







 根据内核中的值,我们得到不同的结果。因此,为了优化计算,我们可以利用现代处理器的多核架构,将图像拆分为条纹,并并行对每个条纹进行卷积。例如,如果您的处理器有 4 个线程,则设置或设置应与默认相同,它将使用所有可用的处理器线程,但仅在两个线程上拆分工作负载。在这里,我们将一个较小的矩阵(称为内核)滑动到图像上,像素值和内核中相应值的乘积之和为我们提供了输出中特定像素的值(称为。在本教程中,我们将实现最简单的函数形式,该函数采用灰度图像(1 个通道)和奇数长度的方形内核并生成输出图像。该操作不会就地执行。
根据内核中的值,我们得到不同的结果。因此,为了优化计算,我们可以利用现代处理器的多核架构,将图像拆分为条纹,并并行对每个条纹进行卷积。例如,如果您的处理器有 4 个线程,则设置或设置应与默认相同,它将使用所有可用的处理器线程,但仅在两个线程上拆分工作负载。在这里,我们将一个较小的矩阵(称为内核)滑动到图像上,像素值和内核中相应值的乘积之和为我们提供了输出中特定像素的值(称为。在本教程中,我们将实现最简单的函数形式,该函数采用灰度图像(1 个通道)和奇数长度的方形内核并生成输出图像。该操作不会就地执行。
目标
本教程的目的是演示如何使用 OpenCV 框架轻松并行化代码。为了说明这个概念,我们将编写一个程序来对图像执行卷积运算。完整的教程代码在这里。parallel_for_
前提
并行框架
第一个前提条件是使用并行框架构建 OpenCV。在 OpenCV 4.5 中,以下并行框架按此顺序提供:
- 英特尔线程构建模块(第三方库,应显式启用)
- OpenMP(集成到编译器,应显式启用)
- APPLE GCD(系统范围,自动使用(仅限 APPLE))
- Windows RT 并发(系统范围,自动使用(仅限 Windows RT))
- Windows 并发(运行时的一部分,自动使用(仅限 Windows - MSVC++ >= 10))
- Pthreads(线程)
如您所见,OpenCV 库中可以使用多个并行框架。一些并行库是第三方库,必须在构建之前在 CMake 中显式启用,而其他并行库则在平台中自动可用(例如 APPLE GCD)。
竞争条件
当多个线程尝试写入或同时读取和写入特定内存位置时,会发生争用条件。基于此,我们可以将算法大致分为两类:-
- 只有单个线程将数据写入特定内存位置的算法。
- 例如,在卷积中,即使多个线程可能在特定时间从一个像素读取,也只有一个线程写入特定像素。
- 多个线程可以写入单个内存位置的算法。
- 查找轮廓、特征等。此类算法可能要求每个线程同时向全局变量添加数据。例如,在检测特征时,每个线程会将其图像各自部分的特征添加到公共向量中,从而创建争用条件。
卷积
我们将使用执行卷积的示例来演示如何使用 并行化计算。这是一个不会导致竞争条件的算法示例。parallel_for_
