







 本文提出了一种名为SACH的新方法,利用预训练的CLIP模型和注意力机制改善无监督跨模态哈希,提高图像-文本检索的性能。SACH通过融合CLIP特征和注意力特征来构建语义相似度矩阵,保持模态间和模态内的语义一致性,从而实现更准确的检索。在MIRFlickr-25K和NUS-WIDE数据集上的实验显示,SACH优于其他浅层和深层的无监督方法。
本文提出了一种名为SACH的新方法,利用预训练的CLIP模型和注意力机制改善无监督跨模态哈希,提高图像-文本检索的性能。SACH通过融合CLIP特征和注意力特征来构建语义相似度矩阵,保持模态间和模态内的语义一致性,从而实现更准确的检索。在MIRFlickr-25K和NUS-WIDE数据集上的实验显示,SACH优于其他浅层和深层的无监督方法。
文章目录
Self-Attentive CLIP Hashing for Unsupervised Cross-Modal Retrieval
【MMAsia ’22, December 13–16, 2022, Tokyo, Japan】
无监督跨模态检索的自注意CLIP哈希
Abstract
本文提出的动机/现有方法存在问题:
1)大多数现有研究在有效利用 原始图像-文本对raw image-text pairs 来生成判别特征表示方面 存在困难。
2)这些方法忽略了不同模态之间的潜在关系,不能构建稳健的相似性矩阵,导致检索性能次优。
本文提出:自注意CLIP哈希(SACH)
- 利用预训练的CLIP模型构建特征提取网络,该模型在零样本任务中表现出了优异的性能。
- 此外,为了充分利用语义关系,引入了注意力模块来减少冗余信息的干扰,并将注意力集中在重要信息上。
- 在此基础上,构造了一个语义融合相似度矩阵,该矩阵能够保留不同模态的原始语义关系。
Introduction
通常,来自各种模态的实例具有不同的数据分布和特征表示。为了获得更好的跨模态检索体验,将多模态数据统一到一个具有低异构性low heterogeneities(也称modality gap)的公共汉明子空间的跨模态哈希方法已经成为人们关注的话题。
无监督跨模态哈希的不足
尽管无监督跨模态哈希具有适用性,但仍存在严重的不足。
最近的工作只是通过简单的网络从不同的模态中提取特征,或者直接使用原始数据集提供的特征。然而,次优的特征表示总是不足以探索模态之间的亲和关系。
此外,尽管一些开创性的工作在跨模态语义重构方面取得了很大进展,但这些方法大多 没有充分利用来自不同模态的互补信息和排他性信息。
它们仍然存在 对关键特征缺乏额外关注和过度冗余的融合策略 问题,因此在特征提取和相似性融合过程中仍有进一步优化的潜力。
解决——自注意CLIP哈希SACH
提出了一种新的无监督跨模态哈希方法,称为自注意CLIP哈希(SACH)。
