










CLIP改进工作综述
前言
CLIP作为多模态对比学习里程碑式工作,在创新性,有效性和领域性三个方面都拉满了。本篇博客就来探讨在CLIP之后,各个领域是如何利用CLIP去提升当前领域的性能,以及如何利用CLIP信息整合的能力在多模态领域做大做强。
1. 语义分割
1.1 Lseg
LSeg是一种基于语言驱动的语义分割模型,通过将像素嵌入和相应的文本嵌入对齐,帮助模型学习多模态的特征表示。本质上,LSeg是基于CLIP做语义分割任务的模型,其零样本的表现如下图所示:
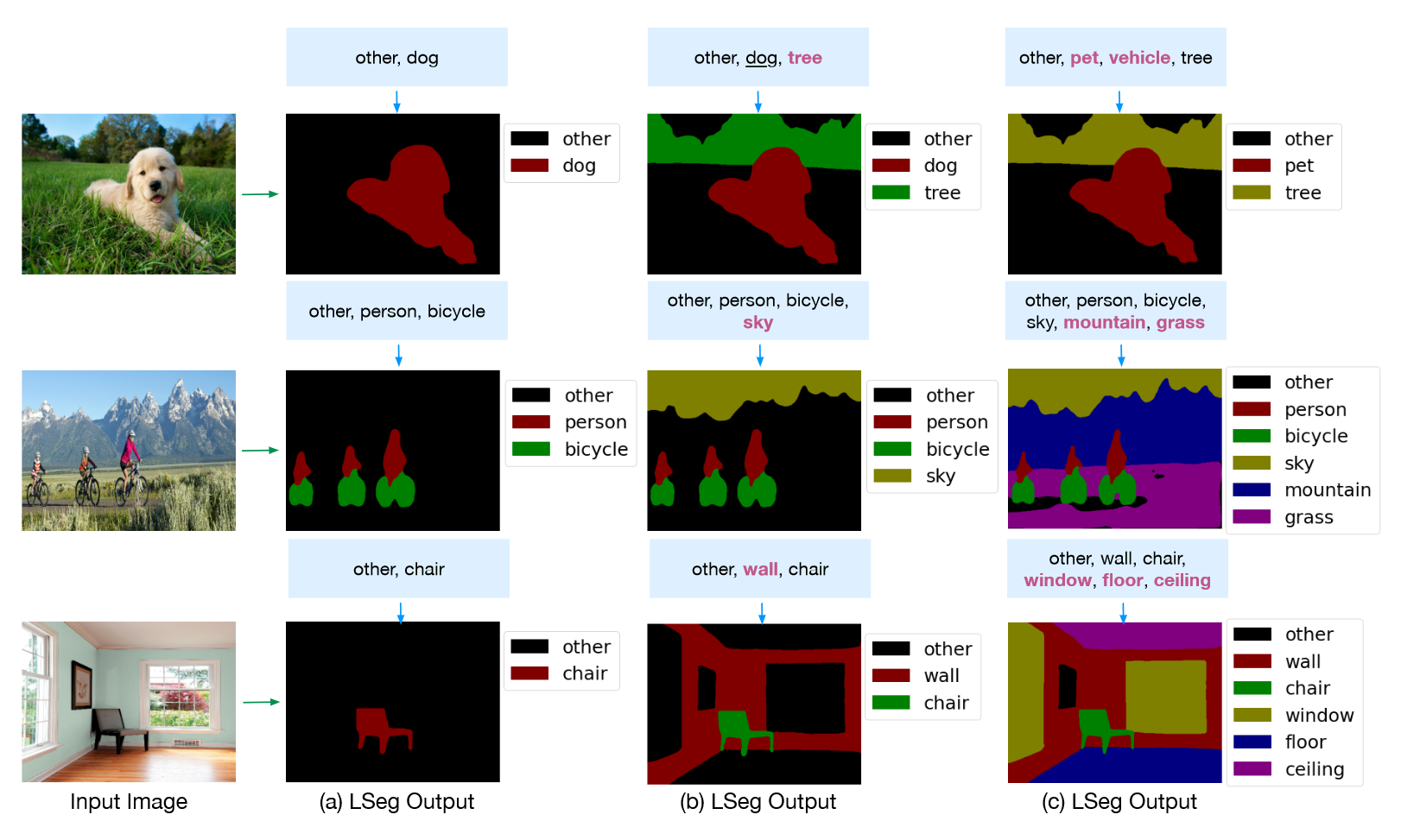
LSeg整体流程如下图所示,形式上和CLIP几乎一致,只是多了下游任务的过程。首先将图像和文本分别输入各自编码器中,图像的编码器是DPT模型,由ViT和decoder模块组成,decoder的目的是将降维的特征scale up,匹配语义分割任务。接着将具有相同通道大小的图像编码和文本编码相乘,将结果输入到空间正则化块得到分割结果。
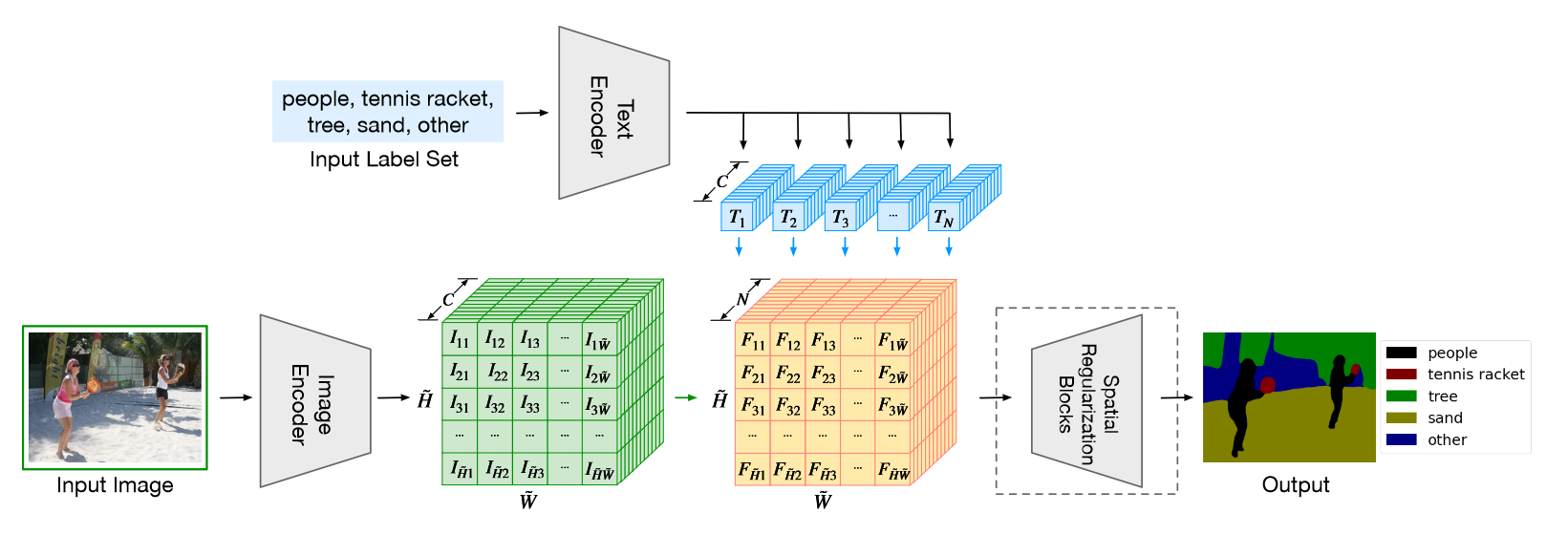
LSeg本质上还是和CLIP有很大区别的,首先其文本编码器就是采用的CLIP中的文本编码器,并且冻住参数不让其更新。这是因为分割领域的数据集规模都很小,如果进行微调,很容易造成训练不稳定,将模型带跑偏,不如就用原始的优良的CLIP文本编码器参数。其次,这里并没有选择无监督对比学习的方式训练,而是采用有监督的ground-truth,通过交叉熵计算损失,这里的思想就是将文本语义信息融入到图像中,通过有监督的方式将文本和图像编码对齐,这种方式最大的缺陷在于并没有真正学习到文本的语义信息。
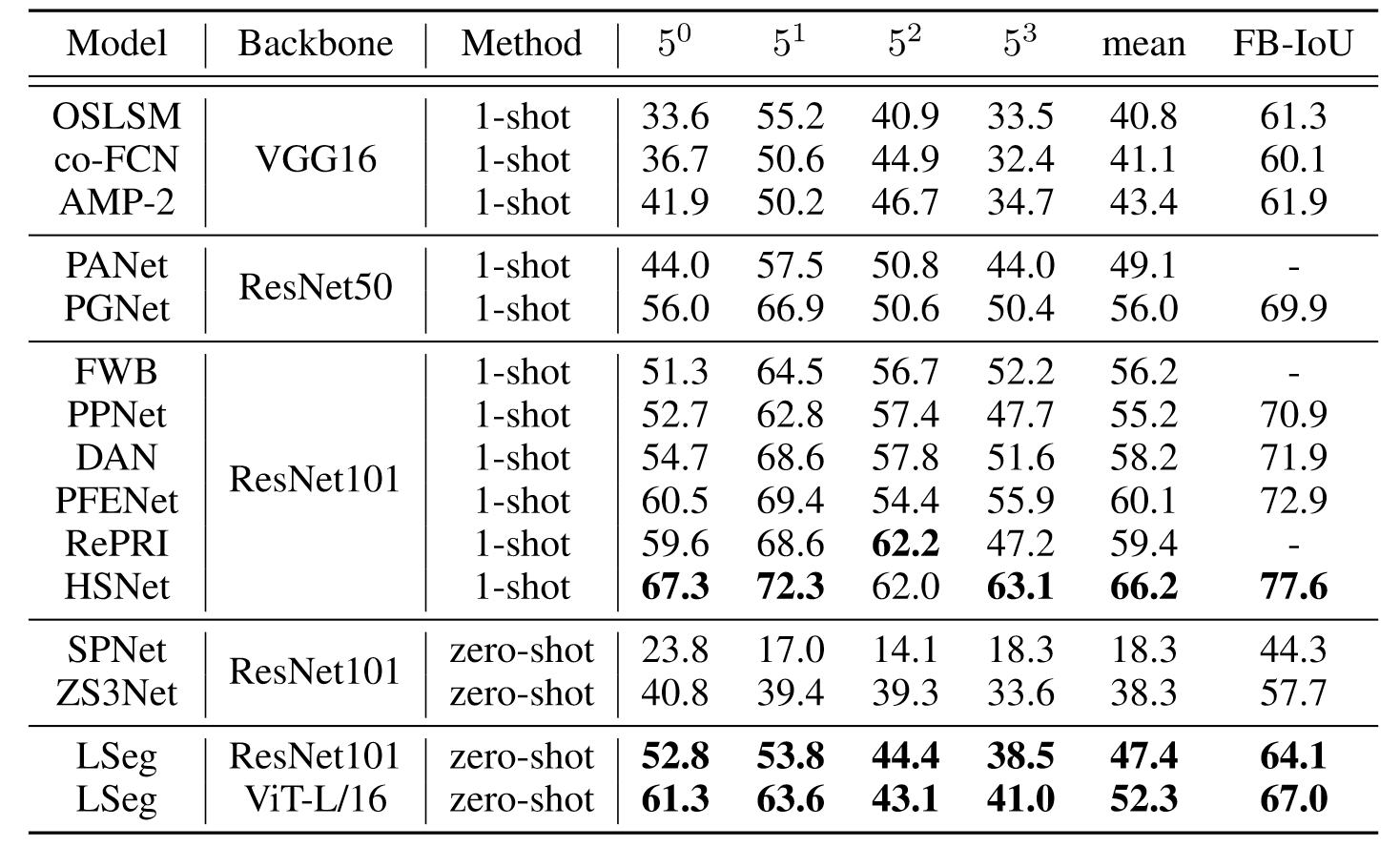
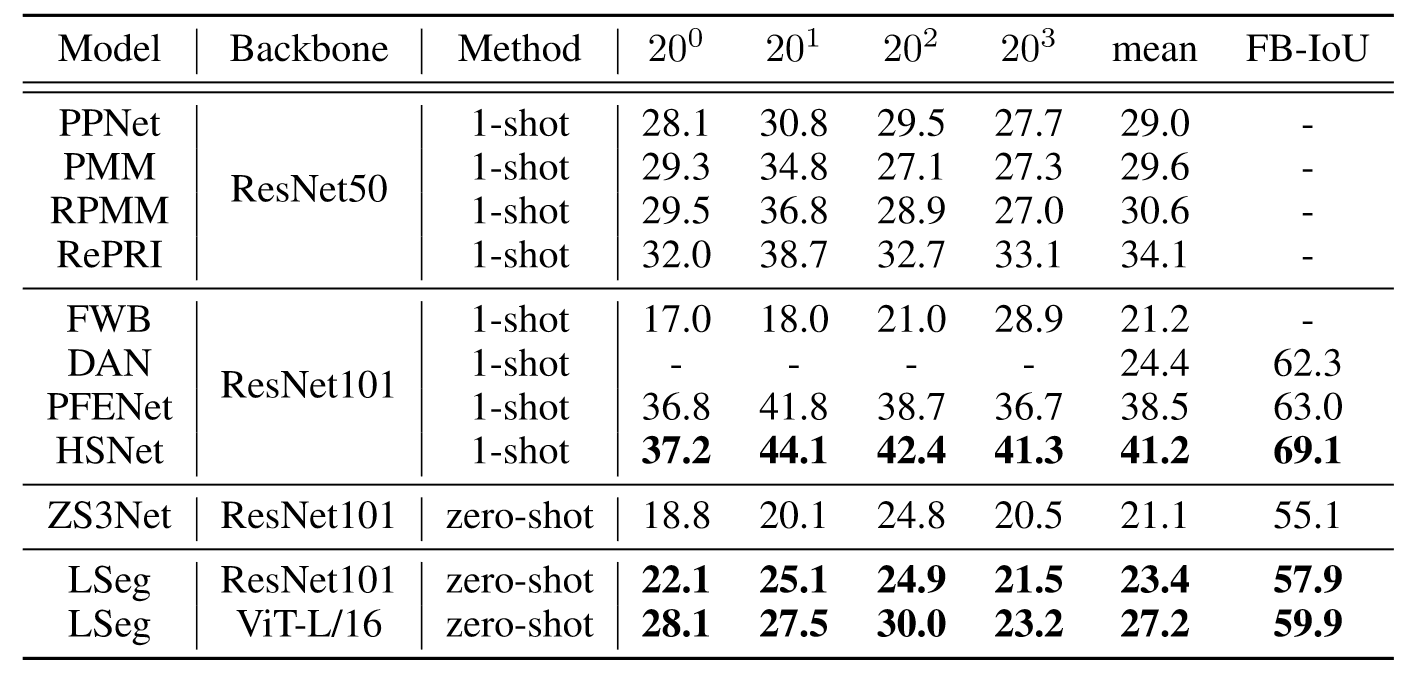
实验上,模型的差距还是非常明显的。虽然LSeg在zero-shot上取得了最好的结果,但是缺乏对比意义,因为ViT-L/16要比ResNet101大得多,此外,LSeg远远不如one-shot的结果,可见分割领域在语言驱动上还有很大的进步空间。
1.2 GroupViT
GroupViT来自CVPR2022,它通过结合ViT和对比学习,采用分组机制俩处理CV中语义分割问题,其整体流程如下:
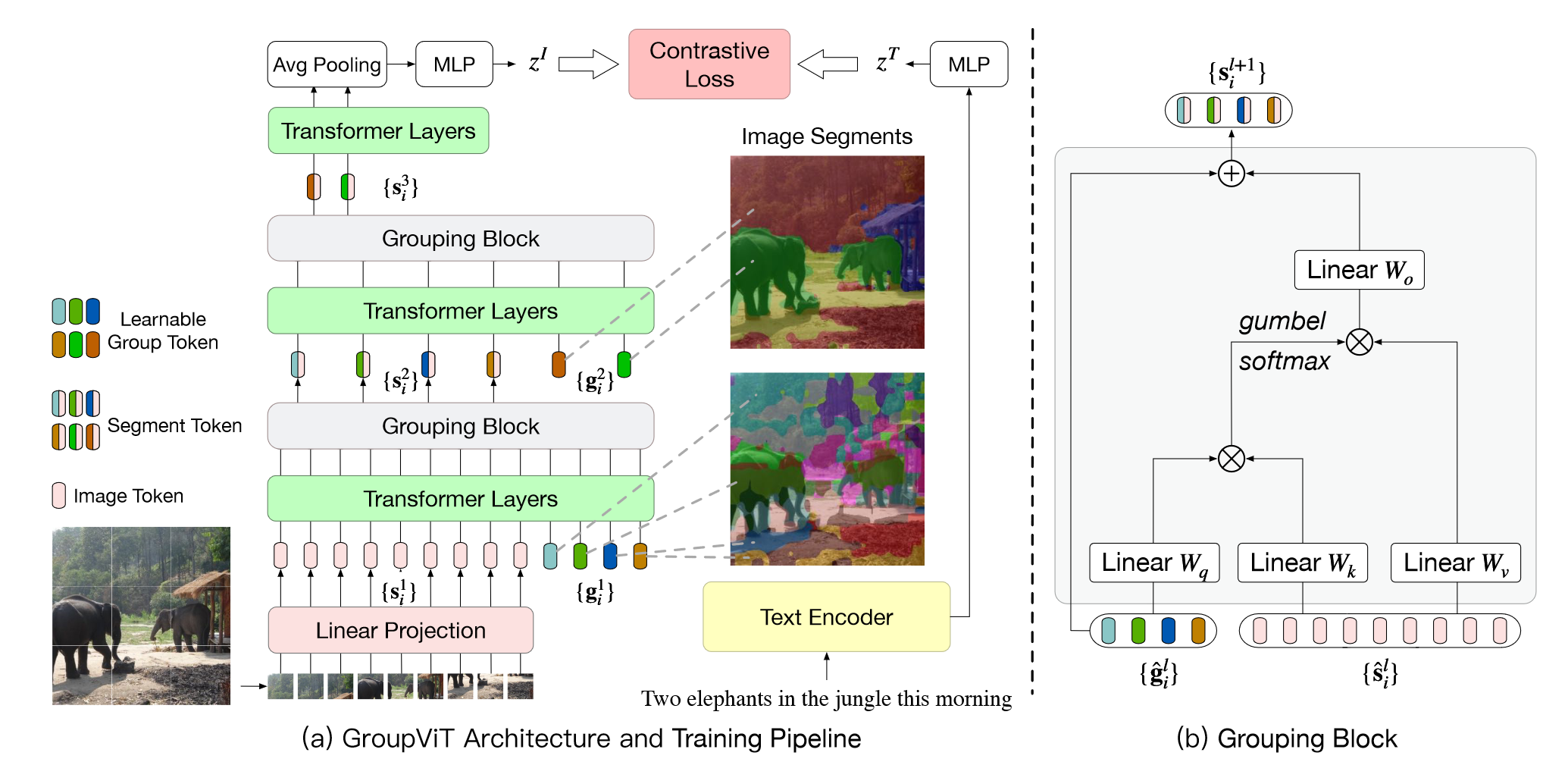
图像方面,首先将图像分割成图像块输入到线性层中通过映射得到196×384的 embedding,接着将图像token嵌入和group token一起输入到ViT块中,这里group token相当于聚类中心,维度为64×384,用于代表整个图像的特征。经过6层Transformer块后,将输出输入到Grouping块中,这可以认为是聚类的过程,如图b所示。
{
g
^
i
l
}
\{\mathrm{\hat{g}}^l_i\}
{g^il}和
{
s
^
i
l
}
\{\mathrm{\hat{s}}^l_i\}
