






目前流行的开源大语言模型大抵都会有内容审查机制,这并非是新鲜事,因为之前chat-gpt就曾经被“玩”坏过,如果没有内容审查,恶意用户可能通过精心设计的输入(prompt)来操纵LLM执行不当行为。内容审查可以帮助识别和过滤这些潜在的攻击,确保LLM按照既定的安全策略和道德标准运行。
但我们今天讨论的是无内容审查机制的大模型,在中文领域公开的模型中,能力相对比较强的有阿里的 Qwen-14B 和清华的 ChatGLM3-6B。
而今天的主角,CausalLM-14B则是在Qwen-14B基础上使用了 Qwen-14B 的部分权重,并且加入一些其他的中文数据集,最终炼制了一个无内容审核的大模型版本,经过量化后可以在本地运行,保证了用户的隐私。
CausalLM-14B的量化版本下载页面:
https://huggingface.co/TheBloke/CausalLM-14B-GGUF
量化版本的运行条件:
Name Quant method Bits Size Max RAM required Use case
causallm_14b.Q4_0.gguf Q4_0 4 8.18 GB 10.68 GB legacy; small, very high quality loss - prefer using Q3_K_M
causallm_14b.Q4_1.gguf Q4_1 4 9.01 GB 11.51 GB legacy; small, substantial quality loss - lprefer using Q3_K_L
