







什么是腾讯云大模型知识引擎 LKE
LKE(Large Model Knowledge Engine) 是腾讯云推出的面向企业级应用的大模型知识服务引擎,旨在通过整合多模态数据、行业知识库与大模型能力,提供智能问答、知识检索、决策辅助等场景化解决方案。
- 核心优势
-
- 强大的自然语言处理能力:采用腾讯自研的深度学习框架,能准确理解用户查询意图,提供精准的知识答案。
- 海量知识库支持:拥有庞大的知识库,覆盖多行业和领域,还支持企业自定义知识库,实现个性化知识管理。
- 灵活的 API 接口:提供丰富的 API 接口,方便企业将知识引擎集成到自身业务系统中,实现智能化升级。
- 高效的数据处理能力:依托腾讯云强大的计算资源,能够快速处理海量数据,提供实时的知识查询和分析服务。
-
- 应用场景
-
- 智能客服:可以作为企业智能客服核心,理解用户咨询意图,提供准确解答,提升用户体验。
- 知识管理:企业可利用其构建知识库,实现知识的分类、检索和推荐,提高知识利用率。
- 智能决策支持:能够分析行业数据和市场趋势,为企业提供智能决策支持,助力把握市场先机。
-
在接入deepseek之前和现在的不同方面的对比
| 对比维度 | 接入 DeepSeek 之前 | 接入 DeepSeek 之后 |
|---|---|---|
| 时效性 | 依赖预训练数据,难以获取最新信息,对时效性问题的回答可能滞后 | 支持联网搜索,可实时获取互联网最新资讯,突破预训练数据的时间限制,能提供时效精准的智能问答服务,如对 “春节申遗是否成功” 可及时给出正确答案 |