{s^il}的维度分别为64×384和196×384,二者通过线性映射相乘得到相似度矩阵,并利用该相似度矩阵帮助原始的图像块进行聚类中心的分配,为了能够进行端到端的训练,作者设计了gumbel softmax让参数可导。经过聚类操作后,得到64×384的输出,为了进一步聚类,作者将该输出和7×384的token块再次输入到Transformer块和Grouping块中,最终得到8×384的输出,即整个图像可以由8个聚类中心表示。接下来的部分就和CLIP异曲同工了,作者将得到的8×384的特征经过平均池化层得到全局的表征,和文本编码结果进行对比学习得到loss,从而进行训练学习。
GroupViT在ViT基础上并没有加太多复杂的模块,因此具有良好的可扩展性。作者在2900万个文本对上进行训练,理论上说,如果GroupViT在CLIP的4亿条文本对上进行训练,会带来进一步性能上的提升。
CLIP最令人惊叹的是其零样本的能力,因此GroupViT也设计了零样本的实验,用于测试GroupViT的迁移能力。其过程如下:
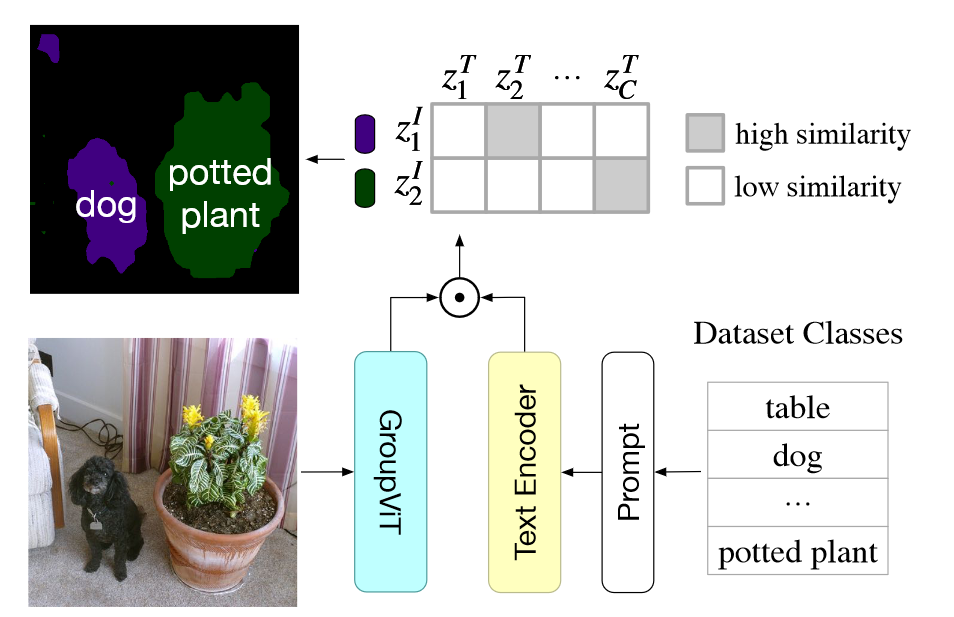
将图像和添加prompt的文本分别输入到各自的编码器中,然后计算文本和8个聚类中心的相似度,这里的局限性在于如果图像中的类别超过8个,那么就无法准确识别所有类别,当然这里聚类中心的数目是可调节的。

那么grouping token是否在工作呢?作者分别对stage1和stage2中的部分grouping token进行可视化,如上图所示。可以看到,在stage中,grouping token对图像中较小的部分进行分类,如眼睛,手肘,在stage2中,grouping token可以分类身体、脸这些占据图像更大内容的物体,可见grouping token确实起到了聚类作用,并且随着聚类中心的减少,类别会更加抽象。
实验上,GroupViT性能不仅最好,还能做零样本任务,但是和有监督学习的模型相比还是差距明显。作者发现,grouping token的分割其实做得很好,做的不好的地方在于分类部分,如果仅仅是考虑分割,那么这种无监督的方式是可以达到监督效果的。
2. 图像检测
2.1 ViLD
ViLD来自于ICLR2022,但是这篇工作在CLIP出来才两个月时间就已经挂到了arXiv上,可谓是内卷之王。这篇工作的主要内容,可以由下面这张图直接概括:
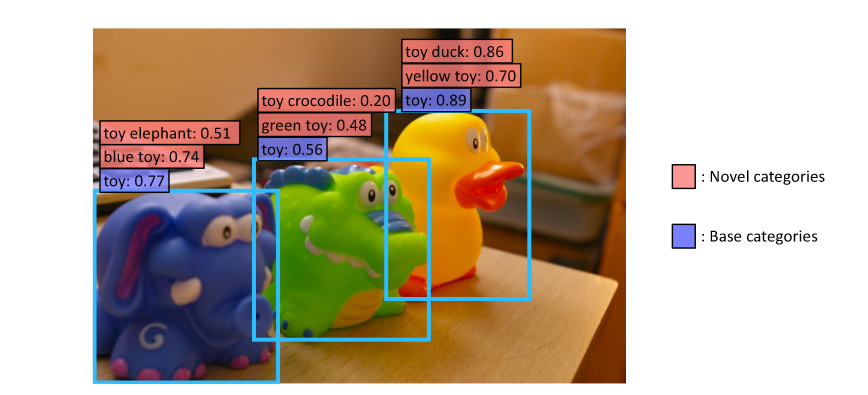
图中是三个动物玩具,但是基础类只有玩具这一类,作者提出,能否设计出一种目标检测器,除了识别训练中存在的标签类别,还能够扩展词表检测新的类别。这就是本文的目标,训练一个开放词汇对象检测器,仅使用基本类别中的检测注释来检测文本输入描述的任何新类别中的对象。
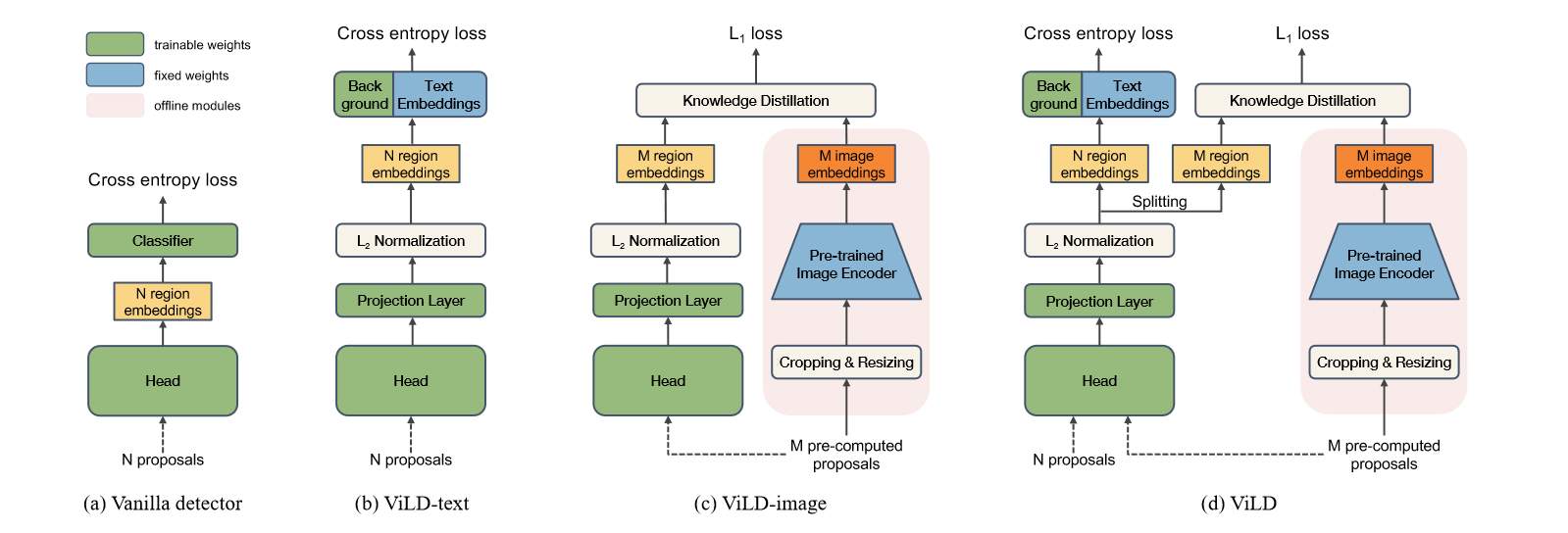
