







本文使用Keras实现双层LSTM进行风暴预测,是一个二分类任务。
模型构建思路
为什么使用 LSTM?
LSTM(长短期记忆网络)是一种特殊的 RNN(循环神经网络),它能够有效地处理长期依赖问题。相比传统的 RNN,LSTM 通过引入门控机制来控制信息的流动,能够保持较长时间范围内的记忆,并防止梯度消失或爆炸的问题。在处理时间序列或语言数据时,LSTM 可以学习序列中的长期依赖关系。
第一层 LSTM 输出整个序列,以便提供丰富的上下文信息给下一层。
第二层 LSTM 从中提取更高层次的特征,并进一步压缩信息。
为什么堆叠多个 LSTM 层?
多层 LSTM 结构通常能帮助模型学习更加复杂的模式。每一层 LSTM 都能提取更高层次的特征,堆叠的 LSTM 层可以提升模型的表达能力,捕获更加复杂的时间序列特征。return_sequences=True 让第一层输出序列以便传递给第二层,而第二层仅返回最后一个时间步的结果来与全连接层(Dense)进行交互。
为什么使用 ReLU 和 Sigmoid 激活函数?
ReLU 在全连接层中使用能够帮助加速训练,避免梯度消失问题,同时增强模型的非线性表达能力。
Sigmoid 激活函数用于输出层,用于二分类任务,输出一个概率值,便于计算交叉熵损失。
优点
适用于序列数据:LSTM 结构能够处理并理解时间序列数据中的长期依赖关系,适用于许多任务,如自然语言处理、股票预测、天气预测等。
深层网络:堆叠的 LSTM 层让网络具备了更强的学习能力,能够从原始数据中提取复杂的特征。
激活函数的选择:tanh 激活函数避免了传统 RNN 中的梯度消失问题,ReLU 加速训练过程,sigmoid 激活函数为二分类任务提供了可靠的概率输出。
灵活性和可扩展性:该模型设计相对简单,可以根据具体任务需求调整 LSTM 层数、神经单元数、激活函数等。比如可以尝试添加更多的 LSTM 层或增加神经元数量来提升模型性能。
- 本次的建模定义了一个适合处理时间序列数据的 双层 LSTM 网络,最终通过全连接层进行分类。设计的核心思想是通过 LSTM 层提取时间序列中的时序依赖特征,利用全连接层进一步映射为输出结果。这样设计的好处是能够捕获数据中的长期依赖关系,并且具有良好的可扩展性,适合二分类任务。
源码
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import Adam
import math
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
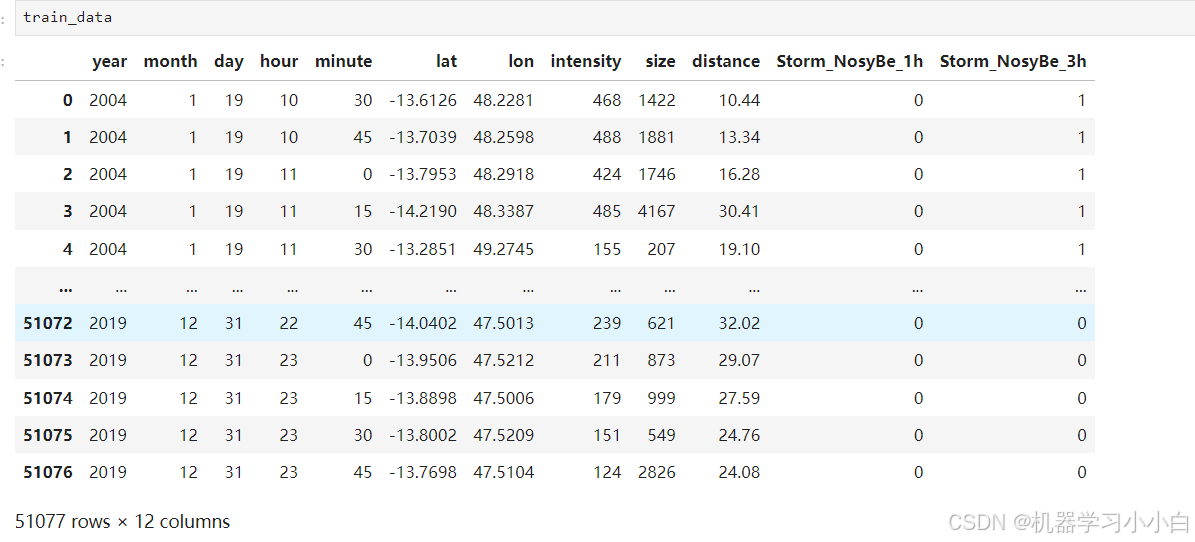
以上就是数据集,首先要将其转换为时间序列。
train_data['datetime'] = pd.to_datetime(train_data[['year', 'month', 'day', 'hour', 'minute']])
# 将新创建的 'datetime' 列设为索引
train_data.set_index('datetime', inplace=True)
test_data['datetime'] = pd.to_datetime(test_data[['year', 'month', 'day', 'hour', 'minute']])
# 将新创建的 'datetime' 列设为索引
test_data.set_index('datetime', inplace=True)
train_data.head()
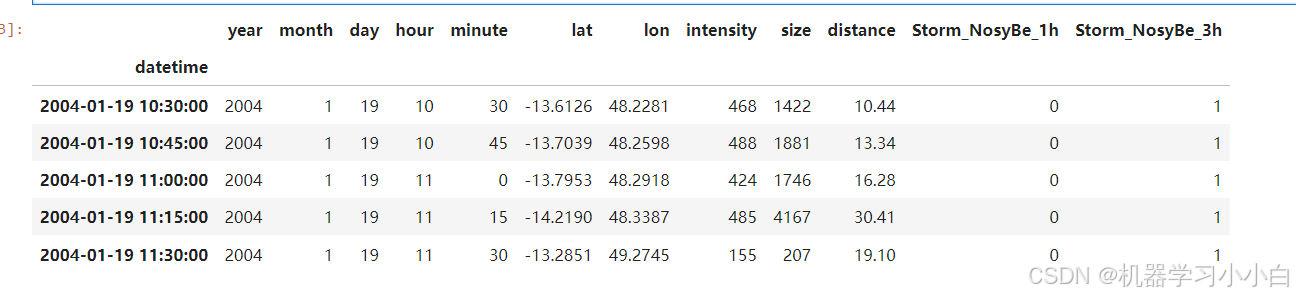
可以看到,数据已经转换为时间序列,本次任务是预测最后两列,一小时后是否有风暴和三小时后是否有风暴。
