







前言:
**在PyTorch中,卷积是一种常用于深度学习的数学运算,特别是在处理图像和视频数据时。卷积运算通过将卷积核(或滤波器)滑动应用于输入数据(如图像),来提取特征或进行图像处理。这种方法在卷积神经网络(CNNs)中尤为重要,因为它能够有效地识别图像中的局部模式,如边缘、纹理等。 **
卷积的作用:
**_ 1. 特征提取:卷积能够从输入数据中提取有用的特征。在图像处理中,不同的卷积核能够捕捉到图像的不同特征,如边缘、角点或其他纹理信息。
2. 降维:通过使用步长大于1的卷积,或者在卷积之后应用池化层(如最大池化),可以减少数据的空间维度,从而减少模型的参数数量和计算量。
3. 保持空间结构:_**与全连接层相比,卷积层保持了数据的空间结构信息。这意味着卷积网络能够理解图像中的空间层次和对象的形状。
相关参数:
1.输入通道数(Input Channels):
指的是输入数据的深度。例如,对于彩色RGB图像,输入通道数为3。
2.输出通道数(Output Channels):
指的是卷积操作后生成的特征图(Feature Maps)的数量。这个数字也代表了卷积核数量,因为每个卷积核产生一个输出特征图。
3.卷积核大小(Kernel Size):
卷积核(或滤波器)的大小,通常是正方形,表示为(n, n)或仅一个数字n(对于n x n的卷积核)。卷积核大小影响了特征提取的粒度,较小的卷积核可以捕捉更细微的特征。
****4.步长(Stride):**
卷积核在输入特征图上滑动的步长。较大的步长会减少输出特征图的空间维度,有助于降低计算量和模型大小。步长通常表示为(s, s)或一个数字s。
5.填充(Padding):
在输入特征图的边缘添加额外的零值(0)以保持特定的输出尺寸。填充可以是"valid"(无填充),“same”(输出尺寸与输入相同),或一个指定的数字,表示在每个边缘添加的零值的行数或列数。
6.分组(Groups):
控制输入和输出通道之间的连接。分组卷积可以减少参数数量和计算量。当分组数等于输入通道数时,这种操作被称为深度卷积。
卷积代码示例:
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 1, 0, 0],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
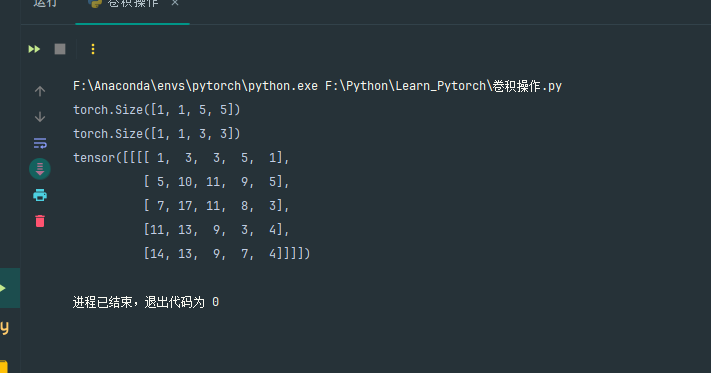
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, padding=1)
print(output)
代码展示:
import torch
from torch import nn
import torchvision.datasets
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('E:\\Python\\Learn_Pytorch\\dataset_01', train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Module(nn.Module):
def __init__(self):
super(Module, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
module = Module()
writer = SummaryWriter('juanji_logs')
step = 0
for data in dataloader:
imgs, targets = data
output = module(imgs)
print(imgs.shape)
print(output.shape)
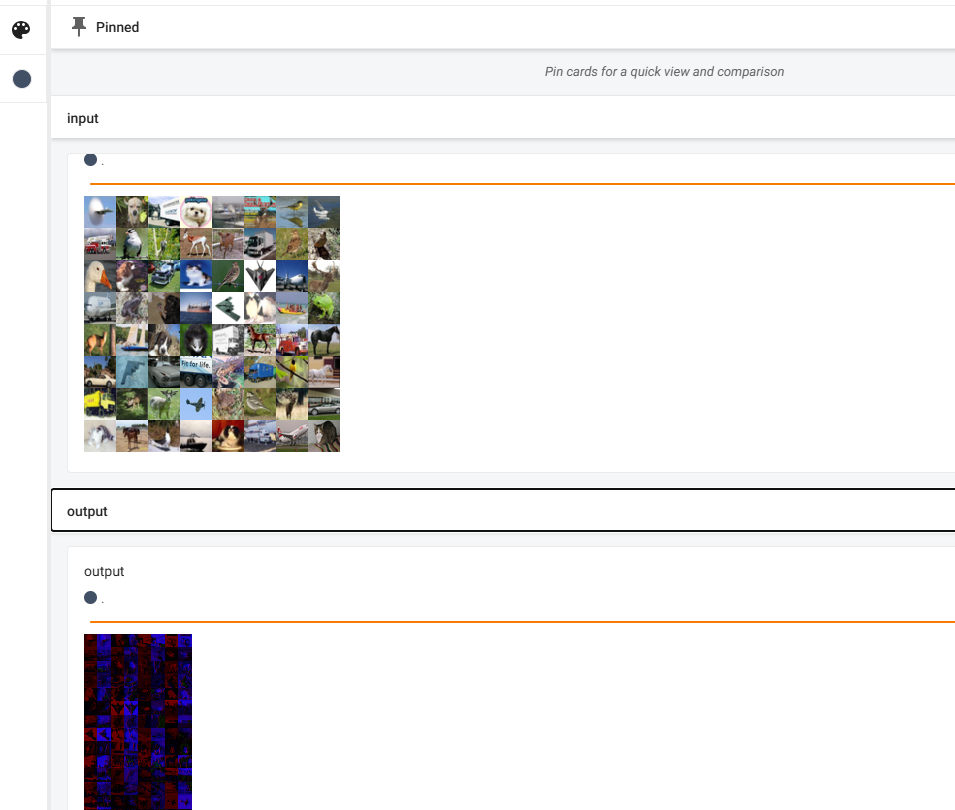
writer.add_images('input', imgs, step)
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images('output', output, step)
step = step + 1















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