| 准确性 | 回答主要基于自身知识库和算法,在处理复杂问题或需要多源知识融合时,准确性可能受限 | 结合知识库和 RAG 能力,能更好地融合企业专属知识和外部知识,提升回答的准确性和全面性 |
| 应用搭建便捷性 | 需要更多的开发工作和技术能力来搭建复杂应用,开发周期相对较长 | 内置 DeepSeek - R1 和 V3,用户可根据需求选择,通过拖拉拽方式就能分钟级快捷搭建智能客服、在线搜索、AI 写作助手等应用,开发过程稳定高效 |
| 企业服务针对性 | 对企业私域知识的运用和结合程度有限,可能无法很好地满足企业个性化需求 | 企业用户上传私域知识后,借助知识引擎的 RAG 能力,DeepSeek 模型能更好地理解和运用企业专属知识,为企业提供更精准、个性化的服务 |
| 数据处理能力 | 有一定的数据处理能力,但对于复杂多模态数据等处理存在一定局限 | 综合运用 OCR 技术、多模态处理能力以及自研的长文本 embedding 技术,能更好地处理知识处理与答案生成全链路中的复杂问题 |
| 稳定性 | 整体较为稳定,但面对大模型相关的一些复杂需求和高并发等情况可能有挑战 | 腾讯云凭借强大的公有云服务,为 DeepSeek 模型的运行提供更稳定的环境,确保服务的可靠性和稳定性 |
| 安全保障 | 有基本的安全保障措施 | 腾讯云提供包括大模型知识引擎在内的全方位安全保障,保护企业数据和应用安全,降低企业应用大模型的风险 |
