






1.微调介绍

2.XTuner介绍


3.训练自己的小助手
先创建开发机,进入后进行环境的安装 ,
,
然后准备数据集,创建文件存放数据,打开Python文件将下面内容复制进去,
import json
# 设置用户的名字
name = '不要姜葱蒜大佬'
# 设置需要重复添加的数据次数
n = 10000
# 初始化OpenAI格式的数据结构
data = [
{
"messages": [
{
"role": "user",
"content": "请做一下自我介绍"
},
{
"role": "assistant",
"content": "我是{}的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦".format(name)
}
]
}
]
# 通过循环,将初始化的对话数据重复添加到data列表中
for i in range(n):
data.append(data[0])
# 将data列表中的数据写入到一个名为'personal_assistant.json'的文件中
with open('personal_assistant.json', 'w', encoding='utf-8') as f:
# 使用json.dump方法将数据以JSON格式写入文件
# ensure_ascii=False 确保中文字符正常显示
# indent=4 使得文件内容格式化,便于阅读
json.dump(data, f, ensure_ascii=False, indent=4)
然后准备模型,进行文件配置,修改后,就可以开始训练了。

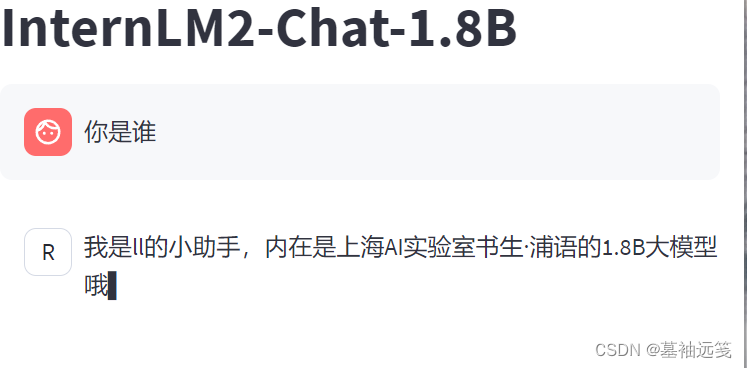
 可以发现到最后模型有些被过拟合了。
可以发现到最后模型有些被过拟合了。
4.Web demo
先下载依赖和InternLM的项目代码,然后存入文件夹。
# 创建存放 InternLM 文件的代码
mkdir -p /root/ft/web_demo && cd /root/ft/web_demo
# 拉取 InternLM 源文件
git clone https://github.com/InternLM/InternLM.git
# 进入该库中
cd /root/ft/web_demo/InternLM连接端口后,打开网址http://127.0.0.1:6006加载模型。















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