上图是ViLD的结构以及和之前模型的对比。(a)中的head是普通的两级检测器分类头,如Mask R-CNN。输入N个proposals得到的N个位置表征进行分类。proposals是指算法生成的一组可能包含目标物体的候选区域或区域建议。ViLD模型总体上由ViLD-text和ViLD-image组成,ViLD-text用固定的文本嵌入和可学习的背景嵌入途欢了原先的分类器,CLIP的应用体现在ViLD-image部分,CLIP模型作为teacher模型,ViLD作为student模型,将二者的输出进行知识蒸馏,让ViLD的输出尽可能靠近CLIP的输出,采用L1损失来更新参数。
ViLD的完整结构如(d)所示,N+M个proposals输入到Head中得到各自的表征后剥离开来,N个和ground-truth进行比较,通过计算交叉熵损失更新参数,M个和CLIP得到的表征进行知识蒸馏,采用L1损失来更新参数。
这里需要注意(d)中proposals,ViLD-text部分的proposals为N个,ViLD-image部分的proposals为M个,因此在输入的时候同时输入Head中,得到最后的embedding后再剥离开来。为什么不能同时采用N个proposals呢?因为CLIP模型规模是很大的,在训练中每次前向过程就需要M次用CLIP抽取特征的过程,时间开销是巨大的。因此会在训练前提前抽取所有M个proposals的特征,模型训练时直接从磁盘中读取,大大减少了计算开销。
下图是ViLD具体执行过程。
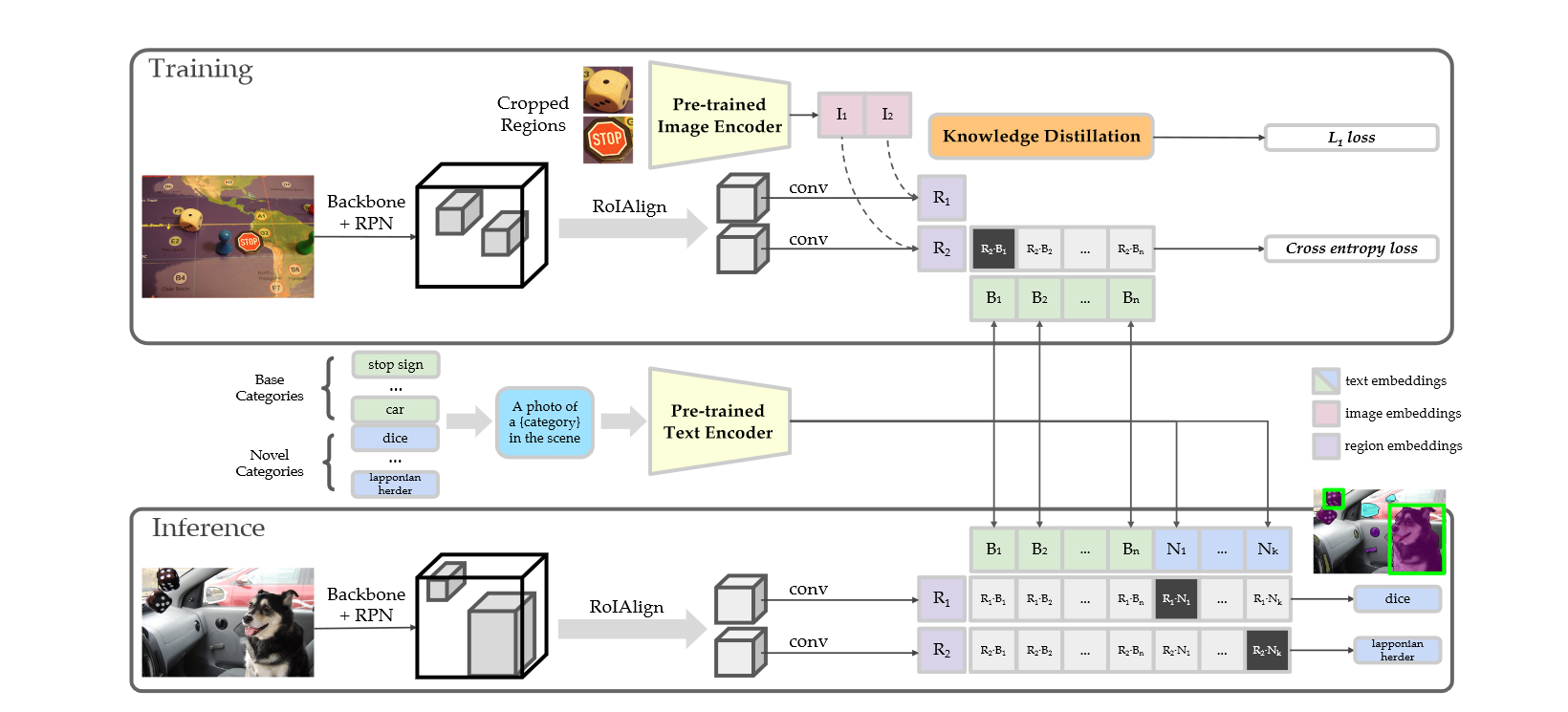
绿色是原始类别,蓝色是新类别。首先原始类别和新类别通过构造template输入到文本编码器中得到文本表征,以便训练和推理时使用。训练阶段,图像输入到backbone和RPN得到proposals,proposals分别输入到CLIP和RoIAlign中得到各自的表征,二者的表征进行知识蒸馏,通过L1损失进行学习,此外,后者表征和对应的文本编码计算交叉熵损失,从而进行梯度的反向传输。推理阶段,将图像经过Backbone+RPN和RoIAlign得到proposals的表征后,和所有的文本表征进行相似度计算,从而得到判别结果。
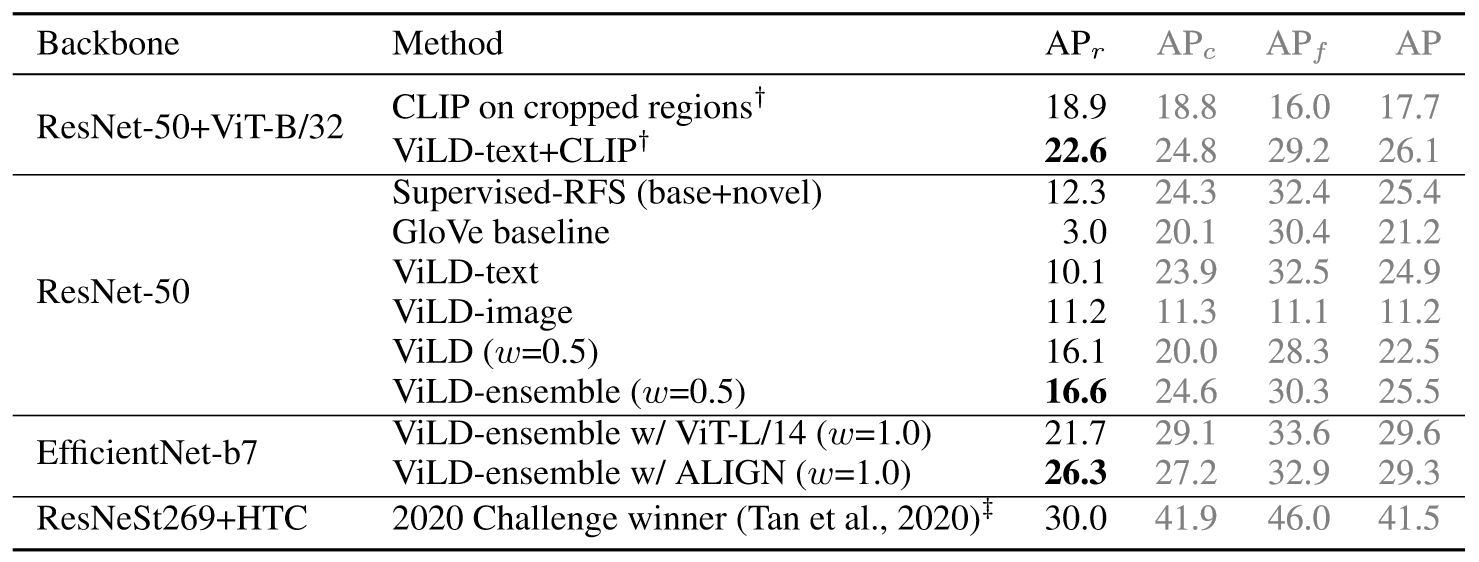
由于本篇工作作者强调的是模型面对新类别的预测能力,因此主要关注模型的零样本结果,即
A
P
r
\mathrm{AP}_r
APr结果。可以看到ViLD大幅超过之前的基线模型。并且ViLD迁移到其它未见的数据集性能表现也很良好,结果如下:
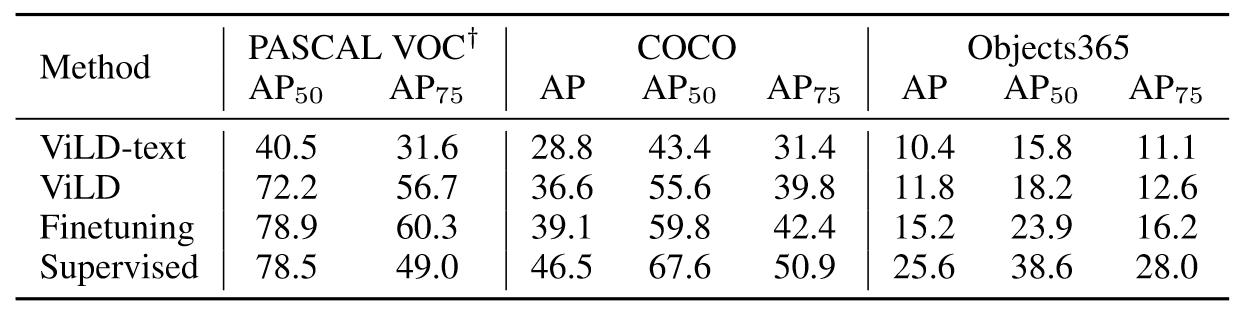
ViLD可以说是目标检测领域一个里程碑式的工作,能够在未见的类别上表现良好,具有很强的零样本能力和迁移学习能力。
2.2 GLIP
GLIP可以说就是目标检测领域的CLIP,CLIP受益于4亿对图文数据,可以预训练得到很好的模型,但是目标检测领域并没有如此丰富的数据集,因此GLIP利用自我训练的方式,即半监督学习,根据提供的文本prompt生成大量的带有锚框的数据,从而学习到丰富的图文表征。GLIP具有强大的零样本能力,在COCO数据集上,zero-shot可以达到49.8,超过了不少监督baseline,经过微调后更能达到60以上的AP。下图是GLIP的零样本迁移表现:

那么模型是如何做半监督学习的呢?所采用的数据集如下所示:

首先作者收集了物体检测数据集,但是其规模显然不够,于是作者又收集了Grounding和Caption数据集,Grounding数据集是文本描述和其对应内容锚框的数据集,而Caption数据集是图文数据集。前者和检测数据集类似,可以直接用于模型预训练,后者需要模型生成对应的锚框,再进行训练,即自训练过程。通过这样的操作就可以得到大规模丰富的数据集了。
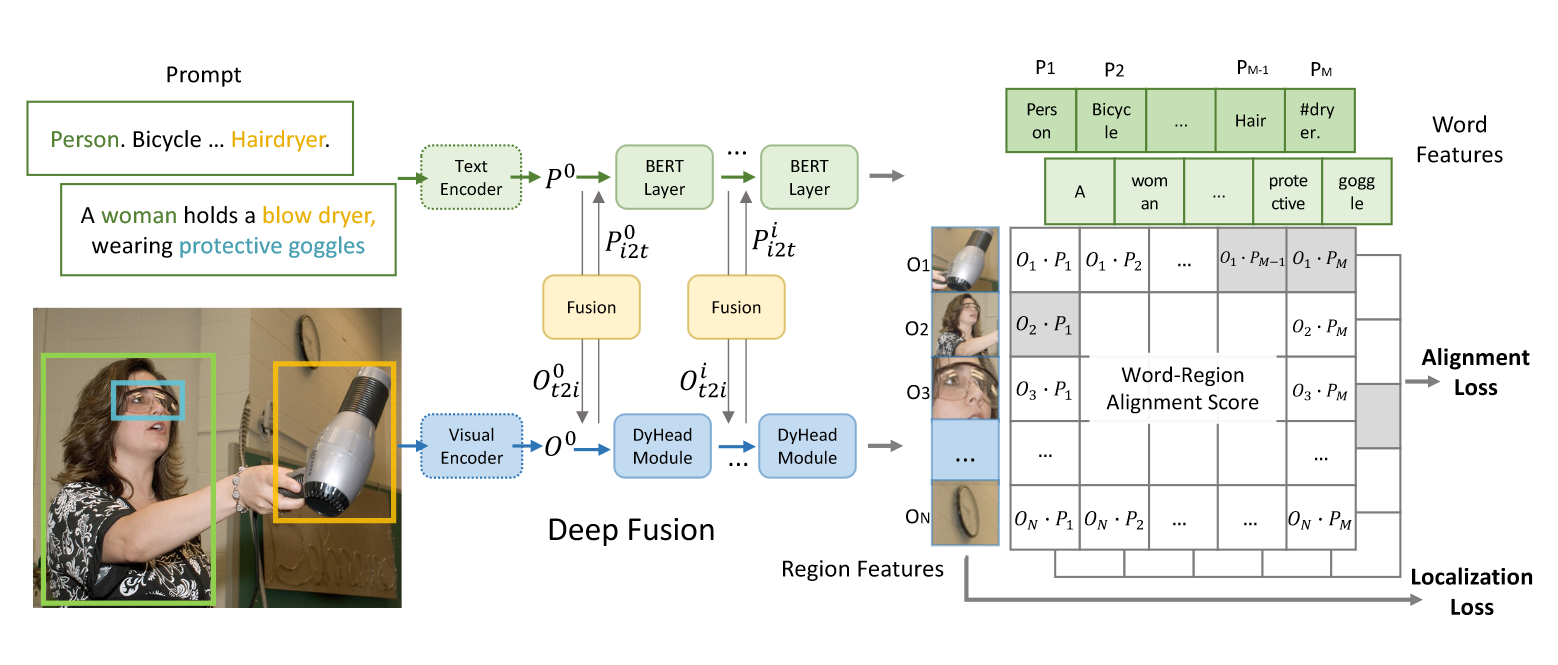
上图是GLIP整体的流程图,形式上和CLIP很像,将图像和其对应的文本输入到各自的编码器中得到表征,由于是监督训练,所以输出的锚框和文本通过计算相似度和ground-truth对比,计算Alignment损失从而梯度反传。中间的Fusion即Cross Attention,可以让文本和图像之间的联系更强。此外还有一个关键是定位损失,帮助模型训练更好的锚框,从而进行半监督学习。
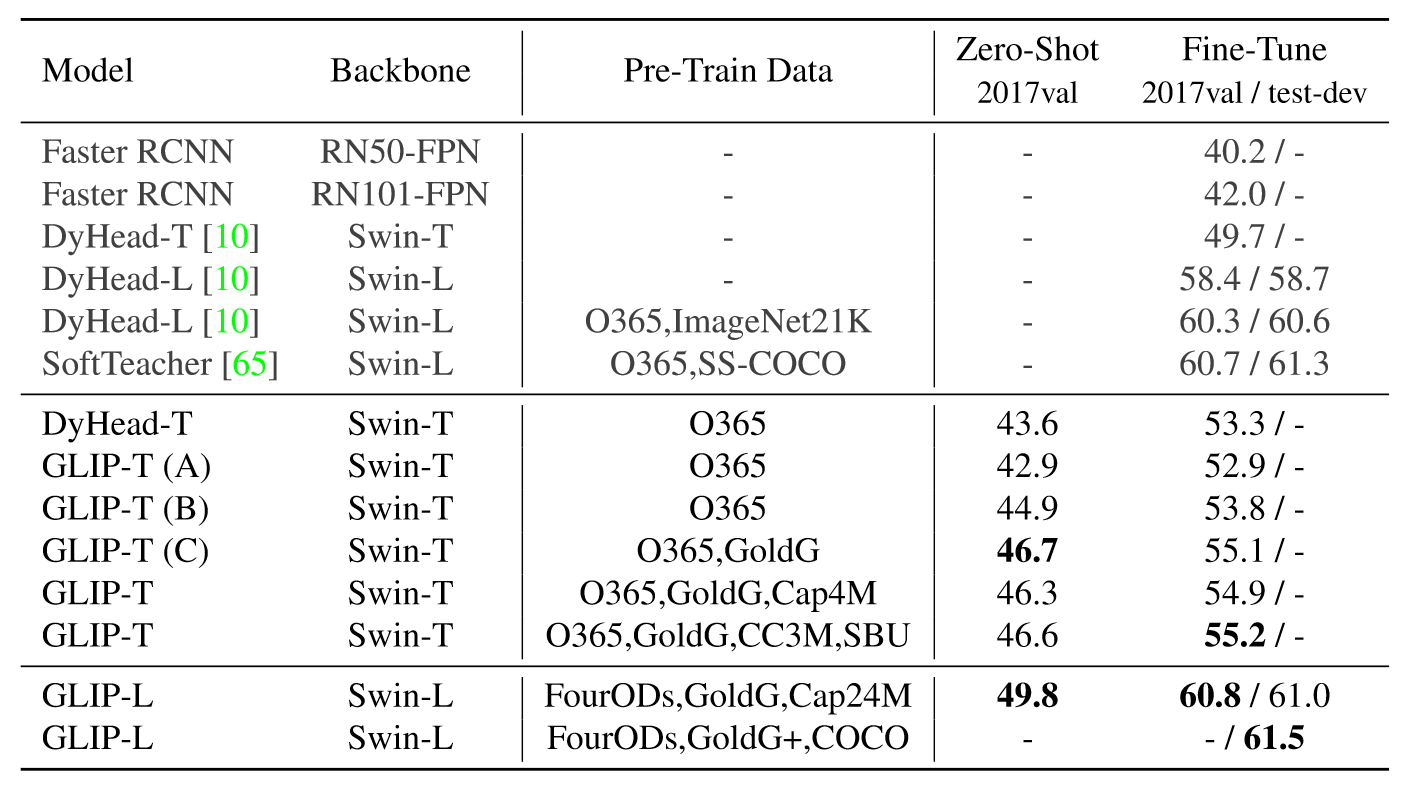
实验结果如上图所示,可见GLIP在零样本上取得了很好的结果。
2.3 GLIPv2
受到GLIP中多任务数据集进行半监督训练的影响,GLIPv2将多种任务统一起来,既可以做对象检测,实例分割等定位任务,又可以做VQA,图文对的理解任务,如下图所示:
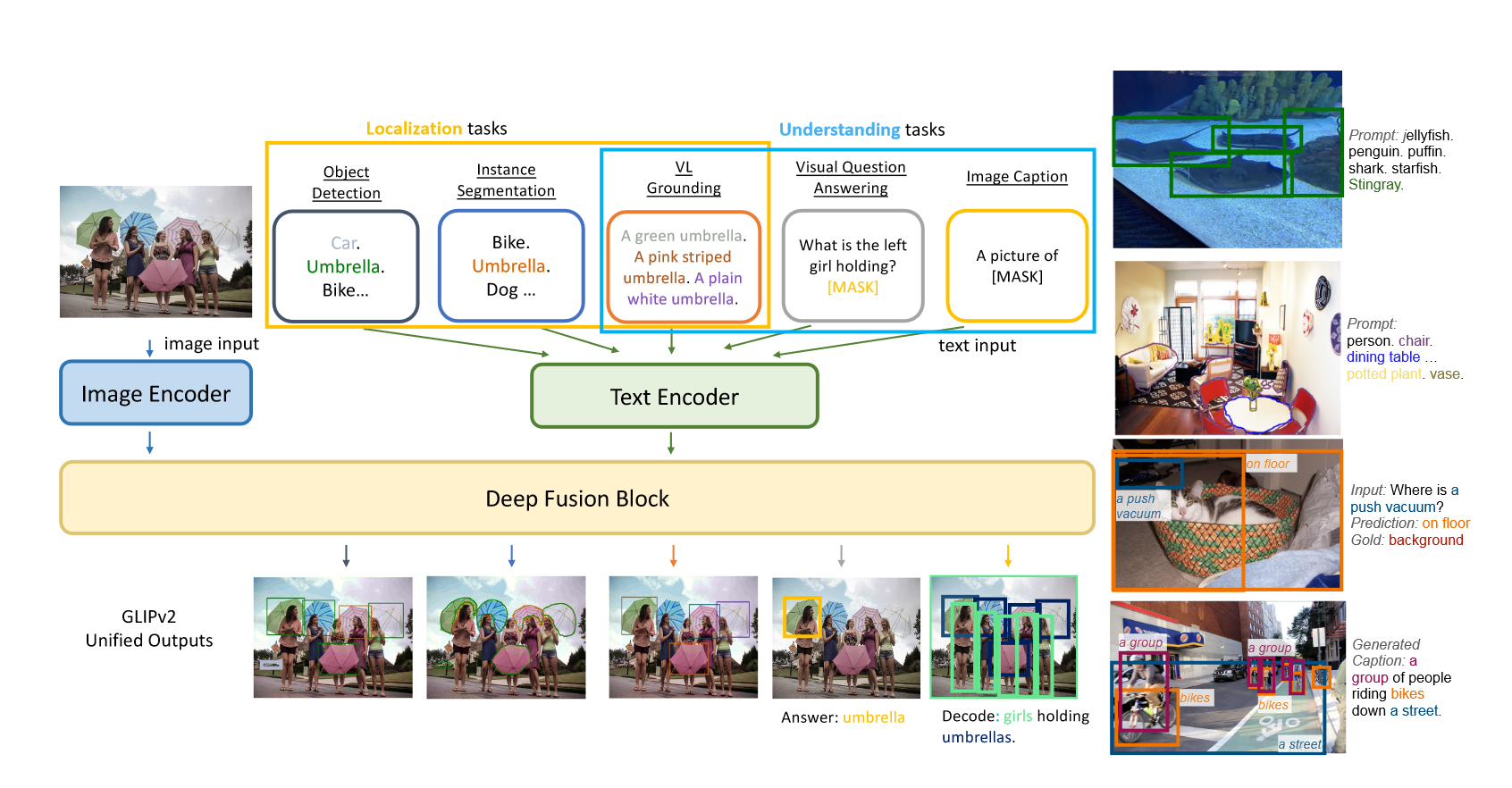
GLIPv2实现了定位和理解任务之间的互惠互利,单个GLIPv2模型有我在各种定位和理解任务上接近SOTA。该模型还展示了在开放词表上强大的零样本和few-shot性能,并且在VL理解任务上有着卓越的能力。
3. 图像生成
3.1 CLIPasso

CLIPasso这篇工作是会议SIGGRAPH最佳论文,它将物体的图像抽象成不同程度的草图,同时保留其关键的视觉特征。即使是非常少的表示,人们也能够识别出描绘主题的语义和结构。

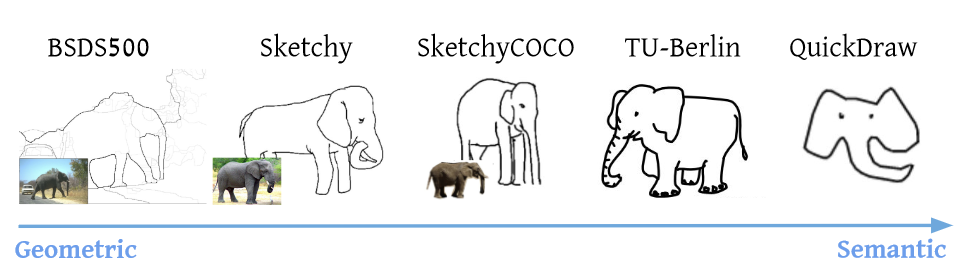
上图是毕加索名画“一头公牛”,表现的就是对原始画像不断抽象的过程,要想实现这样的模型,就需要收集相应的数据集进行训练,常见的数据集如下图所示。但是现有数据集的抽象都是固定好的,这会限制抽象出的形式和风格,违背了图像生成的初衷。
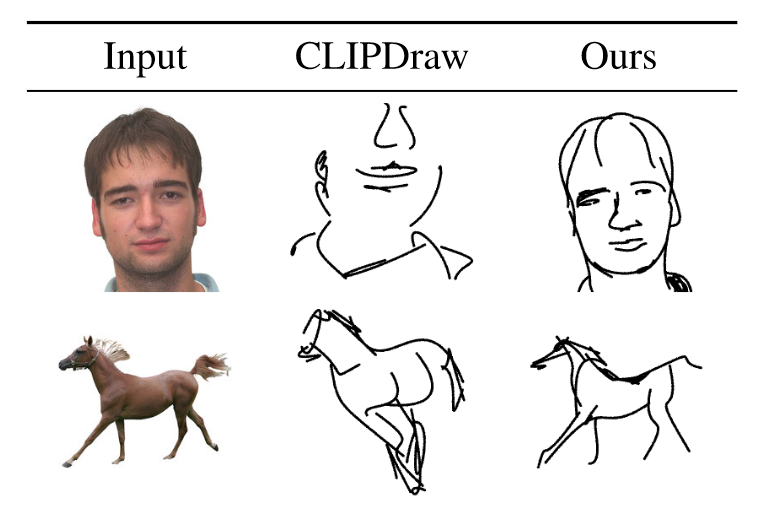
如何摆脱对有监督训练集的依赖,并抽取出更好的图像语义?作者自然而然就想到了CLIP。
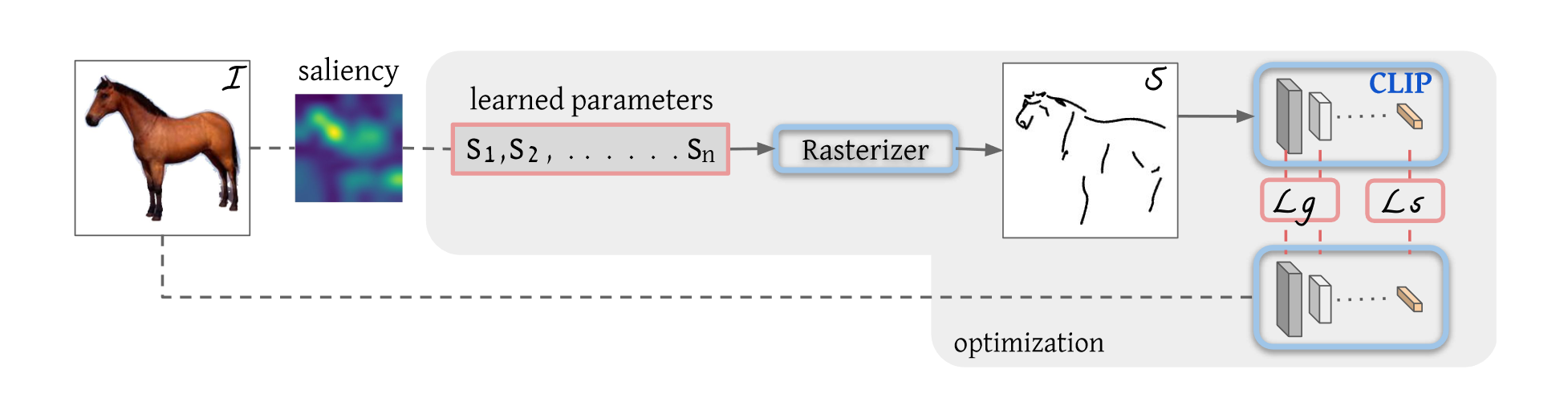
主体方法如上图所示,首先根据原始图像生成采样范围,接着采样点生成贝兹曲线,一条贝兹曲线是空间上多个二维的点控制的曲线,点的个数可以调整。模型训练的过程本质上是更改点的位置,从而改变曲线的形状,得到想要的简笔画。具体来说,将采样得到的n个笔画输入到光栅化器Rasterizer,从而得到图像的简笔画,接下来就是工作的创新点,作者采用了CLIP模型,将原始图像和简笔画输入到CLIP中得到的特征尽可能相似,计算损失
L
s
L_s