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import LSTM, Dense
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 提取特征和标签
train_data2 = train_data.drop(columns=['year','month','day','hour','minute'])
X = train_data2[['lat', 'lon', 'intensity', 'size', 'distance']].values
y_1h = train_data2['Storm_NosyBe_1h'].values
y_3h = train_data2['Storm_NosyBe_3h'].values
# 标准化输入数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 调整输入形状以适配 LSTM
X_seq = X_scaled.reshape(X_scaled.shape[0], 1, X_scaled.shape[1])
# 划分训练集和测试集
X_train, X_test, y_train_1h, y_test_1h = train_test_split(X_seq, y_1h, test_size=0.2, random_state=42)
X_train, X_test, y_train_3h, y_test_3h = train_test_split(X_seq, y_3h, test_size=0.2, random_state=42)
# 构建 LSTM 模型的函数
def build_lstm_model(input_shape):
model = Sequential()
model.add(LSTM(64, return_sequences=True, activation='tanh', input_shape=input_shape))
model.add(LSTM(32, return_sequences=False, activation='tanh'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 使用 sigmoid 激活函数进行二分类
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
# 创建并训练模型预测 1h 风暴
model_1h = build_lstm_model(X_train.shape[1:])
history_1h = model_1h.fit(X_train, y_train_1h, epochs=10, batch_size=32, validation_data=(X_test, y_test_1h))
# 创建并训练模型预测 3h 风暴
model_3h = build_lstm_model(X_train.shape[1:])
history_3h = model_3h.fit(X_train, y_train_3h, epochs=10, batch_size=32, validation_data=(X_test, y_test_3h))
# 在测试集上预测
y_pred_1h = model_1h.predict(X_test)
y_pred_1h = (y_pred_1h > 0.5).astype(int) # 将输出转为二进制 0 或 1
y_pred_3h = model_3h.predict(X_test)
y_pred_3h = (y_pred_3h > 0.5).astype(int) # 将输出转为二进制 0 或 1