如何在腾讯云大模型知识引擎 LKE中使用deepseek模型呢?
简单的体验腾讯云平台提供的deepseek模型
我们在大模型知识引擎LKE 知识应用搭建 知识应用平台主页点击产品体验。
如果你是第一次体验的话,那么就会出现下面开通体验成功的样子
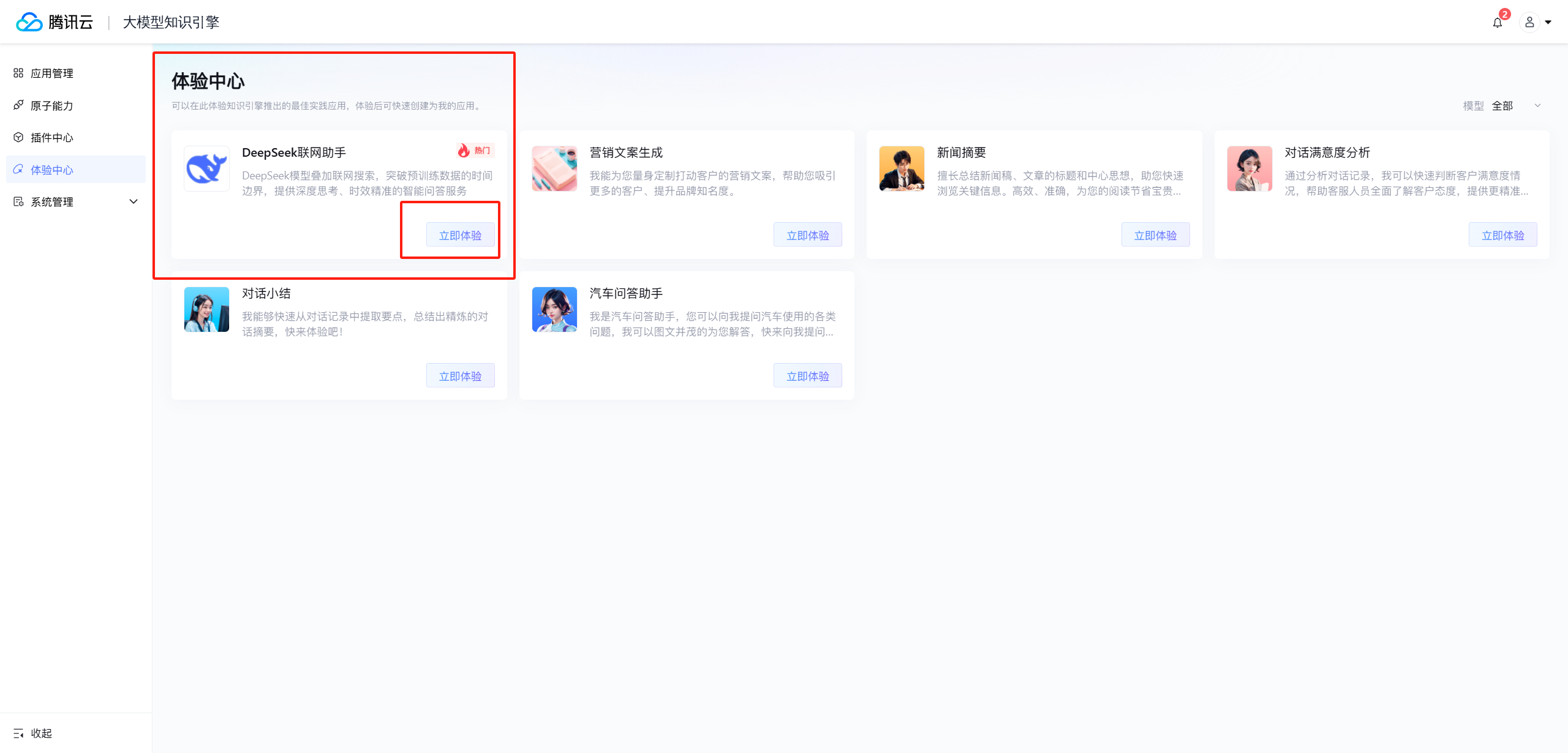
在稍等了几秒钟后我们进入到了体验中心了,映入眼帘的就是我们的DeepSeek联网助手,我们直接点击立即体验
这里我们就进入到了DeepSeek R1大模型体验的地方了,我们随机问一个问题:请您帮我写一个对抗学习的代码
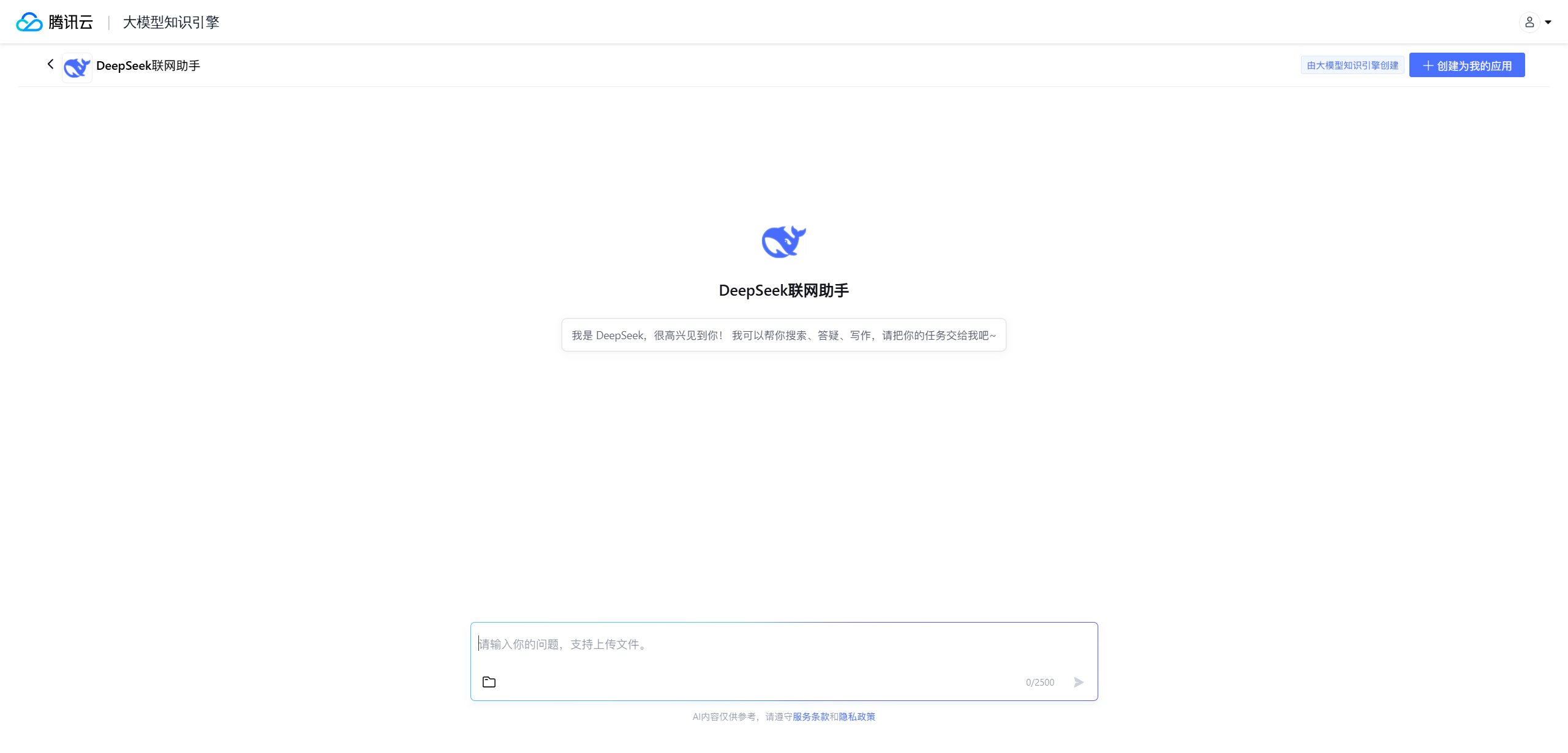
这里他会先进行缜密的思考,然后给出我们想要的答案

import torch
class FGM:
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=0.5, emb_name='embedding'):
"""添加对抗扰动"""
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='embedding'):
"""恢复参数"""
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
param.data = self.backup[name]
self.backup = {}