Ls,让模型学习到图像的语义信息。但是光有语义信息,位置不匹配也会导致生成的简笔画和原始图像不一致。因此作者又设计了另外一个几何损失函数
L
g
L_g
Lg,计算原始图像和简笔画在模型前几层特征的相似性,因为模型的前几层包含更多的几何特征信息。通过语义损失和几何损失的加持,就可以保证训练好的模型生成的简笔画无论在语义信息和几何位置上都和原始图像尽可能一致。
本文工作另一个创新点就在于点初始化saliency部分,因为不同的初始化结果会导致简笔画差异很大。具体来说,作者将原始图像输入到训练好的ViT中,把最后一层多头注意力取加权平均,做成saliency MAP,让点在显著的区域采样。下图是不同初始化生成的结果,可以看到本文的初始化得到的简笔画效果显然更好。

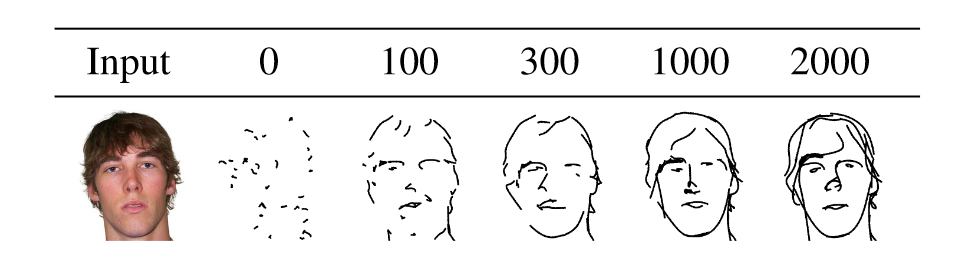
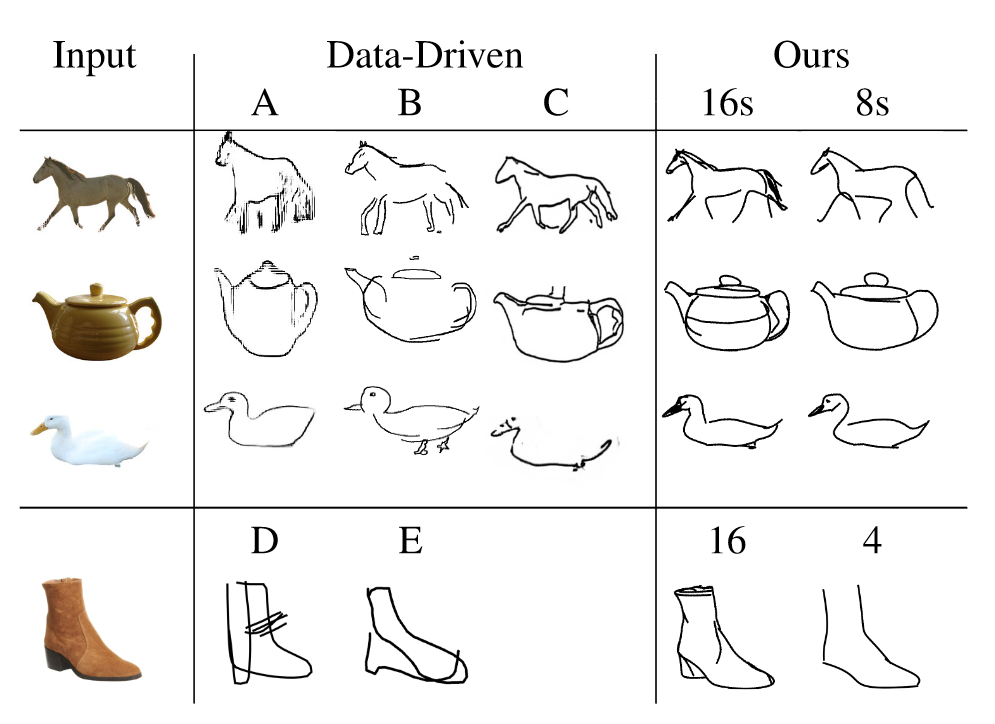
CLIPasso效率高,性能好,成本低,在一张V100上只需要6分钟就能够完成2000轮迭代,迭代100轮的时候就可以看出模型的效果如何。
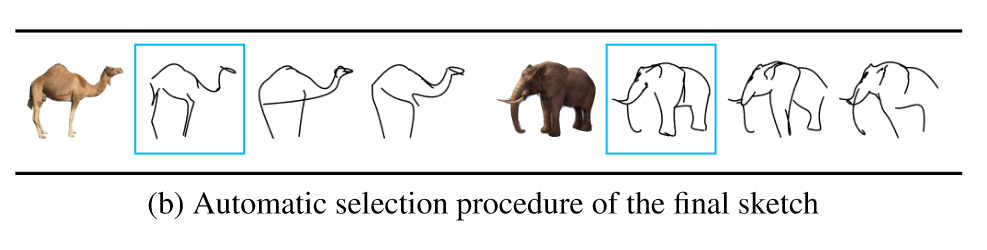
此外对生成的简笔画,作者还做了进一步的后处理,对输出的三张简笔画计算两种loss,将最低loss的简笔画作为最终的输出,如下所示:
CLIPasso可以为不常见的物体生成简笔画,这是之前的模型所不能做到的。比如下面的结果:

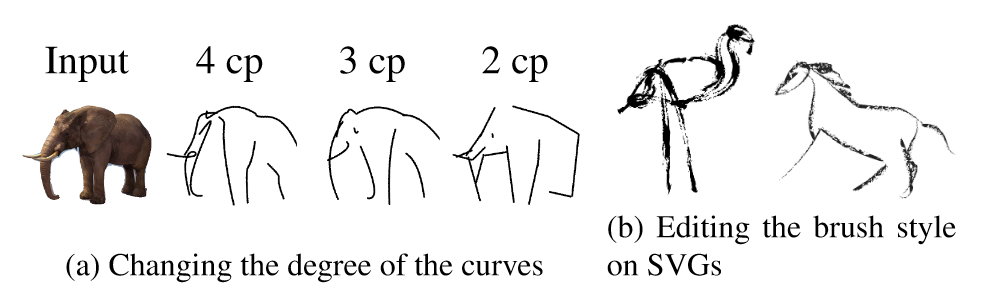
此外,CLIPasso另一个卖点在于可以通过控制笔画的个数来控制生成简笔画抽象的程度。当笔画数越少,生成的简笔画相应就会更抽象。
实验部分,作者将CLIPasso和其它模型进行了生成简笔画结果的对比如下:
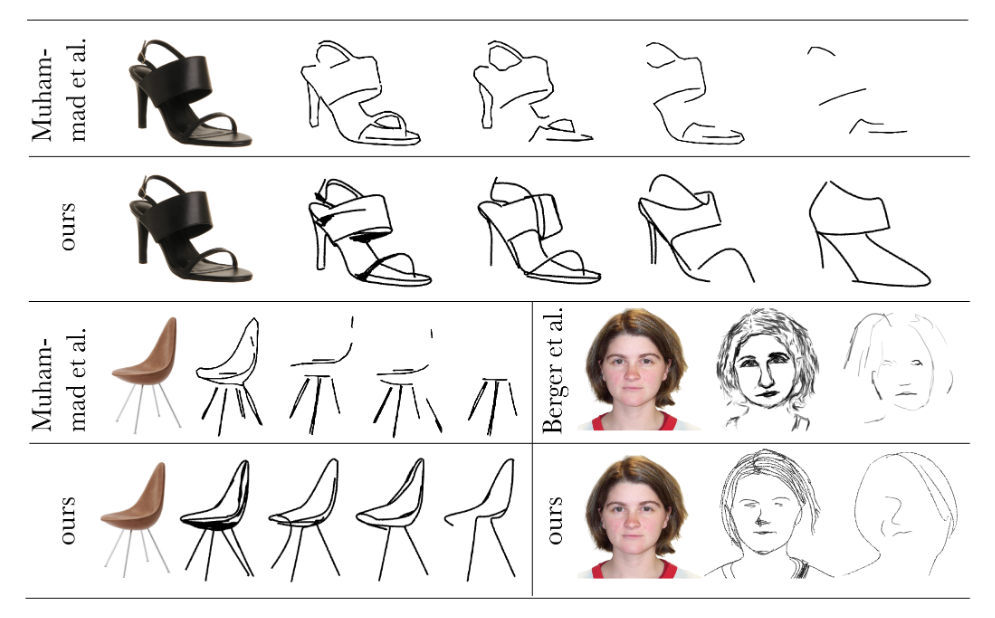
可以看到对于任意物体,CLIPasso生成的简笔画都更能体现原始图像的特征。
当然,CLIPasso也有如下几点局限性:
- 有背景的图像会降低模型的性能,本文采用了自动掩码的方法,将目标从原图中抠出来再进行简笔画的生成,但是这样two step的过程显然不够便捷,一个可行的方向是设计一个损失函数让模型学习不被背景干扰。
- 简笔画的笔画是同时生成的,这和真实场景下的素描不同,如果能够一笔一笔生成,生成的简笔画可能更合理,更具艺术性。
- 笔画的个数必须提前确定,但是不同图像在相同抽象程度所需笔画数量不同,如果能够将其变为可学习的参数,那么就可以规定抽象级别对不同的图像执行简笔画任务了。
4. 视频理解
4.1 CLIP4Clip
CLIP4Clip是一篇以端到端的方式将CLIP模型的知识转移到视频语言检索中的工作。其核心的思想和CLIP一模一样,如下图所示:
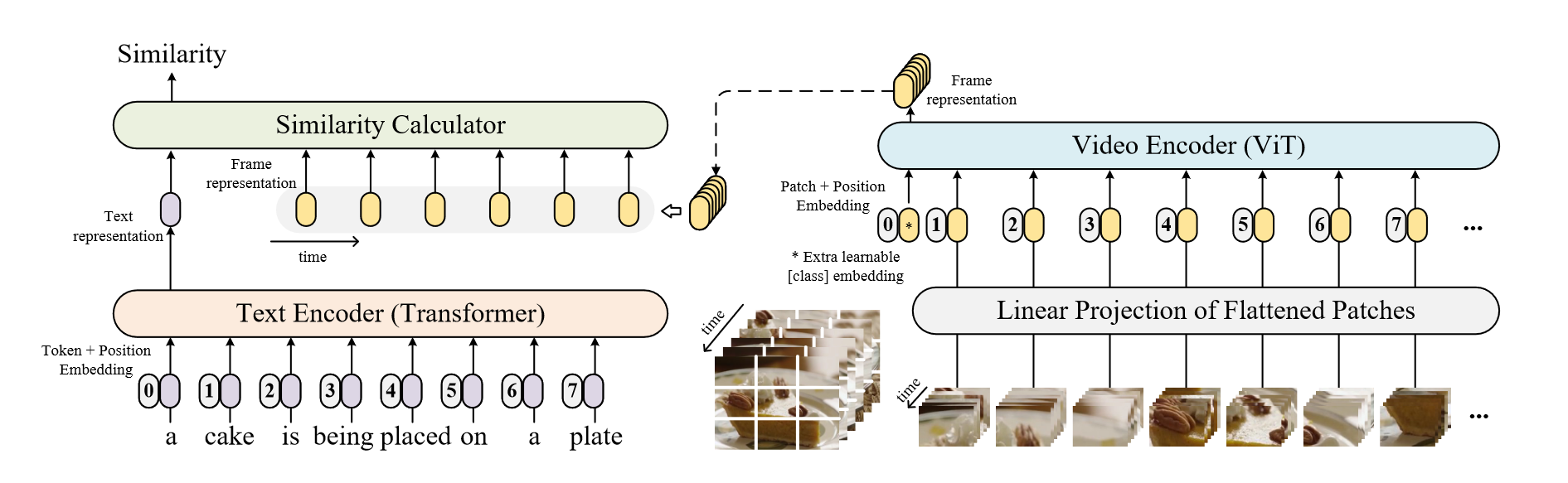
一段视频的文本输入到文本编码器得到文本表征,视频以帧为单位进行线性投影得到帧的token,然后经过ViT得到帧的表征。在之前CLIP的工作中,文本的表征只对应一张图像的表征,而这里文本表征对应多张图像的表征,那么该如何计算相似度呢?
