






阅读文献《MulFS-CAP: Multimodal Fusion-supervised Cross-modality Alignment Perception for Unregistered Infrared-visible Image Fusion》
《MulFS-CAP:多模态融合监督跨模态对齐感知的未配准红外-可见光图像融合》
一、摘要
在这项研究中,提出了多模态融合监督跨模态对齐感知(MulFS-CAP),这是一种用于未配准红外可见图像单阶段融合的新框架。传统的两阶段方法依赖于显式配准算法来对源图像进行空间对齐,这通常会增加复杂性。相比之下,MulFS-CAP无缝地将隐式配准与融合结合在一起,简化了过程并增强了实际应用的适用性。MulFS-CAP利用共享的浅层特征编码器在单个阶段合并未配准的红外可见图像。为了解决特征级对齐和融合的具体要求,我们通过可学习的模态字典开发了一种一致的特征学习方法。该字典为单模态特征提供了补充信息,从而保持了单个特征和融合的多模态特征之间的一致性。因此,MulFSCAP有效地减少了模态方差对跨模态特征对齐的影响,允许同时进行配准和融合。此外,在MulFS-CAP中,我们提出了一种新的跨模态对齐方法,创建一个相关矩阵来详细描述源图像之间的像素关系。该矩阵有助于在红外和可见光图像之间对齐特征,进一步改进融合过程。以上设计使MulFS-CAP更轻量,有效和显式注册自由。来自不同数据集的实验结果证明了提出的方法的有效性及其优于最先进的两阶段方法。
二、网络结构解析
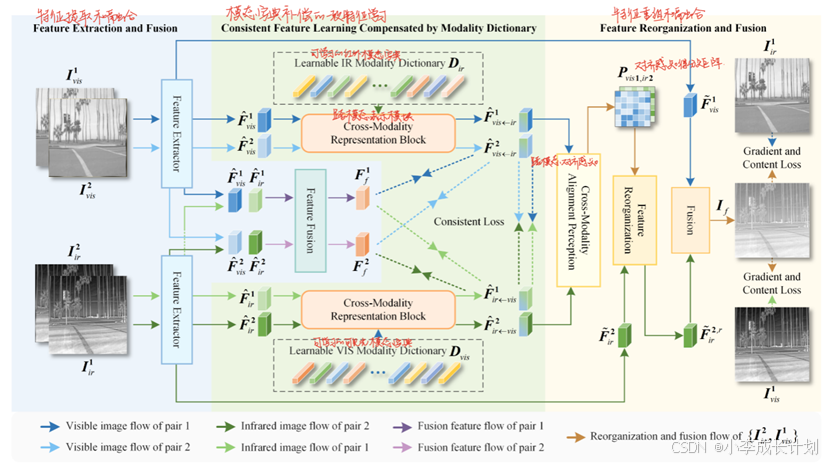
本文的总体网络结构如上图所示,由三部分组成,分别是Feature Extraction and Fusion(特征提取和融合,FEF)、Consistent Feature Learning Compensated by Modality Dictionary(模态字典补偿的一致特征学习,CFLC-MD)和Feature Reorganization and Fusion(特征重组和融合,FRF)。其中,输入部分,![]() 和
和![]() 、
、![]() 和
和![]() 为两对配准的红外-可见光图像对,但
为两对配准的红外-可见光图像对,但![]() 和
和![]() 、
、![]() 和
和![]() 为未配准的红外-可见光图像对。
为未配准的红外-可见光图像对。
| 模块 | 作用 |
| FEF | 从配准和未配准的图像对中提取特征,使用这些特征来指导未配准图像的对齐 |
| CFLC-MD | 通过接收模态字典提供的补偿信息来实现模态差异的去除,促进像素间跨模态对应关系的建立 |
| FRF | 对空间位置的特征进行重组和融合 |
- FEF网络结构解析
1)特征提取网络结构解析
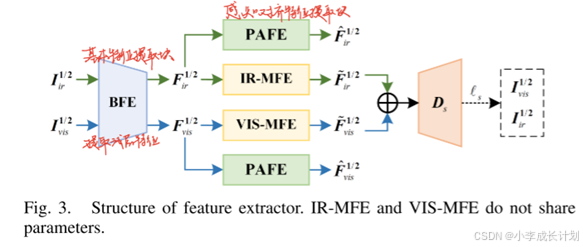
特征编码器由三个不同的特征提取块组成:基本特征提取(BFE)块,IR/VIS特征提取(IR/VISMFE)块和感知对齐特征提取(PAFE)块。
初始,将红外-可见光图像对![]() 和