SACH 利用预先训练的CLIP模型来提取多模态特征表示。模态数据被映射到相同的编码空间中,有助于减轻汉明空间中不同模态之间的异构性。
引入了一种注意力机制来减少关键信息的丢失并抑制不重要的信息。
此外,通过前两步构建了一个全新的语义融合相似度矩阵,从而更好地保持了模态内和模态间的关系。
最后,采用相似性加权机制将不同的实例对拉开,并将相似的实例对拉近,有助于更具鉴别性的哈希表示。
Contributions贡献
- 据我们所知,SACH是将CLIP引入图像-文本哈希检索的第一次尝试。它利用预先训练的CLIP模型,用一个模型提取多模态特征,这有助于缩小模态之间的差距。
- 我们引入了一个注意力模块来关注相关的模态内特征,并构建了一个新的语义融合相似性矩阵,该矩阵将原始的CLIP模型与注意力模块输出相结合。它可以有效地保持模态内和模态间的关系,提高跨模态的不变性。
- 在两个跨模态基准数据集上进行的大量实验表明,与其他无监督的浅层和深层跨模态哈希方法相比,SACH具有优越性。
Related Work
Unsupervised Cross Modal Hashing
CLIP
Attention Mechanism
Methodology
Problem Definition
假设 O = { o i } i = 1 n O=\{o_i\}_{i=1}^n O={oi}i=1n是具有n对实例 o i = [ I i , T i ] o_i=[I_i,T_i] oi=[Ii,Ti]的训练集,其中 I i I_i Ii表示第 i i i个图像, T i T_i Ti表示与图像 I i I_i Ii对应的文本描述。
给定训练数据,SACH的最终目的是学习投影函数 f I ( I ; θ I ) f_I(I;\theta_I) fI(I;θI)和 f T ( T ; θ T ) f_T(T;\theta_T) fT(T;θT)(其中 θ I \theta_I θI和 θ T \theta_T θT分别是图像网络和文本网络的参数),并生成统一的二值表示 B I = { b i 1 , b i 2 , … , b i n } ∈ { − 1 , + 1 } n × d B_I=\{b_i^1, b_i^2, \dots, b_i^n\} \in \{-1,+1\}^{n \times d} BI={bi1,bi2,…,bin}∈{−1,+1}n×d 和 B T = { b t 1 , b t 2 , … , b t n } ∈ { − 1 , + 1 } n × d B_T=\{b_t^1, b_t^2, \dots, b_t^n\} \in \{-1,+1\}^{n \times d} BT={bt1,bt2,…,btn}∈{−1,+1}n×d,其中 d d d是二值码长度。