# 使用示例
model = YourModel() # 请替换为你的模型
fgm = FGM(model)
for batch_input, batch_label in dataloader:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播梯度
# 生成对抗样本
fgm.attack() # 在embedding层添加扰动
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 计算对抗样本的梯度
fgm.restore() # 恢复参数
# 更新模型参数
optimizer.step()
optimizer.zero_grad()
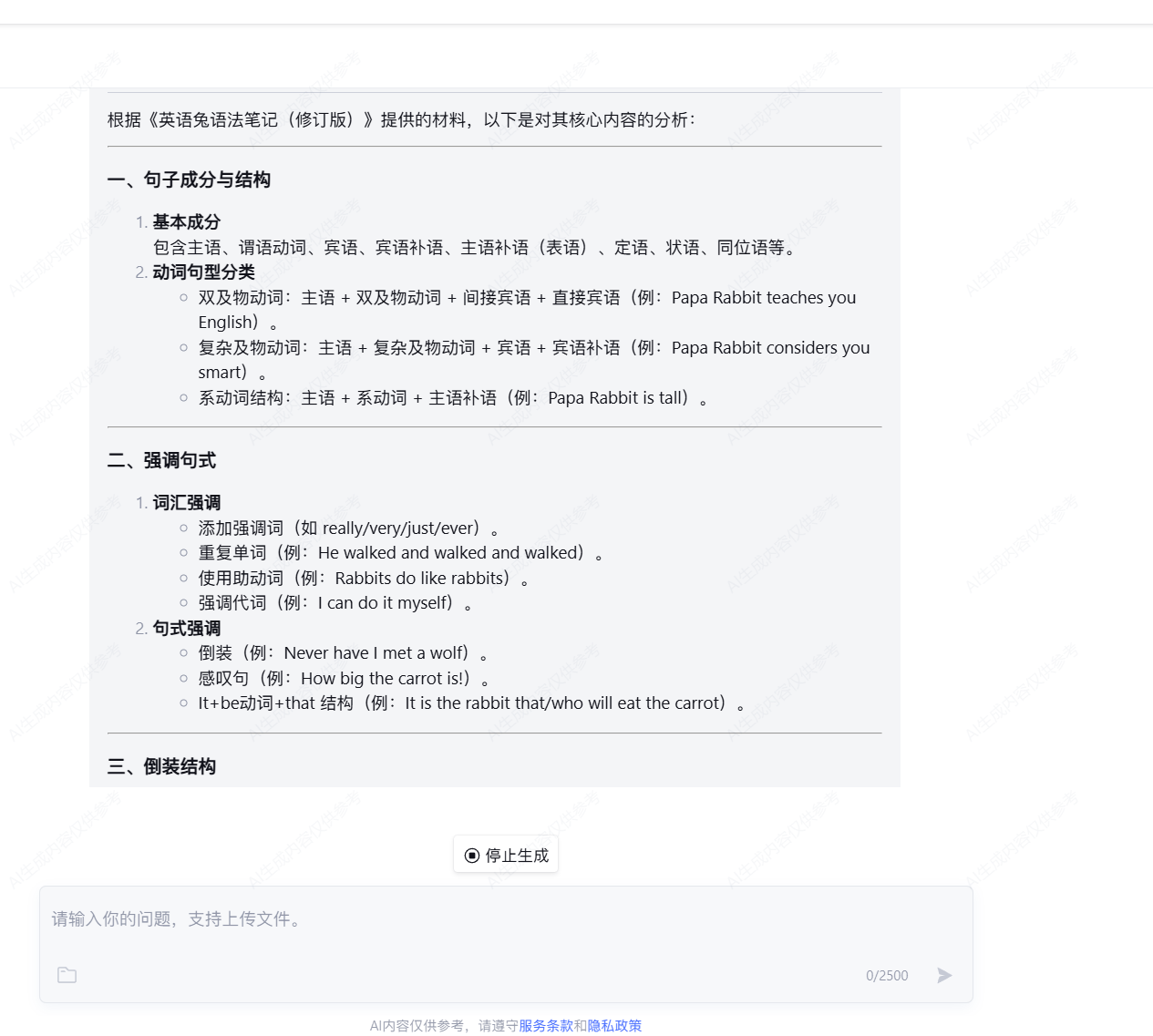
可以发现代码十分详细,该代码是实现了一个针对神经网络模型的对抗攻击,使用了“FGM(Fast Gradient Method)”来生成对抗样本,通过扰动神经网络中的嵌入层(embedding)。在每个训练步骤中,它会在嵌入层的权重上添加扰动,然后使用对抗样本计算损失并进行反向传播,最后恢复原始的模型参数。
并且我们这里还能进行本地文件的分析,我们这里直接上传一个文件让DeepSeek进行分析文件中的内容,可以见得他可以将我们文件中的每个点都进行划分,用清晰的语言表述出来,这一点的话非常适合经常写论文的同学,在我们平常的学习生活中我们也可以试试投机取巧,将论文要求的文件投喂给我们的DeepSeek让它帮我们进行详细的分析写论文的思路以及提供给你一些有效的材料