和![]() 输入BFE,获取浅层特征,为了得到互补的深层特征,将这些浅层特征分别输入IR-MFE和VIS-MFE,得到输出特征
输入BFE,获取浅层特征,为了得到互补的深层特征,将这些浅层特征分别输入IR-MFE和VIS-MFE,得到输出特征![]() 和
和![]() ,这两个特征包含了各自模态特有的信息,用于后续的融合。为了保证融合结果的质量,引入了一致性损失,其损失函数的计算公式如下所示,这个损失旨在限制
,这两个特征包含了各自模态特有的信息,用于后续的融合。为了保证融合结果的质量,引入了一致性损失,其损失函数的计算公式如下所示,这个损失旨在限制![]() 和
和![]() ,促使其生成更好的深层特征。
,促使其生成更好的深层特征。
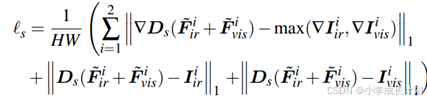
在提取深层特征的同时,还使用了共享参数的感知对齐特征提取模块,分别从红外和可见光特征中提取![]() 和
和![]() ,共享参数的设计确保了不同模态特征学习的一致性,避免了独立编码器可能带来的特征分布差异。
,共享参数的设计确保了不同模态特征学习的一致性,避免了独立编码器可能带来的特征分布差异。![]() 和
和![]() 随后被导向两个独立的流:特征融合(FF)流和CFLC-MD流。
随后被导向两个独立的流:特征融合(FF)流和CFLC-MD流。
2)特征融合网络结构解析
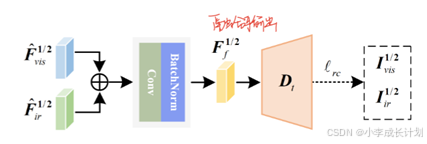
特征融合部分的网络结构图如上图所示,首先对特征![]() 和
和![]() 进行元素加法并将其结果馈送到特征提取块中,该块包括一个核大小为3×3的卷积层,步长为1,以及一个批归一化层,生成融合结果
进行元素加法并将其结果馈送到特征提取块中,该块包括一个核大小为3×3的卷积层,步长为1,以及一个批归一化层,生成融合结果![]() ,为了保证融合结果的质量,引入以下损失函数来约束:
,为了保证融合结果的质量,引入以下损失函数来约束:
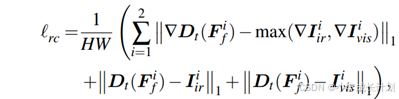
至此,特征提取和融合均已完成。
2、CFLC-MD网络结构解析
由于红外和可见光图像固有的模态差异,在像素级直接对准这两种变形图像是一项重大挑战,因此本文提出使用一个融合特征来监督单模态的输入源图像的特征提取过程,但由于单幅图像缺乏多模态信息,在融合特征监督下实现这种对齐同样具有挑战性,因此本文开发了一种名为CFLC-MD的方法,其网络结构如下图所示,该方法使用模态字典来补偿特定模态信息的缺失,它的目的是尽可能地保留每个特定模态的独特特征。同时保证从一种模态中提取的特征包含了从另一种模态中提取的相关信息。
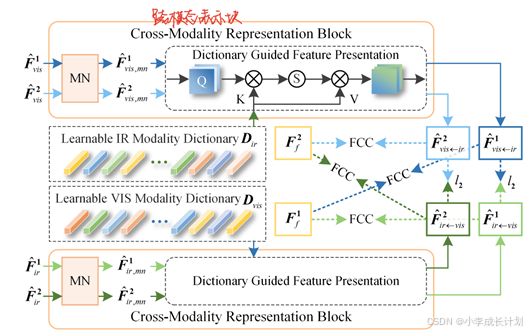
如上图所示,CFLC-MD由两个主要部分组成:跨模态表示块(CMRB)和可学习的IR/VIS模态字典。首先将从上一步特征提取的过程中提取到的特征![]() 和
和![]() 输入到MN层中,MN层起到一个归一化的作用,减少模态之间的差异,然后通过对这些特征的线性映射得到Q,记为