向量 x x x 和 y y y 之间的 C o n s i n e Consine Consine 距离被定义为: c o s ( x i , y j ) = x i T y j ∥ x i ∥ 2 ∥ y j ∥ 2 cos(x_i,y_j)=\frac{x_i^T y_j}{{\parallel x_i \parallel}_2 {\parallel y_j \parallel}_2} cos(xi,yj)=∥xi∥2∥yj∥2xiTyj.
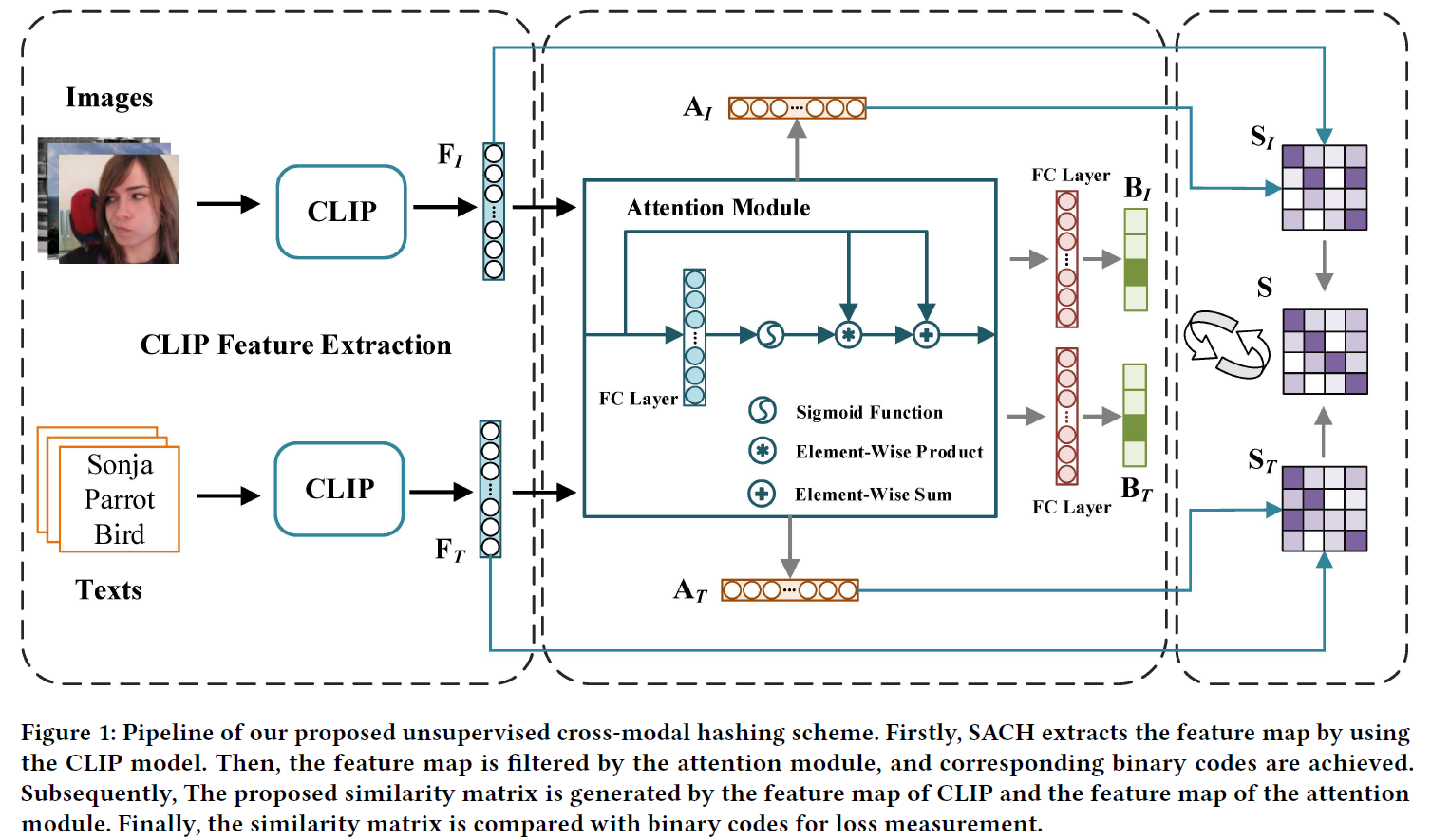
Hashing Representation Extraction
模态数据首先被输入到CLIP模型中用于特征提取。
然后通过注意力模块对特征图进行优化。
最后在全连接层之后实现哈希表示。
CLIP Feature Extraction
受CLIP出色的传递能力的启发,我们没有使用早期的训练方法,例如AlexNet网络或Vgg16网络进行图像特征提取,也没有使用词袋BoW或MLP进行文本特征提取,而是直接使用预训练的CLIP模型来学习图像特征和文本特征。
由于两种模态的特征被映射到同一编码空间并由一个模型生成,因此它们可以被视为同一域中的语义向量,这有助于保持来自不同模态的实例的一致性。
CLIP的输出表示为 F I = { f i 1 , f i 2 , … , f i n } ∈ R n × c F_I= \{ f_i^1, f_i^2, \dots, f_i^n \} \in \mathbb{R}^{n \times c} FI={fi1,fi2,…,fin}∈Rn×c, F T = { f t 1 , f t 2 , … , f t n } ∈ R n × c F_T= \{ f_t^1, f_t^2, \dots, f_t^n \} \in \mathbb{R}^{n \times c} FT={ft1,ft2,…,ftn}∈Rn×c, 其中 c c c表示通过预训练的CLIP模型提取的特征的维度。
Attention Feature Extraction
在特征图中也有多余的信息需要过滤,关键信息值得被注意。
受最新工作的启发,引入了一个注意力模块来学习提取的CLIP特征图的权重矩阵。过滤过程定义如下:
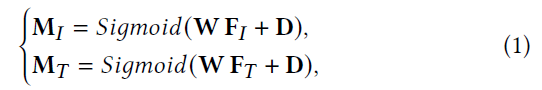
- M I ∈ R n × c M_I \in \mathbb R^{n \times c} MI∈Rn×c 和 M T ∈ R n × c M_T \in \mathbb R^{n \times c} MT∈Rn×c是掩码权重矩阵。
- S i g m o i d Sigmoid Sigmoid表示激活函数
- W W W 和 D D D表示全连接层的参数。
在获得掩码权重矩阵后,可以通过将它们与原始CLIP特征相乘来获得新的语义特征。
然而,简单的点乘操作会使输出特征太小,无法进行下一个学习过程,因此,受残差网络的启发,为了使模型能够获得更深层次的语义信息,同时保留原始的CLIP特征,CLIP的输出被添加到注意力模块中。优化方案定义如下:
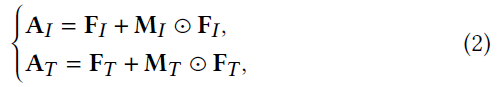
- ⊙ \odot ⊙ 表示元素乘积
- A I ∈ R n × c A_I \in \mathbb R^{n \times c} AI∈Rn×c 和 A T ∈ R n × c A_T \in \mathbb R^{n \times c} AT∈Rn×c 是与图像模态和文本模态相对应的注意力模块的输出。
Hashing Representation
最终,
A
I
A_I
AI和
A
T
A_T
AT被送到全连接层中以生成模态的哈希表示。具体来说,图像模态
H
I
H_I
HI和文本模态
H
T
H_T
HT。
然后对应的二值表示
B
I
B_I
BI和
B
T
B_T
BT可以在二值化操作之后生成。
Similarity Matrix Construction
在无监督跨模态哈希学习中,通常通过将特征图乘以自身来直接计算单个模态的自相似性矩阵。
然而,由于在本文中,特征图是通过注意力模块优化的,因此注意力模块的输出应该与前一个模块具有相同的模态一致性。
根据数据融合data fusion的思想,本文试图融合CLIP特征和注意力特征的语义信息,以保持模态一致性并获取更高的相关性。
首先,归一化
F
I
,
F
T
,
A
I
,
A
T
F_I, F_T, A_I, A_T
FI,FT,AI,AT到
F
^
I
,
F
^
T
,
A
^
I
,
A
^
T
\hat F_I, \hat F_T, \hat A_I, \hat A_T
F^I,F^T,A^I,A^T之后,我们可以构造包含丰富语义信息的余弦相似矩阵来描述邻域结构:
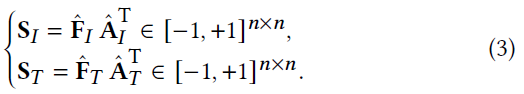
然后,我们将
S
I
S_I
SI和
S
T
S_T
ST融合在统一的相似度矩阵中实现高阶邻域描述,这可以保留耦合实例对之间的语义信息,并相互补充。
融合相似性定义为:
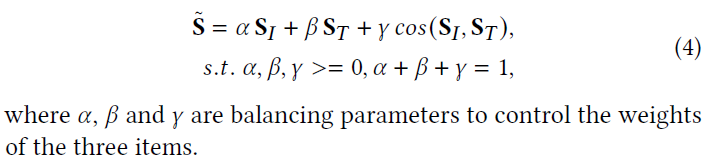
由于相似性分布因数据集而异,因此适当方所实例对之间的相似性可以产生更健壮的哈希码。
在本文中,采用【Jointmodal distribution-based similarity hashing for large-scale unsupervised deep cross-modal retrieval. In ACM SIGIR.】提出的基于分布的相似性加权策略来更新 S ~ \tilde S S~,并生成最终的语义融合相似性矩阵 S = { s i j } i , j = 1 n S = \{s_{ij}\}_{i,j=1}^n S={sij}i,j=1n。
细化过程如下:
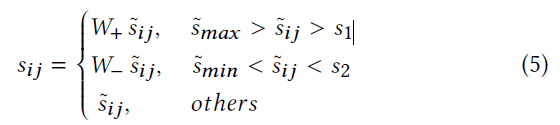
- s 1 s_1 s1和 s 2 s_2 s2是阈值
-
W
+
W_+
W+和
W
−
W_-
W−用于拉近相似的实例对并推开不相似的样本对
- W + = 1 + λ 1 e s ~ i j − s ~ m a x W_+ = 1 + \lambda_1 e^{\tilde s_{ij} - \tilde s_{max}} W+=1+λ1es~ij−s~max
- W − = 1 + λ 2 e s ~ m i n − s ~ i j W_- = 1 + \lambda_2 e^{\tilde s_{min} - \tilde s_{ij}} W−=1+λ2es~min−s~ij
动态加权策略有助于实现更均衡的数据分布,这有助于生成更具鉴别力和准确的二值表示。
Objective Function
生成的二值码可以被视为超立方体顶点的特征向量(feature vectors of a hyper-cube vertex)。
从这个角度看,相邻的顶点对应相似的哈希码,因此,可以通过计算它们的角距离(angular distance)来获得二值码之间的距离。
给定二值表示
B
I
,
B
T
B_I, B_T
BI,BT,成对余弦相似性定义如下:
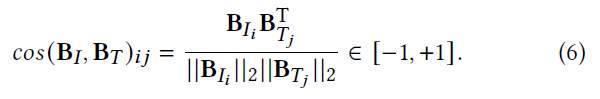
为了保持来自不同模态的实例对的关系,我们将相似性矩阵
S
S
S与
c
o
s
(
B
I
,
B
T
)
cos(B_I, B_T)
cos(BI,BT)进行比较,以保持模态间语义的一致性:

同样的,将相似矩阵
S
S
S与待学习的
c
o
s
(
B
I
,
B
I
)
cos(B_I, B_I)
cos(BI,BI)和
c
o
s
(
B
T
,
B
T
)
cos(B_T, B_T)
cos(BT,BT)进行比较,保持模态内一致性:
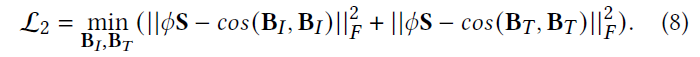
综上所述,将上述两个损失函数分量整合到新的目标函数
L
L
L中,最终目标函数定义如下:
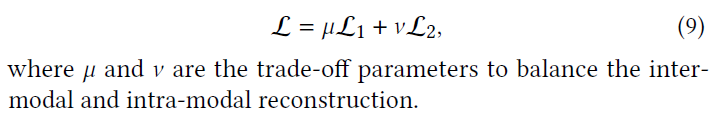
Optimization
由 B I B_I BI和 B T B_T BT梯度消失问题难以解决,无法直接优化Eq. 9。我们将最后一个隐藏层(没有激活函数)的输出表示为 H H H,应用 s g n sgn sgn函数将 H H H映射为二值表示。
然而,由于 s g n sgn sgn函数的输出为-1或+1,因此,所有非零输入都会导致梯度为0,这阻碍了反向传播过程。
在这里,我们采用缩放 t a n h tanh tanh函数来解决这个问题:
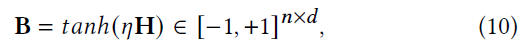
- η \eta η为缩放参数
