






摘要: 本文深入探讨了使用 StyleGAN 生成艺术图像的原理、方法与实践。首先介绍了生成对抗网络(GAN)的基本概念与发展历程,随后详细阐述了 StyleGAN 的独特架构和创新之处,包括其风格迁移机制、渐进式增长策略等。通过大量代码示例展示了如何在实际环境中配置 StyleGAN、准备数据集、训练模型以及生成高质量的艺术图像,并对生成结果进行了分析与评估。文中还讨论了 StyleGAN 在艺术创作领域的应用前景与面临的挑战,为读者深入理解和应用 StyleGAN 进行艺术图像生成提供了全面且详细的参考。
一、引言
随着人工智能技术的飞速发展,生成对抗网络(GAN)在图像生成领域取得了令人瞩目的成就。StyleGAN 作为 GAN 的一种先进变体,以其能够生成高度逼真且风格多样化的图像而备受关注。在艺术创作领域,它为艺术家和创作者提供了全新的工具和灵感来源,能够生成独特的艺术图像,拓展了艺术创作的边界。
二、生成对抗网络(GAN)基础
(一)GAN 的基本原理
GAN 由生成器(Generator)和判别器(Discriminator)两个主要组件构成。生成器的任务是根据随机噪声生成图像,而判别器则负责区分真实图像和生成器生成的假图像。在训练过程中,生成器和判别器相互博弈,生成器不断优化以生成更逼真的图像来欺骗判别器,判别器则不断提高识别能力以准确区分真假图像,最终达到一种平衡状态,此时生成器能够生成高质量的逼真图像。
(二)GAN 的发展历程
GAN 自 2014 年提出以来经历了多个发展阶段。早期的 GAN 模型如 DCGAN 奠定了基础架构,随后出现了许多改进版本,如 WGAN 解决了训练不稳定的问题,LSGAN 优化了损失函数等。这些发展为 StyleGAN 的出现奠定了坚实的理论和实践基础。
三、StyleGAN 架构剖析
(一)风格迁移机制
StyleGAN 引入了独特的风格迁移机制。它通过将输入的随机噪声映射到不同的风格空间,然后在生成图像的不同层次上应用这些风格信息。例如,在生成图像的低层次特征(如纹理、颜色)和高层次特征(如形状、结构)上分别应用不同的风格,从而实现了对图像风格的精细控制。
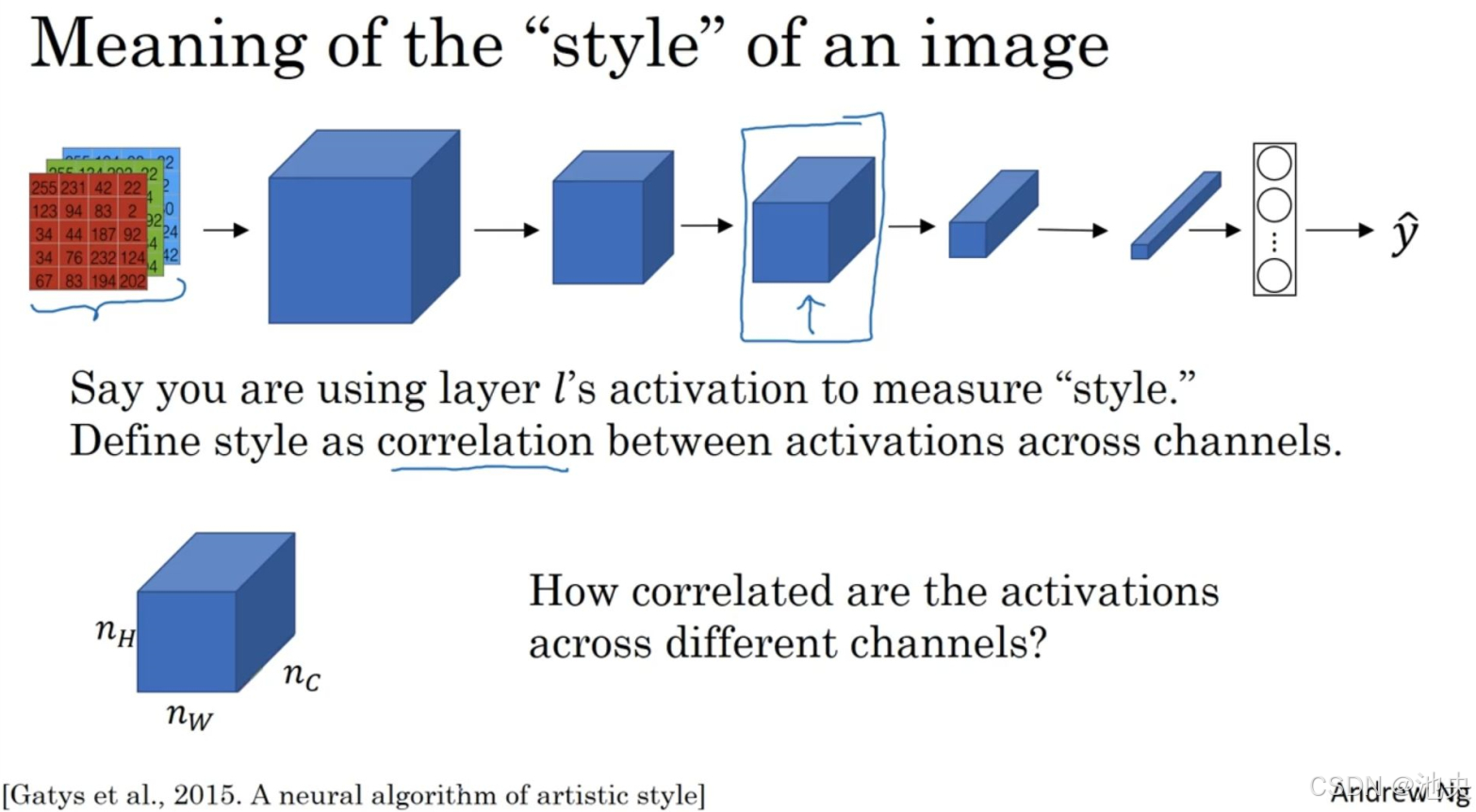
以下是风格迁移的简单代码示例:
# 定义风格映射网络
def style_mapping_network(z):
# 这里可以是多层全连接网络等操作
# 将输入噪声 z 映射到风格空间
style = some_layers(z)
return style
# 在生成图像的某一层应用风格
def apply_style(style, layer):