输入到MN层中,MN层起到一个归一化的作用,减少模态之间的差异,然后通过对这些特征的线性映射得到Q,记为![]() ,再通过对两个模态字典的线性映射得到
,再通过对两个模态字典的线性映射得到![]() 和
和![]() ,如下公式所示,通过模态字典的补偿后得到
,如下公式所示,通过模态字典的补偿后得到![]() ,其中
,其中![]() 表示将vis/ ir信息注入到ir /vis模态中,这一步消除了两者之间的模态差异。
表示将vis/ ir信息注入到ir /vis模态中,这一步消除了两者之间的模态差异。
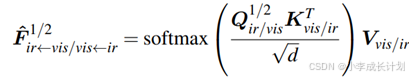
![]() 包含特定于模态和模态共享的信息,因此使用
包含特定于模态和模态共享的信息,因此使用![]() 来指导模态字典的学习过程可以确保它们提供额外的信息来弥补单模态特征的局限性,为了实现这一目标,通过字典增强后的特征应该与融合特征对齐,为了确保两者之间的一致性,使用特征级互关(FCC)来测量两者之间的相关性,因此根据以下损失函数来学习模态字典
来指导模态字典的学习过程可以确保它们提供额外的信息来弥补单模态特征的局限性,为了实现这一目标,通过字典增强后的特征应该与融合特征对齐,为了确保两者之间的一致性,使用特征级互关(FCC)来测量两者之间的相关性,因此根据以下损失函数来学习模态字典
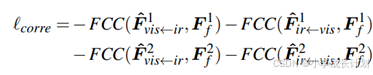
其中相关性FCC的计算公式如下:
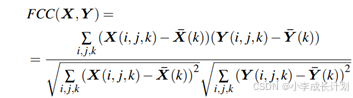
X![]() (k)和X
(k)和X![]() (k)分别表示X和Y的第k个通道的平均值。
(k)分别表示X和Y的第k个通道的平均值。
由于缺失的特定模态信息已经被模态字典补偿了,因此![]() 和
和![]() 之间应该保持一致性,因此引入如下公式所示的一致性损失,进一步优化模态字典:
之间应该保持一致性,因此引入如下公式所示的一致性损失,进一步优化模态字典:
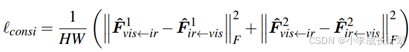
用于构造模态字典的总的损失函数定义为:
![]()
至此,模态字典补偿的特征学习均已完成,这一步骤有效去除了两种模态之间的差异性。
3、FRF网络结构解析
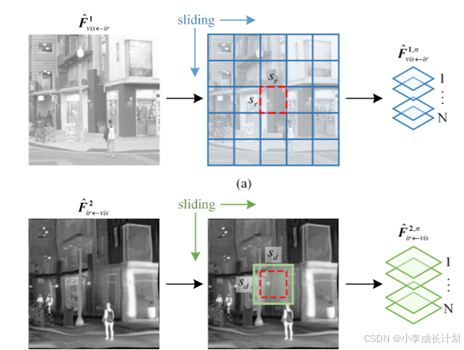
1)感知区域划分
在消除了![]() 和
和![]() 之间的模态差异后,使用这些补偿特征对作为输入特征执行逐像素对齐可能会提高对齐精度,然而直接再整个
之间的模态差异后,使用这些补偿特征对作为输入特征执行逐像素对齐可能会提高对齐精度,然而直接再整个![]() 中搜索相应的像素特征的计算成本非常高,在实践中,红外和可见光图像之间的空间偏差通常是局部化的,允许在局部区域内更有效地进行像素搜索。
中搜索相应的像素特征的计算成本非常高,在实践中,红外和可见光图像之间的空间偏差通常是局部化的,允许在局部区域内更有效地进行像素搜索。
在本文中,将![]() 指定为参考特征,将