随着训练过程中 η \eta η的增加,得到 lim η → + ∞ t a n h ( η x ) = s g n ( x ) \lim \limits_{\eta \to +\infty} tanh(\eta x) = sgn(x) η→+∞limtanh(ηx)=sgn(x)。
如图2所示,可以很好地解决上述棘手的问题。
Experiments
Datasets
MIRFlickr-25K
是一个多标签数据集,由从Flickr网站收集的25,000对图像-文本组成,用24个提供的标签进行标注。
该数据集还分别为每个图像和文本内容提供SIFT描述符和1386维向量。
为了公平比较,我们随机选择2000对图像-文本实例对进行测试,5000对图像-文本实例对进行训练。
NUS-WIDE
由269,648个图像-文本实例对组成。
根据之前的工作,最终的实验数据集包含了前10个最常用的概念以及相应的186,577个实例对。
对于每个图像对应的文本,我们根据频率等级选择1000个注释标签的索引向量。
用于测试和训练的实例对数量与MIRFlickr-25K相同。
Evaluation Metric
在这项工作中,我们关注两个典型的跨模态检索任务:用给定的图像示例搜索相关的文本内容(“图像 → \to →文本”)和用给定的文本内容搜索相关的图像(“文本 → \to →图像”)。
为了公平比较,我们选择了两个广泛使用的检索指标,平均平均精度(mAP) 和 top-N精度曲线 作为所有比较方法的评价标准。
具体来说,给定一个查询和一组 R R R个检索数据,查询的平均精度(AP)定义为:
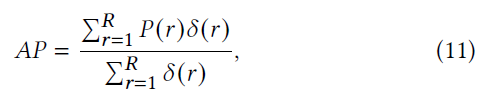
- δ ( r ) = 1 \delta(r) = 1 δ(r)=1:查询和第 r r r个检索实例是ground-truth neighbors,否则 δ ( r ) = 0 \delta(r) = 0 δ(r)=0
- P ( r ) P(r) P(r)表示排名在 r r r的检索实例的精度
mAP是通过对所有的查询的AP取平均值获得的。
在这项工作中,那些共享至少一个公共标签的数据点被视为ground-truth neighbors。
Implementation Details
与以往工作不同的是,我们没有使用MIRFlickr-25K和NUS-WIDE提供的可用特征,而是对于每个batch输入 { I i } i = 1 n \{ I_i\}_{i=1}^n {Ii}i=1n,我们直接采用数据集提供的原始图像,而对于 { T i } i = 1 n \{ T_i\}_{i=1}^n {Ti}i=1n,我们将原始文本描述经过标记(tokenized)后输入CLIP模型。
SACH方法在Pytorch上实现,并在一个Nvidia RTX 3090 GPU上进行了训练。