理论
卷积是一种简单的数学运算,广泛用于图像处理。在这里,我们将一个较小的矩阵(称为内核)滑动到图像上,像素值和内核中相应值的乘积之和为我们提供了输出中特定像素的值(称为内核的锚点)。根据内核中的值,我们得到不同的结果。在下面的示例中,我们使用一个 3x3 内核(锚定在其中心)并在 5x5 矩阵上进行卷积以生成 3x3 矩阵。可以通过用合适的值填充输入来改变输出的大小。
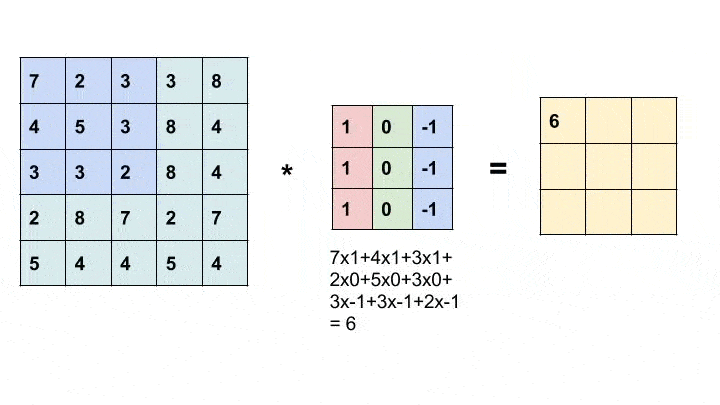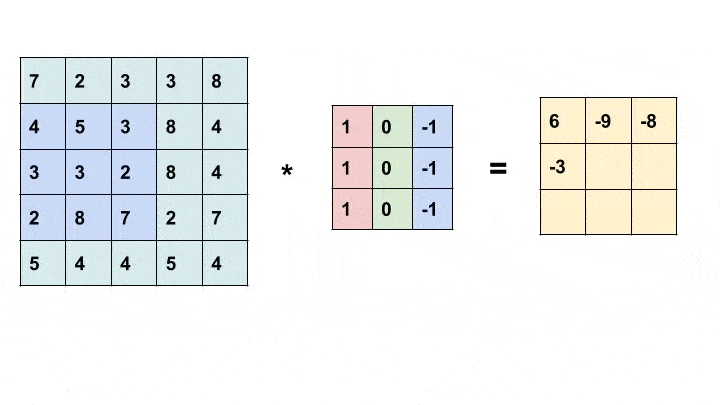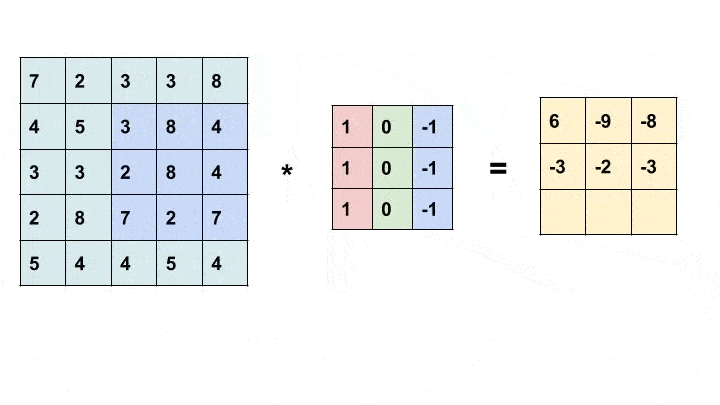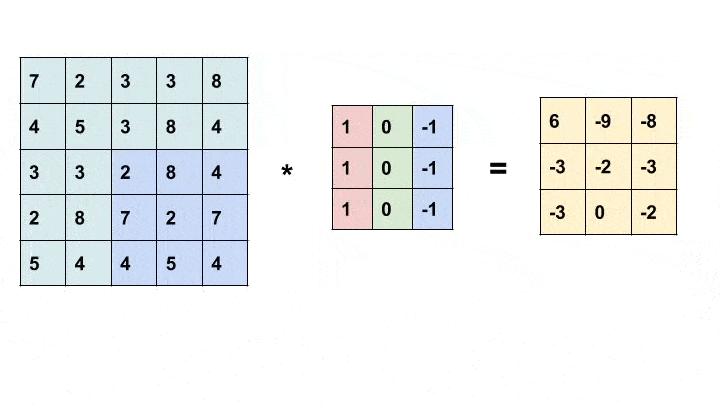
卷积动画
有关不同内核及其作用的更多信息,请查看此处
在本教程中,我们将实现最简单的函数形式,该函数采用灰度图像(1 个通道)和奇数长度的方形内核并生成输出图像。该操作不会就地执行。
-
注意
我们可以临时存储一些相关的像素,以确保我们在卷积期间使用原始值,然后就地进行。但是,本教程的目的是介绍parallel_for_函数,就地实现可能过于复杂。
伪代码
InputImage src, OutputImage dst, kernel(size n)
makeborder(src, n/2)
for each pixel (i, j) strictly inside borders, do:
{
value := 0
for k := -n/2 to n/2, do:
for l := -n/2 to n/2, do:
value += kernel[n/2 + k][n/2 + l]*src[i + k][j + l]
dst[i][j] := value
}
对于 n 大小的内核,我们将添加一个大小为 n/2 的边框来处理边缘情况。然后,我们运行两个循环来沿内核移动,并将乘积相加
实现
顺序实现
void conv_seq(Mat src, Mat &dst, Mat 内核)
{
int rows = src.rows, cols = src.cols;
dst = Mat(rows, cols, src.type());
照顾边缘值
make border = kernel.rows / 2;
int sz = kernel.rows / 2;
copyMakeBorder(src, src, sz, sz, sz, sz, BORDER_REPLICATE);
for (int i = 0; i <行; i++)
{
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