指定为参考特征,将![]() 指定为具有偏移量的特征。本文的目标是使用
指定为具有偏移量的特征。本文的目标是使用![]() 和
和![]() 来学习对齐关系矩阵,当该矩阵应用于
来学习对齐关系矩阵,当该矩阵应用于![]() 时,结果在空间上与
时,结果在空间上与![]() 保持一致。如下图所示,将
保持一致。如下图所示,将![]() 和
和![]() 分割为N个区域块,其中,在
分割为N个区域块,其中,在![]() 中分割的块的大小大于
中分割的块的大小大于![]() 中的,确保
中的,确保![]() 中定义的区域包含
中定义的区域包含![]() 中相应区域的所有像素。
中相应区域的所有像素。
2)跨模态对齐感知
在对特征图进行分割后,可以直接在分割后的区域内进行像素级的感知对齐,但仅以来特征图中单个像素提供的数据来建立像素间的对应关系是非常有限的,单独使用单像素信息难以准确区分不同像素,导致像素级特征匹配的精度较低,因此本文提出了一种多头跨尺度聚合块(MHCASAB),通过整合像素局部区域的多尺度信息,增强每个像素的特征表达能力,提升像素级特征匹配的效果。
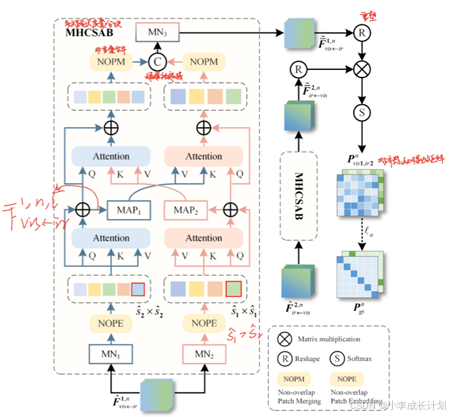
其网络结构如上图所示,首先将局部区域特征馈送到两个具有相同结构和不同参数的MN层,特征图被分割成非重叠的补丁,每个补丁包含一组像素,这些补丁被矢量化形成特征![]() ,包含一系列特征向量,对
,包含一系列特征向量,对![]() 应用线性投影,生成查询(Q)、键(K)和值(V),如下公式所示,通过注意力计算得到输出:
应用线性投影,生成查询(Q)、键(K)和值(V),如下公式所示,通过注意力计算得到输出:
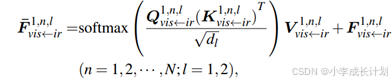
为了增强不同尺度之间的信息交互,引入跨尺度信息交互,使用![]() 的输出作为查询(Q),从
的输出作为查询(Q),从![]() 中提取键(K)和值(V),如下公式计算:
中提取键(K)和值(V),如下公式计算:
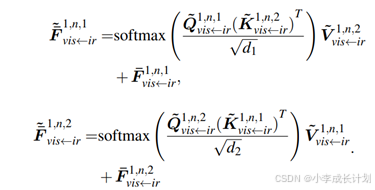
将![]() 和
和![]() 进行非重叠补丁合并,并进行通道级连接,拼接后的特征通过MN层处理,生成最终特征
进行非重叠补丁合并,并进行通道级连接,拼接后的特征通过MN层处理,生成最终特征![]() ,同样将
,同样将![]() 输入到MHCSAB中得到最终特征
输入到MHCSAB中得到最终特征![]() 。
。
接下来,通过如下所示公式推导出对齐感知矩阵:
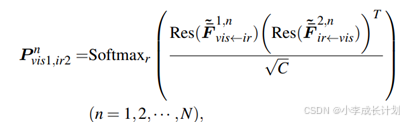
其中Res表示重塑,![]() 用于测量
用于测量![]() 中第i个像素与
中第i个像素与![]() 中第j个像素之间的对齐感知得分,分数越高,表示这两个像素之间匹配的置信度越高。如上文中所提到,将这个矩阵应用到
中第j个像素之间的对齐感知得分,分数越高,表示这两个像素之间匹配的置信度越高。如上文中所提到,将这个矩阵应用到![]() 时,结果在空间上与
时,结果在空间上与![]() 保持一致。
