2023-01-01 1.0
2023-01-02 NaN
2023-01-03 NaN
2023-01-04 4.0
2023-01-05 5.0
2023-01-06 NaN
df_interpolated = df_time_series.interpolate() # 线性插值
print(df_interpolated) # 插值后的数据
Value
Time
2023-01-01 1.0
2023-01-02 2.0
2023-01-03 3.0
2023-01-04 4.0
2023-01-05 5.0
2023-01-06 5.0
1.2.4 模型填充
无论是线性插值还是诸如多项式法、牛顿插值等算法,都是假定了数据符合某种极为特殊的分布规律。但有时数据未必符合这样的分布规律,或多项数据之间有极为复杂的关系,这时简单的插值不能满足需要。则需要使用机器学习算法进行预测插值,这样的方法我称为模型填充。
数值型数据使用回归算法,如线性回归等。分类型数据使用分类算法,如随机森林等。
模型填充较为复杂,会消耗更多的计算资源,使用前既要应当充分评估其必要性,也要考虑到个字段之间的复杂关系。
1.2.5 哑变量填充
哑变量严格来说不是针对缺失值的处理,而是针对模型训练和预测的一种技巧。既适用于分类型,也适用于数值型。
- 分类型一般是将一个字段拆分成多个字段,每个字段的取值是
Ture或False。比如字段性别可以拆分为男性、女性和其他三个字段。分类型哑变量填充可以有缺失值。使用pd.get_dummies()进行哑变量填充。
print(df) # 定义一个分类型的数据,注意unknow不是缺失值,Nan是缺失值
gender
0 male
1 female
2 unknow
4 NaN
df_with_dummies = pd.get_dummies(df, prefix='gender') # 哑变量填充
print(df_with_dummies) # 转换为哑变量后的结果
gender_female gender_male gender_unknow
0 False True False
1 True False False
2 False False True
4 False False False
- 数值型的哑变量填充主要是用“分箱”的方法将其离散化(可以看作是转变为分类型数据)。比如人的年龄,变化1岁的影响是微小的,我们关心的是更大跨度的变化。因此我们将
年龄这一字段拆分为18-25、26-35… 每个字段的取值还是Ture或False。一般这种方法不作为缺失值。使用pd.cut()进行分箱操作
print(df) # 定义一个连续型的数据
Age
0 22
1 27
2 34
3 45
4 55
5 63
# 分箱操作
age_bins = [18, 25, 35, 45, 55, 65, 75]
age_labels = ['18-25', '26-35', '36-45', '46-55', '56-65', '66-75']
df['AgeGroup'] = pd.cut(df['Age'], bins=age_bins, labels=age_labels, right=False)
print(df) # 分箱后的结果
Age AgeGroup
0 22 18-25
1 27 26-35
2 34 26-35
3 45 46-55
4 55 56-65
5 63 56-65
df_dummies = pd.get_dummies(df['AgeGroup'], prefix='Age') # 哑变量填充后的结果
Age_18-25 Age_26-35 Age_36-45 Age_46-55 Age_56-65 Age_66-75
0 True False False False False False
1 False True False False False False
2 False True False False False False
3 False False False True False False
4 False False False False True False
5 False False False False True False
1.3 异常值处理
异常值是脱离常规数据分布的值,一般指的是数值型数据。
异常值的处理一般分为两步:识别异常值和处理异常值。
处理异常值相对来说比较简单:直接删除,或者用处理缺失值的方法填充。本节的重点在于识别异常值。
在处理异常值之前,必须要掌握数据的分布状态,一般用分布直方图的显示。
import matplotlib.pyplot as plt
# 生成数据
np.random.seed(0)
df = pd.DataFrame(np.random.randn(100, 1), columns=['Value'])
# 添加异常值
df.iloc[20] = 3.5
df.iloc[40] = -3.8
df.iloc[80] = 3.2
# 画分布直方图
plt.figure(figsize=(10, 6))
plt.hist(df['Value'], bins=20, edgecolor='black')
plt.title('Value Distribution Histogram')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()

1.3.1 标准差方法
标准差方法(standard deviation, SD)是对于正态分布的数据,认为超过均值三倍标准差的值为离群点。善用pandas提供的DataFrame.describe()函数来查看统计数据。
print(df) # 假设的数据,100行
Value
2023-01-01 1.764052
2023-01-02 0.400157
2023-01-03 0.978738
2023-01-04 2.240893
2023-01-05 1.867558
...