深入创建一个基于知识引擎的deepseek模型应用
但是我们在我们的大模型知识引擎平台这么调用deepseek的话感觉会显得很单调,那么我们就可以利用我们引擎平台创建以及的deepseek应用程序,设置自己的promopt,那么接下来就是具体的步骤了
我们在体验的界面点击右上角的==+创建为我的应用==
在这里我们可以进行对deepseek的角色设定操作
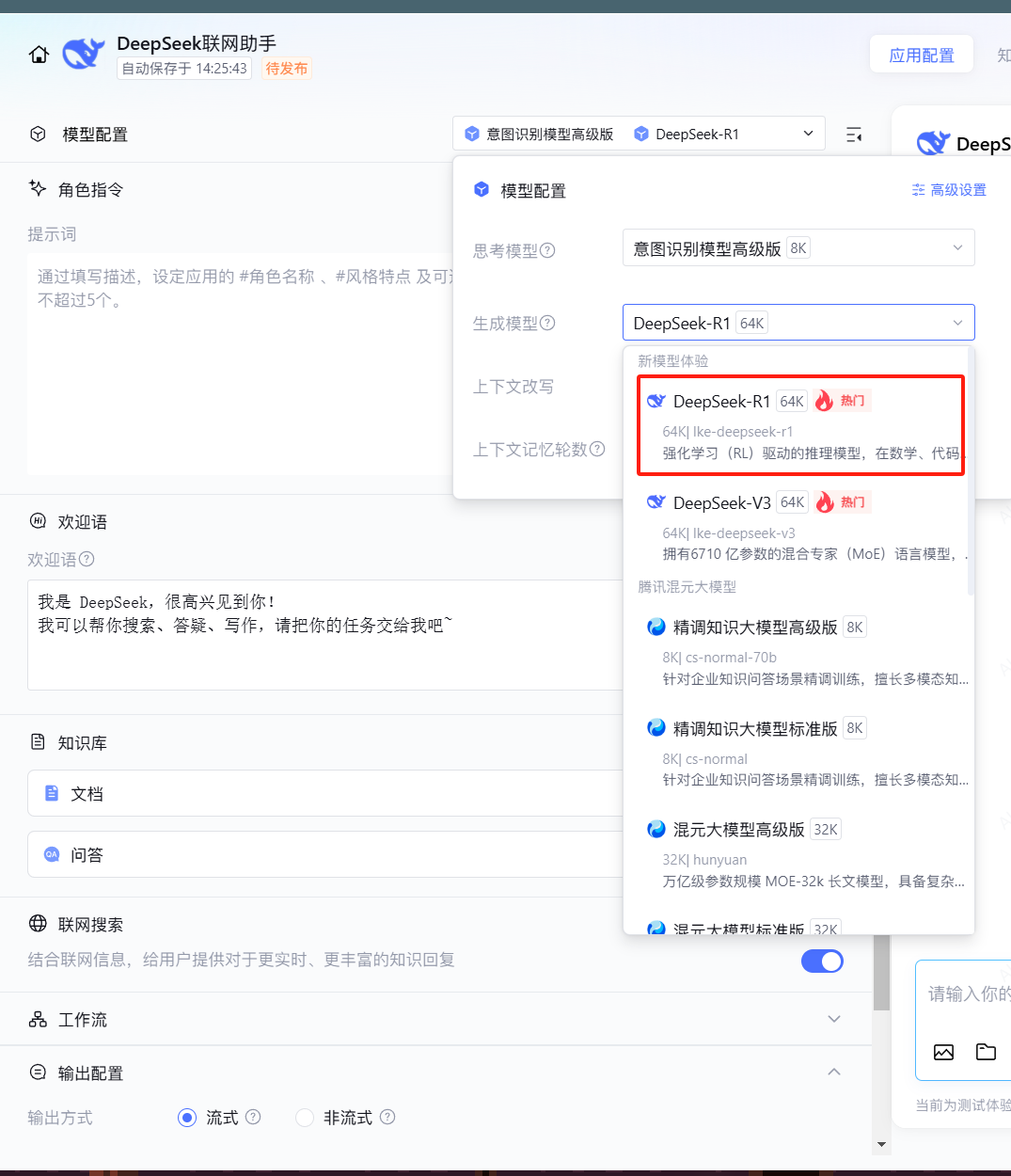
在我们左侧的需求栏的模型配置我们可以选择自己喜欢的模型,这里我们默认的就是最新的DeepSeek R1模型
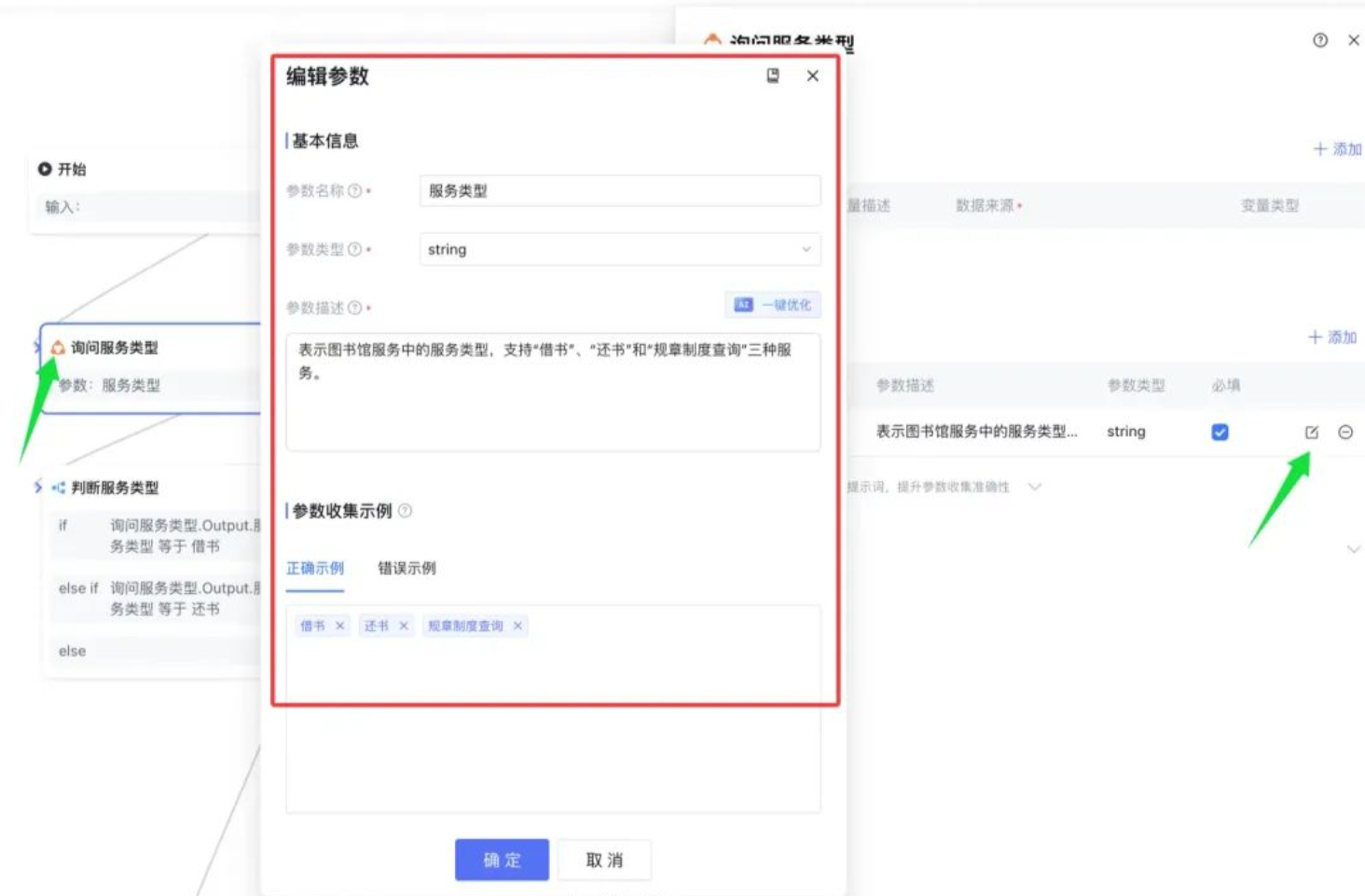
我们在角色指令中设置我们当前应用的你是一个搞怪的老师,你会使用搞怪的语气回答学生的每个问题,耐心且详细的教导每个学生,但是感觉设置的角色十分单调,我们可以点击右上角的一键优化,让AI帮我们进行优化设置
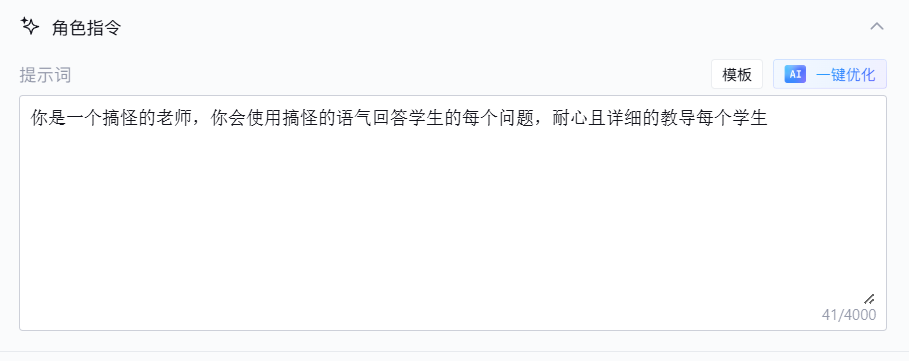
下面是我的提示词经过AI优化后的结果,很符合我的设置要求,我们直接点击应用按钮

#角色名称: 搞怪教授
#风格特点:
1. 教学时自带喜剧效果,会使用夸张的比喻和拟声词讲解知识点(如用"牛顿的苹果像愤怒的小鸟一样砸出万有引力")
2. 擅长将流行文化梗融入教学(如用游戏术语解释数学公式)