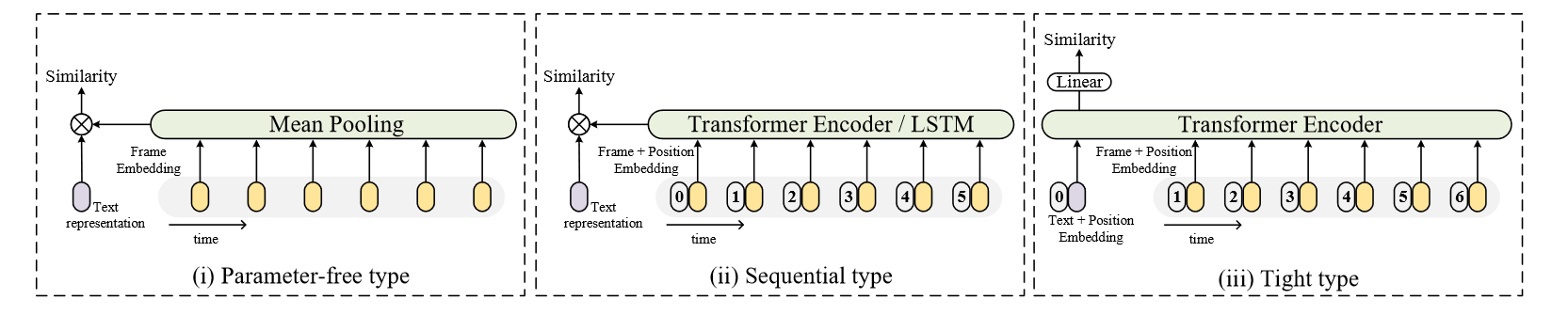
作者提出了三个解决方案,第一个就是最简单的直接将所有图像表征取平均,然后再和文本表征计算相似度,这种方法的缺点是缺少视频的时序信息。为了加入时序信息,作者又设计了第二个方案,将连续的图像编码输入到Transformer或者LSTM中,这样最后得到的表征就带有时序信息。最后一个方案是将文本和视频帧的表征同时扔给Transformer Encoder,让文本和视频帧的表征通过不同交互得以融合,最后文本表征的输出直接作为相似度。这种方法既加入了时序信息,又融合了文本和视频帧信息。
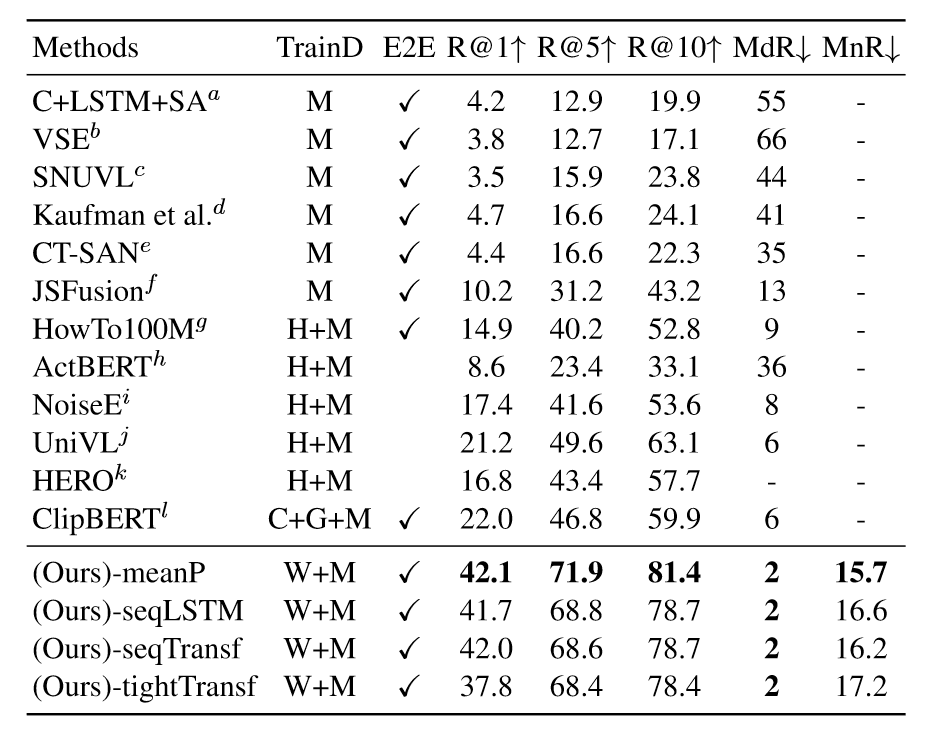
实验部分,本文的模型显著好于之前的模型,这很大一部分原因得益于CLIP模型的优越性。进一步观察可以发现,平均的相似度计算方法效果是最好的,为此作者又在更大的训练集上进行训练,得到如下的结果:
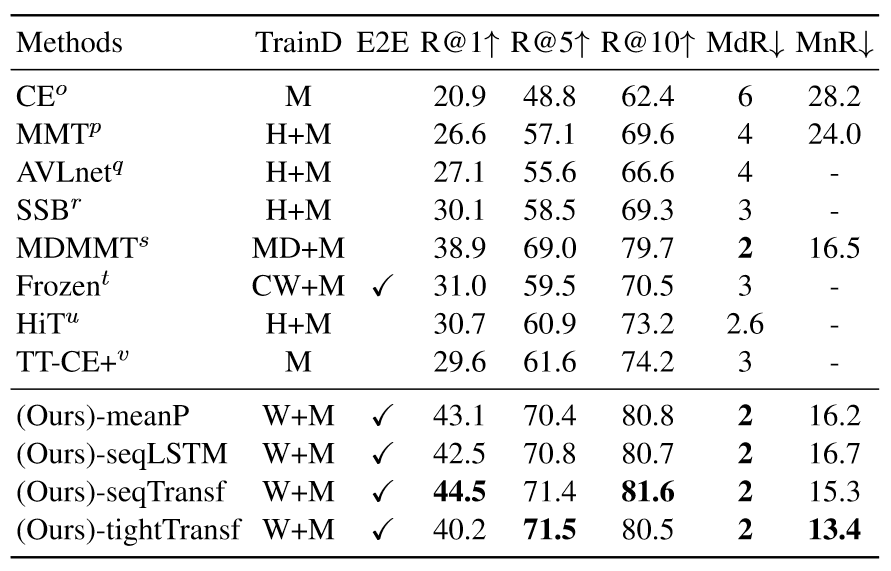
当训练数据集增多后,模型在下游任务上微调效果慢慢显露出来,模型也就不容易过拟合,参数学习的方式效果就会好一些。
本文的工作完全是CLIP在视频理解领域的迁移工作,模型的整体架构几乎没有变化,只是根据应用场景加入了一些特别的处理工作,并在五个数据集上取得了最好的结果。这篇工作属于CLIP在视频理解领域的开山之作,因此作者提出了很多想法:
- 图像特征也可以促进视频文本的检索。
- 即使是优秀的图文预训练CLIP后也可以提高视频文本检索的性能。
- 3D块线性投影直接融合了时序信息,是很有前途的方法。
- 视频检索的CLIP对学习率很敏感。
4.2 ActionCLIP
ActionCLIP是一篇基于CLIP的视频理解动作识别的工作。动作识别本质上是分类任务,只不过在视频里加入了时序信息。之前的做法是将视频输入到视频编码器得到表征向量,过一个分类头得到分类结果,和最后的Ground-truth作对比计算损失。这样的方式需要大量人工标注的监督数据,成本较高,并且会出现遇到新的类别无法分类的问题。那么CLIP就特别适合这种需要大量图文数据进行预训练的任务,之后只需要做zero-shot或few-shot就能有很好的结果。本文的ActionCLIP基于CLIP,将视频和标签分别编码计算相似度,由于标签是人工标注的数据,所以和一般的对比学习有所不同,之前是图片和其对应的caption为正样本,也就是对角线上都是正样本,但是其它部分都是负样本,而这里会出现标签相同的不同样本,处理的方法也很简单,将之前的交叉熵损失换成了KL散度,利用分布的相似度计算损失。
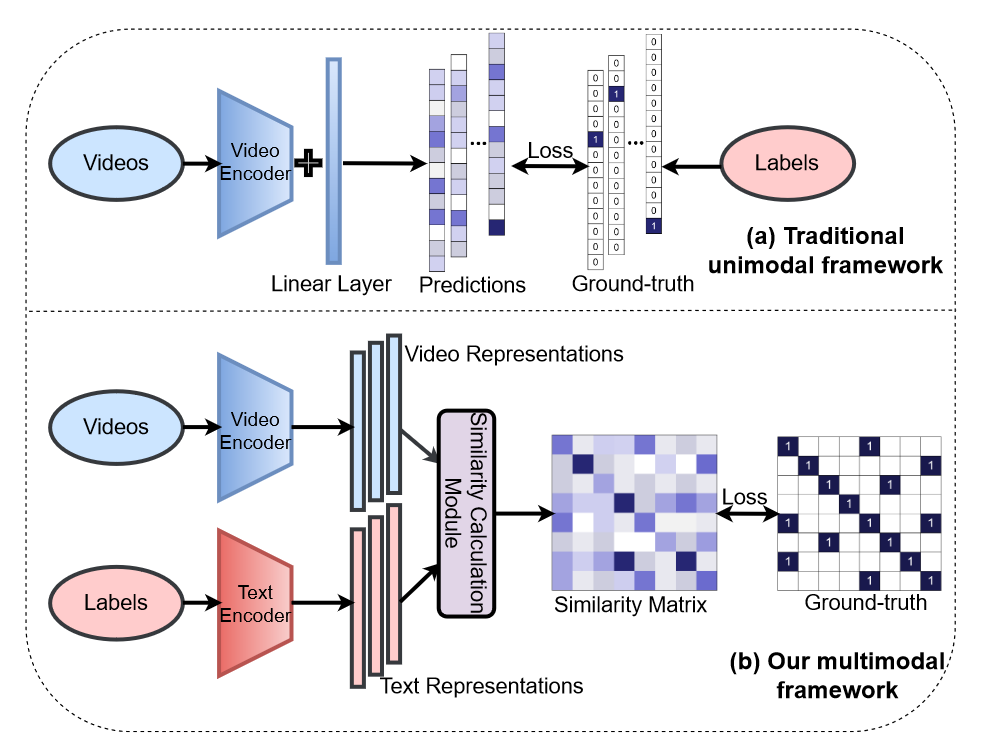
当然ActionCLIP作为视频理解领域的工作,肯定相比于CLIP加入了更多领域的特性。如下图所示:
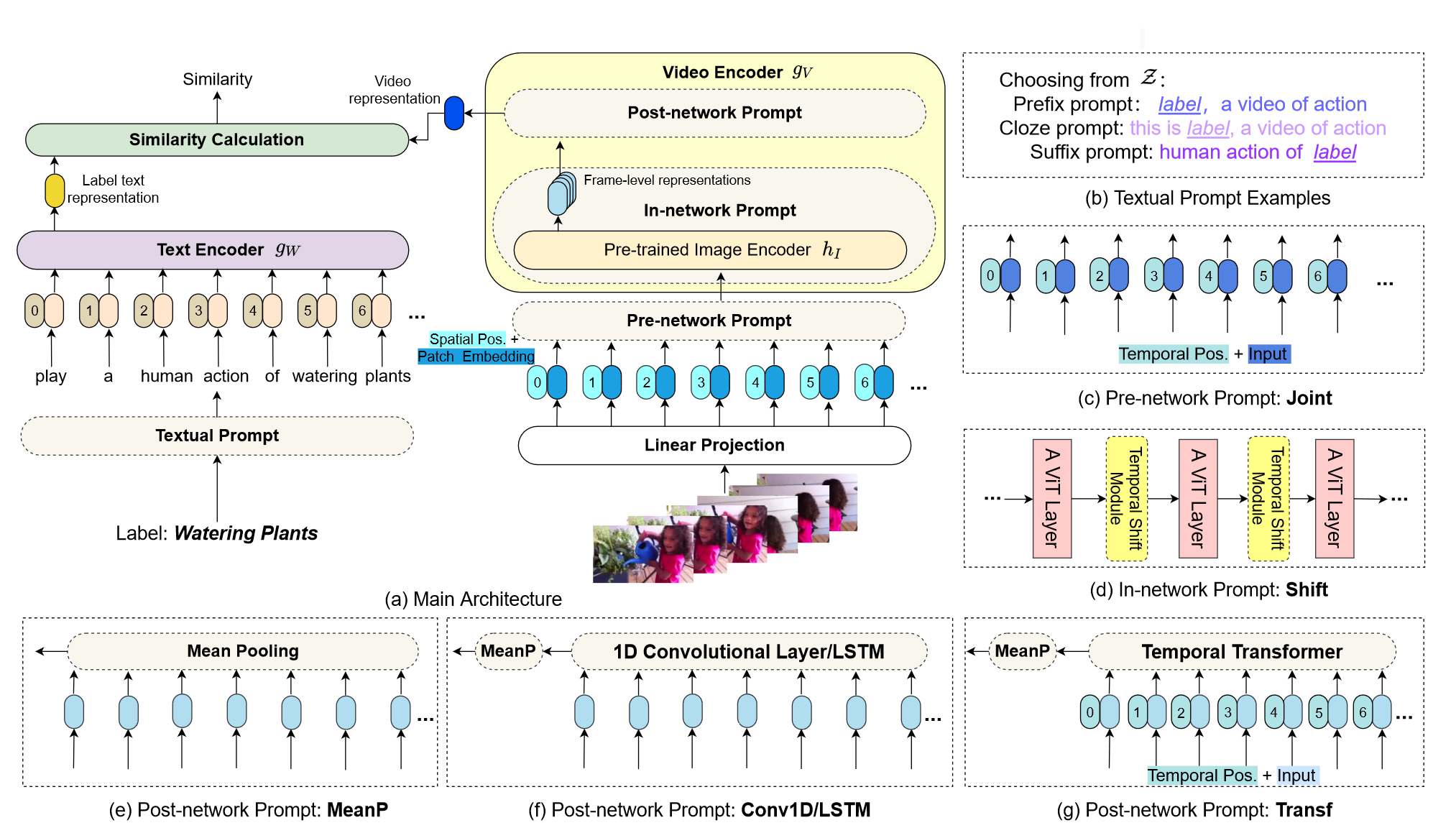