2023-04-06 0.706573
2023-04-07 0.010500
2023-04-08 1.785870
2023-04-09 0.126912
2023-04-10 0.401989
df_des = data.describe() # df的统计数据
Value
count 100.000000 # 数据长度
mean 0.136475 # 平均值
std 1.137217 # 标准差
min -3.800000 # 最小值
25% -0.527816 # 25%分位数
50% 0.127948 # 50%分位数
75% 0.799227 # 75%分位数
max 3.500000 # 最大
threshold = 3 # 设定阈值
mean_val = float(df_des.loc['mean']) # 注意转浮点型
std_val = float(df_des.loc['std'])
# 找到超过均值三倍标准差的值
outliers = data[np.abs(data['Value'] - mean_val) > threshold * std_dev]
1.3.2 中位数绝对偏差
SD有一定的局限性:首先要求数据服从正态分布,其次对极端值非常敏感。中位数绝对偏差(median absolute deviation, MAD)修补了这两个局限性。
先计算出每个数据对中位数的绝对偏差,MAD就是这个绝对偏差的中位数。我们认为MAD大于一定值的数据为离群点。
print(df) # 假设的数据,100行
Value
2023-01-01 1.764052
2023-01-02 0.400157
2023-01-03 0.978738
2023-01-04 2.240893
2023-01-05 1.867558
...
2023-04-06 0.706573
2023-04-07 0.010500
2023-04-08 1.785870
2023-04-09 0.126912
2023-04-10 0.401989
# 计算mad
mad = np.abs(data['Value'] - float(data.describe().loc['50%'])).median()
# 定义阈值,这里取3
mad_threshold = 3 * mad
# 找到离群点
outliers = data[np.abs(data['Value'] -
float(data.describe().loc['50%'])) > mad_threshold]
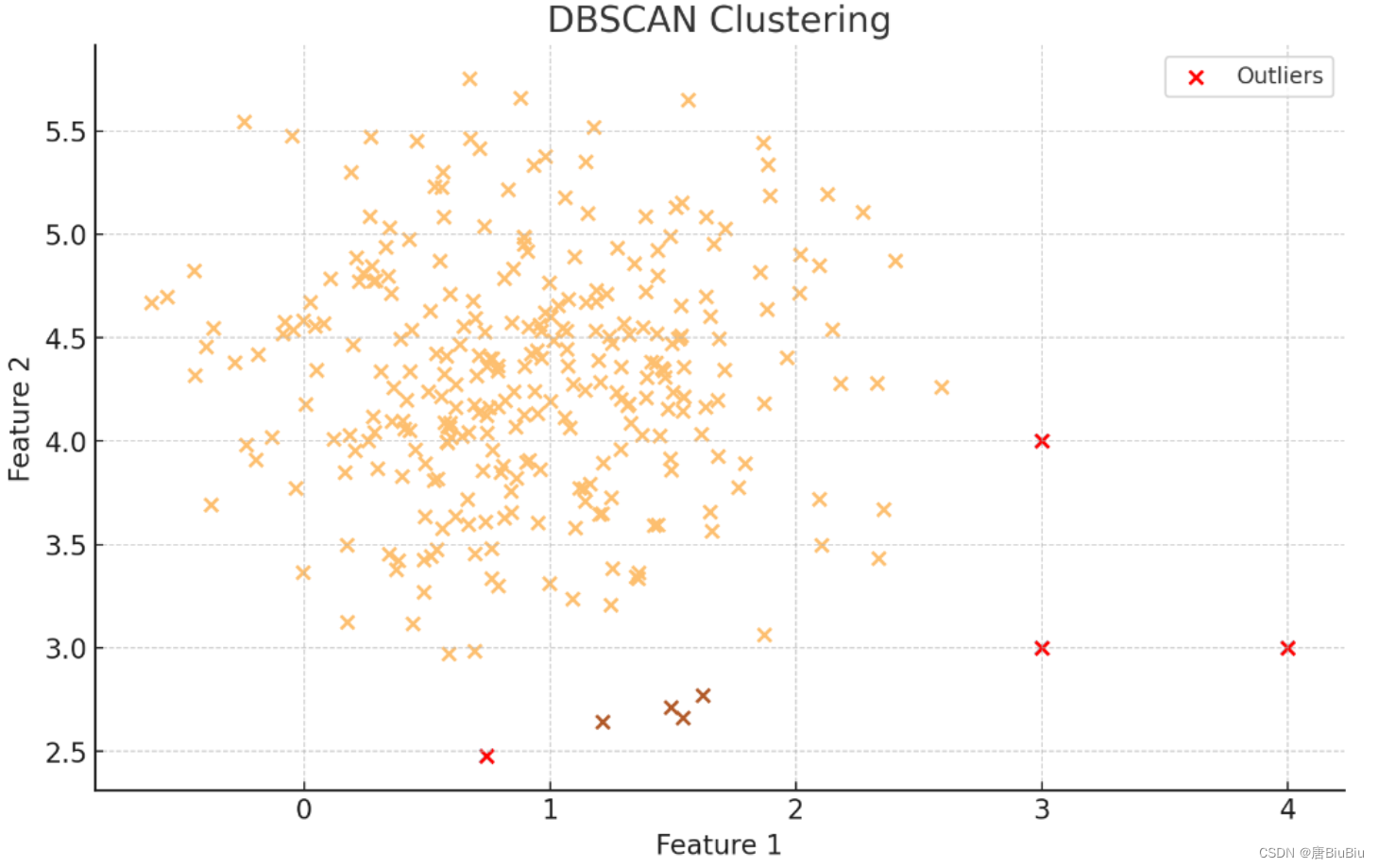
1.3.3 基于密度的异常值识别
MAD也有一定的局限性:首先MAD要求数据的对称分布的,对于偏态的数据中位数参考意义不大。其次MAD只能识别单变量的数据。
基于密度的离群点识别算法(Density-Based Spatial Clustering of Applications with Noise, DBSCAN),能处理偏态分布的多维数据异常值。
DBSCAN将数据分为核心点、边界点和离群点。
核心点:在一定范围的邻域内有一定数量相邻的点。
边界点:一个数据不是核心点,但他在核心点的邻域内。
离群点:以上两者之外的点。
邻域的范围和最小邻居数是DBSCAN的参数。使用sklearn实现DBSCAN:
from sklearn.cluster import DBSCAN
# 定义算法 eps为邻域范围,min_samples是最小邻居数
dbscan = DBSCAN(eps=0.5, min_samples=5)
clusters = dbscan.fit_predict(X)
# 可视化结果
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='Paired', edgecolor='k')
plt.title('DBSCAN Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