使用动量为0.9,权重衰减为0.005的mini-batch SGD optimizer。
为了收敛,将batch size大小固定为32,最大迭代次数设置为80。
根据经验设置MIRFlickr-25的 λ 1 = 0.1 \lambda_1=0.1 λ1=0.1, λ 2 = 0.2 \lambda_2=0.2 λ2=0.2,NUS-WIDE的 λ 1 = 0.2 \lambda_1=0.2 λ1=0.2, λ 2 = 0.2 \lambda_2=0.2 λ2=0.2,两个数据集的 ϕ = 1.4 \phi = 1.4 ϕ=1.4。
经过交叉验证,最终设置MIRFlickr-25K的 α = 0.6 , β = 0.1 , γ = 0.3 \alpha =0.6, \beta=0.1, \gamma=0.3 α=0.6,β=0.1,γ=0.3,NUSWIDE的 α = 0.6 , β = 0.2 , γ = 0.2 \alpha =0.6, \beta=0.2, \gamma=0.2 α=0.6,β=0.2,γ=0.2,对于两个数据集的 μ = 1 , v = 0.1 \mu=1,v=0.1 μ=1,v=0.1。
由于图像网络和文本网络可以看作是一个单独的哈希网络,所以SACH的学习率设置为0.001。
检索点的数量 R R R被设置为50用于mAP评估。
Performance Comparison
为了验证提出的SACH的有效性,选择了7种最先进的无监督方法,包括3种浅层方法和4种深层方法为基线。
- CVH
- CMFH
- LSSH
- DBRC
- UDCMH
- DJSRH
- JDSH
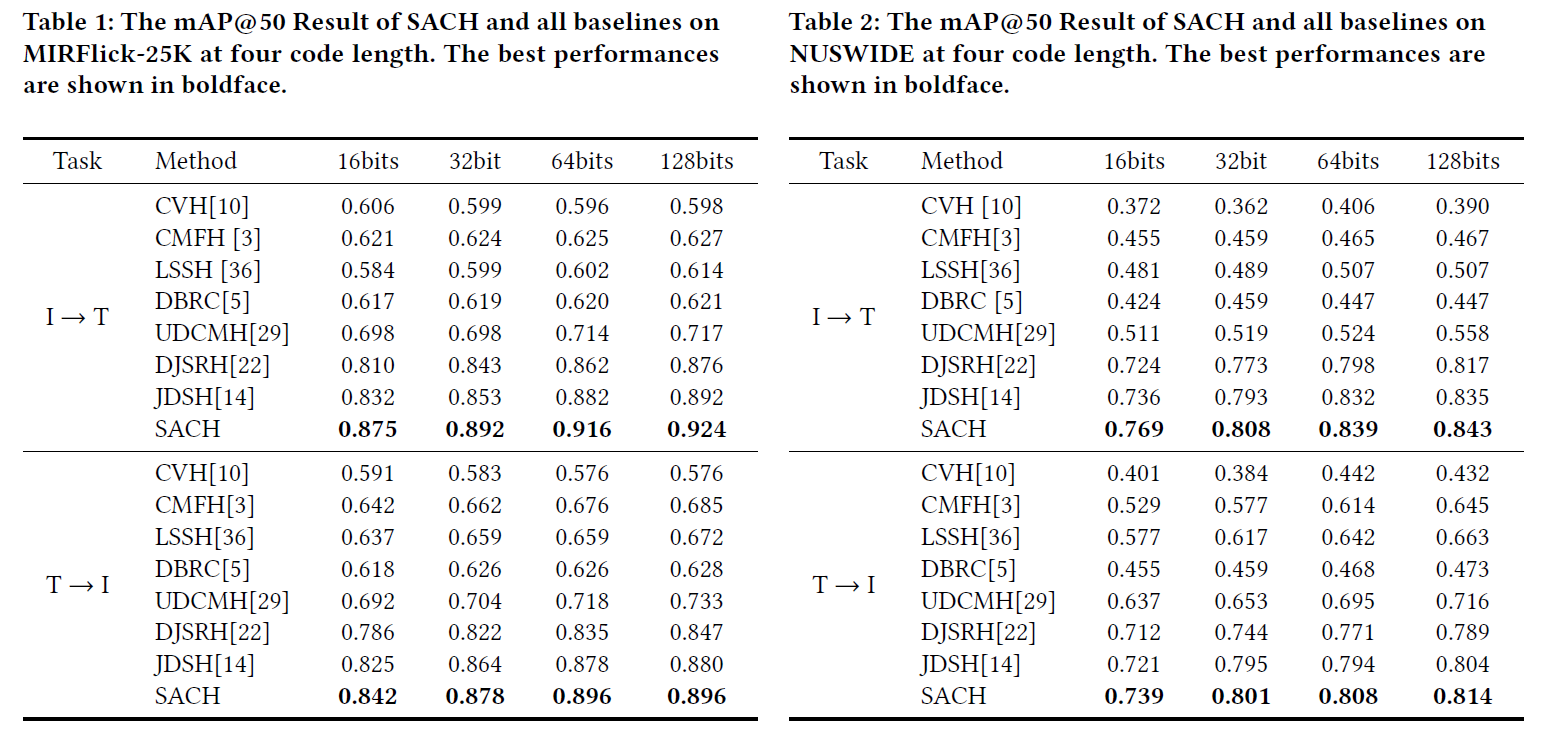
如表1和表2所示,提出的SACH的性能超过了在各种代码长度下的比较的所有浅层和深层方法。
特别是在MIRFlickr数据集上,与经典浅层方法相比,SACH在
I
→
T
I \to T
I→T和
T
→
I
T \to I
T→I任务的四个码长中分别至少提高了29.1%和21.5%,与最先进的深度方法JDSH相比,我们的性能在两个任务上分别提高了3.95%和1.63%。
在NUSWIDE数据集上,我们的方法在两个任务上的性能比最先进的浅层方法LSSH分别高出31.7%和16.7%,与JDSH相比分别提高了1.6%和1.2%。
值得注意的是,基于深度学习的方法总是优于浅层学习的方法。此外,随着编码长度的增加,所有方法的性能都有所提高,这表明较长的编码长度可以更好地保留语义关系。
NUSWIDE数据集比MIRFlickr-25K数据集具有更多的实例对,我们的方法在这两个数据集上都取得了改进。这表明SACH适用于可扩展的跨模态检索任务。
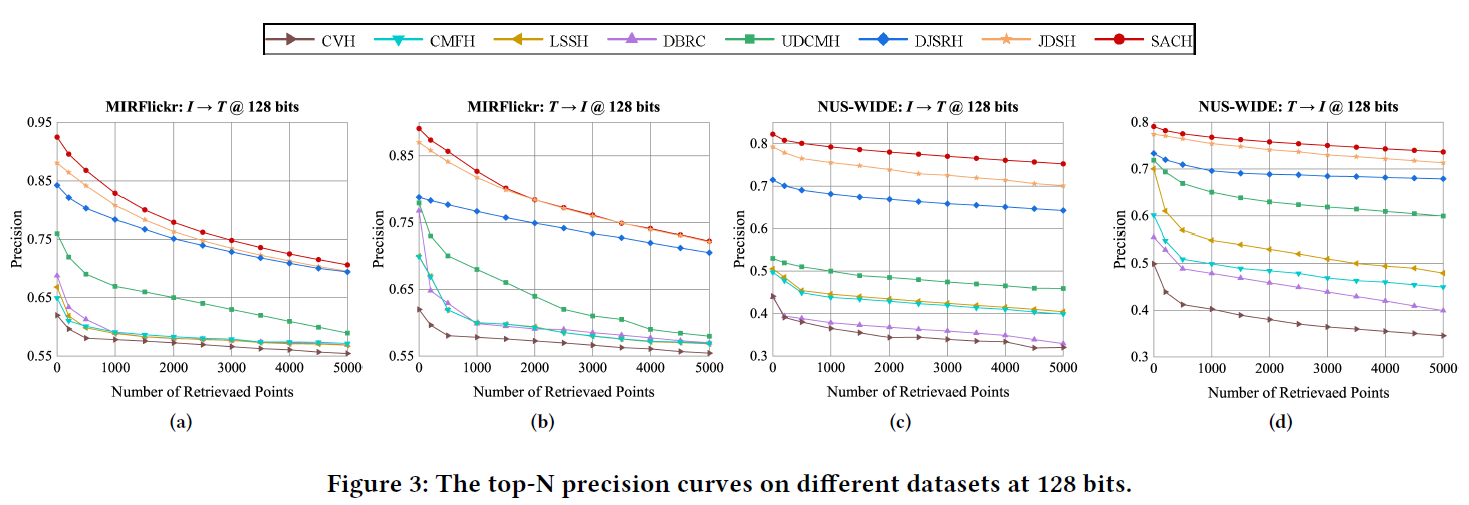