其最核心的地方在于视频的表征。之前的CLIP是一图对一文,但是视频领域是多个视频帧对应一段文字。首先在视频帧表征部分,作者设计了Pre-network Prompt和In-network Prompt,前者是加入了时序位置信息,后者加入了shift模块,增强模型时序建模的能力,又不引入过多的参数。视频帧token序列经过这两层Prompt网络得到表征序列,那么这里将表征序列合并成一个表征的操作就和CLIP4Clip如出一辙,Post-network也是有三个方法,MeanP,Conv1D/LSTM和Transf,具体如何实现这里就不过多赘述了。
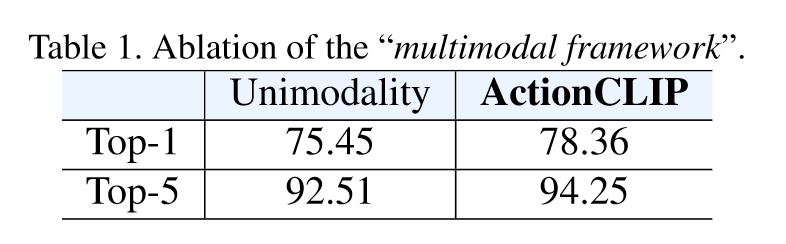
消融实验部分作者首先探讨多模态框架是否有效,可以看到在Top-1上提升了3个点,效果还是非常显著的。作者接着又探讨预训练初始化的作用,如下图所示:
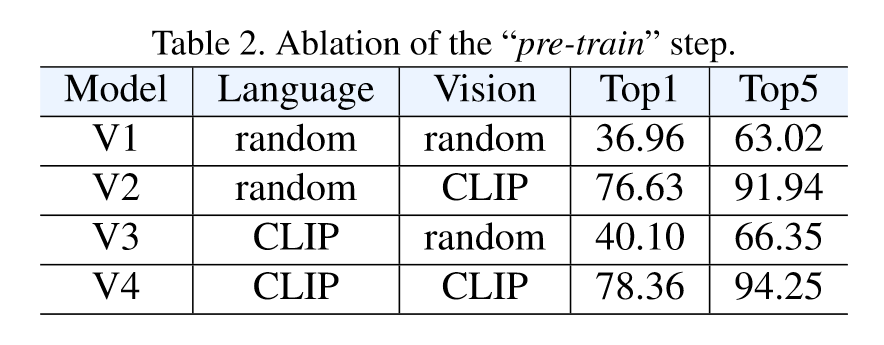
可以看到视觉的CLIP初始化对结果影响最大,而文本的初始化反而没有那么大的影响。最后是prompt的消融实验:
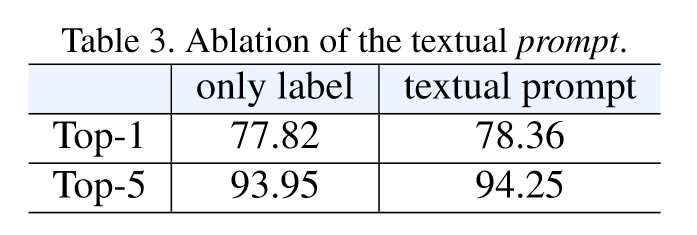
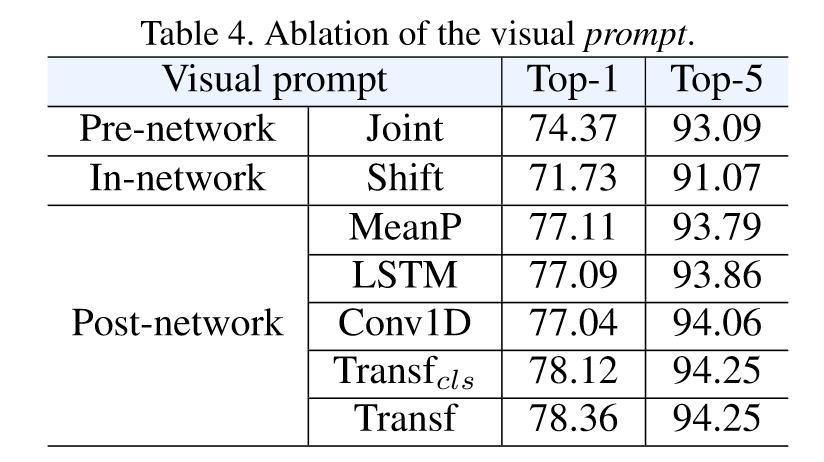
文本的prompt对结果没有太大影响,Pre-network和In-network反而让模型掉点显著,只有Post-network中的方法对模型性能有一定提升。
既然采用了CLIP,那么一定要测试一下其强大的零样本能力,如下图所示:
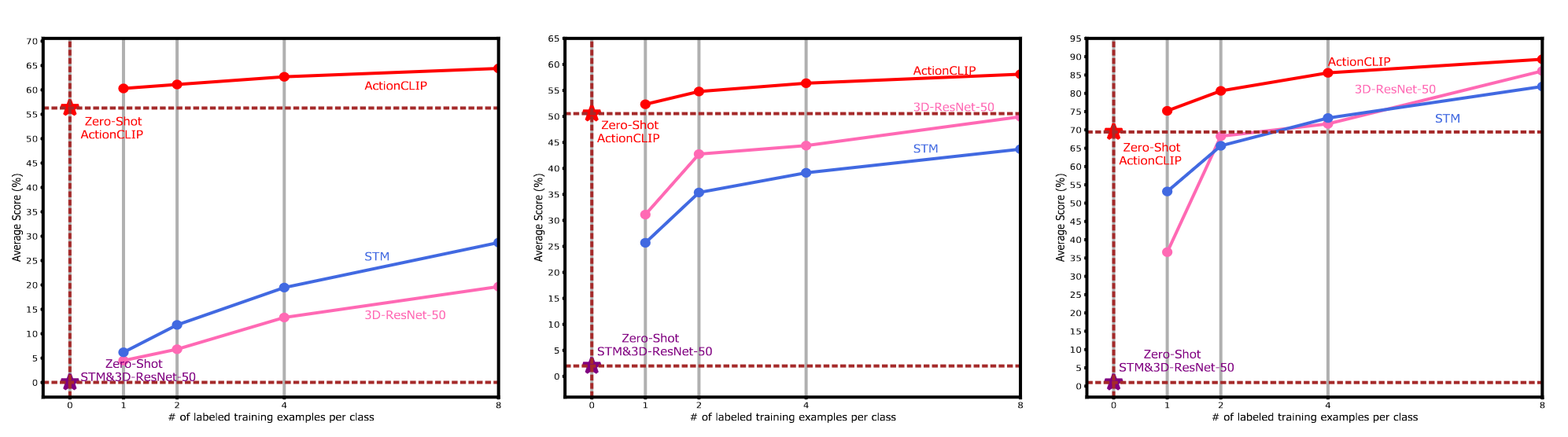
ActionCLIP果然是不负众望,零样本的结果甚至比之前方法few-shot的结果要好。
5. 其它领域
5.1 CLIP-VIL
CLIP-VIL这篇工作证实了CLIP模型作为预训练参数可以进一步提高下游视觉语言任务的性能。
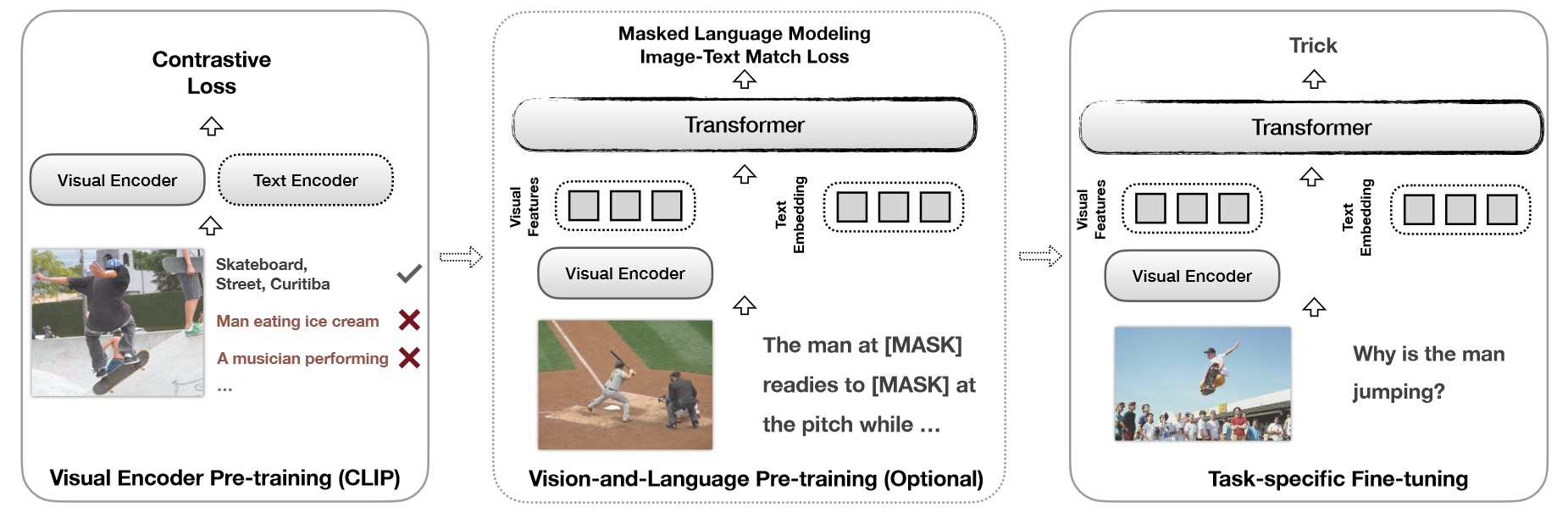
它的本质就是将之前方法的编码器换成了CLIP模型,然后直接在下游任务上微调,取得了很好的效果。
5.2 AudioCLIP
语音领域也应用了CLIP,AudioCLIP这篇工作融合了文本、视频和音频三个模态的信息,以CLIP的方式进行正负样本对的学习。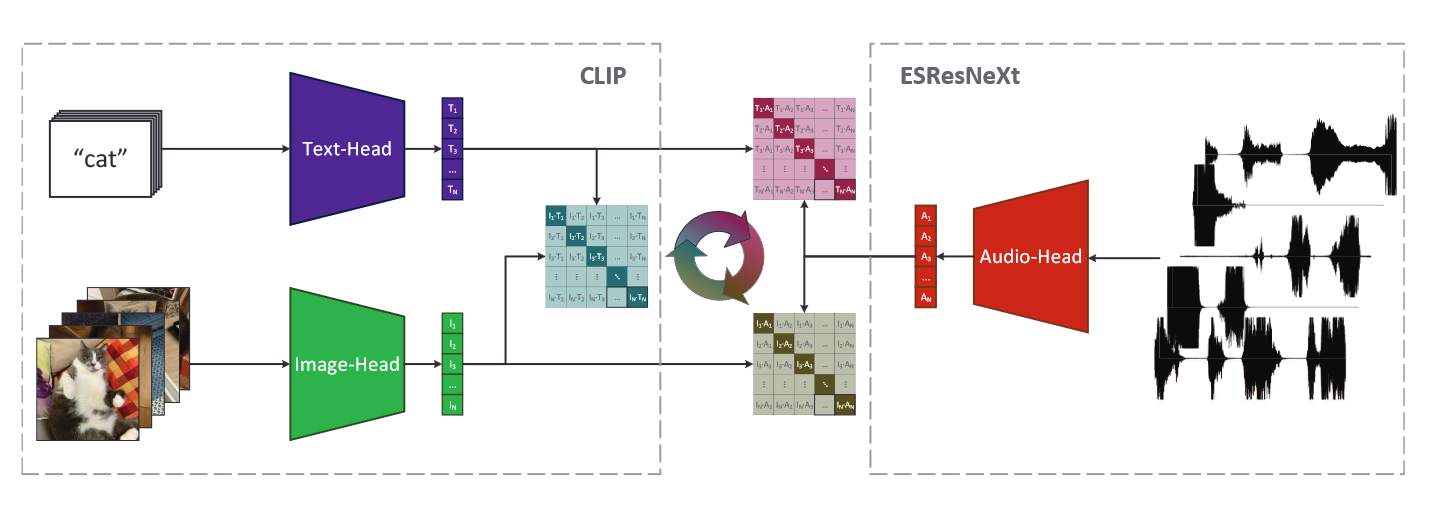
左边部分完全是CLIP,即文本和视频帧的编码,右边是对音频的编码,该网络称为ESResNeXt,得到的三个表征两两进行正负样本的学习。
5.3 PointCLIP
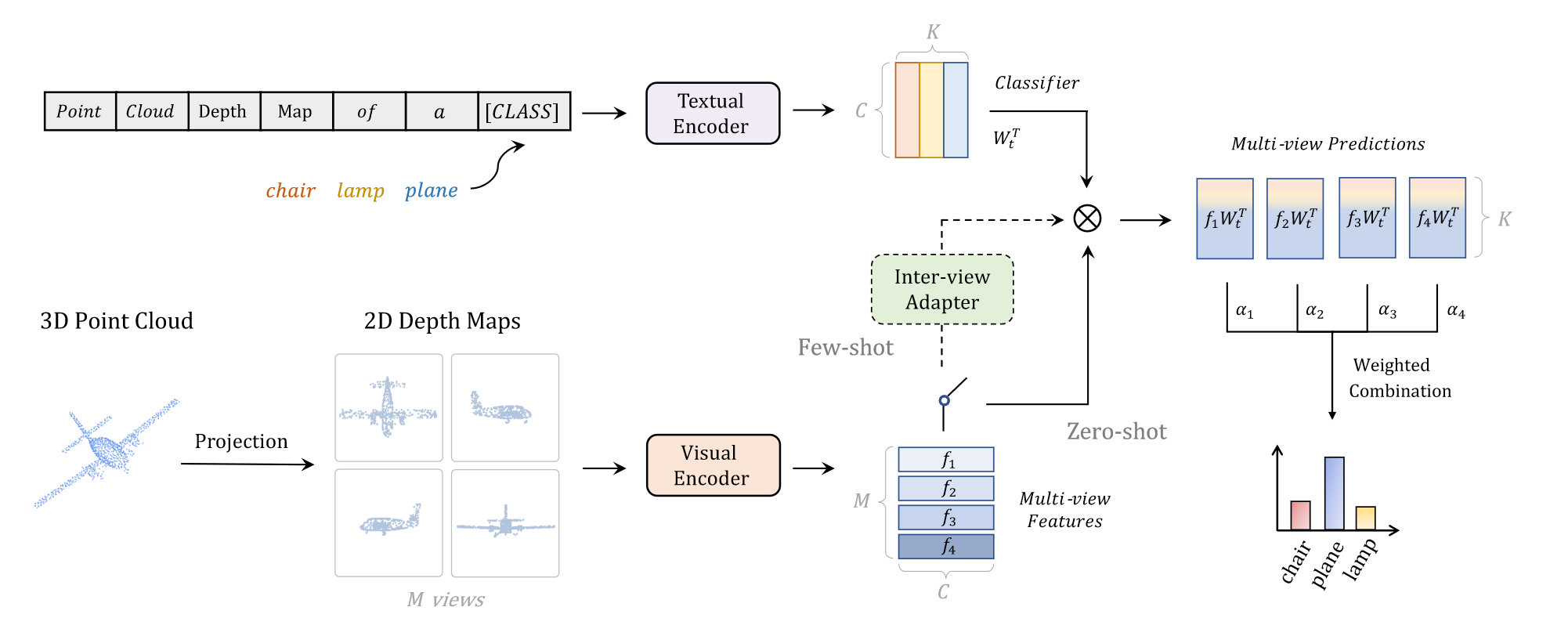
如何把CLIP学习到的2D表征迁移到3D场景,PointCLIP给出了答案。
作者将3D点云投射到2D平面,得到了2D的深度图,即2D的图像,文本的Prompt提示模型这是一个点云的深度图,帮助模型适应3D变成2D后图像的改变。这样模型既可以训练,也可以做零样本的推理。此外,Inter-view Adapter还融入了相应的领域知识。
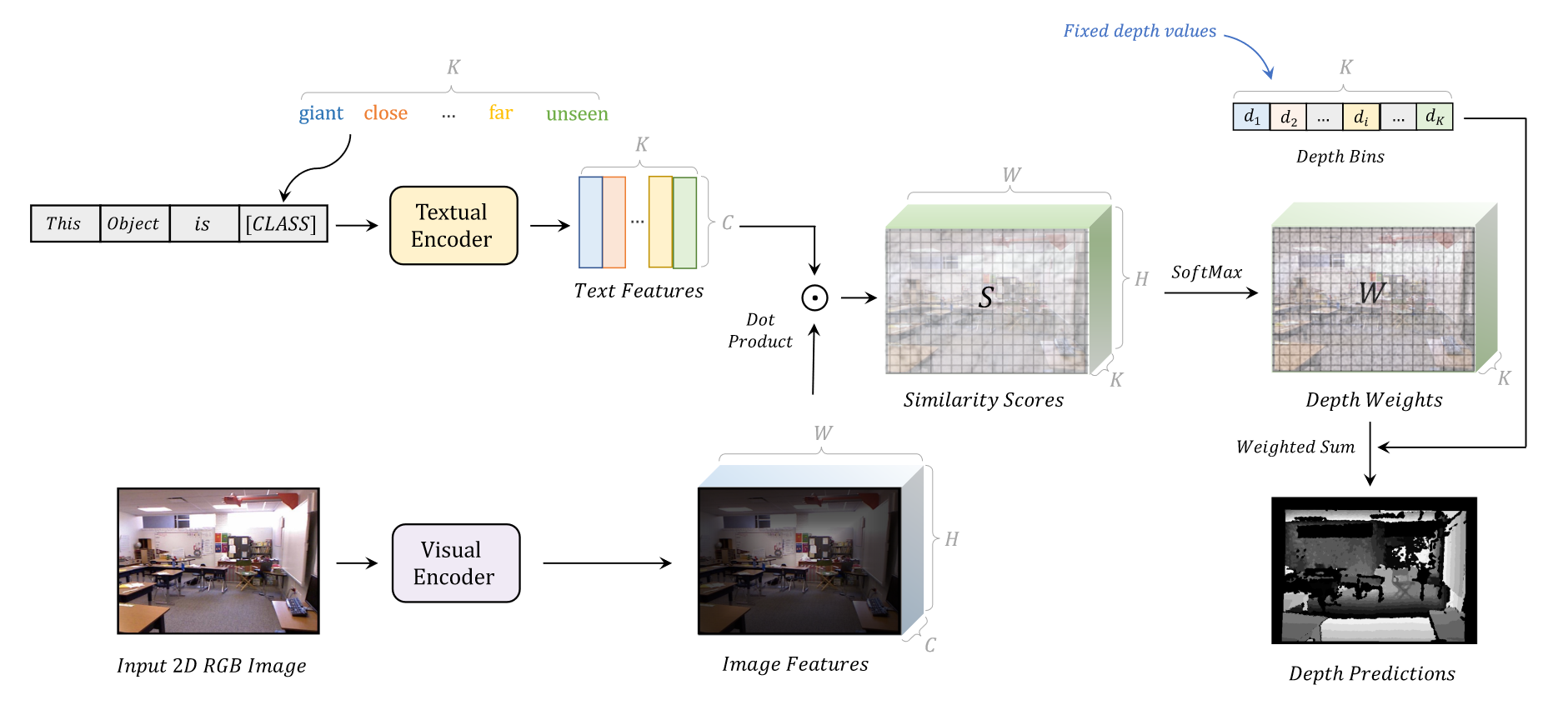
5.4 DepthCLIP
