






HashMap 是以键值对的形式存放的
HashMap 的父类 AbstractMap 已经实现了Map接口 但是源码中又单独实现了Map接口 这是一个多余的实现
主数组 最大有16个 (最大值为 1 << 30 可以不考虑基本用不了怎么大 但是当自己调用HashMap构造如果传入比这个还大的值时会自动赋值为 1<<30)
主数组的扩容边界值为 加载因子 0.75 *主数组 长度 而扩容后的主数组长度为 2^n
初始容量和负载因子也可以自己设定的。 使用的是位运算进行扩容,因为用乘法会影响CPU的性能,计算机不支持乘法运算,最终都会转化为加法运算。
HashMap扩容主要是给数组扩容的,因为数组长度不可变,而链表是可变长度的。从HashMap的源码中可以看到HashMap在扩容时选择了位运算,向集合中添加元素时,会使用(n - 1) & hash的计算方法来得出该元素在集合中的位置。只有当对应位置的数据都为1时,运算结果也为1,当HashMap的容量是2的n次幂时,(n-1)的2进制也就是1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞 如果不满足(n-1)者哈希算法出现哈希碰撞的概率大大增加
HashMap导致死循环
HashMap是一个线程不安全的容器,在最坏的情况下,所有元素都定位到同一个位置,形成一个长长的链表,这样get一个值时,最坏情况需要遍历所有节点,性能变成了O(n)。
JDK1.7中HashMap采用头插法拉链表,所谓头插法,即在每次都在链表头部(即桶中)插入最后添加的数据。
死循环问题只会出现在多线程的情况下。
假设在原来的链表中,A节点指向了B节点。
在线程1进行扩容时,由于使用了头插法,链表中B节点指向了A节点。
在线程2进行扩容时,由于使用了头插法,链表中A节点又指向了B节点。
在线程n进行扩容时,…
这就容易出现问题了。。在并发扩容结束后,可能导致A节点指向了B节点,B节点指向了A节点,链表中便有了环!!!
导致的结果:CPU占用率100%
所以1.8以后使用红黑树
首先讲一下二叉查找树:
1.左子树上所有结点的值均小于或等于它的根结点的值。
2.右子树上所有结点的值均大于或等于它的根结点的值。
3.左、右子树也分别为二叉排序树。

如果要查找10。先看根节点9,由于10 > 9,因此查看右孩子13;由于10 < 13,因此查看左孩子11;由于10 < 11,因此查看左孩子10,发现10正是要查找的节点;这种方式查找最大的次数等于二叉查找树的高度。 复杂度为O(log n),但是二叉查找树也有他的缺点,如果二叉树有如下的三个节点: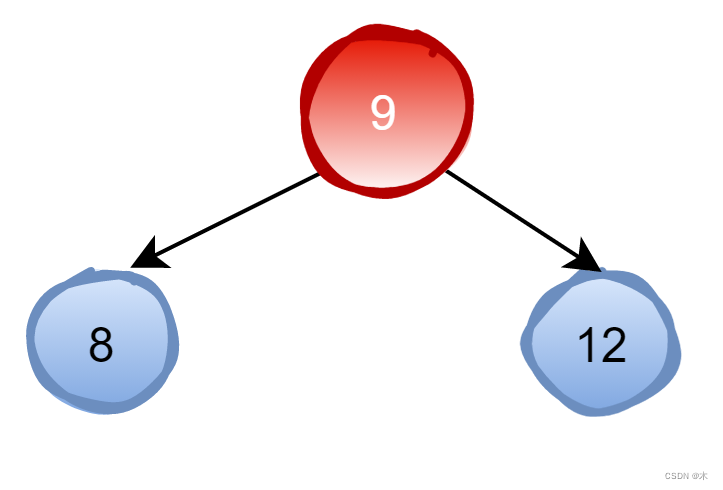
当插入7,6,5,4这四个节点时:

随着树的深度增加,那么查找的效率就变得非常差了,变成了O(n),就不具有二叉查找树的优点了。
那么红黑树就诞生了,红黑树是一种自平衡的二叉查找树。
3.红黑树的特性
1.节点是红色或黑色;
2.根节点是黑色;
3.每个叶子节点都是黑色的空节点(NIL节点);
4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点);
5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点;
6.每次新插入的节点都必须是红色。

红黑树从根节点到叶子节点的最长路径不会超过最短路径的两倍。但是红黑树有时候在插入和删除过程中会破坏自己的规则,比如插入节点26

由于父节点27是红色节点,因此这种情况打破了红黑树的规则4(每个红色节点的两个子节点都是黑色),必须进行调整,使之重新符合红黑树的规则
Map.put(K,V)实现原理
首先 将KV封装到 Entry 对象当中(节点)
Entry对象 (K值,V值,哈希码,下一个元素的地址)
调用 HashCode 方法算出哈希码(hash值)
哈希码经过哈希算法将转换成下标
这个时候下标如果没有数据就把封装的 Entry 对象添加到这个主数组的位置 如果下标对应的位置有数据会产生哈希碰撞 会拿着K的值和链表上的值进行 equals 如果有返回true的者会覆盖如果都返回false 会根据JDB版本加入链表
链表存储方式(七上八下)
存储方式 看JDK 1.7的以前的是加入到链表的头部 1.8以后加入到链表的尾部
如果链表数据大于8的时候链表会改成红黑树的存储方式
Map.get(K)实现原理
先调用K的 HashCode 方法得出哈希值
哈希算法根据哈希值算出数组下标
通过数组下标再快速定位主数组上的位置
如果这个位置上什么也没有返回null
如果有单向链表 会拿着K值对每一个节点上的K进行equals 都返回false结果返回null 其中一个返回true 那么返回该节点的V值
HashMap增删快 查询快的原因
增删是在链表上完成的 查询只需要找的对象的链表 只扫描一部分
装填因子,负载因子,加载|月子 为什么是0.75:
装填因子设置为1:空间利用率得到了很大的满足,很容易碰撞,产生链表->查询效率低
装填因子设置为0.5:碰撞的概率低,扩容,产生链表的几率低,查询效率高,空间利用率太低
0.5 - 1 取中间值: 0.75
主数组的长度为什么必须为 2~n:
HashMap的主数组长度通常为2~n,这是为了提高数据存储的效率、方便扩容以及减少内存浪费
- 减少冲突:如果主数组的长度为2~n,那么每个桶可以容纳2^n个键值对。当多个键的哈希码计算出的索引位置相同,即发生哈希冲突时,它们会被存储在不同的桶中。这样可以最大限度地减少冲突,提高数据存储的效率。
- 便于扩容:当HashMap中的元素数量达到主数组长度的阈值时,HashMap会进行扩容。扩容时,需要创建一个新的主数组,其长度通常是原来的两倍。如果主数组的长度为2~n,那么每次扩容时,新的主数组长度只需简单地乘以2即可。这样可以方便地实现扩容操作,提高HashMap的性能。
- 减少内存浪费:如果主数组的长度为2~n,那么每个桶可以容纳2^n个键值对。当某个桶中的键值对数量少于这个值时,会存在一定的内存浪费。但是,这种浪费是可接受的,因为HashMap的设计目标是实现高效的查询、插入和删除操作,而不是最大限度地利用内存。















 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