各对比方法的top-N精度曲线如图3所示。这表明我们的方法在两个数据集上优于其他方法,由此可以推断SACH在无监督跨模态检索任务中具有更好的性能。
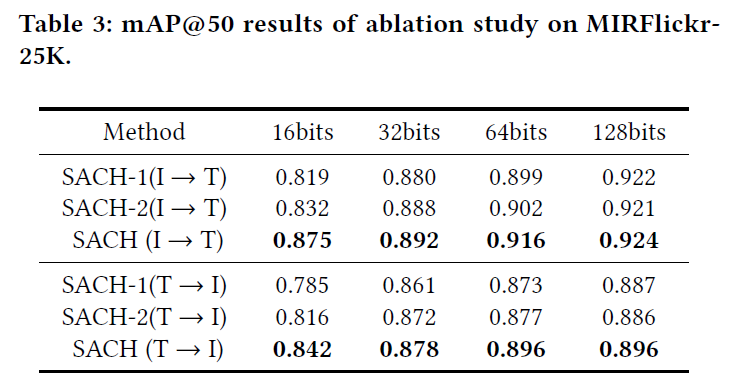
Ablation Study
在本节中,略微修改了模型结构,以进一步验证我们提出的每个组件的有效性。在实验中:
- SACH-1是抛弃了注意力模块,直接使用CLIP生成的特征来计算相似矩阵的变体。
- Eq. 3变为 S I = F ^ I F ^ I T S_I=\hat F_I \hat F_I^T SI=F^IF^IT, S T = F ^ T F ^ T T S_T=\hat F_T \hat F_T^T ST=F^TF^TT
- SACH-2是没有使用CLIP特征进行相似性融合过程的变体。
- S I = A ^ I A ^ I T S_I=\hat A_I \hat A_I^T SI=A^IA^IT, S T = A ^ T A ^ T T S_T=\hat A_T \hat A_T^T ST=A^TA^TT
消融结果如表3所示。很明显,缺少任何组件都会导致性能下降。我们可以得出结论,所有提出的组件都有助于性能改进,并且它们都是不可或缺的。此外,结果表明,我们提出的语义融合相似矩阵可以进一步利用自注意力机制的优势。
Parameters Seneitivity Analysis
为了验证哪个部分对检索性能的影响更大,是模态间一致性还是模态内一致性,我们还进行了参数敏感性分析实验。
如图4所示,在{0.01,0.1,1,2,5,10}中调整 μ \mu μ,在{0.001,0.01,0.1,0.2,0.5,1}中调整了 v v v。
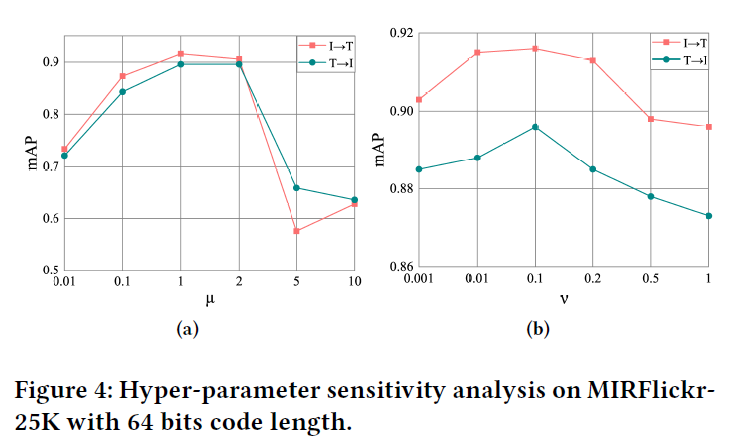
很明显,(a)中的曲线随着指数的变化而有明显的波动,而(b)中的曲线更平坦。根据上述结果,我们可以得出,在训练过程中,确保模态间一致性更为重要。此外,利用模态内语义关系可以进一步提高SACH的性能。
Conclusion
在本文中,我们提出了 自注意CLIP哈希(SACH) 来处理无监督的跨模态检索任务。
SACH首先利用CLIP模型生成图像模态和文本模态的特征表示。
然后,利用注意力模块对特征映射的关键部分进行关注。
在此基础上,创新性地设计了CLIP特征与注意特征相结合的融合相似矩阵,并引入相似度加权机制对相似度矩阵进行优化。
因此,可以很好地保持模态内和模态间的语义一致性。
最后,通过缩放
t
a
n
h
tanh
tanh函数生成二值码,平滑地解决了
s
g
n
sgn
sgn函数引起的反向传播问题。
在两个基准数据集上进行了大量的实验,结果证明了我们提出的SACH的优越性。


















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