# 根据风格信息调整该层的参数或特征
layer = modify_layer(layer, style)
return layer(二)渐进式增长策略
StyleGAN 采用了渐进式增长策略。在训练初期,生成低分辨率的图像,随着训练的进行,逐步增加图像的分辨率。这种策略有助于稳定训练过程,提高生成图像的质量。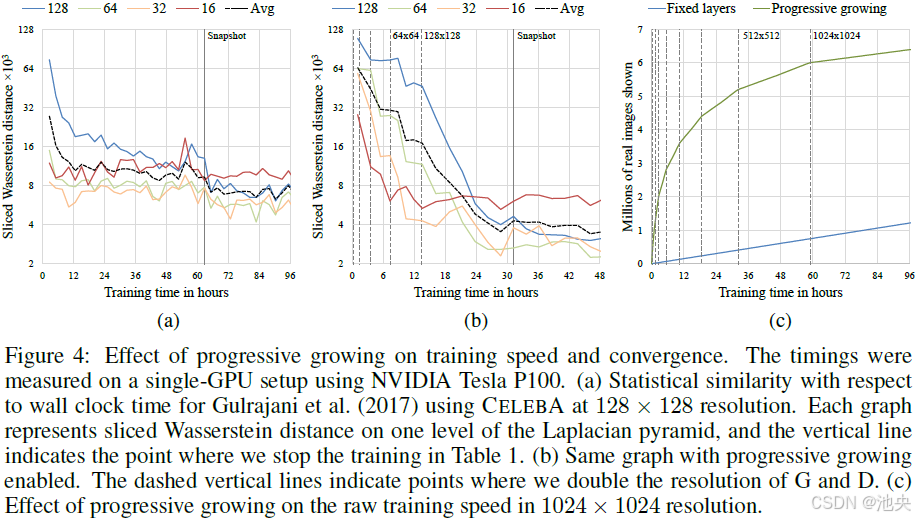
# 渐进式增长训练过程示例
for resolution in [4, 8, 16, 32, 64, 128, 256, 512, 1024]:
# 根据当前分辨率构建网络结构
model = build_model(resolution)
# 训练模型
train_model(model, dataset, current_resolution)四、使用 StyleGAN 生成艺术图像的实践
(一)环境配置
首先需要安装相关的库,如 TensorFlow 或 PyTorch。以 TensorFlow 为例:
pip install tensorflow(二)数据集准备
选择合适的艺术图像数据集,如包含各种绘画风格的图像数据集。可以使用数据增强技术来扩充数据集,提高模型的泛化能力。
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 数据生成器
datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# 加载数据集
dataset = datagen.flow_from_directory(
'data/art_images',
target_size=(256, 256),
batch_size=32,
class_mode='categorical')(三)模型训练
构建 StyleGAN 模型并进行训练。以下是一个简化的训练代码框架:
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D, UpSampling2D
# 定义生成器
def build_generator():
# 输入噪声
z = Input(shape=(100,))
# 多层网络构建生成器结构
x = Dense(256 * 4 * 4)(z)
x = tf.reshape(x, (-1, 4, 4, 256))
x = UpSampling2D()(x)
x = Conv2D(128, (3, 3), padding='same', activation='relu')(x)
# 继续添加更多层
#...