# 突出显示离群点
outliers = X[clusters == -1]
plt.scatter(outliers[:, 0], outliers[:, 1], color='red', label='Outliers')
plt.legend()
plt.show()
2. 数据集成
数据集成是将多个数据来源整合在一起。除了格式转换外,最主要的有三个问题:
- 数据描述的实体:首先要考虑数据与实体对应起来,比如
VIN码和车牌号可能都指向同一辆车。- 字段冗余:比如车辆的
油门踏板深度和加速踏板行程其实描述的是同一个变量(可能单位不同),这部分会在数据规约一节中详细说。- 数据冲突:比如一个人的
年龄是6岁,但出生日期是1968-01-26。出现冲突的数据至少有一个是错误的。
3.数据规约(特征选择)
所谓的数据规约就是让数据维度尽可能小,并且每个维度尽可能正交。
为了保证数据规约的性能,在规约之前一般先进行数据变换。
3.1 数据变换
数据变换的目的是使数据规范化、稀疏化、离散化。
3.1.1 归一化
归一化适用于数值类型,目的是消除量纲的影响,使各个维度的数据处于同一数量级。一般将数据映射到[0,1]的区间(当然亦可以是其他你想要的区间)。这种方法适用于数据集中的情况,不太需要考虑数据分布。但归一化容易受到极端值影响。
from sklearn.preprocessing import MinMaxScaler
print(df) # 假设的数据
Value
0 234
1 24
2 14
3 27
4 -74
5 46
6 73
7 -18
8 59
9 160
# 归一化
scaler = MinMaxScaler()
df_normalized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print(df_normalized)
Value
0 234.0
1 24.0
2 14.0
3 27.0
4 -74.0
5 46.0
6 73.0
7 -18.0
8 59.0
9 160.0
# 反归一化,将数据还原
df_reversed = pd.DataFrame(scaler.inverse_transform(df_normalized), columns=df_normalized.columns)
3.1.2 z-score 标准化
仅适用于数值型数据。基于距离的特征降维模型适合使用z-score 标准化,比如主成分分析等。标准化将原始数据集映射为均值为0、方差1的数据集。前提是原始数据集大致符合正态分布。
from sklearn.preprocessing import StandardScaler
# 使用上个示例的数据,进行标准化
scaler = StandardScaler()
df_standardized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print(df_standardized)
Value
0 2.162800
1 -0.367495
2 -0.487985
3 -0.331348
4 -1.548300
5 -0.102417
6 0.222907
7 -0.873554
8 0.054221
9 1.271172
# 反标准化,将数据还原
df_reversed = pd.DataFrame(scaler.inverse_transform(df_standardized), columns=df_standardized.columns)
还有如L2范数归一化、对数归一化、反正切函数归一化等等方法,不再一一列举,这里只说一下适用情况。
- L2范数归一化:将数据向量调整为单位范数,适合基于距离的分类模型。
- 对数归一化:适合数据分化非常大的情况
- 反正切函数归一化:适合数据范围未知或无界、希望保留正负号、对极端值有鲁棒性的情况
3.2 特征选择
特征可以分为三类,我们对待它们态度是不同的:
- 相关特征(保留):对于学习任务有帮助,可以提升学习算法的效果;
- 无关特征(剔除):对于我们的算法没有任何帮助,不会给算法的效果带来任何提升;