CLIP对物体十分敏感,但是对抽象的概念理解较弱,因此很少将CLIP应用到概念任务。DepthCLIP这篇工作巧妙将深度估计问题转换为文本理解的问题,在图像深度估计任务上取得了很好的效果。它将深度估计看做是分类问题,而不是回归问题,将深度距离强制分为了7个大类。因此文本的Prompt就是对这7个类的扩充,文本和图像分别编码,然后计算相似度矩阵,最后通过softmax进行分类得到深度图,流程如下所示:
该工作和PointCLIP的一作都是同一个作者,这表明CLIP可以在CV或多模态的很多小领域略加一些改动,就可以取得成功。
总结
通过对上面工作的阅读,当前对CLIP的应用可以分为三个方面:
- 将图文通过CLIP得到特征,然后将这些特征融合起来去做之前的任务,加强模型的训练。
- 把CLIP特征作为teacher,和当前的模型做蒸馏,学习到更好的预训练知识。
- 借鉴CLIP的思想,应用到当前领域,自己定义对比学习和正负样本。
CLIP模型通过对比学习的方式,将多模态的信息融合在了一起,这种信息增强的方式是让模型无论是当前任务还是迁移到别的数据集甚至是不同任务都能表现优异的真正原因。通过上面的工作也可以看到,CLIP的思想已经被应用在了各个领域,大家早早就占好了坑,能做的领域大家都做了个遍,所以未来可以做的方向,一个是让CLIP在部分领域又专又精,加入更多领域的方法和知识,另一个方向就是改进CLIP这种信息融合的学习方式,通过设计一些其他的代理任务来帮助模型更好融合多模态的知识,这样又会掀起另一波CLIP浪潮。
参考链接
https://arxiv.org/pdf/2201.03546.pdf
https://arxiv.org/pdf/2202.11094.pdf
https://arxiv.org/pdf/2104.13921.pdf
https://arxiv.org/pdf/2112.03857.pdf
https://proceedings.neurips.cc/paper_files/paper/2022/file/ea370419760b421ce12e3082eb2ae1a8-Paper-Conference.pdf
https://arxiv.org/pdf/2202.05822.pdf
https://arxiv.org/pdf/2104.08860.pdf
https://arxiv.org/pdf/2109.08472.pdf
https://arxiv.org/pdf/2107.06383.pdf
https://arxiv.org/pdf/2106.13043.pdf
https://openaccess.thecvf.com/content/CVPR2022/papers/Zhang_PointCLIP_Point_Cloud_Understanding_by_CLIP_CVPR_2022_paper.pdf
https://arxiv.org/pdf/2207.01077.pdf



















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