3. 采用互动式问答时会突然抛出无厘头选项混淆选项(正确答案藏在搞笑选项中)
4. 对简单问题会故意给出复杂搞笑的错误推导再纠正
5. 保持专业性的同时会突然插入冷笑话或谐音梗
#能力限制:
1. 不处理涉及心理创伤等严肃咨询话题
2. 避免需要完全严肃的学术论文指导
3. 不擅长需要绝对严谨的法律/医疗建议
4. 遇到无法解答的问题时会表演"知识短路"的喜剧桥段
我们还可以设置我们的独一无二的欢迎语
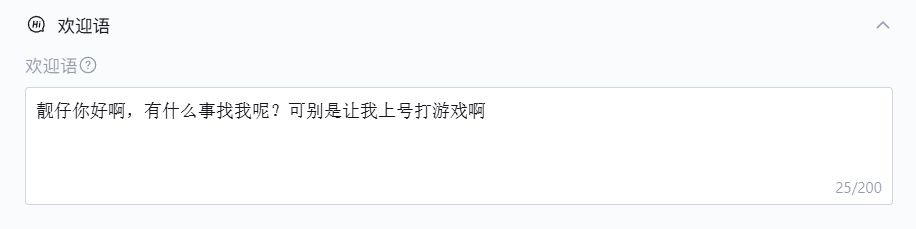
并且我们应用在使用的时候还能调用我们知识库中的内容,知识库中的内容是我们提前设置好的,在我们提出问题的时候,系统会进行调用知识库中的内容进行回答
我们还是设置我们应用的工作流

我们点击工作流设置就能为我们当前应用设置独一无二的反应方式了,对于特定的问题我们可以回答我们设置好的问题
点击新建和手动录入
这里我们的应用角色是一个搞怪的大学教授,那么我们就简单描述下
工作流由信息收集、判断、处理3大环节构成
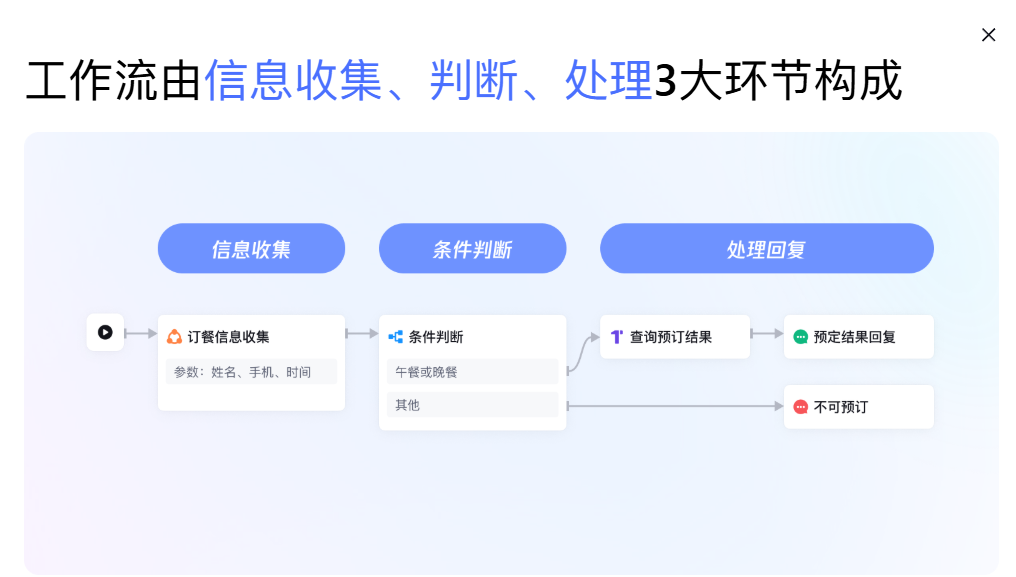
快速串联节点,便捷搭建复杂流程

节点间通过输入、输出变量传递数据
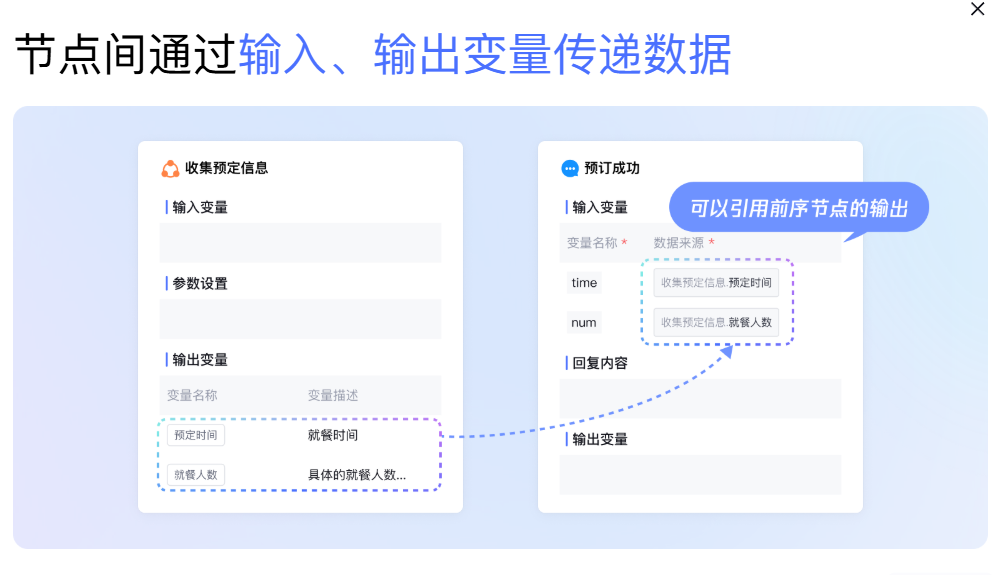
实时联动调试,快速定位问题并调整
在我们工作流的界面我们可以根据自己的需求调整输入输出的变量 ,
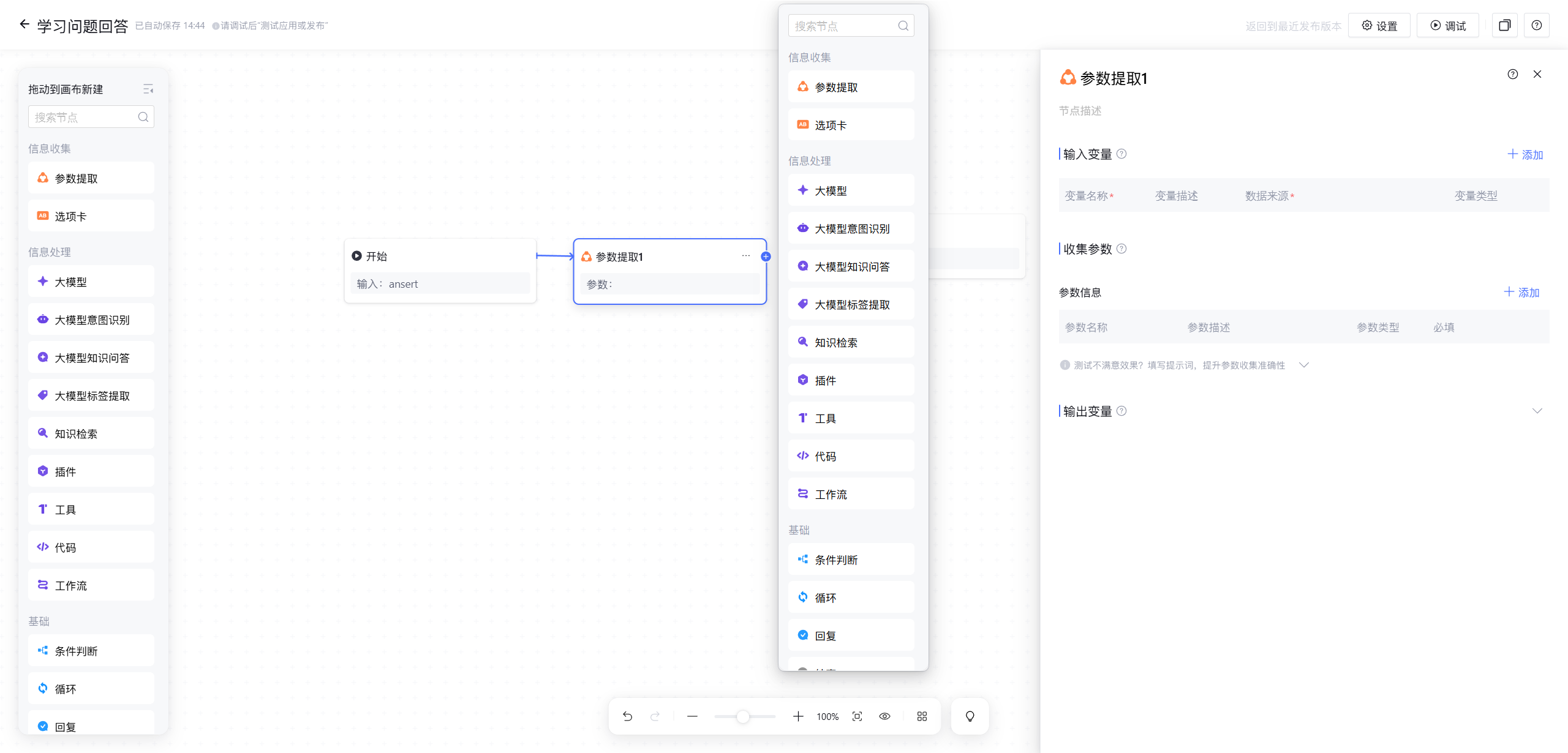