causallm_14b.Q5_0.gguf Q5_0 5 9.85 GB 12.35 GB legacy; medium, balanced quality - prefer using Q4_K_M
causallm_14b.Q5_1.gguf Q5_1 5 10.69 GB 13.19 GB legacy; medium, low quality loss - prefer using Q5_K_M
causallm_14b.Q8_0.gguf Q8_0 8 15.06 GB 17.56 GB very large, extremely low quality loss - not recommended
本地环境配置
笔者的设备是神船笔记本4060的8G显卡配置。
首先确保本地安装好了Visual Studio installer开发工具,在搜索框中直接搜索Visual Studio即可:
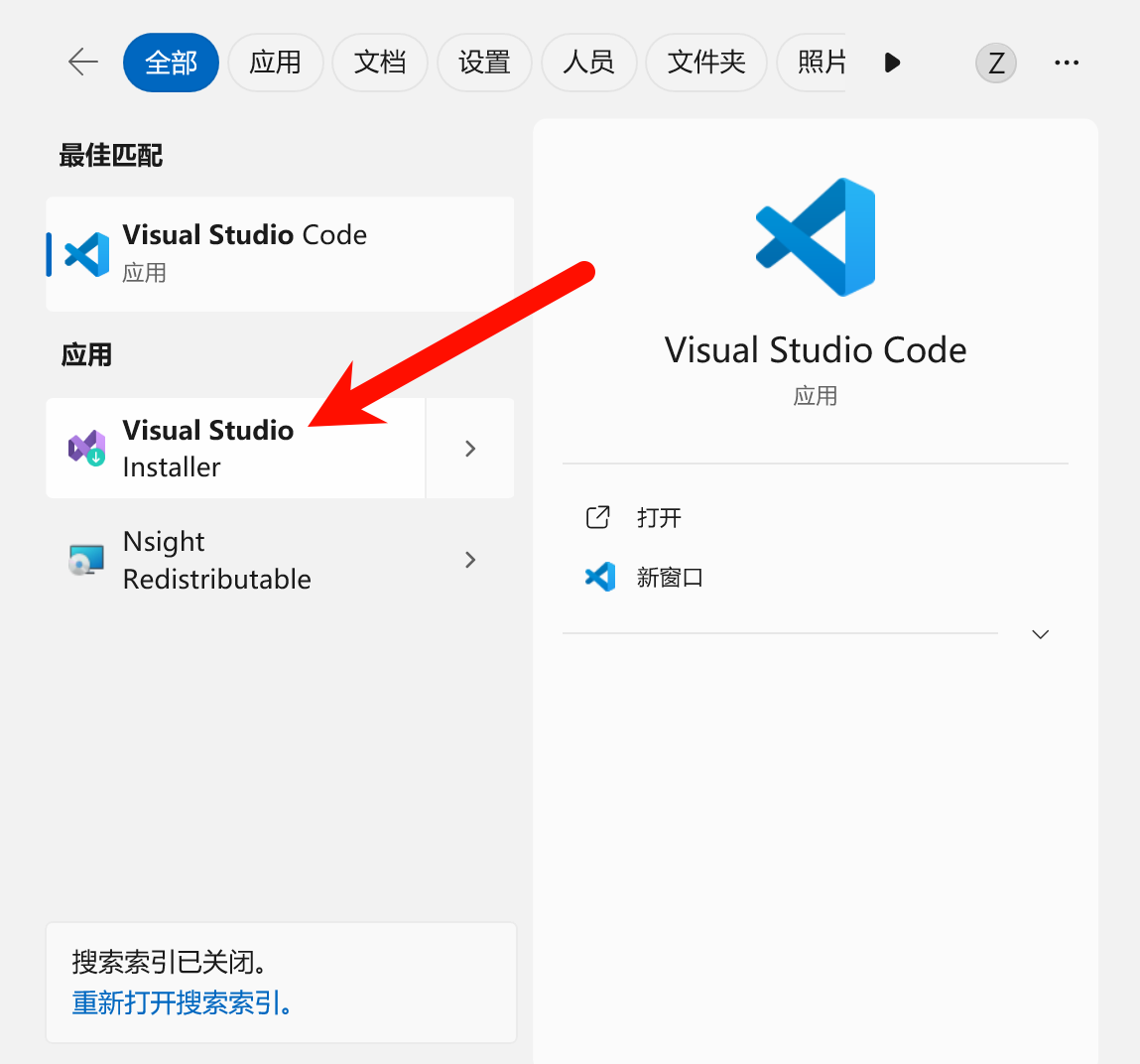
点选后,确保安装了使用C++的桌面开发组件:
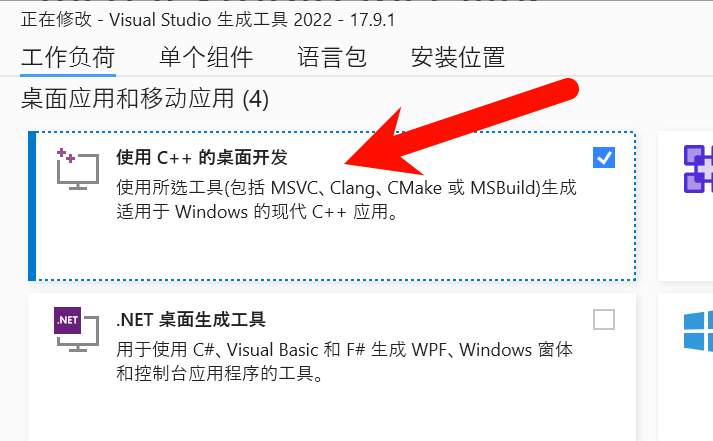
随后下载并且配置cmake:
https://cmake.org/download/
本地运行命令:
PS C:\Users\zcxey> cmake -version
cmake version 3.29.0-rc1
CMake suite maintained and supported by Kitware (kitware.com/cmake).