# 输出图像
img = Conv2D(3, (3, 3), padding='same', activation='tanh')(x)
return Model(z, img)
# 定义判别器
def build_discriminator():
# 输入图像
img = Input(shape=(256, 256, 3))
# 多层卷积网络构建判别器结构
x = Conv2D(64, (3, 3), strides=(2, 2), padding='same', activation='relu')(img)
# 继续添加更多层
#...
# 输出判别结果
validity = Dense(1, activation='sigmoid')(x)
return Model(img, validity)
# 构建生成器和判别器实例
generator = build_generator()
discriminator = build_discriminator()
# 定义损失函数和优化器
cross_entropy = tf.keras.losses.BinaryCrossentropy()
generator_optimizer = tf.keras.optimizers.Adam(0.0002, 0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(0.0002, 0.5)
# 训练循环
@tf.function
def train_step(images):
# 生成噪声
noise = tf.random.normal([images.shape[0], 100])
# 生成假图像
generated_images = generator(noise)
# 训练判别器
with tf.GradientTape() as disc_tape:
real_output = discriminator(images)
fake_output = discriminator(generated_images)
# 计算判别器损失
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
discriminator_loss = real_loss + fake_loss
# 计算判别器梯度并更新
discriminator_gradients = disc_tape.gradient(discriminator_loss, discriminator.trainable_variables)
discriminator_optimizer.apply_gradients(zip(discriminator_gradients, discriminator.trainable_variables))
# 训练生成器
with tf.GradientTape() as gen_tape:
generated_images = generator(noise)
fake_output = discriminator(generated_images)
# 计算生成器损失
generator_loss = cross_entropy(tf.ones_like(fake_output), fake_output)
# 计算生成器梯度并更新
generator_gradients = gen_tape.gradient(generator_loss, generator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients, generator.trainable_variables))
# 进行多轮训练
for epoch in range(100):
for batch_images in dataset:
train_step(batch_images)(四)图像生成
训练完成后,可以使用生成器生成艺术图像。
# 生成图像
noise = tf.random.normal([1, 100])
generated_image = generator(noise)
# 对生成图像进行后处理,如将像素值转换到合适范围等
generated_image = postprocess_image(generated_image)五、生成结果分析与评估
(一)图像质量评估指标
可以使用多种指标来评估生成图像的质量,如峰值信噪比(PSNR)、结构相似性指数(SSIM)等。这些指标可以定量地衡量生成图像与真实图像在像素级和结构上的相似程度。
import skimage.metrics as metrics
# 计算 PSNR
psnr_value = metrics.peak_signal_noise_ratio(real_image, generated_image)
# 计算 SSIM
ssim_value = metrics.structural_similarity(real_image, generated_image, multichannel=True)(二)视觉效果评估
通过人工观察生成图像的视觉效果,评估其在艺术风格、图像细节、色彩搭配等方面的表现。例如,生成的绘画风格图像是否具有与真实绘画相似的笔触、纹理和色彩情感等。
六、StyleGAN 在艺术创作中的应用前景与挑战
(一)应用前景
- 艺术创作辅助:为艺术家提供创意灵感,帮助快速生成多种风格的草图或概念图,加速创作过程。
- 艺术风格迁移:可以将一种艺术风格迁移到其他图像或视频上,创造出独特的艺术作品或特效。
- 虚拟艺术展览:生成大量独特的艺术图像用于虚拟艺术展览,拓展艺术展示的空间和形式。
(二)挑战
- 版权问题:生成的图像可能涉及版权归属和侵权争议,需要建立明确的版权规则和规范。
- 语义理解:目前 StyleGAN 对图像的语义理解有限,难以生成具有特定语义或主题的图像,需要进一步结合语义理解技术进行改进。
- 计算资源需求:训练 StyleGAN 需要大量的计算资源,包括 GPU 内存和计算时间,限制了其广泛应用。
七、结论
StyleGAN 为艺术图像生成带来了强大的能力和无限的可能性。通过深入理解其架构和原理,掌握其在环境配置、数据集准备、模型训练和图像生成等方面的实践方法,能够利用 StyleGAN 创造出高质量、风格多样的艺术图像。然而,其在应用过程中也面临着版权、语义理解和计算资源等挑战。未来随着技术的不断发展和完善,StyleGAN 在艺术创作领域有望发挥更加重要的作用,推动艺术创作走向新的高度。



















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











