







AI云原生时代的算力革命:如何驾驭复杂算力环境与HAMI的创新实践
©作者|Zane
来源|神州问学
背景
引言
随着在2019年ChatGPT4的爆火,AI这个之前常常被人觉得非常高深的技术渐渐的被越来越多的人们所了解,越来越多的公司、组织和开发者开始投入AI的使用和开发中来.随着AI和LLM的火热,算力资源也变的越来越紧缺,所以如何高效的管理和使用算力资源也变成了必须要面对的问题。
因为当前模型的微调、推理以及AI应用的开发过程更加符合云原生的特点,越来越多的公司决定将自己的计算任务放到Kubernetes(下称K8S)上进行。根据OpenAI的官方博客介绍ChatGPT也是使用云原生技术支持模型训练的。官方表示OpenAI已经将K8S集群扩展到了7500个节点,为GPT3,DALL.E等模型提供了可扩展的基础性,同时也为小模型小规模的快速迭代研究提供了基础。这也为AI相关技术的落地提供了参考,越来越多的公司选择将自己的计算任务放到K8S上运行。
而在国内因为特殊情况,当前的的计算设备则具有型号种类多、算力差异大等特点,这些特点彰显了当前的算力环境的复杂,因此如何在K8S上管理、使用如此复杂的算力环境则成为了一个巨大的挑战。
当前AI落地场景
目前在AI落地的不同场景,使用算力资源的场景总体可以分为三个大类,分别是针对大模型的预训练和针对预训练模型的微调的训练场景,以及在模型部署场景中则主要针对训练后模型的推理场景,而目前最多的场景则是针对大模型的应用开发场景,如RAG,Agent等。
而在这三个大类型的不同场景中我们对算力的使用也是不尽相同的,如在训练场景中,我们则往往需要更多的算力也就是更多的卡去并行的训练模型,而在推理场景中我们则更关心的是,我们可能更关系推理服务的稳定和可扩展性,而在应用开发的场景我们则对算力需求比较小,往往仅在使用Embeding、Rerank等小模型时使用小量的算力。
在训练场景中,我们可能会遇到两种情况,分别是算力卡单卡资源不足需要多卡分布式训练的情况,或者单卡资源充足但是进行小参数模型的LoRA微调使用的资源较小的情况。
分布式训练场景

单卡微调场景
在推理场景中,我们仍然可能需要面对的是单卡推理或者分布式推理的场景,以及弹性的扩容推理服务。
单卡推理场景
多卡推理场景
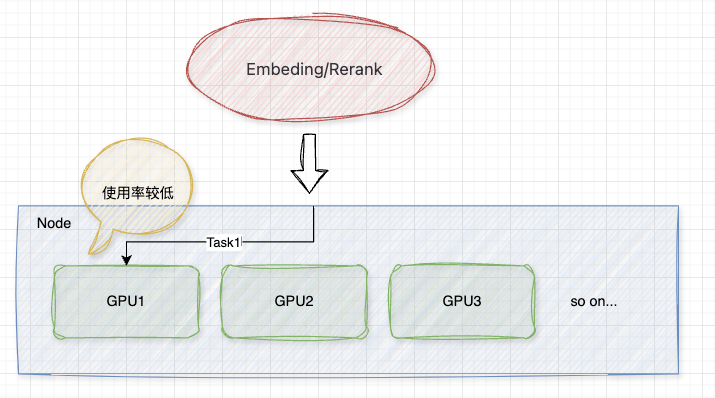
在AI应用的开发中,使用计算资源的部分往往是小的Embeding、Rerank以及OCR等模型,这种模型往往使用的资源较小,通常无法占满一张卡的全部资源。
AI应用,小模型场景
除了列举的几种情况外,还会有其他更多复杂的情况如多机多卡的推理/训练等场景。在针对不同的使用场景时如何更加精确的按需去管理算力资源则又是一个我们必须要必须要面对的问题。
算力卡现状
国际主流GPU厂商
1. 英伟达:以CUDA编程环境和GPU计算平台称雄,其卓越的FP32单双精度浮点性能及AI运算能力,使其在AI训练和高性能计算领域独占鳌头。
2. AMD:Radeon系列GPU在游戏市场与英伟达分庭抗礼,同时,AMD推出Instinct系列加速卡,以卓越的计算力和能效比,领跑AI训练和推理领域。
3. 英特尔:深耕独立GPU市场,推出基于Xe架构的高性能GPU,在集成GPU领域领先。