# 评估模型性能
accuracy_1h = accuracy_score(y_test_1h, y_pred_1h)
accuracy_3h = accuracy_score(y_test_3h, y_pred_3h)
print(f"1 Hour Storm Prediction Accuracy: {accuracy_1h * 100:.2f}%")
print(f"3 Hour Storm Prediction Accuracy: {accuracy_3h * 100:.2f}%")
# 绘制训练和验证的损失图
def plot_loss(history, title):
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title(title)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# 绘制 1h 和 3h 模型的损失图
plot_loss(history_1h, '1 Hour Storm Prediction Loss')
plot_loss(history_3h, '3 Hour Storm Prediction Loss')

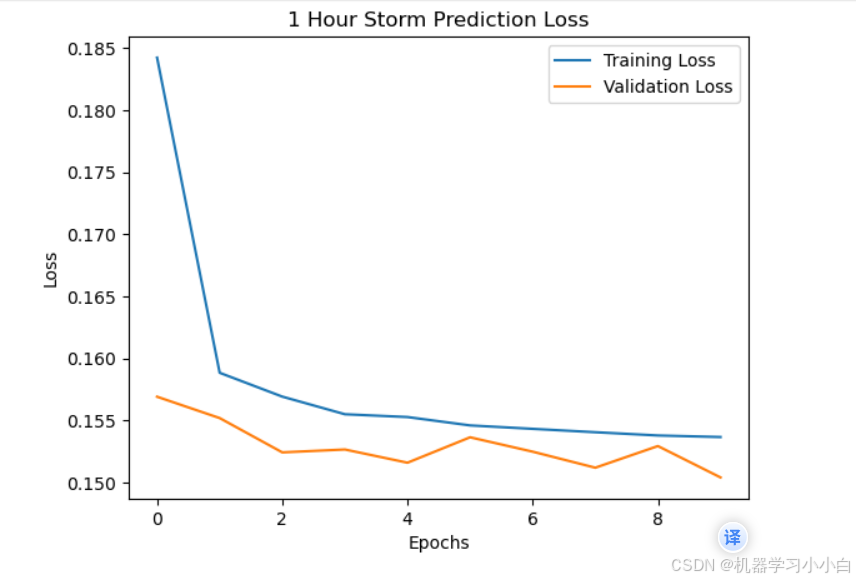
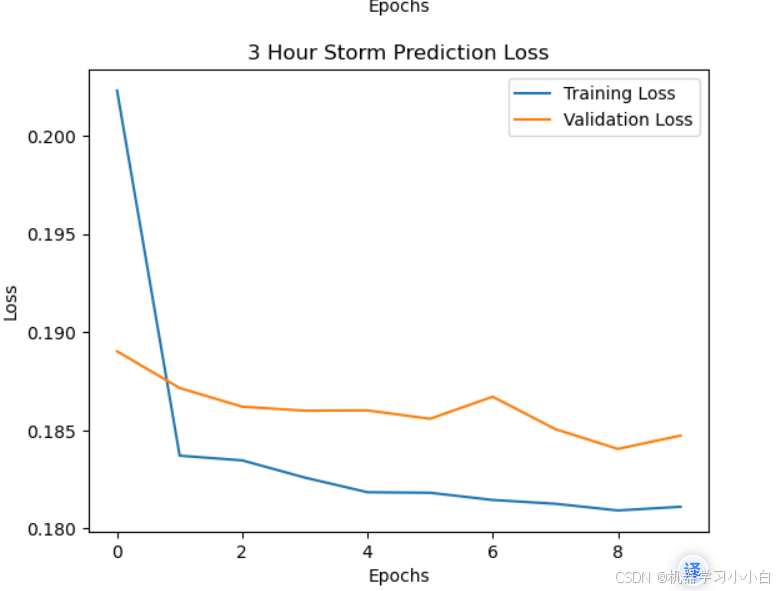
根据输出结果可以看到,效果还行,接下来评估一下。
from sklearn.metrics import roc_auc_score, accuracy_score
# 在测试集上预测
y_pred_1h = model_1h.predict(X_test)
y_pred_1h_binary = (y_pred_1h > 0.5).astype(int) # 将输出转为二进制 0 或 1
y_pred_3h = model_3h.predict(X_test)
y_pred_3h_binary = (y_pred_3h > 0.5).astype(int) # 将输出转为二进制 0 或 1
# 1h 风暴评估
accuracy_1h = accuracy_score(y_test_1h, y_pred_1h_binary)
auc_1h = roc_auc_score(y_test_1h, y_pred_1h)
# 3h 风暴评估
accuracy_3h = accuracy_score(y_test_3h, y_pred_3h_binary)
auc_3h = roc_auc_score(y_test_3h, y_pred_3h)
# 打印评估指标
print(f"1 Hour Storm Prediction Metrics:")
print(f" - Accuracy: {accuracy_1h * 100:.2f}%")
print(f" - AUC: {auc_1h:.2f}")
print(f"\n3 Hour Storm Prediction Metrics:")
print(f" - Accuracy: {accuracy_3h * 100:.2f}%")
print(f" - AUC: {auc_3h:.2f}")

可以看出1小时预测模型性能优秀,适合实际部署,尤其是短时风暴预警的场景。3小时预测模型虽表现良好,但其AUC下降反映出对更长时间预测的适应能力有限。
本次分享到这里就结束了,数据集大家可以自行下载尝试,感谢观看



















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