保持一致。
3)特征重组与融合
特征重组的目标是将红外图像的特征与可见光图像的特征在空间上重新对齐,具体程序如下公式的所示:
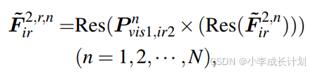
重组后两组特征在各自的空间位置上对齐,接下来就能够产生融合的特征,融合过程的网络结构图如下图所示,对齐后的特征输入到特征提取块,该块由一个卷积层组成,其核大小为3×3,步长为1,然后是一个批处理归一化层和一个ReLU激活函数层,它们共同重建最终的融合结果。
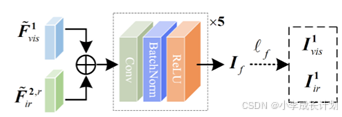
为了保证融合的有效性,该过程同时使用梯度一致性损失和内容一致性损失作为融合结果的约束,如下公式所示:
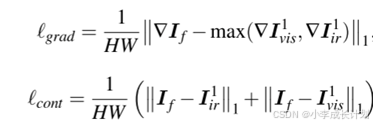
三、实验
1、数据集
RoadScene、LLVIP、MSIFT。从RoadScene数据集中,使用200对IR-VIS图像对进行训练,并留出21对进行测试。从LLVIP数据集中,使用201对IR-VIS图像对进行训练,并随机选择20对进行测试。最后,从MSIFT数据集中,使用460对NIR-VIS(近红外可见)图像对进行训练,保留17对用于测试。
2、与最先进方法的比较
1)直接融合未配准图像的性能比较
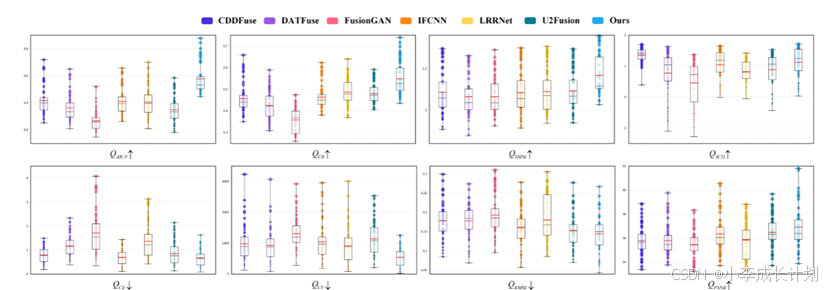
使用未配准的图像,将本文的方法与其它几种方法,包括CDDFuse、LRRNet、DATFuse、U2Fusion、IFCNN和FusionGAN进行了性能比较,融合结果如下第一幅图所示。如图中第三列的梯度差图所示,在输入图像中可以看到明显的畸变和位移。对融合结果中放大区域的仔细检查表明,比较方法倾向于保留空间扭曲并引入伪影,因为它们不是专门为未配准的图像设计的。相比之下,本文提出的方法有效地纠正了这些扭曲并最大限度地减少了伪影,从而产生了更具视觉吸引力的融合结果。为了进一步确定该方法的优越性,本文使用8个常用的评价指标对融合结果进行了评价。为了客观地展示不同方法的性能,本文为所有指标创建了箱形图,如下第二幅图所示。这些结果表明,本文的方法始终达到最大或第二大平均值,表明其优于所比较的方法。此外,第二幅图的结果也突出了本文方法的稳定性,与其他方法相比,本文的下边界值更高。

2)与配准融合的方法的比较
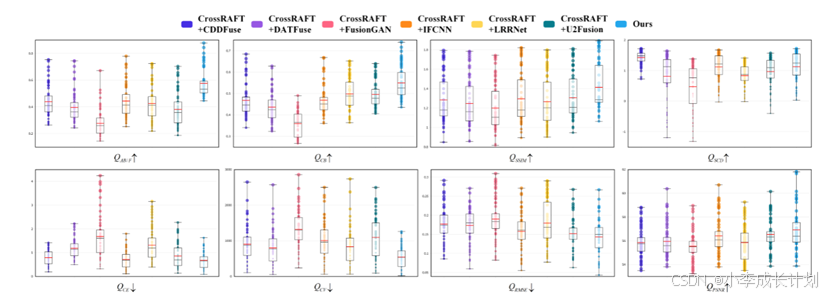
为了证明本文提出的方法与传统的“配准融合”方法相比的有效性,使用高性能的CrossRAFT进行图像配准。随后,采用CDDFuse、LRRNet、DATFuse、U2Fusion、IFCNN和FusionGAn等标准融合方法进行红外和可见光图像融合。如下第一幅图描绘了使用这些不同方法的融合结果的视觉效果。这些结果清楚地表明,CrossRAFT配准算法的引入有效地提高了所有融合结果的质量。此外,详细的对比表明,本文提出的方法不仅保留了源图像的详细信息,而且取得了较好的特征对齐效果。此外,本文通过箱形图展示了每个测试样本对的定量性能。