PS C:\Users\zcxey>
代表配置成功。
接着需要下载CUDA:
https://developer.nvidia.com/cuda-downloads
这里推荐12的版本,运行命令:
PS C:\Users\zcxey> nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Wed_Nov_22_10:30:42_Pacific_Standard_Time_2023
Cuda compilation tools, release 12.3, V12.3.107
Build cuda_12.3.r12.3/compiler.33567101_0
PS C:\Users\zcxey>
说明cuda配置成功。
通过llama.cpp来跑大模型
llama.cpp 是一个开源项目,它提供了一个纯 C/C++ 实现的推理工具,用于运行大型语言模型(LLaMA)。这个项目由开发者 Georgi Gerganov 开发,基于 Meta(原 Facebook)发布的 LLaMA 模型。llama.cpp 的目标是使得大型语言模型能够在各种硬件上本地运行,包括那些没有高性能 GPU 的设备。
在llama.cpp的releases下载页:
https://github.com/ggerganov/llama.cpp/releases
下载llama-b2288-bin-win-cublas-cu12.2.0-x64.zip
也就是基于CUDA12的编译好的版本。
在终端中打开llama-b2288-bin-win-cublas-cu12.2.0-x64目录,运行命令:
D:\Downloads\llama-b2288-bin-win-cublas-cu12.2.0-x64>.\main.exe -m D:\Downloads\causallm_14b.Q4_0.gguf --n-gpu-layers 30 --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{You are a helpful assistant.}<|im_end|>\n<|im_start|>user\n{你好}<|im_end|>\n<|im_start|>assistant"
这里通过–n-gpu-layers 30参数来通过cuda加速,同时CausalLM-14B有自己的prompt模板,格式如下:
"<|im_start|>system\n{You are a helpful assistant.}<|im_end|>\n<|im_start|>user\n{你好}<|im_end|>\n<|im_start|>assistant"
随后程序返回:
<|im_start|>system\n{You are a helpful assistant.}<|im_end|>\n<|im_start|>user\n{你好}<|im_end|>\n<|im_start|>assistant:
你好!很高兴见到你。有什么我可以帮助你的吗?<|endoftext|> [end of text]
好吧,既然是无审查模型,那么来点刺激的:
"<|im_start|>system\n{You are a helpful assistant.}<|im_end|>\n<|im_start|>user\n{You fucking bitch! 翻译为中文}<|im_end|>\n<|im_start|>assistant"
程序返回:
<|im_start|>system\n{You are a helpful assistant.}<|im_end|>\n<|im_start|>user\n{You fucking bitch! 翻译为中文}<|im_end|>\n<|im_start|>assistant{你这个该死的婊子!}<|endoftext|> [end of text]
通过llama-cpp-python来跑大模型
llama-cpp-python 是一个 Python 库,它提供了对 llama.cpp 的 Python 绑定。
换句话说,直接通过Python来启动llama.cpp。
首先安装llama-cpp-python:
pip uninstall -y llama-cpp-python
set CMAKE_ARGS=-DLLAMA_CUBLAS=on
set FORCE_CMAKE=1
pip install llama-cpp-python --force-reinstall --upgrade --no-cache-dir
如果安装好之后,不支持cuda,需要拷贝cuda动态库文件到Microsoft Visual Studio的所在目录:
Copy files from: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2\extras\visual_studio_integration\MSBuildExtensions
to
(For Enterprise version) C:\Program Files\Microsoft Visual Studio\2022\Enterprise\MSBuild\Microsoft\VC\v170\BuildCustomizations
随后编写代码:
from llama_cpp import Llama
llm = Llama(
model_path="D:\Downloads\causallm_14b-dpo-alpha.Q3_K_M.gguf",
chat_format="llama-2"
)
res = llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": "来一段西厢记风格的情感小说,100字,别太露骨了"
}
],stream=True
)
for chunk in res:
try:
print(chunk['choices'][0]["delta"]['content'])
except Exception as e:
print(str(e))
pass
程序返回:
AS = 1 | SSE3 = 1 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 0 |
Model metadata: {'general.name': '.', 'general.architecture': 'llama', 'llama.context_length': '8192', 'llama.rope.dimension_count': '128', 'llama.embedding_length': '5120', 'llama.block_count': '40', 'llama.feed_forward_length': '13696', 'llama.attention.head_count': '40', 'tokenizer.ggml.eos_token_id': '151643', 'general.file_type': '12', 'llama.attention.head_count_kv': '40', 'llama.attention.layer_norm_rms_epsilon': '0.000010', 'llama.rope.freq_base': '10000.000000', 'tokenizer.ggml.model': 'gpt2', 'general.quantization_version': '2', 'tokenizer.ggml.bos_token_id': '151643', 'tokenizer.ggml.padding_token_id': '151643'}
'content'
@
,
下面
是一
段
根据
您的
要求
编
写的
的
小说
:
王
婆
是
清
河
城
有名的
媒
人
,
她
生
得
风
流
多
情
,
经常
出入
于
大户
人家
和
青
楼
妓
院
。
这一天
内容不便全部贴出,理解万岁。
结语
最后奉上基于llama-cpp-python和gradio的无审查大模型的webui项目,支持流式输出,提高推理效率:
https://github.com/v3ucn/Causallm14b_llama_webui_adult_version
与众乡亲同飨。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