- 冗余特征(剔除):不会对我们的算法带来新的信息,或者这种特征的信息可以由其他的特征推断出;
特征选择就是把无用的特征揪出来,留下有用的特征。但还有一种脑洞大开的思路:创造新的正交的特征(PCA),这个我们最后说。
根据特征选择的形式,可分为三大类:
- Filter(过滤法):通过计算特征的相关性来过滤特征
- Wrapper(包装法):将数据集划分为若干子集,用子集来训练模型,选出表现最好的子集。
- Embedded(嵌入法):使用机器学习的模型进行训练,通过正则化方法
这三大类分别都有非常多的算法,下面仅能介绍少数几个经典的算法。
3.2.0 方差筛选
第0小节非常简单,把方差过小的特征去掉。使用sklearn.feature_selection.VarianceThreshold即可。
3.2.1 皮尔逊相关系数(Filter方法)
皮尔逊相关系数一般用于数值型数据,表征的是特征之间的线性关系,取值是[-1,1]。越接近0表示线性相关性越弱。pandas中内置计算相关系数的方法DataFrame.corr()。
import seaborn as sns
import matplotlib.pyplot as plt
# 注意我们构造的数据,Series1、2、3是相关的,Series4是随机的。
data = {
'Series1': np.linspace(1, 100, 100),
'Series2': np.linspace(100, 1, 100),
'Series3': np.linspace(1, 100, 100) + np.random.normal(0, 5, 100),
'Series4': np.random.normal(50, 10, 100)
}
df = pd.DataFrame(data, index=dates)
# 计算相关系数矩阵
corr_matrix = df.corr()
# 绘制相关系数热力图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap='coolwarm')
plt.title('Correlation Matrix Heatmap')
plt.show()

根据热力图,Series1、2、3是冗余特征,选择其中一个保留即可。
3.2.2 卡方验证(Filter方法)
经典的类别型数据相关性算法。尽管不一定适用于时序特征,但由于太经典还是要写一下经典示例:
import numpy as np
from sklearn.datasets import load_digits
from sklearn.feature_selection import SelectKBest, chi2
# 加载数据
digits = load_digits()
X, y = digits.data, digits.target
# 使用SelectKBest和卡方检验选择最佳的20个特征
kbest = SelectKBest(chi2, k=20)
X_new = kbest.fit_transform(X, y)
# 打印被选择的特征
print("Selected features:", kbest.get_support(indices=True))
# 打印每个被选择特征的卡方统计量
print("Chi2 scores of selected features:", kbest.scores_[kbest.get_support()])
3.2.3 互信息法
互信息法(Mutual Information,简称MI)适用于分类和数值型。相比皮尔逊相关系数,互信息能捕捉非线性的相关性。它利用了概率论和信息论的原理衡量两个分布的相似程度。互信息值是非负的,越大代表两个变量的信息依赖性越强,上限 是两个变量的信息熵中最小的值。一般我们选择与目标变量互信息值最大的几个特征。
from sklearn.feature_selection import mutual_info_classif as MIC
# 假设有特征矩阵X和目标变量y
result = MIC(X,y)