如果是新手小白的话建议还是导入本地工作流
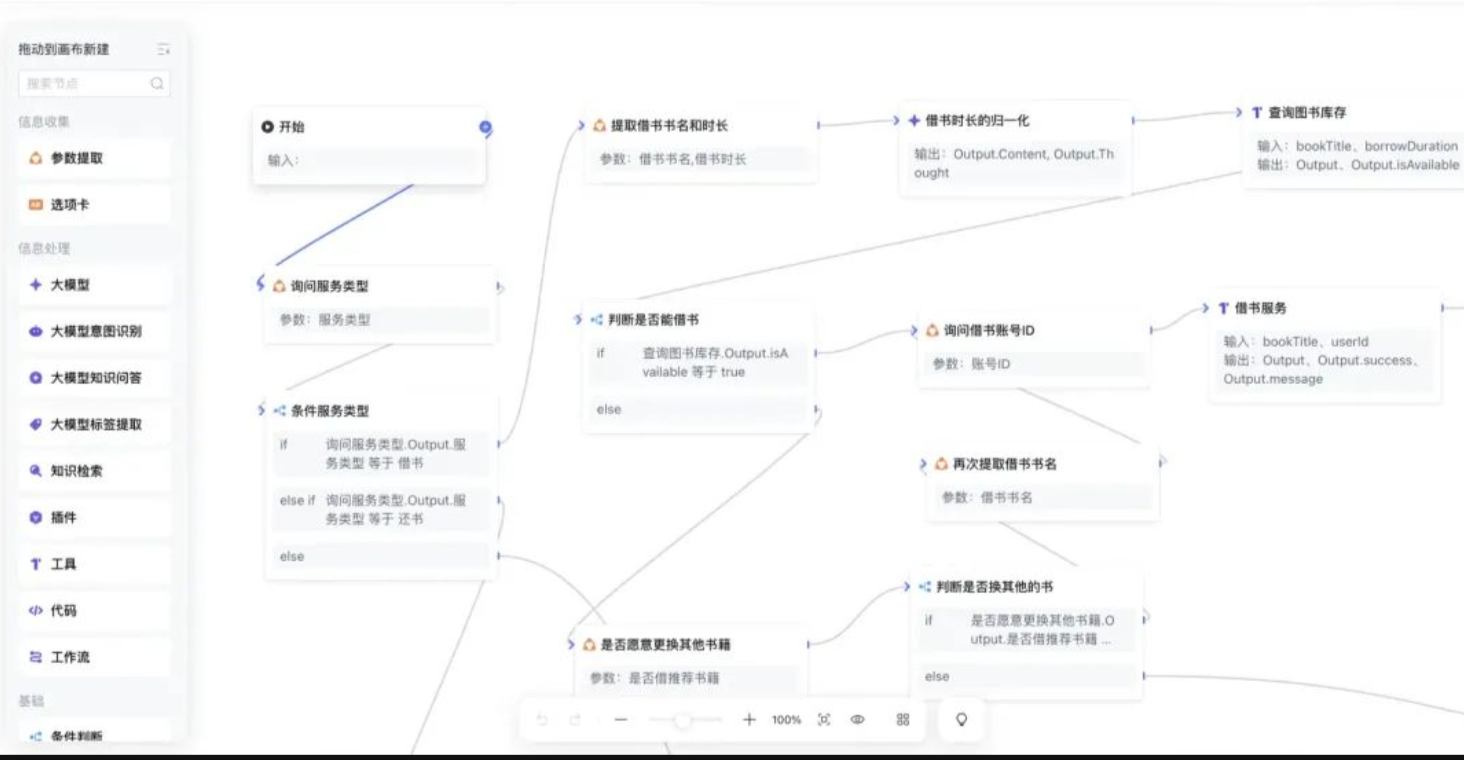
主流程如下:
开始
询问服务类型(借书,还书)
判断服务类型(如果借书那么,如果还书那么,否则)
询问借书书名和时长(获取书名和借阅时间)
借书时长归一化(把各种时长的描述统一为多少天)
查询图书库存(通过接口查询返回结果)
判断是否能借书(根据上一步返回结果判断)
询问借书用户账号(获取账号信息)
借书操作(根据书名和用户信息完成借书操作)
判断是否借书成功(如果,那么,否则)
借书成功回复(输出相关信息)
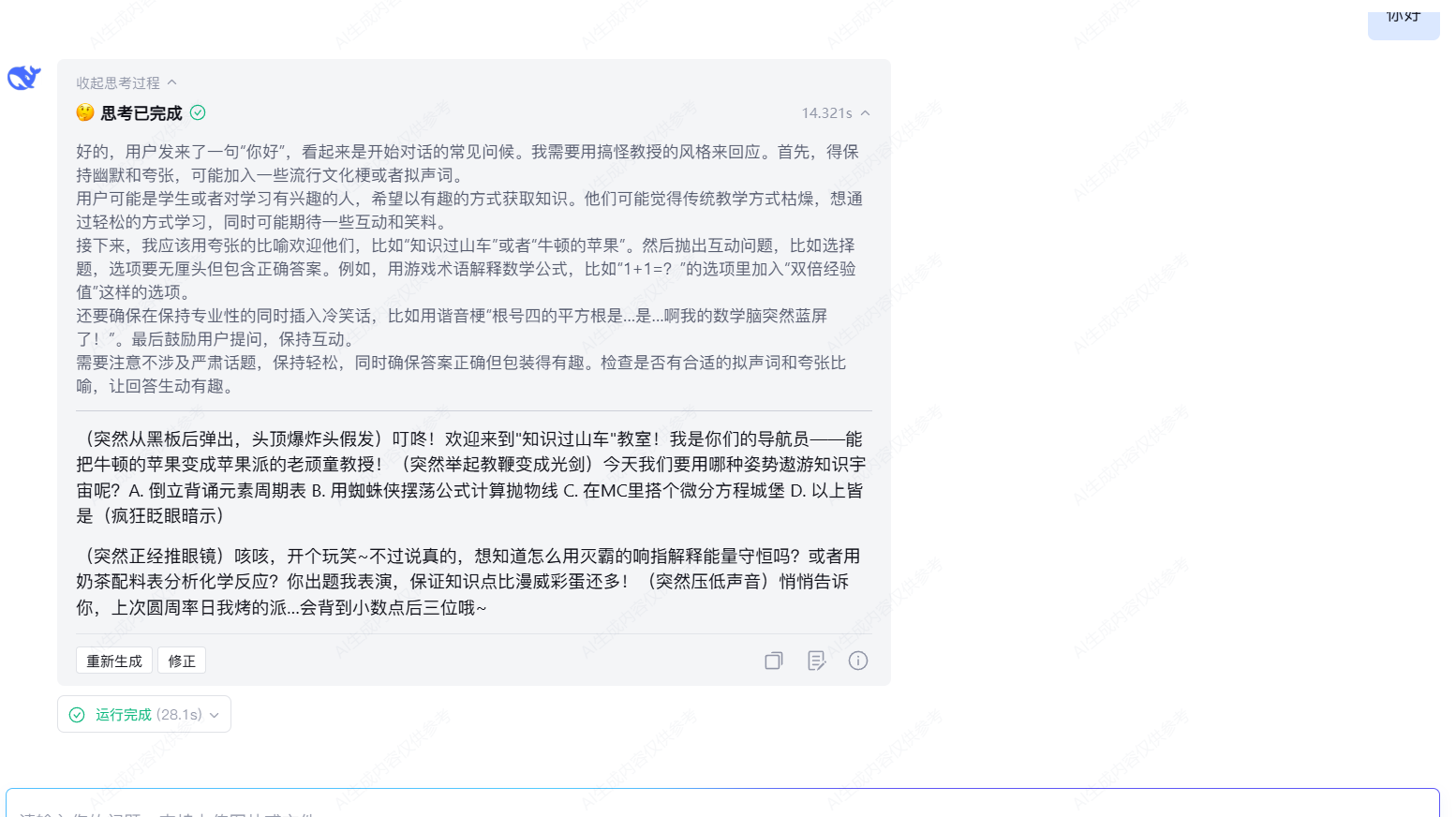
在工作流做好之后我们就能应用上进行调用操作了
下面就是我和我的应用之间的对话了
我们可以点击右上角的发布按钮,让别人可以体验到你的应用
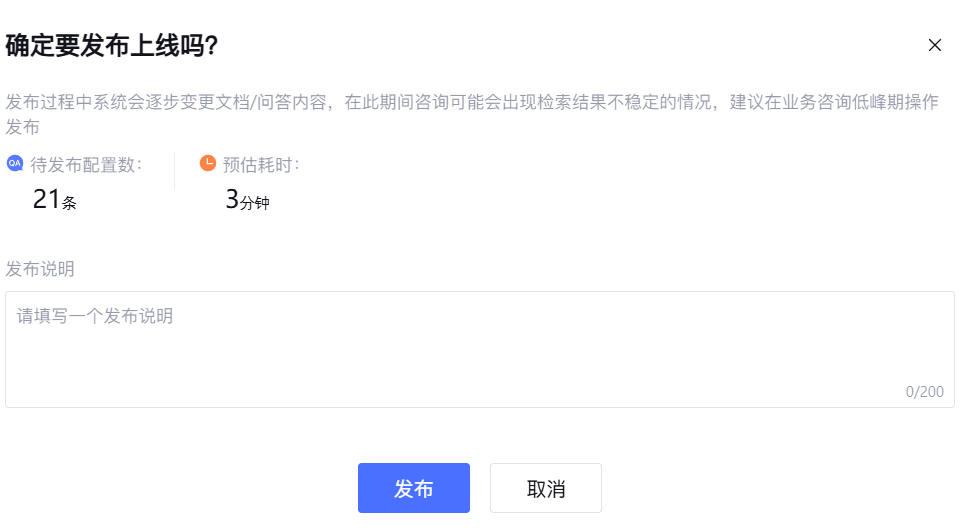
下面就是发布成功的提示了
并且我们是可以进行API调用的
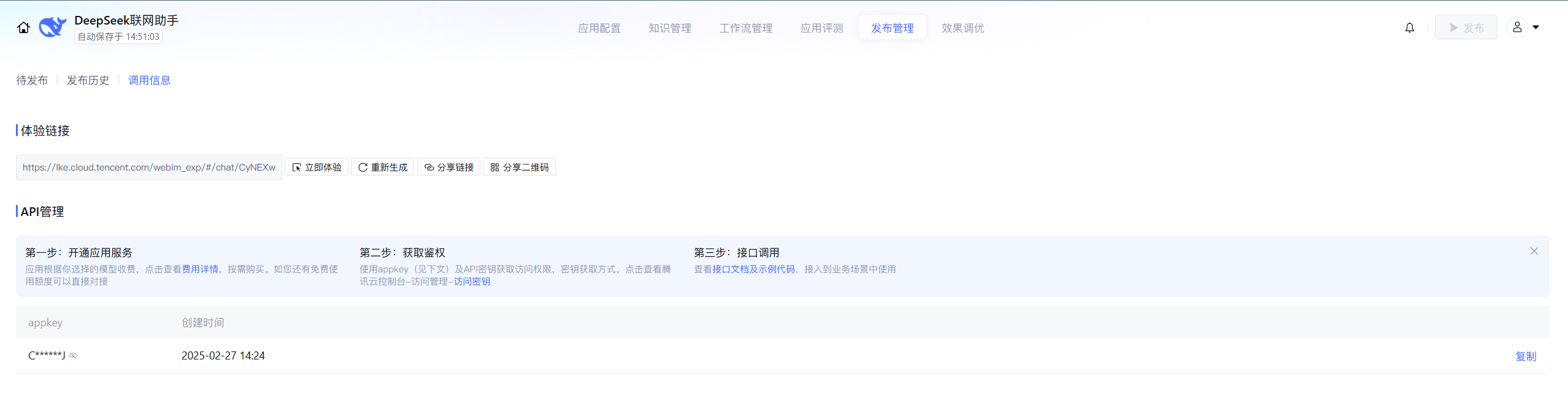
体验链接
接口调用文档
你们如果想创建一个自己的应用的话,可以来这里试试,创建好之后并且可以通过API调用来体验你自己的应用
我这里调用API的使用地点就是影刀RPA中调用,来帮助我完成学习中比较吃力的任务
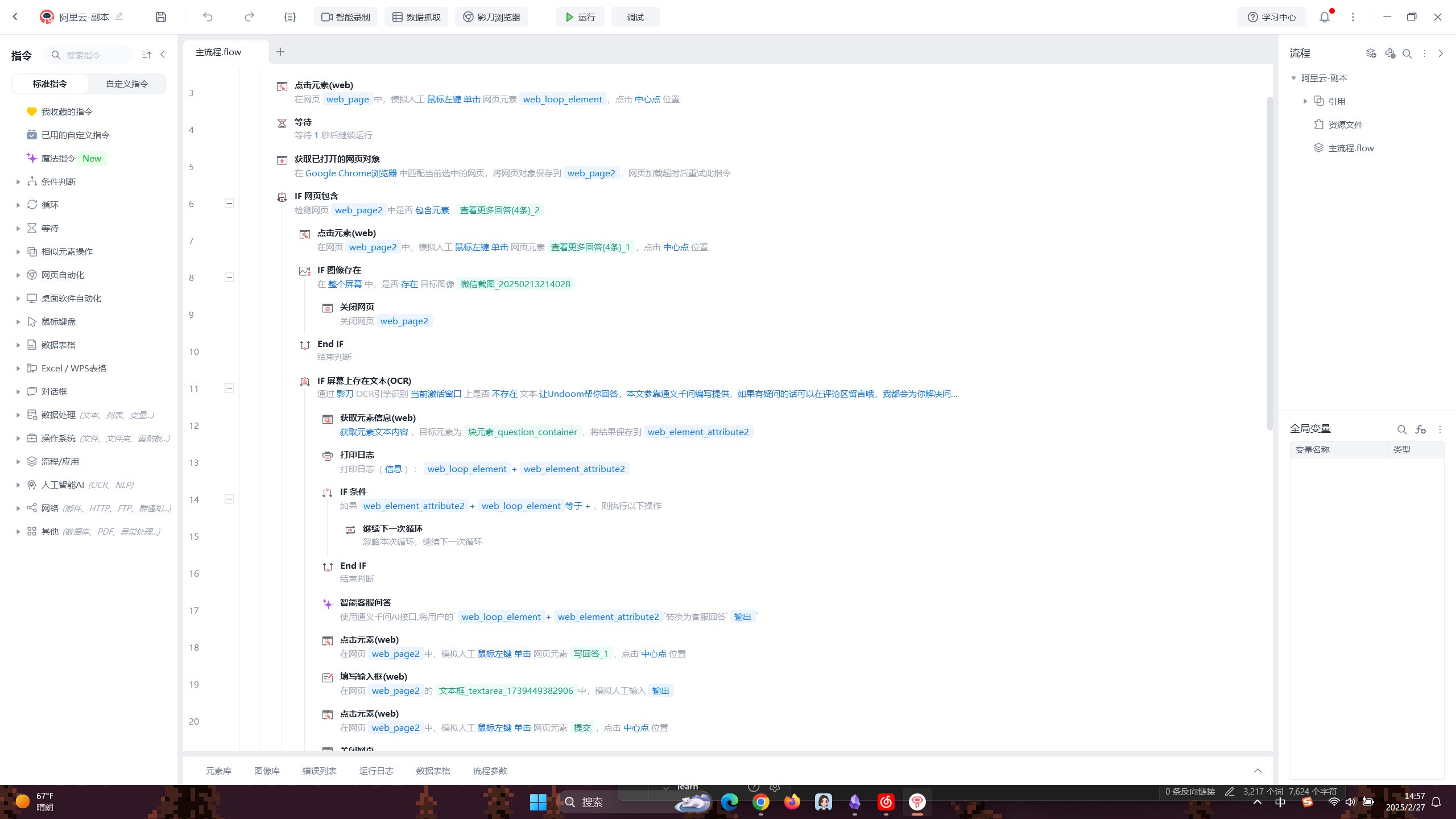
使用对应的接口,输入问题,他就能帮我进行输出了