4. 谷歌:TPU(张量处理单元)是专为AI和机器学习优化的ASIC,在TensorFlow框架中显著提升了深度学习训练和推理效率。
国内主流GPU厂商
1. 海光信息:CPU与DCU产品融合通用计算与特定领域加速,安全性能卓越。
2. 芯动科技:“风华”系列GPU,像素填充率与AI性能直逼国际标杆。
3. 摩尔线程:推出春晓、苏堤芯片,同时推出了AI模型以及智算中心。
4. 华为海思:推出ASIC产品系列,包括昇腾AI芯片,专为人工智能计算设计。
5. 寒武纪:AI芯片设计翘楚,ASIC产品深度学习领域领先,神经网络计算优化架构,高效运行各类AI算法。
当前的现状
在早起的时候K8S官方并未将GPU等算力资源作为默认支持的资源的一种,推测是因为在早起的设计之初K8S是为容器服务提供编排能力更加关心CPU和内存的使用情况,并且大部分的服务并不适用GPU资源,所以官方并没有考虑GPU资源的控制。
而随着K8S在v1.6开始实验性质的支持英伟达的GPU资源调度而从v1.9开始对AMD GPU也开始支持了,当前市面上的一些组件是从v1.8开始通过Device Plugin的方式来实现,而各个厂商为了自家的GPU能够在K8S上被调度使用也分别开发了属于自己的Device Plugin,例如在K8S官方的调度GPU章节分别举例了AMD,Intel和NVIDIA的3家厂商的插件,同时国内的华为昇腾也提供了MindX DL套件来支持Atlas训练推理卡在K8S上的调度管理支持。虽然已经有了很多计算资源的调度方案,但是由于厂家不同,各个方案也被厂家分别维护,同时官方支持的Device Plugin往往不能够支持GPU的资源隔离和资源共享等功能,导致在使用时往往会造成GPU资源分配不合理从而导致浪费情况。
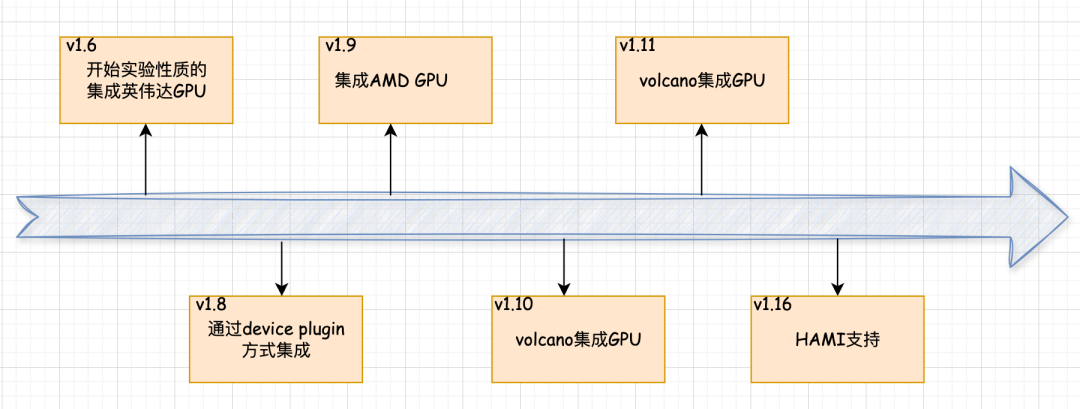
而为了解决这些情况,越来越多的第三方厂商开始对GPU资源的调度进行适配开发,如阿里开发的GPUShare方案、腾讯的vGPU方案以及华为的Volcano方案,都对调度GPU资源进行了支持,但是这些方案往往还是不能满足复杂场景的需求.
而在公有云上各个厂商推出了更加优秀的GPU资源调度方案, 例如阿里云的cGPU,腾讯云的qGPU等方案,这些方案往往能够在更加底层的维度去管理计算资源,但是由于这些方案往往是厂商的在售的方案所以大部分并未开源.
那么为了能够满足资源共享,资源隔离等需求,这里推荐云原生计算资源管理组件HAMI,他能够满足大部分场景,并且适配了很多国产的计算资源,能够为更多的国产化场景提供有力的支持.并且已经加入了CNCF云原生基金会的景观图中.
HAMI
HAMI是一个云原生的K8S异构计算资源设备插件,它可以兼容原生的NVIDIA的设备插件的字段以及K8S的调度器,同时支持多种计算设备,包括国产的华为NPU,寒武纪MLU等计算设备。
HAMI通过接入不同厂商的docker-runtime以及Device Plugin,在更上层进行统一管理,抹平不同设备的调度差异,从而实现不同设备的统一调度。同时通过自己开发的HAMI Core实现对GPU的细粒度划分。
显卡支持

功能
设备共享: 每个任务可以分配设备的一部分而不是整个设备,从而允许多个任务共享一个设备.