如下第二幅图所示,“配准融合”方法的箱形图显示,评价分数在不同测试样本对之间的分布不规则且较为分散。这表明“配准融合”方法在不同的测试样本中表现出更大的性能可变性。这种可变性可归因于配准方法泛化能力不稳定以及融合方法对配准误差的敏感性。相比之下,本文提出的方法在处理不同范围的测试样本时表现出更高的性能稳定性。综上所述,虽然配准方法可以纠正一些失真并提高融合质量,但这些融合算法对多模态配准误差的普遍敏感性限制了模型性能的进一步提高。

3)与未配准图像融合方法的比较
最近的方法,如SemLA, SuperFusion, UMF-CMGR, MURF, IVFWSR和RFVIF已经开发出来,以解决融合未配准IR-VIS图像的挑战。这些方法通常以两阶段范式将配准和融合任务结合起来,称为“配准-联合-融合”方法。本文提出的方法在定性和定量上都与这些方法进行了比较。如下第一幅图为直接融合未配准源图像时不同方法的定性结果。为了直观地分析定量结果,使用如下第二幅图所示的箱形图来评估不同方法的性能。第二幅图的结果显示,本文提出的方法在所有评估指标中表现更好,表明其优于比较的方法。此外,图中还显示,大多数比较方法在QAB/F和QCB指标上表现出稳定的性能。然而,这些方法对QSSIM的评估分数差异很大,而本文提出的方法保持一致的性能。
4)复杂度比较
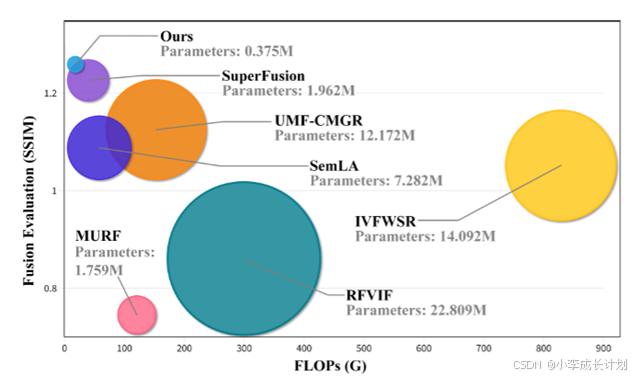
本文提出的方法具有开创性,是第一个将一阶段方法应用于未配准图像融合的方法。与现有方法相比,这种方法的一个显著优点是它的模型更轻量。为了说明这一点,本文比较了不同方法的训练参数和FLOPs。如下图所示,对于一对256×256图像,本文提出的方法具有明显的优势,具有最少的参数数量和FLOPs,同时仍然获得最佳的融合性能。这突出了本文提出的方法设计理念的创新性、实用性和优越性。
四、结论
本文对未配准红外图像与可见光图像的融合进行了研究,提出了一种新的一阶段融合方法。为了解决配准和融合中的特征不兼容问题,本文提出了一种模态字典补偿的一致性特征学习方法。该方法补偿了特定模态信息的丢失,解决了由于红外和可见光图像之间的模态差异而导致的特征不一致,并保留了互补信息。它支持在统一框架内的单个阶段中并发执行两个不同的任务。此外,为了在单个像素水平上对红外和可见光图像的特征进行对齐,我们提出了一种跨模态对齐感知方法。该方法在局部区域内建立了不同像素之间的关系,便于配准结果的重建。因此,它有效地纠正了细节特征中的畸变及其对融合结果的影响。大量的实验证明了本文的方法比现有方法的有效性和优越性。本文的方法主要用于融合红外和可见光图像。然而,当应用于其他类型的图像融合时,它的性能可能会下降,例如多焦点图像融合,并且由于训练集和测试集之间的域转移,它也可能受到性能下降的影响。在未来,将扩展研究,包括在一个阶段和统一的框架内融合各种类型的未配准源图像,如多焦点图像、医学图像和遥感图像,并进行领域概化。

















 63
63

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