k = result.shape[0] - sum(result <= 0)
X_fsmic = SelectKBest(MIC, k=20).fit_transform(X, y)
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsmic,y,cv=5).mean()
3.2.4 递归特征消除(Wrapper方法)
递归特征消除(Recursive Feature Elimination, RFE)是递归的减少特征数量找到最合适的数据子集的方法,数值型和类别型的数据都适用。所有的Wrapper方法都不能离开回归或分类模型,示例选择随机森林回归和SVM方法。
from sklearn.feature_selection import RFE
# 假设有特征矩阵X和目标变量y
# SVM方法
from sklearn.svm import SVC
svc = SVC(kernel="linear", C=1)
selector = RFE(estimator=svc, n_features_to_select=3, step=1) # 选择三个特征
selector.fit(X, y)
print(selector.ranking_) # 打印特征排名
print(selector.support_) # 打印选中特征
# randomforest方法
from sklearn.ensemble import RandomForestRegressor
estimator = RandomForestRegressor(n_estimators=100)
selector = RFE(estimator, n_features_to_select=3, step=1)
selector = selector.fit(X, y)
print(selector.ranking_) # 打印特征排名
print(selector.support_) # 打印选中特征
3.2.5 正则化方法(Embedded方法)
正则化严格来说不是一种方法,而是一种思想:在机器学习的loss function中添加正则项,正则项能够使得模型在训练的过程中逐渐缩减解空间。这就要涉及到具体的机器学习模型了,本文不给出示例。
3.2.6 主成分分析(创造新的特征)
主成分分析(Principal Component Analysis,PCA)是将原始特征映射到一个新的空间中,使得在这个新的坐标系统的第一坐标轴上的数据方差最大,第二坐标轴上的数据方差次之,以此类推。由于这种映射是线性的,每个主成分是所有原始特征的线性组合,我们选取贡献率最高的若干主成分作为模型的输入特征,以实现降维的目的。sklearn的实现非常简洁:
from sklearn.decomposition import PCA
# 假设我们有原始特征矩阵X
pca = PCA(n_components=3) # 假设我们想要3个有效特征
X_pca = pca.fit(X) # X_pca就是我们算出来的主成分
explained_variance_ratio = X_pca.explained_variance_ratio_ # 每个主成分的贡献率
sum(explained_variance_ratio) # 累计贡献率,越接近1越好。用来确认3个主成分是否够用。
4 数据集划分
数据集划分本身没什么好说的,一般常用hold-out和k折交叉验证的方法。但我们经常会遇到样本不足的情况,这时会出现一些坑:
- 一定要考虑不同数据集的平衡性,比如你的分类问题使用5折交叉验证,但某些类别集中到少数几个集合里面,这时就会出现训练性能大幅下降的情况。
- 样本不足时我们总是想到做数据扩充。一定要注意数据集划分和扩充的顺序,先划分再扩充。如果顺序反了。扩充后同源的数据会泄露到多个数据集中,导致测试结果虚高。
















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