设备内存控制: 可以为设备分配特定的设备内存大小或者整个GPU的百分比,确保其不超过指定的边界.
设备类型规范: 可以通过设置注释来制定针对特定任务的要使用或者避免的设备类型.
设备uuid规范: 可以通过设置注释来制定要使用或者避免用于特定任务的设备UUID
易于使用: 无需修改任务的配置即可使用调度程序,安装后自动支持,也可以指定nvidia之外的资源
调度策略支持: 支持节点级和GPU级策略,可以通过调度参数默认设置,并且两个维度都支持两种策略:`binpack`和`spread`。
应用场景
1. K8S上的计算设备共享
2. 需要为pod分配特定的设备内容
3. 需要在具有多个GPU节点的集群中平衡GPU的使用情况
4. 设备内存和计算单元的利用率低,例如子一个GPU上运行多个TensorFlow服务
5. 需要大量小型GPU的情况,例如提供一块GPU供多名学生使用的教学场景、提供小型GPU实例的云平台等
HAMI实践
安装
可以使用Helm命令行快速安装
```helm repo add hami-charts https://project-hami.github.io/HAMi/kubectl versionhelm install hami hami-charts/hami --set scheduler.kubeScheduler.imageTag=v1.16.8 -n kube-system```
使用
按照大小分配具体显存
```resources:limits:nvidia.com/gpu: 1 # requesting 1 GPUnvidia.com/gpumem: 3000 # Each GPU contains 3000m device memory```
按照核数分配
```resources:limits:nvidia.com/gpu: 1 # requesting 1 GPUnvidia.com/gpucores: 50 # Each GPU allocates 50% device cores.```
指定设备的型号
```metadata:annotations:nvidia.com/use-gputype: "A100,V100" # Specify the card type for this job, use comma to seperate, will not launch job on non-specified card```
按照id指定设备
```metadata:annotations:nvidia.com/use-gpuuuid: "GPU-123456"```
支持寒武纪设备
```apiVersion: v1kind: Podmetadata:name: gpu-podspec:containers:- name: ubuntu-containerimage: ubuntu:18.04command: ["bash", "-c", "sleep 86400"]resources:limits:cambricon.com/mlunum: 1 # requesting 1 MLUcambricon.com/mlu.smlu.vmemory: 20 # each MLU requesting 20% MLU device memorycambricon.com/mlu.smlu.vcore: 10 # each MLU requesting 10% MLU device core```
支持昇腾910B设备
```apiVersion: v1kind: Podmetadata:name: gpu-podspec:containers:- name: ubuntu-containerimage: ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.RC3-centos7command: ["bash", "-c", "sleep 86400"]resources:limits:huawei.com/Ascend910: 1 # requesting 1 vGPUshuawei.com/Ascend910-memory: 2000 # requesting 2000m device memory```
总结
目前的算力环境仍然已英伟达的GPU设备为主,但是目前也有很多厂商的设备在被使用,虽然其中主流厂商都有提供自己的卡在K8S上的调度支持,但是这些厂商方案往往比较基础,通常需要按照卡的数量进行调度而没办法进行更细粒度的调度,导致很多计算资源被浪费,HAMI基于这些厂商的开源方案进行集成,主要在使用劫持CUDA的方案来实现计算设备的共享、隔离,在插件层使用一个方案集成多种计算资源.
目前HAMI在实现设备资源隔离时使用的是在CUDA层进行劫持,会深度依赖CUDA,当CUDA发布新版本有更新如果存在增加功能或者接口变更,则可能导致不可用.更优的方案是类似阿里云上的cGPU在内核层面进行劫持实现,但是由于壁垒、法律等诸多问题阿里的cGPU或者腾讯的qGPU开源的开源的可能性较小.
同时由于显卡市场的发展,越来越多厂家推出更多显卡设备导致当前上设备种类繁多,目前HAMI支持的显卡型号虽然已经很多了,但是仍有大量的显卡不支持,这也为异构计算集群的搭建产生了巨大的挑战.
相信未来随着算力市场的发展,最终会形成一套标准的框架,来屏蔽软件到硬件之间的差异,到时异构计算集群组建将不在是难题.
参考资料
[Scaling Kubernetes to 2,500 nodes](https://openai.com/index/scaling-kubernetes-to-2500-nodes/)
[Scaling Kubernetes to 7,500 nodes](https://openai.com/index/scaling-kubernetes-to-7500-nodes/)
[https://github.com/Project-HAMi/HAMi](https://github.com/Project-HAMi/HAMi)















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