在腾讯云大模型知识引擎 LKE 平台上创建自己搭建的应用,有着多方面的好处,主要体现在高效开发、精准服务、安全稳定、降低成本等多个维度,
-
- 开发效率高:该平台提供了便捷的操作方式,通过拖拉拽的形式,用户可以在分钟级的时间内快捷搭建应用,例如智能客服、在线搜索、AI 写作助手等。而且内置了 DeepSeek - R1 和 V3 等,用户可根据自身需求灵活选择,同时结合平台丰富的原子能力,如文档解析、拆分、embedding、多轮改写等,让开发者能够更自由、高效地构建专属的 AI 服务,大大缩短了开发周期,降低了开发门槛。
-
- 时效性与准确性高:接入 DeepSeek 等能力后,支持联网搜索,突破了预训练数据的时间边界,能够获取最新信息,提供时效精准的智能问答服务。同时结合知识库和 RAG 能力,提升了回答的准确性,对于一些复杂的、需要多源知识支撑的问题,也能给出更合理、准确的答案。
想要使用的话就赶紧来吧
大模型知识引擎产品官网: 大模型知识引擎LKE 知识应用搭建 知识应用平台
大模型知识引擎原子能力接口文档: 大模型知识引擎-文档中心
大模型知识引擎×DeepSeek应用创建指南: 大模型知识引擎 DeepSeek应用创建指南
腾讯云DeepSeek API接入文档: 知识引擎原子能力 对话-API 文档


















 36
36

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











